Mutex是10G新增的锁机制,目前专用于保护共享池中的对象。理解Mutex的机制,对于理解共享池的争用,意义巨大。Mutex和Latch的实再方式有类似之处,它们都用到了“原子”操作。什么是计算机中的原子操作?先从这一部分开始吧。
第 一 部分 原子操作
理解Mutex的重要基础,就是要理解原子操作。咱们作DBA的,不一定每个人都对底层有了解,下面我先用一系列图片,帮助大家了解什么是原子操作、为什么需要原子操作。 所谓锁,简单点说就是一个标志,比如一个内存变量,LK。如果LK等于0,相当于没有锁,LK等于1,相当于加锁。 一个进程要加锁的话,先判断LK变量的值是否为0,如果为0了,证明别人还没有加锁,把LK值改为1,加锁成功。代码如下形式: If ( LK == 0 ) { LK=1; } Else { 加锁不成功; } 这段代码很简单,我想无论用什么语言来描述,大家理解起来应该都没有问题。用一张流程图来表示,如下:
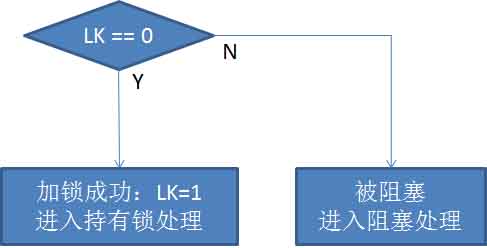
图1 M1.jpg
但是,考虑一下并发环境,有两个进程A与B,同时要求加锁:
图2 M2.jpg
A、B两进程在同一时刻要求加锁:
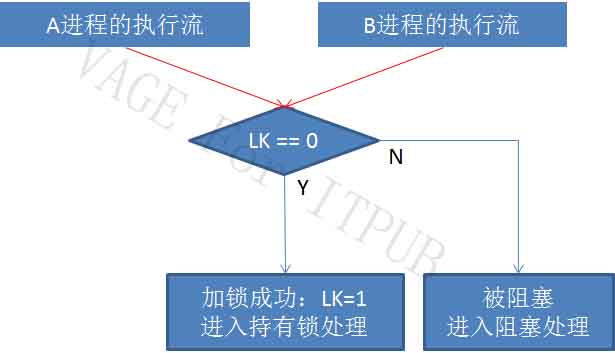
图3 M3.jpg
如上图所示,A、B同时执行if ( LK ==0 ) 。注意,if ( LK ==0 )在底层可不是一条语句,而是会变成如下多条指令:
1、读出LK变量的值 2、比较读出的值是否为0
A、B两进程同时执行if ( LK == 0 )的话,流程如下图:
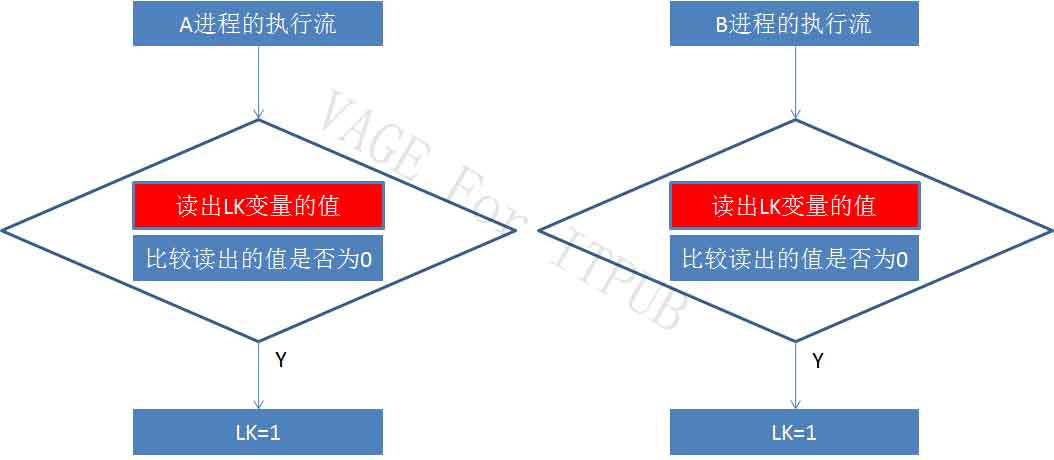
图4 m4.jpg
假设两个进程同时执行到图中红色区域:读出LK变量的值。两个进程读出的值都是0,接下,两进程又同时执行判断:
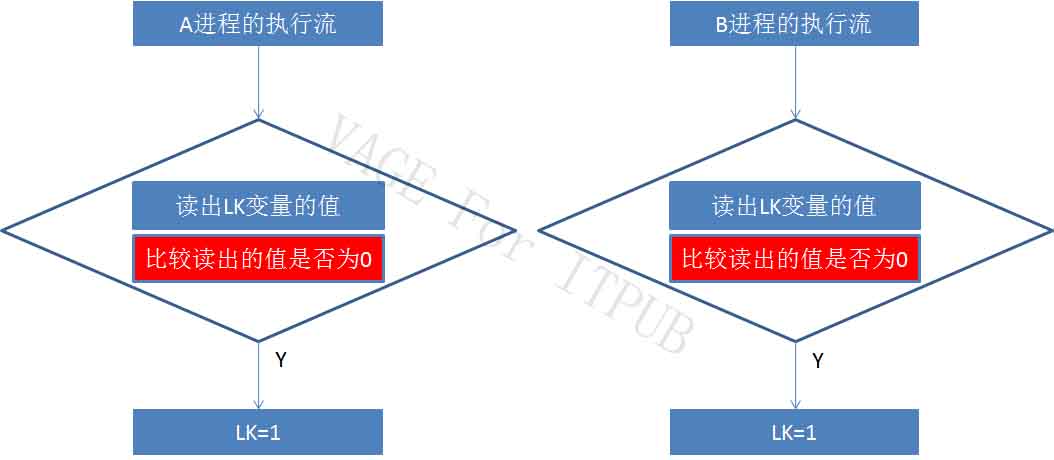
图5 M5.jpb
两个进程判断的结果是一样的,LK值为0。接下来,如下图:
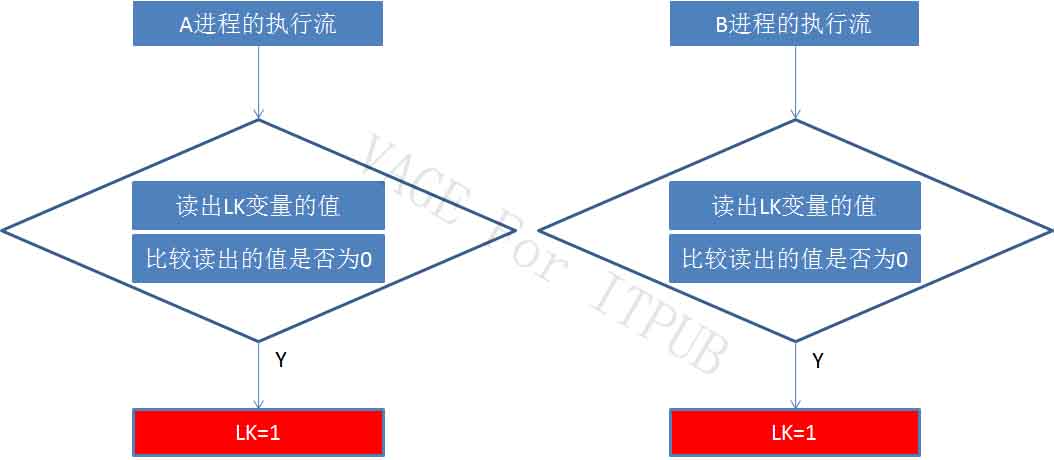
图6 M6.jpg
两个进程同时将LK的值设值为1。然后两个进程都认为只有自己得到了锁,这不就有问题了,因为只有一个进程可以得到锁。问题如何解决呢?如下图:
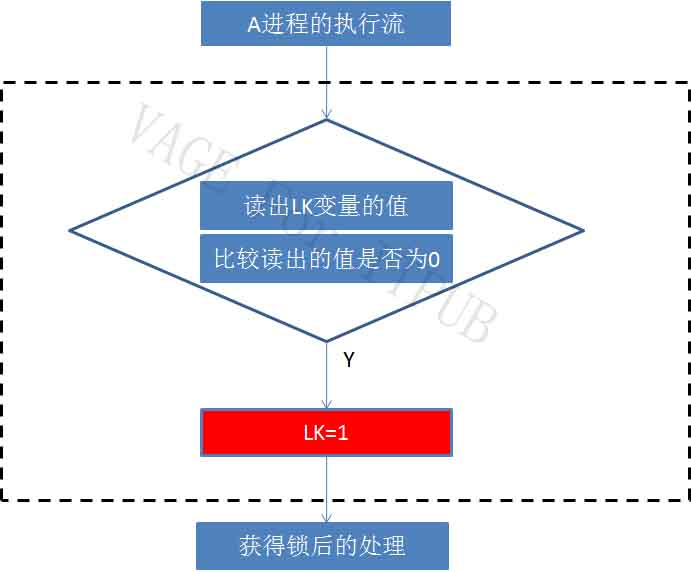
图7 M7.jpg
解决方案就是将上图虚线框中的多条指令,集合成一条指令。这条指令就是资料中常说的“测试并交换”,有些平台上是“测试并设置”。到底是哪个,取决于CPU。这条集合多个操作为一身的指令,就是Latch和Mutex的基础:原子指令。 无论“测试并交换”还是“测试并设置”,这条指令好由CPU提供,用CPU中蚀刻成的电路实现,这样才能保证“原子”、“快速”的特性。 在Intel平台中,这条原子指令是cmpxchg,一般常称为“比较并交换”。使用这条指令后,加锁流程图如下:
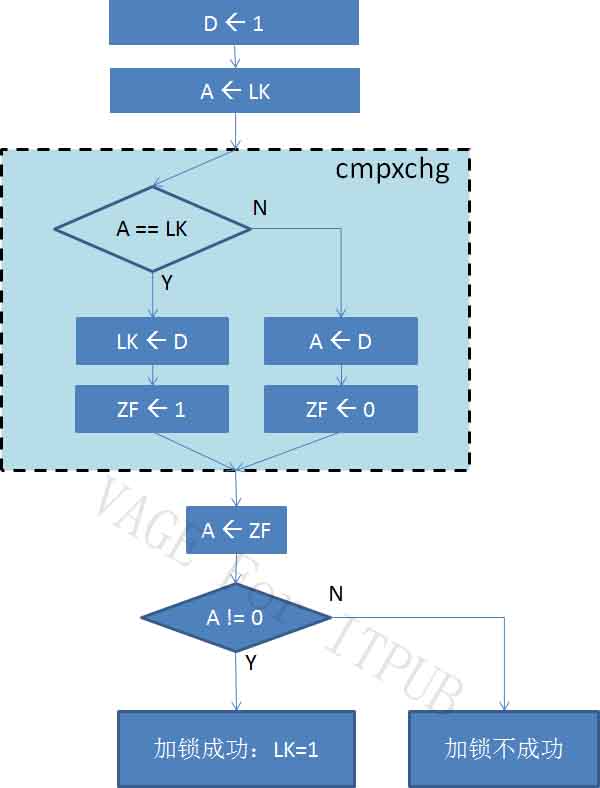 图8 M8.jpg
我们解释一下这张图,注意以下几点:
1、虚线框中的部分,就是原子指令cmpxchg。它完成的工作还真多啊。不过,再多也没关系,由CPU中的电路保证,这是一条指令,它的执行,不会被别的进程打断。
2、这张图中用到了几个新的变量:D、A和ZF。这几个变量都是私有变量,每个进程有自己一套值,互相之间看不到对方的私有变量值。而代表锁的变量LK,则是一个公共变量。
(为了和变量A区分,我不再假设进程A、B,而用进程P1、P2代替)
