жҰӮи§Ҳ
Dynamo жҳҜдёҖдёӘй«ҳеҸҜз”Ёзҡ„ KV еӯҳеӮЁзі»з»ҹгҖӮдёәдәҶдҝқиҜҒй«ҳеҸҜз”Ёе’Ңй«ҳжҖ§иғҪпјҢDynamo йҮҮз”ЁдәҶз»ҲдёҖиҮҙжҖ§жЁЎеһӢпјҢе®ғеҜ№ејҖеҸ‘дәәе‘ҳжҸҗдҫӣдёҖз§Қж–°еһӢ APIпјҢдҪҝз”ЁдәҶзүҲжң¬жңәеҲ¶пјҢ并йҖҡиҝҮз”ЁжҲ·дҫ§иҫ…еҠ©и§ЈеҶіеҶІзӘҒгҖӮDynamo зӣ®ж ҮжҳҜжҸҗдҫӣдёҚй—ҙж–ӯзҡ„жңҚеҠЎпјҢеҗҢж—¶дҝқиҜҒжҖ§иғҪе’ҢеҸҜжү©еұ•жҖ§гҖӮз”ұдәҺдәҡ马йҖҠеӨ§йҮҸйҮҮз”ЁдәҶеҺ»дёӯеҝғеҢ–гҖҒй«ҳеәҰи§ЈиҖҰеҫ®жңҚеҠЎжһ¶жһ„пјҢеӣ жӯӨеҜ№еҫ®жңҚеҠЎзҠ¶жҖҒзҡ„еӯҳеӮЁзі»з»ҹзҡ„еҸҜз”ЁжҖ§иҰҒжұӮе°Өе…¶й«ҳгҖӮ
S3 пјҲSimple Storage ServiceпјүжҳҜ Amazon еҸҰдёҖж¬ҫжңүеҗҚзҡ„еӯҳеӮЁжңҚеҠЎпјҢиҷҪ然д№ҹеҸҜд»ҘзҗҶи§Јдёә KV еӯҳеӮЁпјҢдҪҶе®ғе’Ң Dynamo зҡ„зӣ®ж ҮеңәжҷҜ并дёҚдёҖиҮҙгҖӮS3 жҳҜйқўеҗ‘еӨ§ж–Ү件зҡ„еҜ№иұЎеӯҳеӮЁжңҚеҠЎпјҢдё»иҰҒеӯҳеӮЁдәҢиҝӣеҲ¶ж–Ү件пјҢдёҚжҸҗдҫӣи·ЁеҜ№иұЎзҡ„дәӢеҠЎгҖӮиҖҢ Dynamo жҳҜдёҖж¬ҫйқўеҗ‘е°Ҹж–Ү件зҡ„ж–ҮжЎЈеӯҳеӮЁжңҚеҠЎпјҢдё»иҰҒеӯҳеӮЁз»“жһ„еҢ–ж•°жҚ®пјҲеҰӮ jsonпјүпјҢ并且еҸҜд»ҘеҜ№ж•°жҚ®и®ҫзҪ®зҙўеј•пјҢдё”ж”ҜжҢҒи·Ёж•°жҚ®жқЎзӣ®зҡ„дәӢеҠЎгҖӮ
зӣёеҜ№дәҺдј з»ҹзҡ„е…ізі»еһӢж•°жҚ®еә“пјҢDynamo еҸҜд»Ҙи®ӨдёәжҳҜеҸӘжҸҗдҫӣдё»й”®зҙўеј•пјҢд»ҺиҖҢиҺ·еҸ–жӣҙй«ҳзҡ„жҖ§иғҪе’ҢжӣҙеҘҪзҡ„жү©еұ•жҖ§гҖӮ
дёәдәҶе®һзҺ°еҸҜжү©еұ•жҖ§е’Ңй«ҳеҸҜз”ЁжҖ§пјҢ并дҝқиҜҒз»ҲдёҖиҮҙжҖ§пјҢDynamo з»јеҗҲдҪҝз”ЁдәҶд»ҘдёӢжҠҖжңҜпјҡ
- дҪҝз”ЁдёҖиҮҙжҖ§е“ҲеёҢеҜ№ж•°жҚ®иҝӣиЎҢеҲҶзүҮпјҲpartitionпјүе’ҢеӨҮд»ҪпјҲreplicateпјүгҖӮ
- дҪҝз”ЁзүҲжң¬еҸ·жңәеҲ¶пјҲVector ClockпјүеӨ„зҗҶж•°жҚ®дёҖиҮҙжҖ§й—®йўҳгҖӮ
- дҪҝз”ЁеӨҡж•°зҘЁпјҲQuorumпјүе’ҢеҺ»дёӯеҝғеҢ–еҗҢжӯҘеҚҸи®®жқҘз»ҙжҢҒеүҜжң¬й—ҙзҡ„дёҖиҮҙжҖ§пјҲMerkle TreeпјүгҖӮ
- еҹәдәҺ Gossip Protocol иҝӣиЎҢеӨұиҙҘжЈҖжөӢе’ҢеүҜжң¬з»ҙжҢҒгҖӮ
е®һзҺ°дёҠжқҘиҜҙпјҢDynamo жңүд»ҘдёӢзү№зӮ№пјҡ
- е®Ңе…ЁеҺ»дёӯеҝғеҢ–пјҢжІЎжңүдёӯеҝғиҠӮзӮ№пјҢжүҖжңүиҠӮзӮ№е…ізі»еҜ№зӯүгҖӮ
- йҮҮз”Ёз»ҲдёҖиҮҙжҖ§пјҢдҪҝз”ЁзүҲжң¬еҸ·и§ЈеҶіеҶІзӘҒпјҢз”ҡиҮіиҰҒжұӮз”ЁжҲ·еҸӮдёҺи§ЈеҶіеҶІзӘҒгҖӮ
- дҪҝз”Ёе“ҲеёҢеҖјиҝӣиЎҢж•°жҚ®еҲҶзүҮпјҢз»„з»Үж•°жҚ®еҲҶеёғпјҢеқҮиЎЎж•°жҚ®иҙҹиҪҪгҖӮ
дҪңиҖ…пјҡжңЁйёҹжқӮи®° www.qtmuniao.com/2020/06/13/вҖҰ, иҪ¬иҪҪиҜ·жіЁжҳҺеҮәеӨ„
иғҢжҷҜ
зӣ®ж Үе’ҢеҒҮи®ҫ
дёҚеҗҢзҡ„и®ҫи®ЎеҒҮи®ҫе’ҢиҰҒжұӮдјҡеҜјиҮҙе®Ңе…ЁдёҚеҗҢзҡ„и®ҫи®ЎпјҢDynamo зҡ„и®ҫи®Ўзӣ®ж Үжңүд»ҘдёӢеҮ дёӘпјҡ
жҹҘиҜўжЁЎеһӢгҖӮдҪҝз”Ё Dynamo еҸӘдјҡдҪҝз”Ёдё»й”®иҝӣиЎҢжҹҘиҜўпјҢдёҖиҲ¬жІЎжңүи·Ёж•°жҚ®жқЎзӣ®пјҢеӣ жӯӨдёҚйңҖиҰҒе…ізі»жЁЎеһӢгҖӮжӯӨеӨ–пјҢDynamo еҒҮи®ҫе…¶еӯҳеӮЁзҡ„ж•°жҚ®йғҪзӣёеҜ№иҫғе°ҸпјҢйҖҡеёёе°ҸдәҺ 1MгҖӮ
ACID зү№жҖ§гҖӮдј з»ҹе…ізі»еһӢж•°жҚ®еә“пјҲDBMSпјүдёәдәҶдҝқиҜҒдәӢеҠЎзҡ„жӯЈзЎ®жҖ§е’ҢеҸҜйқ жҖ§пјҢйҖҡеёёйңҖиҰҒе…·еӨҮ ACID зү№жҖ§гҖӮдҪҶеҜ№ ACID зҡ„ж”ҜжҢҒдјҡжһҒеӨ§йҷҚдҪҺж•°жҚ®зҡ„жҖ§иғҪпјҢдёәдәҶй«ҳеҸҜз”ЁжҖ§пјҢDynamo еҸӘжҸҗдҫӣејұдёҖиҮҙжҖ§пјҲCпјүпјҢдёҚжҸҗдҫӣйҡ”зҰ»жҖ§пјҲIпјүпјҢдёҚе…Ғи®ёеҚ•дёӘ key зҡ„并еҸ‘жӣҙж–°гҖӮ
ж•ҲзҺҮгҖӮAmazon дёӯеӨ§йғЁеҲҶжңҚеҠЎеҜ№е»¶иҝҹжңүзқҖдёҘж јзҡ„иҰҒжұӮпјҢдёәдәҶиғҪеӨҹж»Ўи¶іжӯӨзұ»жңҚеҠЎзҡ„ SLAпјҢDynamo йЎ»еҸҜй…ҚзҪ®пјҢи®©з”ЁжҲ·иҮӘе·ұеңЁжҖ§иғҪгҖҒж•ҲзҺҮгҖҒеҸҜз”ЁжҖ§е’ҢжҢҒд№…еҢ–й—ҙиҝӣиЎҢйҖүжӢ©гҖӮ
е…¶д»–гҖӮDynamo еҸӘз”ЁеңЁ Amazon еҶ…йғЁжңҚеҠЎдёӯпјҢеӣ жӯӨеҸҜд»ҘдёҚиҖғиҷ‘е®үе…ЁжҖ§гҖӮжӯӨеӨ–пјҢеҫҲеӨҡжңҚеҠЎдјҡдҪҝз”ЁзӢ¬з«Ӣзҡ„ Dynamo е®һдҫӢпјҢеӣ жӯӨеҲқй’ҲеҜ№еҸҜжү©еұ•жҖ§зҡ„зӣ®ж ҮеңЁзҷҫеҸ°жңәеҷЁзә§еҲ«гҖӮ
