KunlunBase 数据库集群在数据库内部支持读写分离,并且对应用透明,用户应用程序不需要做任何修改就可以使用数据库的读写分离功能,从而提高整个系统性能及投资回报率。
一、产品架构
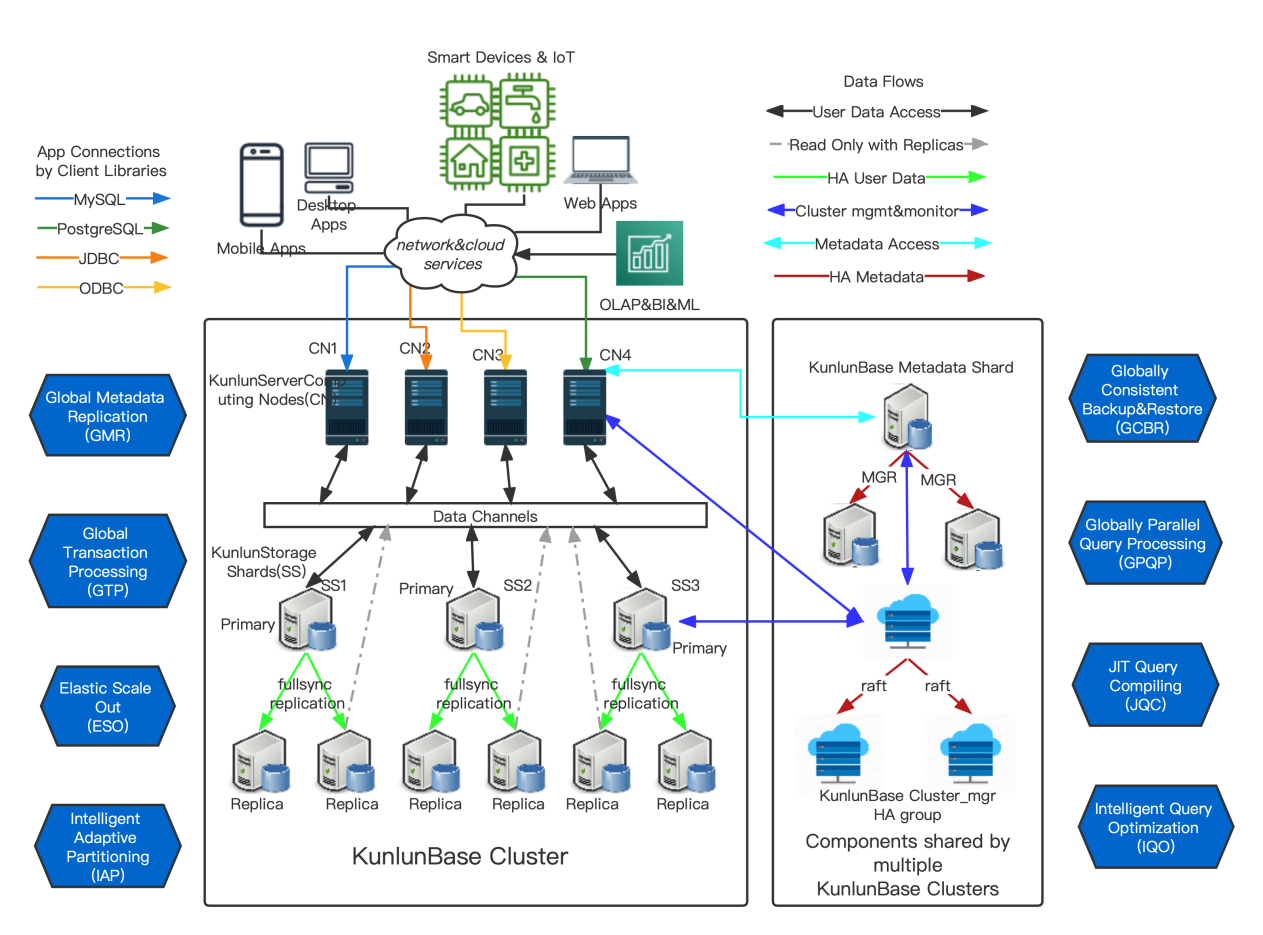
KunlunBase 的整体架构主要由计算层和存储层构成,计算层负责 SQL 响应、解释、执行等,存储层负责数据的存储管理,存储层的数据采用多副本存储机制,备机(从副本)通过强同步技术保持数据与主节点一致性。
备机的存储节点的硬件配置与主节点一致,在一般的生产使用过程中,备机节点的主要目的是作为主机出现故障后的替换节点,不接受应用程序的直接数据处理请求,因此,在非故障切换的情况下,备机的存储节点资源利用率相对较低。
KunlunBase 的读写分离方案是通过路由只读操作到备节点,从而可以减少计算节点的资源竞争,降低主节点负载。
二、实现原理
KunlunBase 的读写分离在计算层的远程查询优化器内实现的,当用户的SQL同时满足如下条件:
- 当前SQL类型为select;
- SQL中不包含用户自定义函数(即create function语句创建的函数),除非当前事务为只读事务;
- 如果不在事务中(autocommit=on),则允许读写分离;如果语句在显示事务中,则要满足:
- 如果在只读事务中,则允许读写分离;
- 如果在读写事务中,则该事务尚未更新过任何数据;
远程查询优化器就会将相应的SQL 执行计划下发到从备机的节点上执行
KunlunServer 会根据以下规则选择发送select语句到目标存储集群的哪个备机节点:
- 根据节点权重值选择 (ro_weight)
- 根据网络延迟(ping)
- 根据主从副本的数据一致性延迟(latency)
三、配置实施
场景说明:某 OLTP 业务系统有大量的查询操作,在业务高峰期数据库响应速度变慢,导致了业务的性能问题。经检查发现存储节点主节点的存储节点的 IO 资源利用到达瓶颈,但备机节点的 IO 资源利用率低。
以上场景可以通过读写分离方案解决系统性能问题,不需要修改应用, 不需要增加硬件配置,通过读写分离的实施,可以解决性能问题。
实施步骤:
步:设置参数,启用读写分离。(根据情况选一种级别)