假设进程P1、P2同时要获得锁LK。LK原值是0,如下图:
图8 M8.jpg
我们解释一下这张图,注意以下几点:
1、虚线框中的部分,就是原子指令cmpxchg。它完成的工作还真多啊。不过,再多也没关系,由CPU中的电路保证,这是一条指令,它的执行,不会被别的进程打断。
2、这张图中用到了几个新的变量:D、A和ZF。这几个变量都是私有变量,每个进程有自己一套值,互相之间看不到对方的私有变量值。而代表锁的变量LK,则是一个公共变量。
(为了和变量A区分,我不再假设进程A、B,而用进程P1、P2代替)
假设进程P1、P2同时要获得锁LK。LK原值是0,如下图:
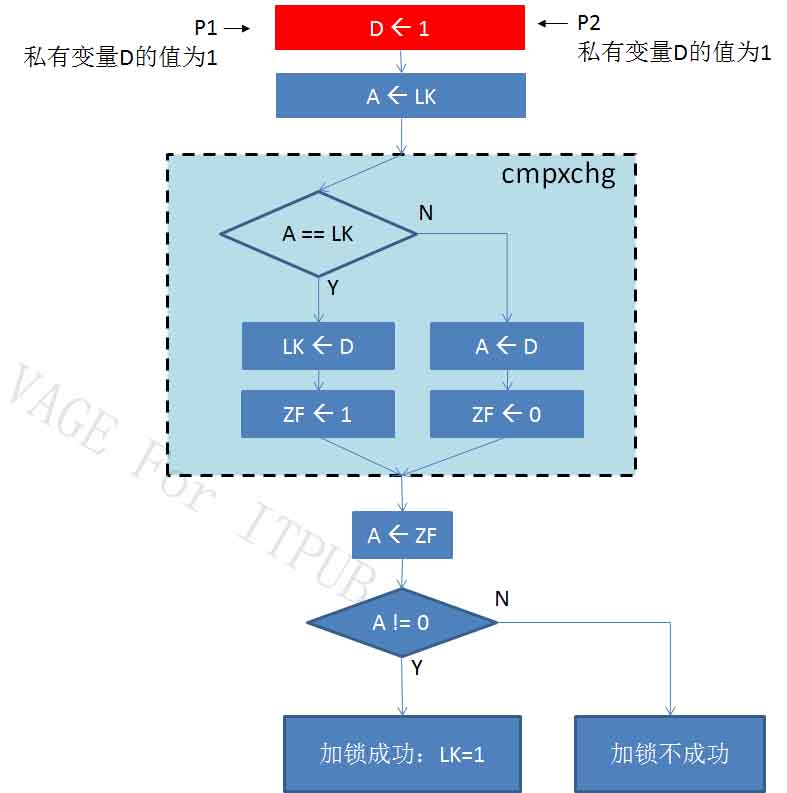 图9 M9.jpg
图9 M9.jpg
如图9所示,假P1和P2分别在两个CPU(或两个核)中同时执行条指令:将1传给各自的私有变量D。
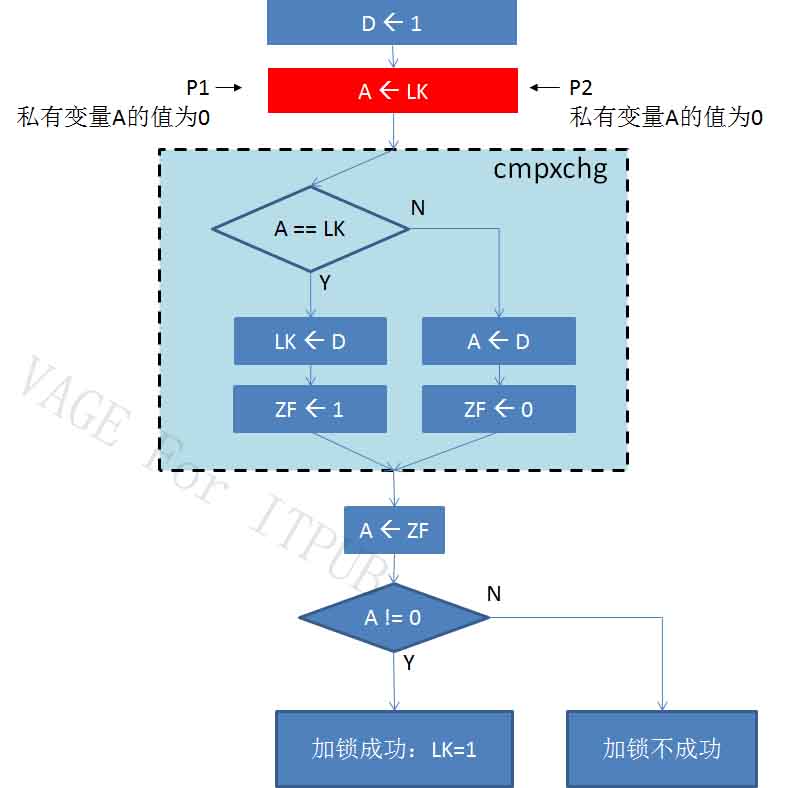 图10 M10.jpg
再看图10,P1、P2进程同时执行下一条指令,将公共变量LK的值0,赋给各自的私有变量A。
图10 M10.jpg
再看图10,P1、P2进程同时执行下一条指令,将公共变量LK的值0,赋给各自的私有变量A。
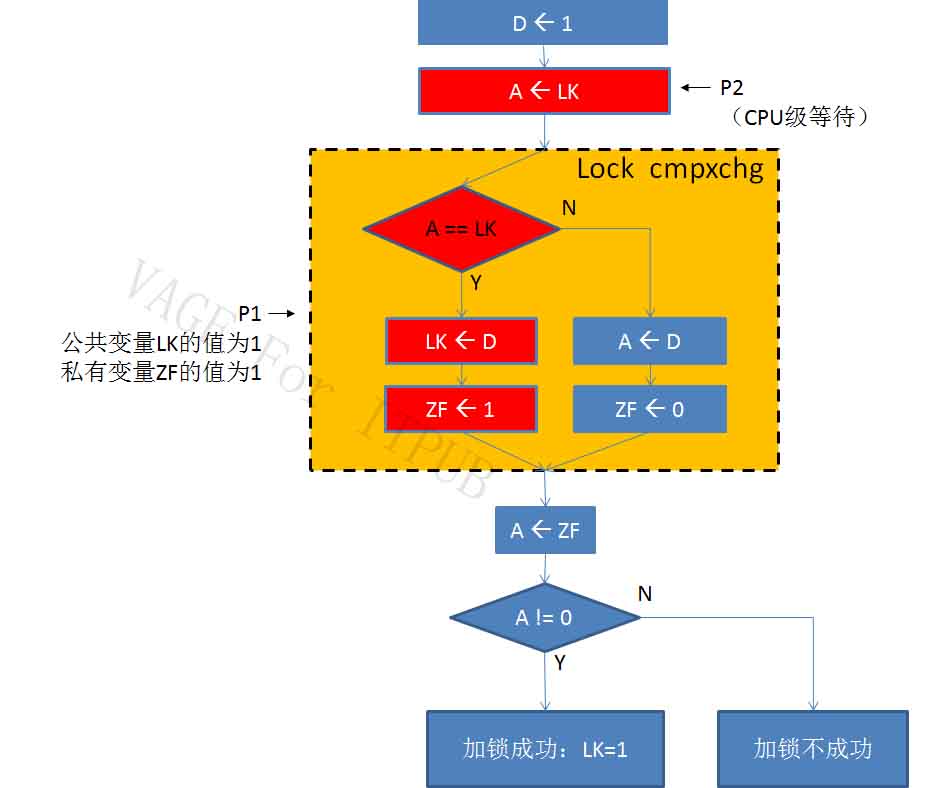 图11 M11.jpg
接着看图11,此处的原子指令cmpxchg前面,加了前缀Lock。此前缀的目的,保证只有一个CPU可以使用cmpxchg指令访问变量LK。其他进程只能先等着。
假设此处是P1进程所在CPU先执行原子指令。先判断A == LK 。
此时,公共变量LK的值为0,P1的私有变量A的值也是0,条件满足。将私有变量D的值赋给LK。这就相当于锁加成了。
(注意,D的值1,就是要传到锁变量LK中的值。这个值就是后面要说到的mutex_value,可以在v$mutex_sleep_history看到,它也是等待事件中P2的值)
接着,还有将私有变量ZF的值设为1。这一步相当设个标志位。后面会根据ZF的值,判断锁是否加成功。
P1在执行原子指令期间,P2进程的CPU在等待。
(注意:CPU等待和进程等待很不相同。进程等待时通常会让出CPU,CPU等待时什么都不会让出)。
这条原子指令虽然复杂,但它毕竞是用硬件实现的CPU指令。它占的指令周期会比一条普通的Mov指令多一点,但也不会多太多。
很快,P1执行完毕,公共变量LK的值已经被改为1。标志变量ZF(私有变量)被设置为1。然后,继续向下执行:
图11 M11.jpg
接着看图11,此处的原子指令cmpxchg前面,加了前缀Lock。此前缀的目的,保证只有一个CPU可以使用cmpxchg指令访问变量LK。其他进程只能先等着。
假设此处是P1进程所在CPU先执行原子指令。先判断A == LK 。
此时,公共变量LK的值为0,P1的私有变量A的值也是0,条件满足。将私有变量D的值赋给LK。这就相当于锁加成了。
(注意,D的值1,就是要传到锁变量LK中的值。这个值就是后面要说到的mutex_value,可以在v$mutex_sleep_history看到,它也是等待事件中P2的值)
接着,还有将私有变量ZF的值设为1。这一步相当设个标志位。后面会根据ZF的值,判断锁是否加成功。
P1在执行原子指令期间,P2进程的CPU在等待。
(注意:CPU等待和进程等待很不相同。进程等待时通常会让出CPU,CPU等待时什么都不会让出)。
这条原子指令虽然复杂,但它毕竞是用硬件实现的CPU指令。它占的指令周期会比一条普通的Mov指令多一点,但也不会多太多。