SLA
з”ұдәҺйҮҮз”Ёеҫ®жңҚеҠЎжһ¶жһ„пјҢAmazon иҙӯзү©зҪ‘з«ҷзҡ„жҜҸдёӘйЎөйқўзҡ„жёІжҹ“йҖҡеёёдјҡж¶үеҸҠеҲ°дёҠзҷҫдёӘжңҚеҠЎгҖӮдёәдәҶдҝқиҜҒз”ЁжҲ·дҪ“йӘҢпјҢеҝ…йЎ»еҜ№жҜҸдёӘжңҚеҠЎзҡ„延иҝҹеҒҡдёҘж јйҷҗеҲ¶гҖӮAmazon йҮҮз”ЁдёүдёӘд№қпјҲ99.9% зҡ„иҜ·жұӮйңҖиҰҒе°ҸдәҺ 300msпјүзҡ„ SLAгҖӮиҖҢжңҚеҠЎзҡ„зҠ¶жҖҒеӯҳеӮЁзҺҜиҠӮеҲҷжҳҜжҸҗдҫӣиҜҘ SLA зҡ„е…ій”®иҠӮзӮ№пјҢдёәжӯӨ Dynamo зҡ„дёҖдёӘе…ій”®и®ҫи®ЎжҳҜи®©жңҚеҠЎеҸҜжҢүйңҖе®ҡеҲ¶жҢҒд№…еҢ–е’ҢдёҖиҮҙжҖ§зӯүеҸӮж•°пјҢд»ҘеңЁжҖ§иғҪгҖҒжҲҗжң¬е’ҢжӯЈзЎ®жҖ§й—ҙиҝӣиЎҢжҠүжӢ©гҖӮ
и®ҫи®ЎиҖғйҮҸ
еҜ№дәҺеӨҡеүҜжң¬зі»з»ҹпјҢй«ҳеҸҜз”ЁжҖ§е’ҢејәдёҖиҮҙжҖ§жҳҜдёҖеҜ№зҹӣзӣҫгҖӮдј з»ҹе•Ҷз”Ёзі»з»ҹеӨҡдёәдәҶдҝқиҜҒејәдёҖиҮҙжҖ§иҖҢзүәзүІйғЁеҲҶеҸҜз”ЁжҖ§пјҢдҪҶDynamo дёәй«ҳеҸҜз”ЁиҖҢз”ҹпјҢеӣ жӯӨйҖүжӢ©дәҶејӮжӯҘеҗҢжӯҘзӯ–з•ҘгҖӮдҪҶжҳҜз”ұдәҺзҪ‘з»ңе’ҢжңҚеҠЎеҷЁж•…йҡңзҡ„йў‘еҸ‘зү№жҖ§пјҢзі»з»ҹеҝ…йЎ»еӨ„зҗҶиҝҷдәӣж•…йҡңжүҖеҜјиҮҙзҡ„дёҚдёҖиҮҙпјҢжҲ–иҖ…иҜҙжҳҜеҶІзӘҒгҖӮиҝҷдәӣеҶІзӘҒеҰӮдҪ•и§ЈеҶіпјҢдё»иҰҒеҢ…жӢ¬дёӨж–№йқўпјҡеңЁд»Җд№Ҳж—¶еҖҷи§ЈеҶіпјҢд»ҘеҸҠпјҢи°ҒжқҘи§ЈеҶігҖӮ
дҪ•ж—¶и§ЈеҶігҖӮдј з»ҹеӯҳеӮЁзі»з»ҹдёәдәҶз®ҖеҢ–иҜ»еҸ–пјҢйҖҡеёёеңЁеҶҷе…Ҙдҫ§и§ЈеҶіеҶІзӘҒпјҢеҚіеҪ“еӯҳеңЁеҶІзӘҒзҡ„ж—¶еҖҷпјҢжӢ’з»қеҶҷе…ҘгҖӮдҪҶ Dynamo дёәдәҶдҝқиҜҒе•ҶеҹҺдёҡеҠЎеҜ№з”ЁжҲ·д»»ж„Ҹж—¶еҲ»еҸҜз”ЁпјҲжҜ”еҰӮйҡҸж—¶иғҪе°Ҷе•Ҷе“ҒеҠ иҙӯзү©иҪҰпјҢжҜ•з«ҹзұ»дјјиҝҮзЁӢзҡ„дҪ“йӘҢзЁҚеҫ®дёҖдёӢйҷҚпјҢе°ұдјҡеҪұе“ҚеӨ§жҠҠзҡ„收е…ҘпјүпјҢйңҖиҰҒжҸҗдҫӣ"ж°ёиҝңеҸҜеҶҷ"пјҲalways writableпјүзҡ„дҝқиҜҒпјҢеӣ жӯӨйңҖиҰҒе°Ҷи§ЈеҶіеҶІзӘҒзҡ„еӨҚжқӮеәҰжҺЁиҝҹеҲ°иҜ»еҸ–ж—¶еҲ»гҖӮ
и°ҒжқҘи§ЈеҶігҖӮжҳҜз”ұ Dynamo жқҘи§ЈеҶіпјҢиҝҳжҳҜеә”з”Ёдҫ§жқҘи§ЈеҶігҖӮеҰӮжһңжҳҜ Dynamo зі»з»ҹжқҘи§ЈеҶіпјҢйҖҡеёёдјҡж— и„‘йҖүжӢ©"еҗҺиҖ…иғң(last write win)"пјҢеҚідҪҝз”Ёиҫғж–°зҡ„жӣҙж”№иҰҶзӣ–еҒҸж—§зҡ„жӣҙж”№гҖӮеҰӮжһңдәӨз”ұеә”з”ЁжқҘи§ЈеҶіпјҢеҲҷеҸҜд»ҘдҫқжҚ®еә”з”ЁйңҖжұӮдҫҝе®ңиЎҢдәӢпјҢжҜ”еҰӮеҸҜд»ҘеҗҲ并еӨҡж¬ЎеӨҡж¬ЎеҠ иҙӯзү©иҪҰж“ҚдҪңиҝ”еӣһз»ҷз”ЁжҲ·гҖӮеҪ“然пјҢиҝҷдёӘжҳҜеҸҜйҖүзҡ„пјҢжҜ•з«ҹеҫҲеӨҡеә”з”ЁдҪҝз”ЁйҖҡз”Ёзӯ–з•ҘпјҲ"last write win"пјүе°ұи¶іеӨҹдәҶгҖӮ
е…¶д»–е…ій”®и®ҫи®ЎеҺҹеҲҷиҝҳжңүпјҡ
еўһйҮҸжү©еұ•пјҲincremental scalabilityпјүгҖӮж”ҜжҢҒиҠӮзӮ№зҡ„еҠЁжҖҒеўһеҲ пјҢиҖҢе°ҸеҢ–еҜ№зі»з»ҹе’Ңиҝҗз»ҙзҡ„еҪұе“ҚгҖӮ
еҜ№з§°жҖ§пјҲSymmetryпјүгҖӮзі»з»ҹдёӯзҡ„жҜҸдёӘиҠӮзӮ№иҒҢиҙЈзӣёеҗҢпјҢжІЎжңүзү№ж®ҠиҠӮзӮ№пјҢд»Ҙз®ҖеҢ–жһ„е»әе’Ңз»ҙжҠӨжҲҗжң¬гҖӮ
еҺ»дёӯеҝғеҢ–пјҲDecentralizationпјүгҖӮжІЎжңүдёӯеҝғжҺ§еҲ¶иҠӮзӮ№пјҢдҪҝз”ЁзӮ№еҜ№зӮ№зҡ„жҠҖжңҜд»ҘдҪҝзі»з»ҹй«ҳеҸҜз”ЁгҖҒжҳ“жү©еұ•гҖӮ
ејӮжһ„жҖ§пјҲHeterogeneityпјүгҖӮзі»з»ҹйңҖиҰҒиғҪеӨҹе……еҲҶеҲ©з”Ёиө„жәҗејӮжһ„зҡ„иҠӮзӮ№пјҢжқҘжҢүиҠӮзӮ№е®№йҮҸиҝӣиЎҢиҙҹиҪҪеҲҶй…ҚгҖӮ
зі»з»ҹжһ¶жһ„
еӣҙз»•еҲҶеҢәз®—жі•гҖҒеӨҮд»Ҫзӯ–з•ҘгҖҒзүҲжң¬жңәеҲ¶гҖҒжҲҗе‘ҳз»„з»ҮпјҢй”ҷиҜҜеӨ„зҗҶе’ҢеҸҜжү©еұ•жҖ§зӯүеҲҶеёғејҸжҠҖжңҜиҝӣиЎҢеұ•ејҖгҖӮ
зі»з»ҹжҺҘеҸЈ
Dynamo жҡҙйңІдёӨдёӘжҺҘеҸЈпјҡput() е’Ң get():
get(key) пјҡиҝ”еӣһ key еҜ№еә”зҡ„еҚ•дёӘ objectпјҢжҲ–иҖ…жңүжңүзүҲжң¬еҶІзӘҒзҡ„ object еҲ—иЎЁгҖӮ
put(key, context, object)пјҡж №жҚ® key йҖүеҮә object иҰҒж”ҫзҡ„еүҜжң¬жңәеҷЁпјҢ并е°Ҷж•°жҚ®иҗҪзӣҳгҖӮcontext дјҡеҢ…еҗ«дёҖдәӣеҜ№и°ғз”ЁиҖ…йҖҸжҳҺзҡ„зі»з»ҹе…ғдҝЎжҒҜпјҢжҜ”еҰӮ object зҡ„зүҲжң¬еҸ·дҝЎжҒҜгҖӮcontext дјҡе’Ң object дёҖеқ—еӯҳеӮЁд»ҘйӘҢиҜҒ put иҜ·жұӮзҡ„еҗҲжі•жҖ§гҖӮ