设置 enable_replica_read = on (on 开启读写, off 关闭)。
用户级别开启:(用户登录后生效)
alter user abc set
enable_replica_read = true;
Session 级别开启:(当前 session 生效)
set enable_replica_read=on;
数据库级别开启:(对该计算节点的所有session有效)
在 pg_hba.conf 文件中设置
enable_replica_read=on;
第二步:登录数据库,配置读写分离策略。
设置如下参数,启动读写分离策略:
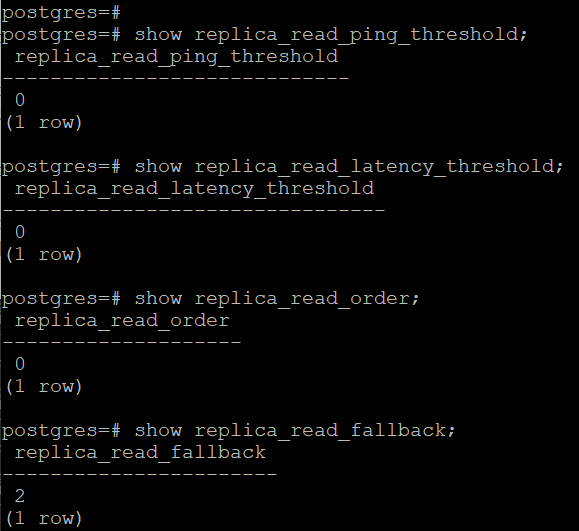
replica_read_ping_threshold,计算节点到备节点的ping延迟阈值,0表示不关心;replica_read_latency_threshold,主备同步延迟的阈值,0表示不关系;replica_read_order,选择备机优先级:0,按权重;1、按ping延迟;2、按主备同步延迟;replica_read_fallback,备机选择的回退策略(如果备机不能访问);replica_read_fallback=0,直接报错,replica_read_fallback=1,任意选择一个备机进行访问,replica_read_fallback=2,选择主机进行访问。
第三步:检查&设置权重(可选)。
在演示的环境中 ,数据集群由两个 shard 组成(shard1 , shard2) ,shard1 的shard_id=1, shard1 包含3个副本(id 为1,2, 3,id为1的是主节点,id为2和3的是备机。
通过配置, 可以设置只读操作的首先备机
设置 Shard1 的 node3 主机的作为首先备机(因为node2节点位于不同机房,延迟太高):
update pg_shard_node set ro_weight=2 where
port=6006;
Select * from pg_shard_node ;
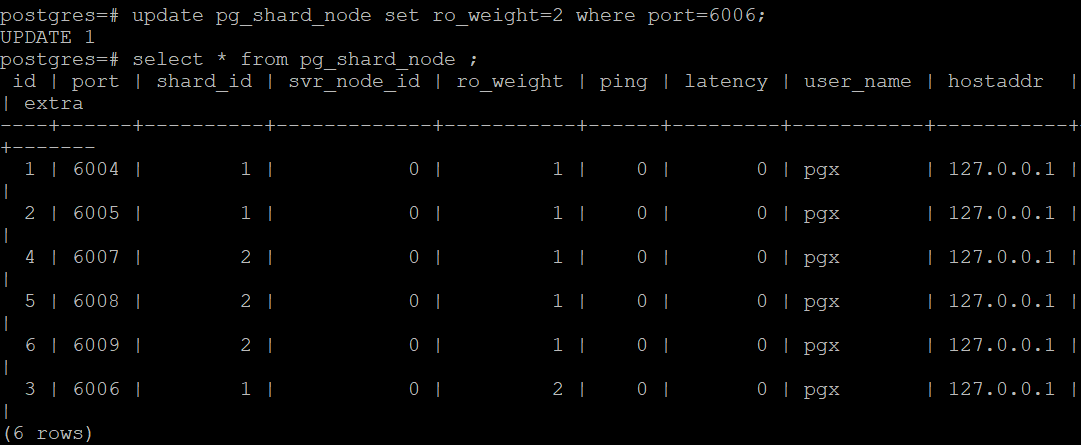
Shard1 的 node3 的权重高(ro_weight=2)