很快,P1执行完毕,公共变量LK的值已经被改为1。标志变量ZF(私有变量)被设置为1。然后,继续向下执行:
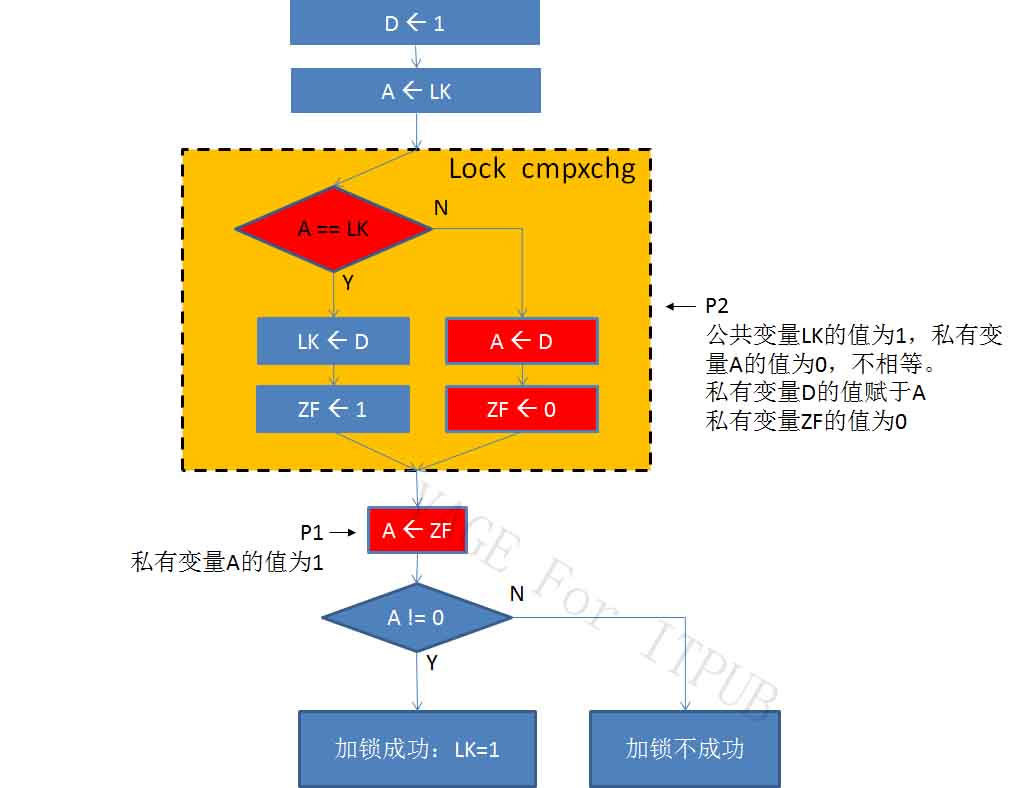 图12 M12.jpg
P1进程执行原子指令的下一条语句,将私有变量ZF的值1,传给私有变量A。同时,另一颗CPU执行P2进程执行流的下一条指令,也就是原子指令cmpxchg。
但此时公共变量LK的值此时已经为1。P2进程的私有变量A的值还是0, A == LK,判断条件不满足。从图右边执行,将私有变量D的值赋于私有变量A。并将私有变量ZF的值设置为0。
执行到这一步,P1的私有变量ZF值为1,而P2的私有变量ZF值为0。
图12 M12.jpg
P1进程执行原子指令的下一条语句,将私有变量ZF的值1,传给私有变量A。同时,另一颗CPU执行P2进程执行流的下一条指令,也就是原子指令cmpxchg。
但此时公共变量LK的值此时已经为1。P2进程的私有变量A的值还是0, A == LK,判断条件不满足。从图右边执行,将私有变量D的值赋于私有变量A。并将私有变量ZF的值设置为0。
执行到这一步,P1的私有变量ZF值为1,而P2的私有变量ZF值为0。
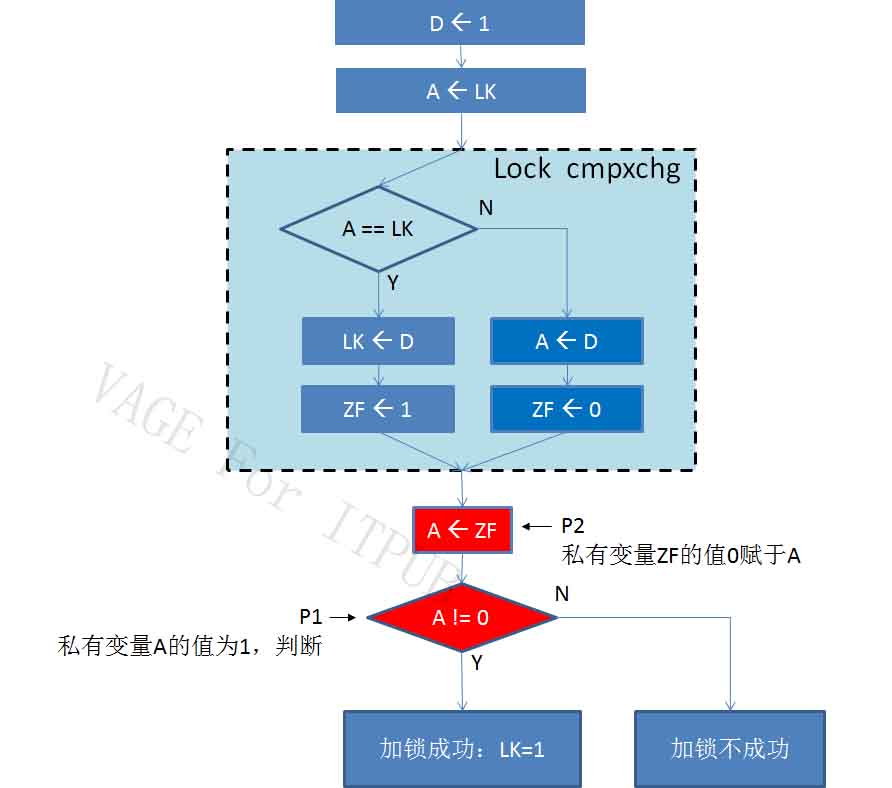 图13 M13.jpg
P1进程执行判断语句: A != 0 ,P1的私有变量A的值为1,不等于0。P1接下来将进入加锁成功的流程继续执行。
P2进程私有变量ZF值0赋于A。再下一步P2也要判断条件:A != 0。P2的私有变量A,是等于0的,因此P2终将进入加锁不成功的流程。
这就是原子操作的作用。
使用了带lock前缀的cmpxchg指令,可以保证在多芯、多核平台,多个进程同时要求设置锁变量LK,只有一个进程可以设置成功、进入加锁成功的流程。而其他进程都设置不成功,只能进入加锁不成功的流程。
注意:
1、将以上流程图中的变量替换一下,私有变量D,A,换成寄存器EDX/DX,A换成寄存器EAX/AX,ZF换成标志寄存器ZF。就是Oracle中实际的cmpxchg指令了。
2、另需 说明,cmpxchg指令不是的原子操作,使用mov操作一个对齐的内存字,通常也是一个原子操作,等等。有兴趣可以阅读CPU相关技术文章。
图13 M13.jpg
P1进程执行判断语句: A != 0 ,P1的私有变量A的值为1,不等于0。P1接下来将进入加锁成功的流程继续执行。
P2进程私有变量ZF值0赋于A。再下一步P2也要判断条件:A != 0。P2的私有变量A,是等于0的,因此P2终将进入加锁不成功的流程。
这就是原子操作的作用。
使用了带lock前缀的cmpxchg指令,可以保证在多芯、多核平台,多个进程同时要求设置锁变量LK,只有一个进程可以设置成功、进入加锁成功的流程。而其他进程都设置不成功,只能进入加锁不成功的流程。
注意:
1、将以上流程图中的变量替换一下,私有变量D,A,换成寄存器EDX/DX,A换成寄存器EAX/AX,ZF换成标志寄存器ZF。就是Oracle中实际的cmpxchg指令了。
2、另需 说明,cmpxchg指令不是的原子操作,使用mov操作一个对齐的内存字,通常也是一个原子操作,等等。有兴趣可以阅读CPU相关技术文章。
第 二 部分 SPIN