Dynamo е°Ҷ key е’Ң value йғҪи§Ҷдёәеӯ—иҠӮж•°з»„пјҢ并且еҜ№ key иҝӣиЎҢ MD5 з®—жі•д»Ҙз”ҹжҲҗдёҖдёӘ 128 дҪҚзҡ„ж ҮиҜҶз¬ҰпјҢд»ҘиҝӣиЎҢеӯҳеӮЁиҠӮзӮ№зҡ„йҖүжӢ©гҖӮ
еҲҶеҢәз®—жі•(Partitioning algorithm)
дёәдәҶж”ҜжҢҒеўһйҮҸејҸжү©е®№пјҢDynamo дҪҝз”ЁдёҖиҮҙжҖ§е“ҲеёҢз®—жі•иҝӣиЎҢиҙҹиҪҪеҲҶй…ҚгҖӮдҪҶеҹәжң¬зүҲзҡ„дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жңүдёӨдёӘзјәзӮ№пјҡ
- дёҚиғҪеӨҹеқҮеҢҖзҡ„еҲҶж‘ҠиҙҹиҪҪгҖӮ
- з…§йЎҫдёҚеҲ°дёҚеҗҢиҠӮзӮ№зҡ„иө„жәҗе·®ејӮгҖӮ
дёәдәҶи§ЈеҶідәӣй—®йўҳпјҢDynamo дҪҝз”ЁдәҶдёҖиҮҙжҖ§е“ҲеёҢзҡ„еҸҳз§Қпјҡеј•е…ҘиҷҡжӢҹиҠӮзӮ№гҖӮе…·дҪ“з®—жі•дёәпјҡ
- иҠӮзӮ№еңЁжҺҘе…Ҙзі»з»ҹж—¶пјҢж №жҚ®е…¶е®№йҮҸеӨ§е°Ҹз”ҹжҲҗзӣёеә”ж•°йҮҸзҡ„иҷҡжӢҹиҠӮзӮ№пјҢжҜҸдёӘиҷҡжӢҹиҠӮзӮ№йҡҸжңәеҲҶй…ҚдёҖдёӘиҠӮзӮ№зј–еҸ·гҖӮ
- жүҖжңүиҷҡжӢҹиҠӮзӮ№жҢүзј–еҸ·зҡ„еӨ§е°Ҹз»„з»ҮжҲҗдёҖдёӘйҰ–е°ҫзӣёжҺҘзҺҜзҠ¶з»“жһ„гҖӮ
- еҪ“жңүиҜ·жұӮеҲ°жқҘж—¶пјҢеңЁдёҺиҠӮзӮ№еҗҢж ·зҡ„зј–еҸ·з©әй—ҙеҶ…дҪҝз”Ё key еҠ жҹҗз§Қе“ҲеёҢз®—жі•з”ҹжҲҗдёҖдёӘж•°жҚ®зј–еҸ·гҖӮ
- ж №жҚ®жӯӨзј–еҸ·з»•зқҖиҷҡжӢҹиҠӮзӮ№зҺҜйЎәж—¶й’ҲжҹҘжүҫпјҢжүҫеҲ°дёӘиҷҡжӢҹиҠӮзӮ№жүҖеҜ№еә”зҡ„зү©зҗҶиҠӮзӮ№пјҢе°ҶиҜ·жұӮи·Ҝз”ұиҝҮеҺ»гҖӮ
- еҪ“жңүиҠӮзӮ№зҰ»ејҖж—¶пјҢеҸӘйңҖиҰҒ移йҷӨе…¶еҜ№еә”зҡ„иҷҡжӢҹиҠӮзӮ№еҚіеҸҜпјҢиҙҹиҪҪдҫҝдјҡиҮӘеҠЁйҮҚж–°з»•зқҖзҺҜиҝҒ移гҖӮ
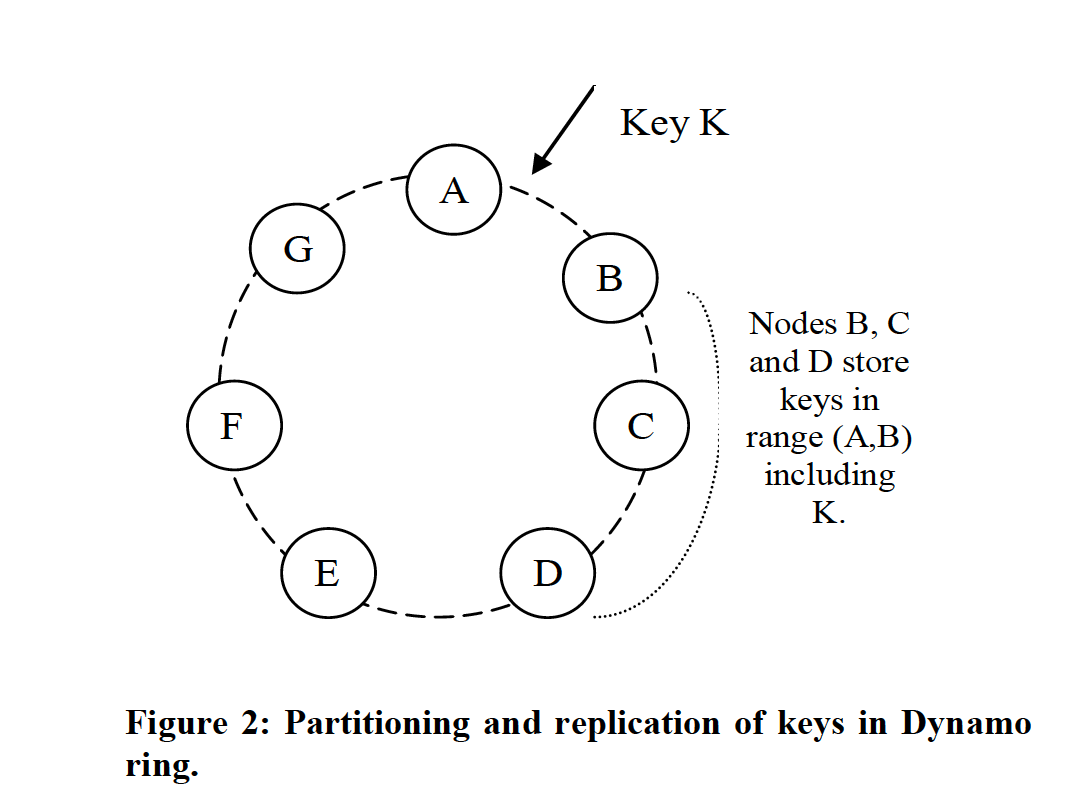
е…¶дёӯпјҢйҖҡиҝҮеҲҶй…ҚиҷҡжӢҹиҠӮзӮ№зҡ„ж•°йҮҸжқҘз…§йЎҫеҲ°дёҚеҗҢиҠӮзӮ№зҡ„е®№йҮҸе·®ејӮпјҢйҖҡиҝҮз”ҹжҲҗиҷҡжӢҹиҠӮзӮ№зј–еҸ·зҡ„йҡҸжңәз®—жі•дҝқиҜҒиҠӮзӮ№еўһеҲ ж—¶зҡ„жөҒйҮҸеқҮж‘ҠгҖӮ
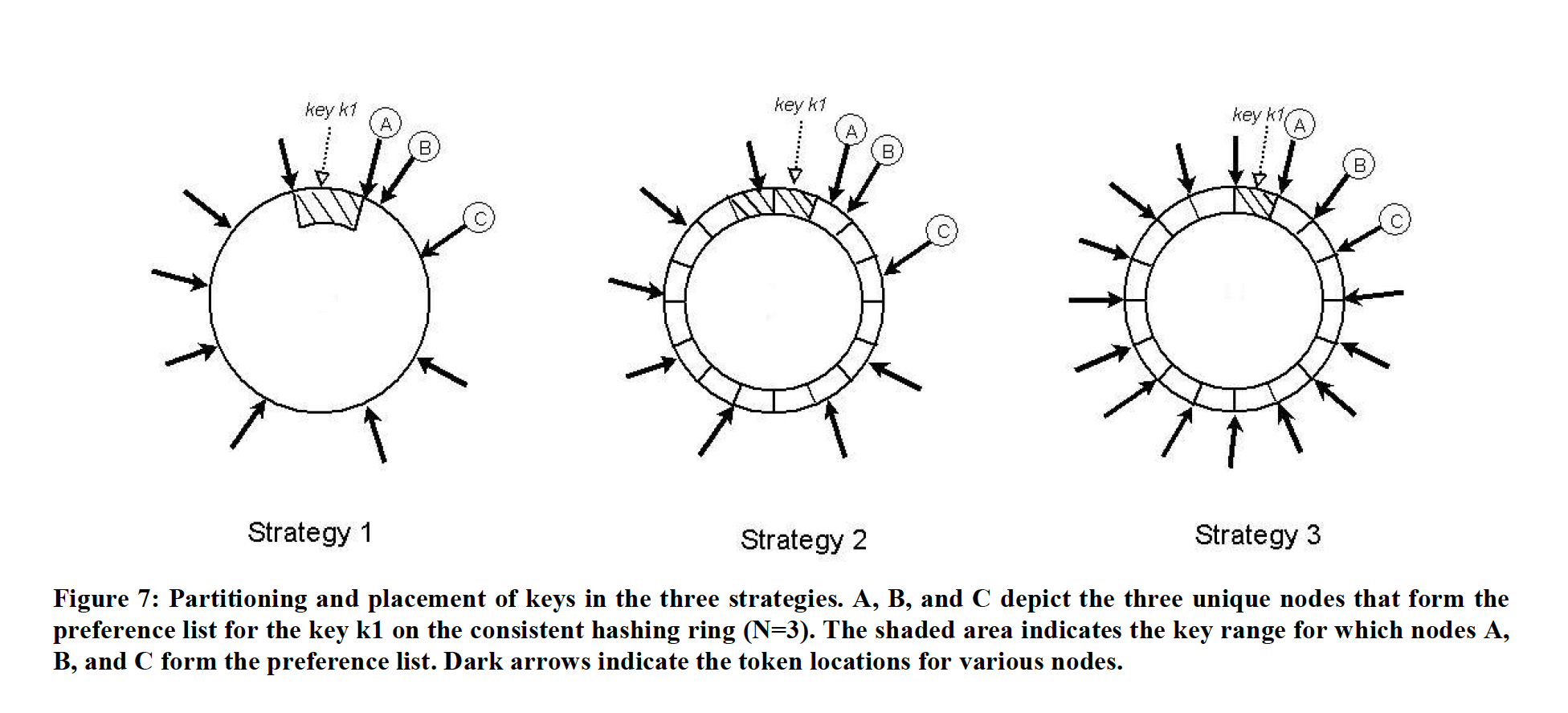
дёәдәҶз…§йЎҫиҠӮзӮ№зҡ„еўһеҲ гҖҒеӨҮд»Ҫзҡ„ж–№дҫҝпјҢDynamo е…ҲеҗҺдҪҝз”ЁдәҶдёүз§Қ Partition зӯ–з•Ҙпјҡ
-
жҜҸдёӘиҠӮзӮ№еҲҶй…Қ T дёӘйҡҸжңәзҡ„ж•°еҖјзј–еҸ·пјҲtokenпјүпјҢжҜҸдёӘиҷҡжӢҹиҠӮзӮ№дёҖдёӘ tokenпјҢе“ҲеёҢзҺҜдёӯзӣёйӮ»дёӨдёӘиҷҡжӢҹиҠӮзӮ№зҡ„ token жүҖеҚЎеҮәзҡ„еҢәй—ҙеҚідёәдёҖдёӘ partitionгҖӮ
иҝҷз§ҚеҲқзҡ„зӯ–з•Ҙжңүд»ҘдёӢеҮ дёӘзјәзӮ№пјҡ
-
иҝҒ移жү«жҸҸгҖӮеҪ“жңүж–°иҠӮзӮ№еҠ е…Ҙзі»з»ҹж—¶пјҢйңҖиҰҒд»Һе…¶д»–иҠӮзӮ№еҒ·иҝҮжқҘдёҖдәӣж•°жҚ®гҖӮиҝҷйңҖиҰҒжү«жҸҸж–°еўһиҷҡжӢҹиҠӮзӮ№еҗҺ继еҮ дёӘиҠӮзӮ№дёӯжүҖжңүж•°жҚ®жқЎзӣ®д»Ҙеҫ—еҲ°йңҖиҰҒиҝҒ移зҡ„ж•°жҚ®пјҲзҢңжөӢдёәдәҶ serve get иҜ·жұӮпјҢиҠӮзӮ№дёҠзҡ„ж•°жҚ®дёҖиҲ¬жҳҜжҢүз”ЁжҲ· key иҝӣиЎҢзҙўеј•з»„з»Үзҡ„пјҢиҖҢдёҚжҳҜ key зҡ„ hash еҖјпјҢеӣ жӯӨиҰҒиҺ·еҸ–жҹҗдёӘ hash еҖјж®өзҡ„ж•°жҚ®пјҢйңҖиҰҒе…Ёзӣҳжү«жҸҸпјүгҖӮиҝҷдёӘж“ҚдҪңжҢәйҮҚзҡ„пјҢдёәдәҶдҝқиҜҒеҸҜз”ЁжҖ§йңҖиҰҒйҷҚдҪҺиҝҒ移иҝӣзЁӢзҡ„иҝҗиЎҢжқғйҮҚпјҢдҪҶиҝҷдјҡдҪҝеҫ—иҝҒ移иҝҮзЁӢжҢҒз»ӯеҫҲд№…гҖӮ
-
Merkle Tree йҮҚж–°и®Ўз®—гҖӮMerkle Tree дёӢйқўдјҡи®ІеҲ°пјҢеҸҜзІ—зҗҶи§Јдёәд»ҘеҲҶеҢәдёәеҚ•дҪҚеҜ№ж•°жҚ®иҝӣиЎҢеұӮж¬ЎеҢ–зӯҫеҗҚгҖӮеҪ“жңүиҠӮзӮ№еҠ е…Ҙ/зҰ»ејҖйӣҶзҫӨж—¶пјҢдјҡеҜјиҮҙ key range зҡ„жӢҶеҲҶ/еҗҲ并пјҢиҝӣиҖҢеј•иө·еҜ№еә” Merkle Tree зҡ„йҮҚж–°и®Ўз®—пјҢиҝҷд№ҹжҳҜдёҖдёӘи®Ўз®—еҜҶйӣҶеһӢж“ҚдҪңпјҢдјҡеҜјиҮҙеҫҲйҮҚзҡ„йўқеӨ–иҙҹиҪҪпјҢеңЁзәҝдёҠзі»з»ҹдёӯдёҚиғҪеҝҚеҸ—гҖӮ
-
йҡҫд»Ҙе…ЁеұҖеҝ«з…§гҖӮз”ұдәҺж•°жҚ®еңЁзү©зҗҶиҠӮзӮ№дёӯзҡ„еҲҶеёғжҳҜжҢү key зҡ„е“ҲеёҢеҖјиҝӣиЎҢеҲҮеҲҶзҡ„пјҢеӣ жӯӨеңЁ key з©әй—ҙдёӯжҳҜж•Јд№ұзҡ„пјҢеҫҲйҡҫеңЁ key з©әй—ҙдёӯеҒҡе…ЁеұҖеҝ«з…§пјҢеӣ дёәиҝҷиҰҒжұӮжүҖжңүиҠӮзӮ№дёҠзҡ„ж•°жҚ®иҝӣиЎҢе…ЁеұҖеҪ’并жҺ’еәҸпјҢж•ҲзҺҮдҪҺдёӢгҖӮ