第四步:执行查询,验证读写分离(可选)。

通过设置log_min_messages to ‘debug1’ 可以将 SQL 语句的执行信息输出到日志中, 以方便检查 SQL 下发的目标存储节点(生产系统不要设置,否则影响性能)。
查看计算节点的日志,确认读写分离。

SQL 只读语句(select ti.id from t1) 被下发到 shard1,节点3上(该副本权重高), 而update 语句(update t1 set id=3) 是在主节点 shard1 节点1上执行。
结论
以上过程验证了该用户的读写操作分离实现。只读语句将被路由到从备机节点,降低了主节点的IO资源利用率,系统整体性能获得提升。
推荐阅读
KunlunBase架构介绍
KunlunBase技术优势介绍
KunlunBase技术特点介绍
KunlunBase集群基本概念介绍
昆仑数据库是一个HTAP NewSQL分布式数据库管理系统,可以满足用户对海量关系数据的存储管理和利用的全方位需求。
应用开发者和DBA的使用昆仑数据库的体验与单机MySQL和单机PostgreSQL几乎完全相同,因为首先昆仑数据库支持PostgreSQL和MySQL双协议,支持标准SQL:2011的 DML 语法和功能以及PostgreSQL和MySQL对标准 SQL的扩展。同时,昆仑数据库集群支持水平弹性扩容,数据自动拆分,分布式事务处理和分布式查询处理,健壮的容错容灾能力,完善直观的监测分析告警能力,集群数据备份和恢复等 常用的DBA 数据管理和操作。所有这些功能无需任何应用系统侧的编码工作,也无需DBA人工介入,不停服不影响业务正常运行。
昆仑数据库具备全面的OLAP 数据分析能力,通过了TPC-H和TPC-DS标准测试集,可以实时分析新的业务数据,帮助用户发掘出数据的价值。昆仑数据库支持公有云和私有云环境的部署,可以与docker,k8s等云基础设施无缝协作,可以轻松搭建云数据库服务。
请访问 http://www. kunlunbase.com/ 获取更多信息并且下载昆仑数据库软件、文档和资料。
KunlunBase项目已开源
【GitHub:】
https://github.com/zettadb
【Gitee:】
https://gitee.com/zettadb