上一部分,讲述了什么是Mutex或Latch中使用的原子操作。下面,接着上面的图,如果P1进程成功设置了LK变量,获得了锁。P2进程没有成功设置LK,它进入“加锁不成功”的流程。如果P2加锁不成功,会做什么呢? 答案是:SPIN。也称“自旋”。 以上图为例,P2进程自旋,就是不停的循环,判断LK变量是否为0,如果为0,P2进程重新申请锁。 自旋很简单。Mutex的自旋是255次,Latch的是2000次。 关于自旋,Oracle也在不断的开进算法, 下面讨论三个问题:为什么要自旋、我的自旋是否有效率、自旋之后呢。先从个开始。 一、为什么要自旋 这个问题很简单。多个进程在CPU上来回切换是有成本的。P2进程如果因为拿不到一个小小的“内存锁”,而被“换出”CPU、进入睡眠状态,这有点浪费。要知道P2进程已经运行了一会,CPU的Cache中,已经都是P2的数据,现在P2让出CPU,让别的进程使用CPU,等到过一会P2再使用CPU时,CACHE中又是别人的数据,这将影响效率。 如果你对上段文字理解不是太清楚,打个简单的比方,如果你跑了老远去找朋友,朋友不在家,你估计朋友会很快回来,你会怎么办!打道回府?肯定不会,你会在朋友家门口等他一会儿。这就相当于自旋。 如果不能获得资源,并不马上放弃,而是会选择重试。重试一定次数后,如果还无法获得,再放弃。 二、我的自旋是否有效率 如果100次自旋中有90次都可以得到锁,哪么自旋还是相当有效率的。如果相反,100次自旋只有10来次可以获得锁,哪么,大多数自旋都是没有意义的,浪费了CPU而已。 如果得到自旋期间获得锁的比例呢?很遗憾,Mutex无法统计,只能统计Latch的。Latch的Misses相当于Spin次数, Spin_gets则是在Spin期间得到了Latch的次数。Spin_gets/Misses,这个结果就是Spin期间得到Latch的比例。 Latch不但可以方便的计算出这个比例,还可以方便的调节SPIN的次数。如果这个比例很高,比如都是百分之九十几,那证明Spin还是很有用的,十次Spin多于九次都可以在Spin期间得到Latch,这时不需要调节_spin_coun。相反,如果Spin_gets/Misses的比例很低,Spin期间很少得到Latch,说明目前的Spin意义不大。可以将_spin_coun增大,让进程多Spin一会儿,这样可以提升Spin_gets/Misses的比例。或者,也可以将_spin_coun减少,既然Spin期间都得不到Latch,不如减少Spin循环的次数,这样虽不能提高Spin期间获得Latch的比例,但可以减少CPU无谓的消耗。 针对Mutex,并非Oracle不愿为我们提供这些统计数据,而是无法提供。非不愿,实不能。原因将在后面的章节讨论。这是Mutex的特性决定的,它很迅速,因此它的相关统计资料就少。它像一个独行侠,江湖上只有它的传说。也因此,它的观察、监控、调优,都比较困难。 还有一个问题,自旋之后呢,看下一部分吧。第三部分 自旋之后:Sleep
Mutex自旋是255次,Latch自旋是2000次。自旋就是循环一遍遍的看“锁”是否可以获得。如果自旋期间无法获得锁,无论是Mutex还是Latch,都将转入睡眠状态。不同的是,Latch是长睡不醒,等待着别人唤醒。Mutex,在短暂的睡眠后,进程将起来重新尝试获得锁、无法获得开始SPIN、SPIN期间无法获得再一次短暂睡眠。
Mutex的缕战缕败,将极大的消耗CPU。特别是在11GR2的早期版本中,因为短暂睡眠时间太短,只有毫秒左右,一个缕战缕败的Mutex,从vmstat中的统计资料来看,几乎会占满一个CPU。到11.2.0.3后,这种情况会好很多,因为睡眠时间延长到10毫秒(一个CPU时间片)。
下面,用Linux来观察一下此点,这非常简单。不需要使用Dtrace、也不需要Gdb、mdb,更不需要分析汇编代码。先从Latch开始,验证一下Latch是如何长睡不醒的。 步1:找一个测试表 lhb@OCP> select dbms_rowid.ROWID_RELATIVE_FNO(rowid),dbms_rowid.rowid_block_number(rowid),vage.* from vage where rownum=1;