еҸҜд»ҘзңӢеҮәпјҢиҝҷз§Қзӯ–з•Ҙзҡ„ж №жң¬й—®йўҳеңЁдәҺпјҢж•°жҚ®еҲҶеҢәпјҲpartitionпјүе’Ңж•°жҚ®еҪ’зҪ®пјҲplacementпјүжҳҜиҖҰеҗҲеңЁдёҖеқ—зҡ„гҖӮиҝҷж ·жҲ‘们е°ұж— жі•еҚ•зӢ¬зҡ„еҜ№иҠӮзӮ№иҝӣиЎҢеўһеҲ иҖҢдёҚеҪұе“Қж•°жҚ®еҲҶеҢәгҖӮеӣ жӯӨпјҢдёҖдёӘеҫҲиҮӘ然зҡ„ж”№иҝӣжғіжі•жҳҜпјҢе°Ҷж•°жҚ®еҲҶеҢәдёҺж•°жҚ®еҪ’зҪ®зӢ¬з«ӢејҖжқҘгҖӮ
-
-
жҜҸдёӘиҠӮзӮ№д»ҚйҡҸжңәеҲҶй…Қ T дёӘзј–еҸ·пјҢдҪҶжҳҜе°Ҷе“ҲеёҢз©әй—ҙзӯүеҲҶдҪңдёәеҲҶеҢәгҖӮ
еңЁжӯӨзӯ–з•ҘдёӢпјҢиҠӮзӮ№зҡ„зј–еҸ·пјҲtokenпјүеҸӘжҳҜз”ЁжқҘжһ„е»әиҷҡжӢҹиҠӮзӮ№зҡ„е“ҲеёҢзҺҜпјҢиҖҢдёҚеҶҚз”ЁжқҘеҲҮеҲҶеҲҶеҢәгҖӮжҲ‘们е°Ҷе“ҲеёҢз©әй—ҙзӯүеҲҶдёә Q д»ҪпјҢQ >> S*TпјҢе…¶дёӯ S жҳҜзү©зҗҶиҠӮзӮ№ж•°гҖӮд№ҹе°ұжҳҜиҜҙжҜҸдёӘиҷҡжӢҹиҠӮзӮ№еҸҜд»Ҙж”ҫеҫҲеӨҡеҲҶеҢәгҖӮиҝҷз§Қзӯ–з•ҘеҸҜд»Ҙд»ҺеҸҰдёҖз§Қи§’еәҰжқҘзҗҶи§ЈпјҢеҚіиҠӮзӮ№ host зҡ„е°ҸеҚ•дҪҚдёҚеҶҚжҳҜ keyпјҢиҖҢжҳҜдёҖдёӘеҲҶеҢәпјҢжҜҸж¬ЎиҠӮзӮ№еўһеҲ ж—¶пјҢеҲҶеҢәдјҡж•ҙдҪ“иҝӣиЎҢ移еҠЁгҖӮиҝҷж ·е°ұи§ЈеҶідәҶеңЁиҠӮзӮ№еўһеҲ ж—¶пјҢиҝҒ移жү«жҸҸе’Ң Merkle Tree йҮҚж–°и®Ўз®—зҡ„й—®йўҳгҖӮ
еҜ№дәҺ key зҡ„ж”ҫзҪ®зӯ–з•ҘдёәпјҢжҜҸж¬Ў key иҝӣиЎҢи·Ҝз”ұж—¶пјҢйҰ–е…Ҳз®—еҮәе…¶е“ҲеёҢеҖјпјҢдҫқжҚ®е“ҲеёҢеҖјжүҖеңЁеҲҶеҢәпјҲkey rangeпјүзҡ„еҗҺдёҖдёӘе“ҲеёҢеҖјпјҢеңЁе“ҲеёҢзҺҜдёӯжҹҘжүҫгҖӮйЎәж—¶й’ҲйҒҮеҲ°зҡ„еүҚ N дёӘзү©зҗҶиҠӮзӮ№дҪңдёәеҒҸеҘҪеҲ—иЎЁгҖӮ
-
жҜҸдёӘиҠӮзӮ№ Q/S дёӘйҡҸжңәзј–еҸ·пјҢе“ҲеёҢз©әй—ҙзӯүеҲҶдҪңдёәеҲҶеҢәгҖӮ
иҝҷз§Қзӯ–з•ҘеңЁдёҠдёҖз§Қзҡ„еҹәзЎҖдёҠпјҢејәеҲ¶жҜҸдёӘзү©зҗҶиҠӮзӮ№жӢҘжңүзӯүйҮҸзҡ„еҲҶеҢәгҖӮз”ұдәҺ Q ж•°йҮҸпјҢз”ҡиҮіжҜҸдёӘиҠӮзӮ№жүҝиҪҪзҡ„еҲҶеҢәж•° пјҲQ/Sпјү зҡ„ж•°йҮҸиҝңеӨ§дәҺиҠӮзӮ№ж•°пјҲSпјүпјҢеӣ жӯӨеңЁиҠӮзӮ№зҰ»ејҖж—¶пјҢеҫҲе®№жҳ“е°Ҷе…¶жүҝиҪҪзҡ„иҠӮзӮ№ж•°еҲҶй…Қз»ҷе…¶д»–иҠӮзӮ№пјҢиҖҢд»Қ然иғҪз»ҙжҢҒиҜҘжҖ§иҙЁпјӣеҪ“жңүиҠӮзӮ№еҠ е…Ҙж—¶пјҢжҜҸдёӘиҠӮзӮ№з»ҷд»–еҢҖзӮ№д№ҹе®№жҳ“гҖӮ
еӨҮд»Ҫзӯ–з•Ҙ(Replication)
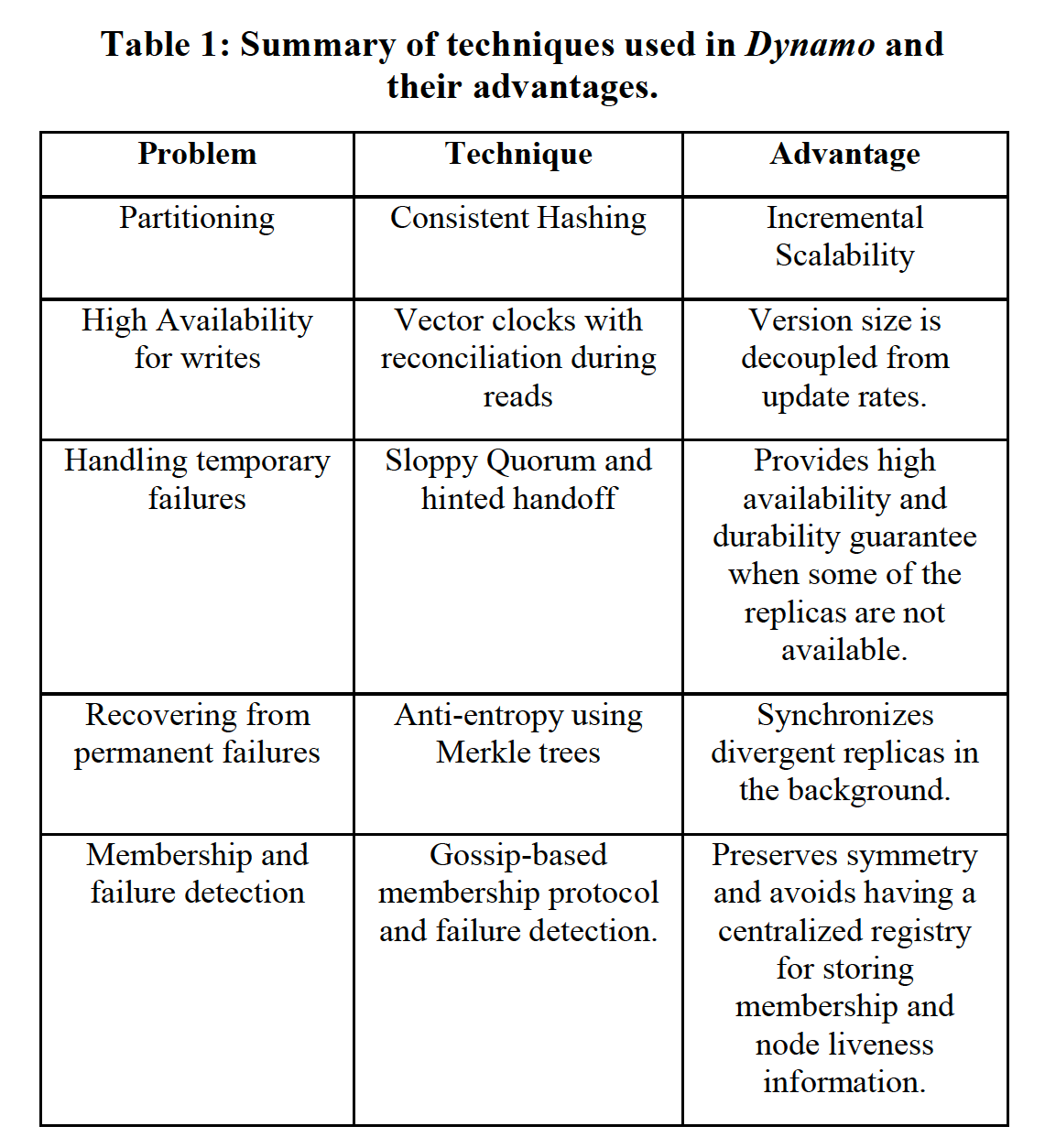
Dynamo дјҡе°ҶжҜҸжқЎж•°жҚ®еңЁ N дёӘиҠӮзӮ№дёҠиҝӣиЎҢеӨҮд»ҪпјҢе…¶дёӯ N жҳҜеҸҜд»Ҙй…ҚзҪ®зҡ„гҖӮеҜ№дәҺжҜҸдёӘ keyпјҢдјҡжңүдёҖдёӘеҚҸи°ғиҠӮзӮ№пјҲcoordinatorпјүжқҘиҙҹиҙЈе…¶еңЁеӨҡдёӘиҠӮзӮ№зҡ„еӨҮд»ҪгҖӮе…·дҪ“жқҘиҜҙпјҢеҚҸи°ғиҠӮзӮ№дјҡиҙҹиҙЈдёҖдёӘй”®еҢәж®ө пјҲkey rangeпјүгҖӮ
еңЁиҝӣиЎҢеӨҮд»Ҫж—¶пјҢеҚҸи°ғиҠӮзӮ№дјҡйҖүжӢ©дёҖиҮҙжҖ§е“ҲеёҢзҺҜдёҠпјҢйЎәж—¶й’Ҳж–№еҗ‘зҡ„еҗҺ继 N - 1 иҠӮзӮ№пјҢиҝһеҗҢе…¶жң¬иә«пјҢеҜ№ж•°жҚ®жқЎзӣ®иҝӣиЎҢ NеүҜжң¬еӯҳеӮЁпјҢеҰӮеӣҫдәҢжүҖзӨәгҖӮиҝҷ N дёӘиҠӮзӮ№иў«з§°дёәеҒҸеҘҪеҲ—иЎЁпјҲpreference listпјүгҖӮе…¶дёӯпјҡ
- key еҲ°иҠӮзӮ№зҡ„жҳ е°„ж №жҚ®дёҠиҝ°дёүз§ҚдёҚеҗҢзҡ„еҲҶеҢәзӯ–з•ҘиҖҢдёҚеҗҢгҖӮ
- иҠӮзӮ№еҸҜиғҪдјҡе®•жңәйҮҚеҗҜпјҢеҒҸеҘҪеҲ—иЎЁжңүж—¶еҖҷеҸҜиғҪдјҡеӨҡдәҺ N дёӘиҠӮзӮ№гҖӮ
- з”ұдәҺдҪҝз”Ёзҡ„жҳҜиҷҡжӢҹиҠӮзӮ№пјҢеҰӮжһңдёҚеҠ е№Іж¶үпјҢиҝҷ N дёӘиҠӮзӮ№еҸҜиғҪдјҡеҜ№еә”е°ҸдәҺ N дёӘзү©зҗҶжңәгҖӮдёәжӯӨпјҢжҲ‘们еңЁйҖүжӢ©иҠӮзӮ№зҡ„ж—¶еҖҷйңҖиҰҒиҝӣиЎҢи·ійҖүпјҢд»ҘдҝқиҜҒ N дёӘиҠӮзӮ№еӨ„дәҺ N еҸ°зү©зҗҶжңәдёҠгҖӮ
зүҲжң¬жңәеҲ¶(Data Versioning)
Dynamo жҸҗдҫӣз»ҲдёҖиҮҙжҖ§дҝқиҜҒпјҢд»ҺиҖҢе…Ғи®ёеӨҡеүҜжң¬иҝӣиЎҢејӮжӯҘеҗҢжӯҘпјҢжҸҗй«ҳеҸҜз”ЁжҖ§гҖӮеҰӮжһңжІЎжңүжңәеҷЁе’ҢзҪ‘з»ңж•…йҡңпјҢеӨҡеүҜжң¬е°ҶдјҡеңЁжңүйҷҗж—¶й—ҙеҶ…еҗҢжӯҘе®ҢжҜ•пјӣеҰӮжһңеҮәзҺ°ж•…йҡңпјҢеҸҜиғҪжңүдәӣеүҜжң¬пјҲreplicaпјүе°Ҷж°ёиҝңж— жі•жӯЈеёёе®ҢжҲҗеҗҢжӯҘгҖӮ