DBMS_ROWID.ROWID_RELATIVE_FNO(ROWID) DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID) ID NAME ------------------------------------ ------------------------------------ ---------- ---------- 5 367 1 AAAAAA
我的测试表是vage,他的行在5号文件367号块。 步2:找到保护此块的Latch: idle> idle> select ba,file#,dbablk,HLADDR ,tch,lru_flag from x$bh where file#=5 and dbablk=367;
BA FILE# DBABLK HLADDR TCH LRU_FLAG ---------------- ---------- ---------- ---------------- ---------- ---------- 00000000746A8000 5 367 0000000083DD1BB0 2 0
保护此块的Latch地址为0x0000000083DD1BB0。 步3:使用oradebug,将这个内存地址设置为0xffffffffffffffff idle> oradebug setmypid Statement processed.
idle> oradebug poke 0x0000000083DD1BB0 8 0xffffffffffffffff BEFORE: [083DD1BB0, 083DD1BB8) = 00000000 00000000 AFTER: [083DD1BB0, 083DD1BB8) = FFFFFFFF FFFFFFFF
步4:打开一个会话,查看它的进程号: [oracle@ocp ~]$ sqlplus lhb/a
SQL*Plus: Release 11.2.0.3.0 Production on Tue Aug 27 07:10:32 2013
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options
lhb@OCP> select c.sid,spid,pid,a.SERIAL# from (select sid from v$mystat where rownum<=1) c,v$session a,v$process b where c.sid=a.sid and a.paddr=b.addr;
SID SPID PID SERIAL# ---------- ------------------------ ---------- ---------- 14 4793 18 21
进程号是4793。
步5:使用Strace跟踪。 [root@ocp ~]# strace -p 4793 Process 4793 attached - interrupt to quit read(9,
步6:在4793号进程的会话中查议VAGE表行: lhb@OCP> select * from vage where rowid='AAAEWeAAFAAAAFvAAA';
(操作将被Hang住,等待事件是CBC Latch)
步7:查看Strace结果:
[root@ocp ~]# strace -p 4793 Process 4793 attached - interrupt to quit read(9, "\1P\0\0\6\0\0\0\0\0\21i \376\377\377\377\377\377\377\377\2\0\0\0\0\0\0\0\1\0\0"..., 8208) = 336 getrusage(RUSAGE_SELF, {ru_utime={0, 38994}, ru_stime={0, 26995}, ...}) = 0 times({tms_utime=3, tms_stime=2, tms_cutime=0, tms_cstime=0}) = 429483164 ……………………………………………… getrusage(RUSAGE_SELF, {ru_utime={0, 39993}, ru_stime={0, 26995}, ...}) = 0 getrusage(RUSAGE_SELF, {ru_utime={0, 39993}, ru_stime={0, 27995}, ...}) = 0 getrusage(RUSAGE_SELF, {ru_utime={0, 39993}, ru_stime={0, 27995}, ...}) = 0 semop(98304, 看后一行,进程调用semop系统函数,开始等待。Man semop一行,可以轻松得知,semop是一个没有超时时间的函数,进程将交出CPU、转入睡眠、直到信号量被设置。
Mutex,也可以使用类似的方法进行验证,但关键是要找到一个Mutex的地址。这可以从x$mutex_sleep_history的MUTEX_ADDR列查到。 但,没有竞争的Mutex,在x$mutex_sleep_history中查不到。这是观察Mutex的难点之处,只有当出现竞争了,我们才能找到Mutex。下面,我们先制造个竞争,找询目标Mutex: 步1:制造竞争,找询目标Mutex。 在两个会话中,执行如下PL/SQL程序块: declare msql varchar2(500); mcur number; mstat number; jg varchar2(4000); cg number; begin mcur:=dbms_sql.open_cursor; for i in 1..1000000 loop msql:='select id from vage where rownum=1’; dbms_sql.parse(mcur,msql,dbms_sql.native); dbms_sql.define_column(mcur,1,jg,4000); mstat:=dbms_sql.execute(mcur); -- dbms_sql.define_column(mcur,1,jg,4000); --cg:=dbms_sql.fetch_rows(mcur); --dbms_sql.column_value(mcur,1,jg); end loop; dbms_sql.close_cursor(mcur); end; /
这是一个完整的动态游标的例子,循环中后三行去掉了,因为我们不需要“抓取”,只需要不停的解析即可。
如果观察等待事件,会发现两个会话执行这段代码期间,有很多的cursor: pin S等待。这是软软解析时的Mutex相关等待。查看x$mutex_sleep_history,可以发现Mutex地址
步2:确定目标Mutex地址: idle> select MUTEX_ADDR,GETS,SLEEPS,MUTEX_TYPE,MUTEX_VALUE from x$mutex_sleep_history;