Dynamo жҸҗдҫӣд»»ж„Ҹж—¶еҲ»зҡ„еҸҜз”ЁжҖ§пјҢеҰӮжһңж–°зҡ„ж•°жҚ®дёҚиғҪз”ЁпјҢйңҖиҰҒжҸҗдҫӣж¬Ўж–°зҡ„гҖӮдёәдәҶжҸҗдҫӣиҝҷз§ҚдҝқиҜҒпјҢDynamo е°ҶжҜҸдёӘдҝ®ж”№и§ҶдёәдёҖдёӘж–°зүҲжң¬гҖҒдёҚеҸҜеҸҳж•°жҚ®гҖӮе®ғе…Ғи®ёеӨҡдёӘзүҲжң¬зҡ„ж•°жҚ®е№¶еӯҳпјҢеӨ§еӨҡж•°жғ…еҶөдёӢпјҢж–°зүҲжң¬ж•°жҚ®иғҪеӨҹеҜ№ж—§зүҲжң¬зҡ„иҝӣиЎҢиҰҶзӣ–пјҢд»ҺиҖҢи®©зі»з»ҹеҸҜд»ҘиҮӘеҠЁзҡ„жҢ‘йҖүеҮәжқғеЁҒзүҲжң¬пјҲsyntactic reconciliationпјҢиҜӯжі•е’Ңи§ЈпјүгҖӮдҪҶеҪ“еҸ‘з”ҹж•…йҡңжҲ–иҖ…еӯҳеңЁе№¶иЎҢж“ҚдҪңж—¶пјҢеҸҜиғҪдјҡеҮәзҺ°дә’зӣёеҶІзӘҒзҡ„зүҲжң¬еҲҶж”ҜпјҢжӯӨж—¶зі»з»ҹж— жі•иҮӘеҠЁиҝӣиЎҢеҗҲ并пјҢе°ұйЎ»дәӨз”ұе®ўжҲ·з«ҜжқҘиҝӣиЎҢеҗҲ并пјҲcollapseпјүеӨҡдёӘзүҲжң¬ж•°жҚ®пјҲиҜӯд№үе’Ңи§ЈпјҢsemantic reconciliationпјүгҖӮ
Dynamo дҪҝз”ЁдёҖз§ҚеҸ«еҒҡзҹўйҮҸж—¶й’ҹпјҲvector clockпјүзҡ„йҖ»иҫ‘ж—¶й’ҹжқҘиЎЁиҫҫеҗҢдёҖж•°жҚ®еӨҡдёӘзүҲжң¬й—ҙзҡ„еӣ жһңе…ізі»пјҲcausalityпјүгҖӮзҹўйҮҸж—¶й’ҹз”ұдёҖз»„ <иҠӮзӮ№пјҢ и®Ўж•°> еәҸеҲ—з»„жҲҗпјҢеҲҶеҲ«еҜ№еә”еҗҢдёҖж•°жҚ®зҡ„еҗҢжӯҘзүҲжң¬гҖӮеҸҜд»ҘйҖҡеӨҡдёӘж•°жҚ®зүҲжң¬зҡ„зҹўйҮҸж—¶й’ҹжқҘзЎ®е®ҡиҝҷдәӣж•°жҚ®зүҲжң¬й—ҙзҡ„е…ізі»пјҡжҳҜ并иЎҢеҸ‘з”ҹпјҲparallel branchesпјүиҝҳжҳҜеӯҳеңЁеӣ жһңпјҲcasual orderingпјүпјҡ
- еҰӮжһңзҹўйҮҸж—¶й’ҹ A дёӯзҡ„и®Ўж•°е°ҸдәҺзҹўйҮҸж—¶й’ҹ B дёӯжүҖжңүиҠӮзӮ№зҡ„и®Ўж•°пјҢеҲҷ A жҳҜ B зҡ„еүҚй©ұпјҢеҸҜд»Ҙиў«дёўејғгҖӮжҜ”еҰӮпјҢA дёә[<node1, 1>]пјҢB дёә [<node1, 1>, <node2, 2>, <node3, 1>]
- еҰӮжһң A дёҚжҳҜ B зҡ„еүҚй©ұпјҢB д№ҹдёҚжҳҜ A зҡ„еүҚй©ұпјҢеҲҷ A е’Ң B еӯҳеңЁзүҲжң¬еҶІзӘҒпјҢйңҖиҰҒиў«е’Ңи§ЈгҖӮ
еңЁ Dynamo дёӯпјҢе®ўжҲ·з«Ҝжӣҙж–°ж•°жҚ®еҜ№иұЎж—¶пјҢеҝ…йЎ»жҢҮжҳҺжүҖиҰҒжӣҙж–°зҡ„ж•°жҚ®еҜ№иұЎзҡ„зүҲжң¬гҖӮе…·дҪ“ж–№ејҸдёәе°Ҷд№ӢеүҚд»Һ Get дёӯиҺ·еҫ—зҡ„еҗҢдёҖж•°жҚ®еҜ№иұЎзҡ„зүҲжң¬дҝЎжҒҜпјҲvector clockпјүдј е…Ҙжӣҙж–°ж“ҚдҪңдёӯзҡ„ contextгҖӮеҗҢж ·зҡ„пјҢе®ўжҲ·з«ҜеңЁиҜ»еҸ–ж•°жҚ®ж—¶пјҢеҰӮжһңзі»з»ҹдёҚиғҪеӨҹиҝӣиЎҢиҮӘеҠЁеҗҲ并пјҲиҜӯжі•е’Ңи§ЈпјүпјҢеҲҷдјҡе°ҶеӨҡдёӘзүҲжң¬дҝЎжҒҜйҖҡиҝҮ context иҝ”еӣһз»ҷе®ўжҲ·з«ҜпјҢдёҖж—Ұе®ўжҲ·з«Ҝз”ЁжӯӨдҝЎжҒҜиҝӣиЎҢеҗҺз»ӯжӣҙж–°пјҢзі»з»ҹе°ұи®Өдёәе®ўжҲ·з«ҜеҜ№иҝҷеӨҡдёӘзүҲжң¬иҝӣиЎҢдәҶеҗҲ并пјҲиҜӯд№үе’Ңи§ЈпјүгҖӮдёӢеӣҫжҳҜдёҖдёӘиҜҰз»ҶдҫӢеӯҗгҖӮ
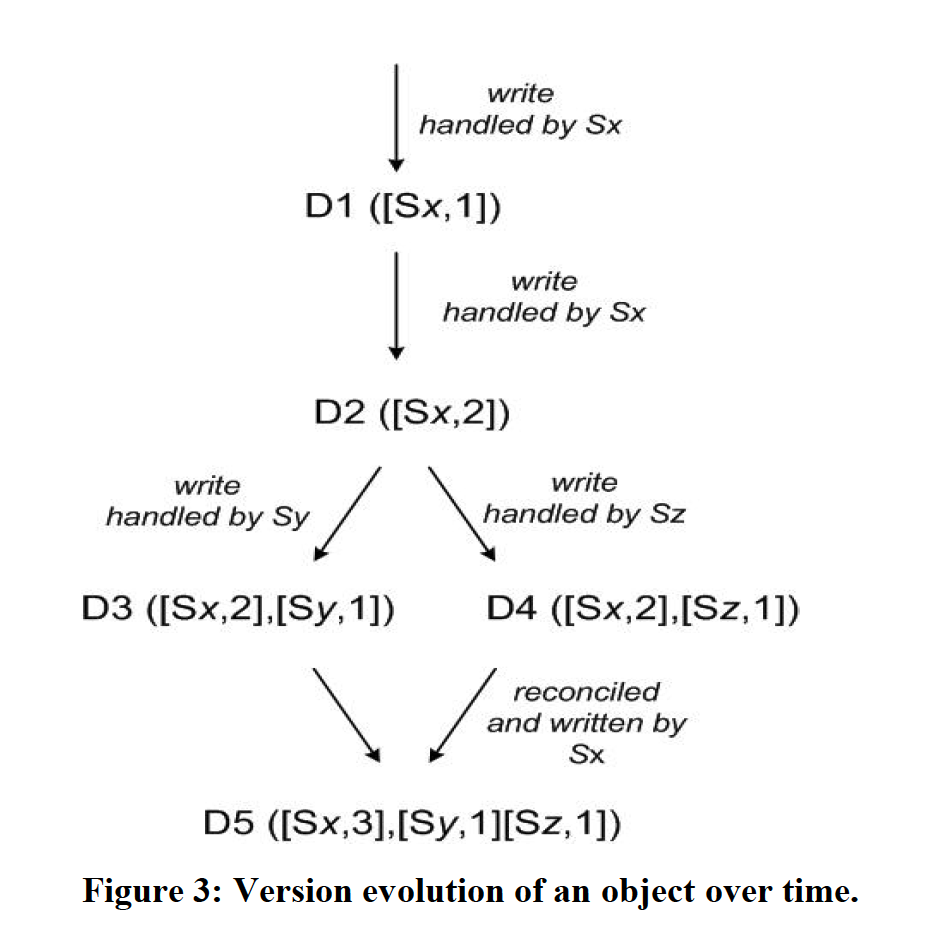
е…¶дёӯжңүеҮ зӮ№йңҖиҰҒжіЁж„Ҹпјҡ
- жҜҸдёӘжңҚеҠЎеҷЁиҠӮзӮ№з»ҙжҠӨдёҖдёӘиҮӘеўһзҡ„и®Ўж•°еҷЁпјҢеҪ“е…¶еӨ„зҗҶжӣҙж”№иҜ·жұӮеүҚпјҢжӣҙж–°и®Ўж•°еҷЁзҡ„еҖјгҖӮ
- дёәдәҶйҳІжӯўзҹўйҮҸж—¶й’ҹзҡ„е°әеҜёж— йҷҗеўһй•ҝпјҢе°Өе…¶жҳҜеҮәзҺ°зҪ‘з»ңеҲҶеҢәжҲ–иҖ…жңҚеҠЎеҷЁеӨұиҙҘж—¶пјҢDynamo зҡ„зӯ–з•ҘжҳҜпјҢзҹўйҮҸж—¶й’ҹеәҸеҲ—и¶…иҝҮдёҖе®ҡйҳҲеҖјж—¶пјҲжҜ”еҰӮиҜҙ 10пјүпјҢе°ҶеәҸеҲ—дёӯж—©зҡ„дёҖдёӘж—¶й’ҹеҜ№дёўејғгҖӮ
get() е’Ң put()
жң¬е°ҸиҠӮжҸҸиҝ°зі»з»ҹдёҚдә§з”ҹж•…йҡңж—¶зҡ„дәӨдә’гҖӮдё»иҰҒеҲҶдёәдёӨдёӘиҝҮзЁӢпјҡ
- з”Ёжҹҗз§Қж–№ејҸйҖүжӢ©дёҖдёӘ coordinatorгҖӮ
- coordinator дҪҝз”Ё quorum жңәеҲ¶иҝӣиЎҢж•°жҚ®еӨҡеүҜжң¬еҗҢжӯҘгҖӮ
йҖүжӢ© coordinator
Dynamo йҖҡиҝҮ HTTP ж–№ејҸеҜ№еӨ–жҡҙйңІжңҚеҠЎпјҢдё»иҰҒжңүдёӨз§Қзӯ–з•ҘжқҘиҝӣиЎҢ coordinator зҡ„йҖүжӢ©пјҡ
- дҪҝз”ЁдёҖдёӘиҙҹиҪҪеқҮиЎЎеҷЁжқҘйҖүеҮәдёҖдёӘиҙҹиҪҪиҫғиҪ»зҡ„иҠӮзӮ№гҖӮ
- дҪҝз”ЁеҸҜд»ҘиҝӣиЎҢеҲҶеҢәж„ҹзҹҘзҡ„е®ўжҲ·з«ҜпјҢзӣҙжҺҘи·Ҝз”ұеҲ°иҙҹиҙЈиҜҘ key зҡ„зӣёеә” coordinator пјҲеҚіеҒҸеҘҪеҲ—иЎЁдёӯзҡ„дёӘпјүгҖӮ
з§Қж–№ејҸе®ўжҲ·з«ҜдёҚз”ЁдҝқеӯҳжңҚеҠЎеҷЁиҠӮзӮ№дҝЎжҒҜпјҢ第дәҢз§Қж–№ејҸдёҚйңҖиҰҒиҪ¬еҸ‘пјҢ延иҝҹжӣҙдҪҺгҖӮ
еҜ№дәҺз§Қж–№ејҸпјҢеҰӮжһңжҳҜ put() иҜ·жұӮпјҢйҖүеҮәзҡ„иҠӮзӮ№ S дёҚеңЁеҲ—иЎЁ N дёӘиҠӮзӮ№дёӯпјҢS дјҡе°ҶиҜ·жұӮиҪ¬еҸ‘еҲ°еҒҸеҘҪеҲ—иЎЁдёӯдёҖдёӘжңәеҷЁдҪңдёә coordinatorгҖӮеҰӮжһңжҳҜ get() иҜ·жұӮпјҢдёҚз®Ў S еңЁдёҚеңЁеҒҸеҘҪеҲ—иЎЁдёӯпјҢйғҪеҸҜд»ҘзӣҙжҺҘдҪңдёә coordinatorгҖӮ
Quorum жңәеҲ¶
Quorum иҜ»еҶҷжңәеҲ¶жҳҜдёҖз§Қжңүж„ҸжҖқзҡ„иҜ»еҶҷж–№ејҸпјҢжңүдёӨдёӘе…ій”®й…ҚзҪ®еҸӮж•° R е’Ң WпјҢйҖҡеёё R е’Ң W йңҖиҰҒж»Ўи¶і1.R + W > N 2. W > N/2пјҢе…¶дёӯ N жҳҜйӣҶзҫӨеӨҮд»Ҫж•°гҖӮзҗҶи§Јж—¶еҸҜд»Ҙд»ҺдёӨдёӘи§’еәҰзҗҶи§ЈпјҢдёҖдёӘжҳҜзұ»жҜ”иҜ»еҶҷй”ҒпјҢеҚізі»з»ҹдёҚиғҪеҗҢж—¶жңүеӨҡдёӘеҶҷеҶҷгҖҒиҜ»еҶҷпјҢдҪҶжҳҜ R и®ҫзҪ®зҡ„е°ҸдёҖдәӣеҸҜд»ҘеҗҢж—¶жңүеӨҡдёӘиҜ»пјӣеҸҰдёҖдёӘжҳҜйңҖиҰҒеҚҠж•°д»ҘдёҠеҶҷжҲҗеҠҹпјҢд»Ҙж»Ўи¶іж•°жҚ®зҡ„жҢҒд№…еҢ–зү№жҖ§гҖӮдҪҶжҳҜеңЁ Dynamo иҝҷдәӣйғҪжІЎжңүзЎ¬жҖ§иҰҒжұӮпјҢз”ЁжҲ·еҸҜд»Ҙж №жҚ®йңҖжұӮзҒөжҙ»й…ҚзҪ®гҖӮ
еҪ“дёҖдёӘ put() иҜ·жұӮеҲ°иҫҫж—¶пјҢcoordinator дёәж–°ж•°жҚ®з”ҹжҲҗдёҖдёӘж–°зҡ„ vector clock зүҲжң¬дҝЎжҒҜпјҢ并е°Ҷе…¶еҶҷе…Ҙжң¬ең°пјҢ然еҗҺе°Ҷж•°жҚ®еҸ‘з»ҷ N дёӘеҒҸеҘҪзҡ„ replica иҠӮзӮ№пјҢзӯүеҲ° W-1 иҠӮзӮ№еӣһеӨҚпјҢеҚіеҸҜи®ӨдёәиҜ·жұӮжҲҗеҠҹгҖӮ
еҪ“дёҖдёӘ get() иҜ·жұӮеҲ°иҫҫж—¶пјҢcoodinator еҗ‘дҝқжңүиҜҘ key N дёӘиҠӮзӮ№пјҲеҢ…жӢ¬/дёҚеҢ…жӢ¬е®ғиҮӘе·ұпјүеҸ‘йҖҒиҜ·жұӮпјҢзӯүеҲ°е…¶дёӯ R дёӘиҠӮзӮ№иҝ”еӣһж—¶пјҢе°ҶеӨҡзүҲжң¬з»“жһңеҲ—иЎЁиҝ”еӣһз»ҷз”ЁжҲ·гҖӮ然еҗҺйҖҡиҝҮ vector clock 规еҲҷиҝӣиЎҢиҜӯжі•е’Ңи§ЈпјҢ并е°Ҷе’Ңи§ЈеҗҺзҡ„зүҲжң¬еҶҷеӣһгҖӮ
ж•…йҡңеӨ„зҗҶпјҡHinted Handoff
еҰӮжһңдҪҝз”ЁдёҘж јзҡ„ Quorum жңәеҲ¶еӨ„зҗҶиҜ»еҶҷпјҢйӮЈд№ҲеҚідҪҝеҸӘжңүе°‘йҮҸиҠӮзӮ№е®•жңәжҲ–иҖ…зҪ‘з»ңеҲҶеҢәд№ҹдјҡдҪҝеҫ—зі»з»ҹдёҚеҸҜз”ЁпјҢеӣ жӯӨ Dynamo дҪҝз”ЁдёҖз§Қ"зІ—з•Ҙд»ІиЈҒ"пјҲsloppy quorumпјүз®—жі•пјҢеҸҜд»ҘйҖүжӢ©дёҖиҮҙжҖ§е“ҲеёҢзҺҜдёӯеҲ—иЎЁзҡ„еүҚ N дёӘеҒҘеә·иҠӮзӮ№гҖӮ
并且еҪ“ coordinator пјҲжҜ”еҰӮиҜҙ Aпјүж•…йҡңж—¶пјҢиҜ·жұӮеңЁи·Ҝз”ұеҲ°е…¶д»–иҠӮзӮ№пјҲDпјүж—¶пјҢдјҡеңЁе…ғдҝЎжҒҜдёӯеёҰдёҠйҖүжӢ©пјҲA зҡ„дҝЎжҒҜпјүпјҢD еҗҺеҸ°дјҡжңүдёӘеёёй©»зәҝзЁӢпјҢжЈҖжөӢеҲ° A йҮҚж–°дёҠзәҝж—¶пјҢдјҡе°Ҷиҝҷдәӣжңүж Үи®°зҡ„ж•°жҚ®з§»еҲ°еҜ№еә”жңәеҷЁдёҠпјҢ并且еҲ йҷӨжң¬жңәзӣёеә”еүҜжң¬гҖӮDynamo йҖҡиҝҮиҝҷз§Қ hinted handoff зҡ„ж–№ејҸпјҢдҝқиҜҒжңүиҠӮзӮ№жҲ–зҪ‘з»ңж•…йҡңж—¶пјҢд№ҹиғҪжӯЈеёёе®ҢжҲҗиҜ·жұӮгҖӮ
еҪ“然пјҢжңҚеҠЎдёәдәҶй«ҳеҸҜз”ЁпјҢеҸҜд»Ҙе°Ҷ W и®ҫзҪ® 1пјҢиҝҷж ·еҲ—иЎЁдёӯд»»дҪ•иҠӮзӮ№еҸҜз”ЁпјҢйғҪеҸҜд»ҘеҶҷжҲҗеҠҹгҖӮдҪҶеңЁе®һи·өдёӯдёәдәҶдҝқиҜҒжҢҒд№…еҢ–пјҢдёҖиҲ¬йғҪдёҚдјҡи®ҫиҝҷд№ҲдҪҺгҖӮеҗҺйқўз« иҠӮе°ҶдјҡиҜҰиҝ° NпјҢR е’Ң W зҡ„й…ҚзҪ®й—®йўҳгҖӮ
жӯӨеӨ–пјҢдёәдәҶеӨ„зҗҶж•°жҚ®дёӯеҝғзә§еҲ«зҡ„ж•…йҡңпјҢDynamo йҖҡиҝҮй…ҚзҪ®дҪҝеҫ—иҠӮзӮ№еҲ—иЎЁи·Ёи¶ҠдёҚеҗҢдёӯеҝғпјҢд»ҘиҝӣиЎҢе®№зҒҫгҖӮ
ж•…йҡңеӨ„зҗҶпјҡеүҜжң¬еҗҢжӯҘ
Hinted Handoff еҸӘиғҪеӨ„зҗҶеҒ¶з„¶зҡ„гҖҒдёҙж—¶зҡ„иҠӮзӮ№е®•жңәй—®йўҳгҖӮдёәдәҶеӨ„зҗҶе…¶д»–жӣҙдёҘйҮҚзҡ„ж•…йҡңеёҰжқҘзҡ„дёҖиҮҙжҖ§й—®йўҳпјҢDynamo дҪҝз”ЁдәҶеҺ»дёӯеҝғеҢ–зҡ„еҸҚзҶөз®—жі•пјҲanti-entropyпјүжқҘиҝӣиЎҢеҲҶзүҮеүҜжң¬й—ҙзҡ„ж•°жҚ®еҗҢжӯҘгҖӮ