MUTEX_ADDR GETS SLEEPS MUTEX_TYPE MUTEX_VALUE ---------------------------- ------------ -------- ------------------- ------------------------------- 000000007D3A86A0 3456958 39 Cursor Pin 0000001000000000 000000007D3A86A0 3930618 66 Cursor Pin 00 00000000816C6078 1 1 Library Cache 00 0000000085085E50 499 1 Library Cache 00 000000007EE1E5C8 1 4 Cursor Pin 0000001000000000 …………
看前两行,它们两个的Gets、Sleeps次数多,而且它们是同一个地址:0x000000007D3A86A0。这就是PL/SQL程序块中我们的测试SQL:select id from vage where rownum=1在软软解析时需要的Mutex了。
步3:使用Oradebug,手动设置Mutex: idle> oradebug peek 0x000000007D3A86A0 8 [07D3A86A0, 07D3A86A8) = 00000000 00000000 idle> oradebug poke 0x000000007D3A86A0 8 0x0000001000000001 BEFORE: [07D3A86A0, 07D3A86A8) = 00000000 00000000 AFTER: [07D3A86A0, 07D3A86A8) = 00000001 00000010 此步骤将Mutex设置为0x0000001000000001。
idle> oradebug poke 0x000000007D3A86A0 8 0x0000000000000000 BEFORE: [07D3A86A0, 07D3A86A8) = 00000001 00000000 AFTER: [07D3A86A0, 07D3A86A8) = 00000000 00000000
步4:使用Strace跟踪进程: [root@ocp ~]# strace -p 4793 Process 4793 attached - interrupt to quit read(9,
步5:在4793进程对应的会话中执行Select语句: select id from vage where rownum=1
这个执行会被Hang住,等待事件就是Cursor:Pin S。因为Mutex我们已经手动设置过值了。
步6:观察Strace的结果: [root@ocp ~]# strace -p 4793 Process 4793 attached - interrupt to quit read(9, "\1?\0\0\6\0\0\0\0\0\21i7\376\377\377\377\377\377\377\377\2\0\0\0\0\0\0\0\4\0\0"..., 8208) = 319 getrusage(RUSAGE_SELF, {ru_utime={39, 843942}, ru_stime={4, 736279}, ...}) = 0 times({tms_utime=3984, tms_stime=473, tms_cutime=0, tms_cstime=0}) = 429693484 getrusage(RUSAGE_SELF, {ru_utime={39, 843942}, ru_stime={4, 736279}, ...