дёәдәҶеҝ«йҖҹжЈҖжөӢеүҜжң¬й—ҙж•°жҚ®жҳҜеҗҰдёҖиҮҙгҖҒ并且иғҪеӨҹе®ҡдҪҚеҲ°дёҚдёҖж ·зҡ„еҢәеҹҹпјҢDynamo дҪҝз”Ё Merkle Tree пјҲд№ҹеҸ«е“ҲеёҢж ‘пјҢеҢәеқ—й“ҫдёӯд№ҹз”ЁпјүжқҘд»ҘеҲҶзүҮдёәеҚ•дҪҚеҜ№еҲҶзүҮдёӯжүҖжңүж•°жҚ®иҝӣиЎҢеұӮеұӮзӯҫеҗҚгҖӮжүҖжңүеҸ¶еӯҗиҠӮзӮ№жҳҜзңҹе®һж•°жҚ®зҡ„ hash еҖјпјҢиҖҢжүҖжңүдёӯй—ҙиҠӮзӮ№жҳҜе…¶еӯ©еӯҗиҠӮзӮ№зҡ„е“ҲеёҢеҖјгҖӮиҝҷж ·зҡ„ж ‘жңүдёӨдёӘеҘҪеӨ„пјҡ
- еҸӘиҰҒжҜ”еҜ№ж №иҠӮзӮ№пјҢе°ұеҸҜд»ҘзҹҘйҒ“еҲҶзүҮзҡ„дёӨдёӘеүҜжң¬ж•°жҚ®жҳҜеҗҰдёҖиҮҙгҖӮ
- жҜҸдёӘдёӯй—ҙиҠӮзӮ№йғҪд»ЈиЎЁжҹҗдёӘиҢғеӣҙзҡ„жүҖжңүж•°жҚ®зҡ„зӯҫеҗҚпјҢеҸӘиҰҒе…¶зӣёзӯүпјҢеҲҷеҜ№еә”ж•°жҚ®дёҖиҮҙгҖӮ
- еҰӮжһңеҸӘжңүе°‘йҮҸдёҚдёҖиҮҙпјҢеҸҜд»Ҙд»Һж №иҠӮзӮ№еҮәеҸ‘пјҢиҝ…йҖҹе®ҡдҪҚеҲ°дёҚдёҖиҮҙзҡ„ж•°жҚ®дҪҚзҪ®гҖӮ
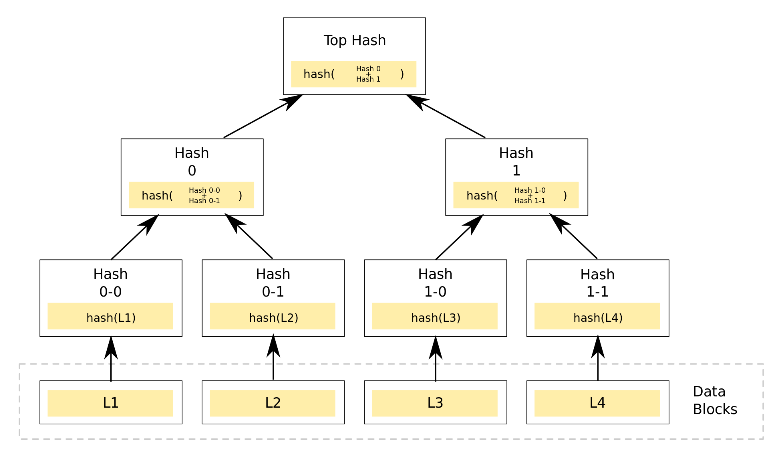
Dynamo еҜ№жҜҸдёӘж•°жҚ®еҲҶзүҮпјҲkey range or shardпјҢshard жҳҜе°Ҹзҡ„йҖ»иҫ‘еӯҳеӮЁеҚ•дҪҚпјүз»ҙжҠӨдёҖдёӘ Merkle TreeпјҢеҖҹеҠ©Merkle Tree зҡ„жҖ§иҙЁпјҢDynamo еҸҜд»ҘеҫҲеҝ«жҜ”иҫғдёӨдёӘж•°жҚ®еҲҶзүҮзҡ„еүҜжң¬ж•°жҚ®жҳҜеҗҰдёҖиҮҙгҖӮеҰӮжһңдёҚдёҖиҮҙпјҢеҸҜд»ҘйҖҡиҝҮе®ҡдҪҚдёҚдёҖиҮҙдҪҚзҪ®пјҢе°‘еҢ–ж•°жҚ®дј иҫ“гҖӮ
иҝҷж ·еҒҡзҡ„зјәзӮ№жҳҜпјҢеҰӮжһңжңүиҠӮзӮ№еҠ е…ҘжҲ–иҖ…зҰ»ејҖйӣҶзҫӨпјҢдјҡеј•иө·еӨ§йҮҸзҡ„ key range зҡ„еҸҳеҠЁпјҢд»ҺиҖҢйңҖиҰҒеҜ№еҸҳеҢ–зҡ„ key range йҮҚж–°и®Ўз®— Merkle TreeгҖӮеҪ“然пјҢеүҚйқўд№ҹи®Ёи®әдәҶпјҢж”№иҝӣеҗҺзҡ„еҲҶеҢәзӯ–з•Ҙж”№иҝӣдәҶиҝҷдёӘй—®йўҳгҖӮ
жҲҗе‘ҳе…ізі»е’Ңж•…йҡңжЈҖжөӢ
жҳҫејҸз®ЎзҗҶжҲҗе‘ҳе…ізі»гҖӮеңЁ Amazon зҡ„зҺҜеўғдёӯпјҢз”ұдәҺж•…йҡңжҲ–дәәдёәеӨұиҜҜйҖ жҲҗзҡ„иҠӮзӮ№зҰ»ејҖйӣҶзҫӨйҖҡеёёеҫҲе°‘пјҢжҲ–иҖ…дёҚдјҡжҢҒз»ӯеӨӘй•ҝж—¶й—ҙгҖӮеҰӮжһңжҜҸж¬ЎжңүиҠӮзӮ№дёӢзәҝйғҪз«ӢеҚіиҮӘеҠЁи°ғж•ҙж•°жҚ®еҲҶзүҮзҡ„ж”ҫзҪ®дҪҚзҪ®пјҢдјҡеј•иө·дёҚеҝ…иҰҒзҡ„ж•°жҚ®йңҮиҚЎиҝҒ移гҖӮеӣ жӯӨ Dynamo йҮҮз”ЁжҳҫејҸз®ЎзҗҶжҲҗе‘ҳзҡ„ж–№ејҸпјҢжҸҗдҫӣзӣёеә”жҺҘеҸЈз»ҷз®ЎзҗҶе‘ҳеҜ№зү©зҗҶиҠӮзӮ№иҝӣиЎҢдёҠдёӢзәҝгҖӮеҚіпјҢз”ұдәҺж•…йҡңеҜјиҮҙиҠӮзӮ№дёӢзәҝдёҚдјҡеј•иө·ж•°жҚ®еҲҶзүҮзҡ„移еҠЁгҖӮ
зұ» Gossip з®—жі•е№ҝж’ӯе…ғдҝЎжҒҜгҖӮжҲҗе‘ҳе…ізі»еҸҳеҠЁйҰ–е…Ҳз”ұеӨ„зҗҶжҲҗе‘ҳеўһеҲ иҜ·жұӮзҡ„иҠӮзӮ№ж„ҹзҹҘеҲ°пјҢжҢҒд№…еҢ–еҲ°жң¬ең°пјҢ然еҗҺеҲ©з”Ёзұ» Gossip з®—жі•иҝӣиЎҢе№ҝж’ӯпјҢжҜҸж¬ЎйҡҸжңәйҖүжӢ©дёҖдёӘиҠӮзӮ№иҝӣиЎҢдј ж’ӯпјҢз»ҲдҪҝеҫ—жүҖжңүжҲҗе‘ҳеҜ№жӯӨиҫҫжҲҗе…ұиҜҶгҖӮжӯӨеӨ–пјҢиҜҘз®—жі•д№ҹз”ЁдәҺиҠӮзӮ№еңЁеҲҡеҗҜеҠЁж—¶дәӨжҚўж•°жҚ®еҲҶзүҮдҝЎжҒҜе’Ңж•°жҚ®еҲҶеёғдҝЎжҒҜгҖӮ
жҜҸдёӘиҠӮзӮ№еҲҡеҗҜеҠЁж—¶пјҢеҸӘзҹҘйҒ“иҮӘе·ұзҡ„иҠӮзӮ№дҝЎжҒҜе’Ң token дҝЎжҒҜпјҢйҡҸзқҖеҗ„дёӘиҠӮзӮ№жёҗж¬ЎеҗҜеҠЁпјҢ并йҖҡиҝҮз®—жі•дә’зӣёдәӨжҚўдҝЎжҒҜпјҢеўһйҮҸзҡ„еңЁжҜҸдёӘиҠӮзӮ№еҲҶеҲ«жһ„е»әеҮәж•ҙдёӘе“ҲеёҢзҺҜзҡ„жӢ“жү‘пјҲkey range еҲ°иҷҡжӢҹиҠӮзӮ№пјҢиҷҡжӢҹиҠӮзӮ№еҲ°зү©зҗҶиҠӮзӮ№зҡ„жҳ е°„пјүгҖӮд»ҺиҖҢпјҢеҪ“жҹҗдёӘиҜ·жұӮеҲ°жқҘзҡ„ж—¶еҖҷпјҢеҸҜд»ҘзӣҙжҺҘиҪ¬еҸ‘еҲ°еҜ№еә”зҡ„еӨ„зҗҶиҠӮзӮ№гҖӮ
з§ҚеӯҗиҠӮзӮ№йҒҝе…ҚйҖ»иҫ‘еҲҶеҢәгҖӮеј•е…ҘеҠҹиғҪжҖ§зҡ„з§ҚеӯҗиҠӮзӮ№еҒҡжңҚеҠЎеҸ‘зҺ°пјҢжҜҸдёӘиҠӮзӮ№йғҪдјҡзӣҙиҝһз§ҚеӯҗиҠӮзӮ№пјҢд»ҘдҪҝеҫ—жҜҸдёӘеҠ е…Ҙзҡ„иҠӮзӮ№еҝ«йҖҹдёәе…¶д»–иҠӮзӮ№жүҖзҹҘпјҢйҒҝе…Қз”ұдәҺеҗҢж—¶еҠ е…ҘйӣҶзҫӨпјҢдә’дёҚзҹҘжҷ“пјҢеҮәзҺ°йҖ»иҫ‘еҲҶеҢәгҖӮ
ж•…йҡңжЈҖжөӢгҖӮдёәдәҶйҒҝе…Қе°Ҷ put/get иҜ·жұӮе’ҢеҗҢжӯҘе…ғдҝЎжҒҜиҜ·жұӮжҢҒз»ӯиҪ¬еҸ‘еҲ°дёҚеҸҜиҫҫиҠӮзӮ№пјҢд»…дҪҝз”ЁеұҖйғЁзҡ„ж•…йҡңжЈҖжөӢе°ұи¶іеӨҹдәҶгҖӮеҚіеҰӮжһң A еҸ‘еҗ‘ B зҡ„иҜ·жұӮеҫ—еҲ°дёҚеҲ°еӣһеә”пјҢA е°ұе°Ҷ B ж Үи®°дёәж•…йҡңпјҢ然еҗҺејҖеҗҜеҝғи·іпјҢд»Ҙж„ҹзҹҘе…¶жҒўеӨҚгҖӮеҰӮжһң A 收еҲ°еә”иҜҘиҪ¬еҗ‘ B зҡ„иҜ·жұӮпјҢ并且еҸ‘зҺ° B ж•…йҡңпјҢе°ұдјҡеңЁиҜҘ key еҜ№еә”зҡ„иҠӮзӮ№еҲ—иЎЁдёӯйҖүжӢ©дёҖдёӘжӣҝд»ЈиҠӮзӮ№гҖӮ
еҸҜд»ҘзңӢеҮәпјҢDynamo е°ҶиҠӮзӮ№зҡ„зҰ»ејҖе’ҢжҡӮж—¶зҰ»ејҖеҲҶејҖеӨ„зҗҶгҖӮдҪҝз”ЁжҳҫзӨәжҺҘеҸЈжқҘеўһеҲ жҲҗе‘ҳпјҢ并е°ҶжҲҗе‘ҳжӢ“жү‘йҖҡиҝҮ gossip з®—жі•иҝӣиЎҢе№ҝж’ӯпјӣдҪҝз”Ёз®ҖеҚ•ж Үи®°е’Ңеҝғи·іжқҘеӨ„зҗҶеҒ¶еҸ‘ж•…йҡңпјҢеҗҲзҗҶиҝӣиЎҢжөҒйҮҸиҪ¬еҸ‘гҖӮеңЁж•…йҡңиҫғе°‘зҡ„зҺҜеўғйҮҢпјҢеҰӮжӯӨеҲҶиҖҢжІ»д№ӢпјҢиғҪеӨ§еӨ§жҸҗй«ҳиҫҫжҲҗдёҖиҮҙзҡ„ж•ҲзҺҮпјҢеӨ§йҷҗеәҰйҒҝе…ҚиҠӮзӮ№еҒ¶еҸ‘ж•…йҡңе’ҢзҪ‘з»ңйҳөжі•жҠ–еҠЁеј•иө·зҡ„дёҚеҝ…иҰҒзҡ„ж•°жҚ®жҗ¬иҝҒгҖӮ
еўһеҲ иҠӮзӮ№
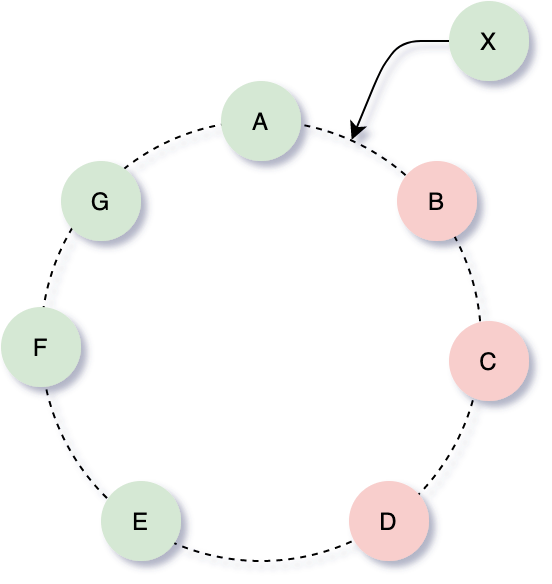
еҰӮдёӢеӣҫпјҢиҖғиҷ‘дёүеүҜжң¬пјҲN=3пјү并且йҮҮз”Ёз®ҖеҚ•зҡ„еҲҶеҢәзӯ–з•Ҙзҡ„жғ…еҶөдёӢпјҢеҪ“еңЁеңЁиҠӮзӮ№ A е’Ң B й—ҙеҠ е…ҘдёҖдёӘиҠӮзӮ№ X ж—¶пјҢX е°ҶдјҡиҙҹиҙЈ Key Rangeпјҡ (F,G]пјҢ(G, A]пјҢ(A, X] пјҢеҗҢж—¶ B е°ҶдёҚеҶҚиҙҹиҙЈ (F,G]пјҢC е°ҶдёҚеҶҚиҙҹиҙЈ(G, A]пјҢD е°ҶдёҚеҶҚиҙҹиҙЈ (A, X] пјҢDynamo йҖҡиҝҮ BпјҢCпјҢD дё»еҠЁеҗ‘ X жҺЁйҖҒзӣёе…і Key Range зҡ„ж–№ејҸжқҘйҖӮеә” X зҡ„еҠ е…ҘгҖӮеңЁжҺЁйҖҒеүҚжңүдёӘзӯүеҫ… X зЎ®и®Өйҳ¶ж®өпјҢд»ҘйҒҝе…ҚйҮҚеӨҚжҺЁйҖҒгҖӮ
е®һзҺ°
Dynamo дёӯжҜҸдёӘиҠӮзӮ№дё»иҰҒеҢ…жӢ¬еӣӣдёӘ组件пјҡиҜ·жұӮеҚҸи°ғпјҲrequest coordinationпјүпјҢжҲҗе‘ҳз®ЎзҗҶпјҲmembershipпјүпјҢж•…йҡңжЈҖжөӢпјҲfailure detectionпјүе’ҢдёҖдёӘжң¬ең°зҡ„жҢҒд№…еҢ–еј•ж“ҺпјҲlocal persistence engineпјүгҖӮжүҖжңү组件йғҪжҳҜз”Ё Java е®һзҺ°зҡ„гҖӮ
Dynamo зҡ„жң¬ең°жҢҒд№…еҢ–组件пјҢе…Ғи®ёйҖүжӢ©еӨҡз§Қеј•ж“ҺпјҢеҢ…жӢ¬ Berkeley DatabaseпјҲBDBпјүпјҢMySQL е’ҢдёҖдёӘеҹәдәҺеҶ…еӯҳ+жҢҒд№…еҢ–зҡ„еӯҳеӮЁгҖӮз”ЁжҲ·еҸҜд»Ҙж №жҚ®дёҡеҠЎеңәжҷҜиҝӣиЎҢйҖүжӢ©пјҢеӨ§йғЁеҲҶзҡ„з”ҹдә§зҺҜеўғдҪҝз”Ё BDB гҖӮ
иҜ·жұӮеҚҸи°ғ组件дҪҝз”Ё Java NIO йҖҡйҒ“е®һзҺ°пјҢйҮҮз”ЁдәӢ件й©ұеҠЁжЁЎеһӢпјҢе°ҶдёҖдёӘж¶ҲжҒҜзҡ„еӨ„зҗҶиҝҮзЁӢиў«еҲҶдёәеӨҡдёӘйҳ¶ж®өгҖӮеҜ№дәҺжҜҸдёӘеҲ°жқҘзҡ„иҜ»еҶҷиҜ·жұӮйғҪдјҡеҲқе§ӢеҢ–дёҖдёӘзҠ¶жҖҒжңәжқҘеӨ„зҗҶгҖӮжҜ”еҰӮеҜ№дәҺиҜ»иҜ·жұӮжқҘиҜҙпјҢе®һзҺ°дәҶд»ҘдёӢзҠ¶жҖҒжңәпјҡ
- еҸ‘йҖҒиҜ·жұӮеҲ°еҢ…еҗ« key жүҖеңЁеҲҶзүҮзҡ„еүҜжң¬зҡ„жүҖжңүиҠӮзӮ№гҖӮ
- зӯүеҫ…иҜ»иҜ·жұӮе°ҸиҰҒжұӮзҡ„иҠӮзӮ№ж•°пјҲRпјүдёӘиҠӮзӮ№иҝ”еӣһгҖӮ
- еңЁи®ҫе®ҡж—¶йҷҗеҶ…пјҢжІЎжңү收йӣҶеҲ° R дёӘиҜ·жұӮпјҢиҝ”еӣһе®ўжҲ·з«ҜеӨұиҙҘж¶ҲжҒҜгҖӮ
- еҗҰеҲҷ收йӣҶжүҖжңүзүҲжң¬ж•°жҚ®пјҢ并еҶіе®ҡйңҖиҰҒиҝ”еӣһзҡ„зүҲжң¬ж•°жҚ®гҖӮ
- еҰӮжһңеҗҜз”ЁдәҶзүҲжң¬жҺ§еҲ¶пјҢе°ұдјҡиҝӣиЎҢиҜӯжі•е’Ңи§ЈпјҢ并е°Ҷе’Ңи§ЈеҗҺзүҲжң¬еҶҷе…ҘдёҠдёӢж–ҮгҖӮ
еңЁиҜ»зҡ„иҝҮзЁӢдёӯпјҢеҰӮжһңеҸ‘зҺ°жҹҗдәӣеүҜжң¬ж•°жҚ®иҝҮжңҹдәҶпјҢдјҡйЎәеёҰе°Ҷе…¶жӣҙж–°пјҢиҝҷеҸ«еҒҡиҜ»дҝ®еӨҚпјҲread repairпјүгҖӮ
еҜ№дәҺеҶҷиҜ·жұӮпјҢе°Ҷдјҡз”ұ N дёӘиҠӮзӮ№дёӯзҡ„дёҖдёӘдҪңдёәеҚҸи°ғиҖ…иҝӣиЎҢеҚҸи°ғпјҢйҖҡеёёжҳҜдёӘгҖӮдҪҶдёәдәҶжҸҗй«ҳеҗһеҗҗпјҢеқҮиЎЎиҙҹиҪҪпјҢйҖҡеёёиҝҷ N дёӘиҠӮзӮ№йғҪеҸҜд»ҘдҪңдёәеҚҸи°ғиҖ…гҖӮе°Өе…¶жҳҜпјҢеӨ§йғЁеҲҶж•°жҚ®еңЁиҜ»еҸ–д№ӢеҗҺпјҢйҖҡеёёдјҡзҙ§и·ҹзқҖеҶҷе…ҘпјҲиҜ»еҸ–иҺ·еҸ–зүҲжң¬пјҢ然еҗҺдҪҝз”ЁеҜ№еә”зүҲжң¬иҝӣиЎҢеҶҷе…ҘпјүпјҢеӣ жӯӨеёёе°ҶеҶҷе…Ҙи°ғеәҰеҲ°дёҠж¬ЎиҜ»еҸ–дёӯеӣһеӨҚеҝ«зҡ„иҠӮзӮ№пјҢиҜҘиҠӮзӮ№дҝқеӯҳдәҶиҜ»еҸ–ж—¶зҡ„дёҠдёӢж–ҮдҝЎжҒҜпјҢд»ҺиҖҢиғҪжӣҙеҝ«е“Қеә”пјҢжҸҗй«ҳеҗһеҗҗгҖӮ