}) = 0 getrusage(RUSAGE_SELF, {ru_utime={39, 843942}, ru_stime={4, 736279}, ...}) = 0 times({tms_utime=3984, tms_stime=473, tms_cutime=0, tms_cstime=0}) = 429693484 getrusage(RUSAGE_SELF, {ru_utime={39, 843942}, ru_stime={4, 736279}, ...}) = 0 times({tms_utime=3984, tms_stime=473, tms_cutime=0, tms_cstime=0}) = 429693484 getrusage(RUSAGE_SELF, {ru_utime={39, 843942}, ru_stime={4, 737279}, ...}) = 0 times({tms_utime=3984, tms_stime=473, tms_cutime=0, tms_cstime=0}) = 429693484 getrusage(RUSAGE_SELF, {ru_utime={39, 843942}, ru_stime={4, 737279}, ...}) = 0 sched_yield() = 0 sched_yield() = 0 semtimedop(98304, 0x7fffd456d540, 1, {0, 10000000}) = -1 EAGAIN (Resource temporarily unavailable) semtimedop(98304, 0x7fffd456d540, 1, {0, 10000000}) = -1 EAGAIN (Resource temporarily unavailable) semtimedop(98304, 0x7fffd456d540, 1, {0, 10000000}) = -1 EAGAIN (Resource temporarily unavailable) …………………………(省略N行)………………………………
semtimedop(98304, 0x7fffd456d540, 1, {0, 10000000}) = -1 EAGAIN (Resource temporarily unavailable)
semtimedop(98304, 0x7fffd456d540, 1, {0, 10000000}
Semtimedop函数,会以很高的频率被重复的调用。看它的第四个参数,值为{0, 10000000},这本是一个。。。类型的结构,用作超时时间。可以用秒或者以纳秒为单位。此处,是以纳秒为单位的,10000000纳秒,正是10毫秒。 与之对应,当进程无法获得Mutex、一遍遍的重试时,v$mutex_sleep和v$mutex_sleep_history中的Sleeps列值,也会飞一样快速增长。
一个长睡不醒,一个不断的醒来,这是Latch和Mutex主要的区别之一。
第 四 部分 Mutex的类型
为了方便调查Mutex问题,根据Mutex作用,Oracle将Mutex分成不同的类型。常见的类型有Cursor Parent、Library Cache、Hash Table、Cursor Pin、Cursor Stat五种。在V$MUTEX_SLEEP和V$MUTEX_SLEEP_HISTORY中,都有一个MUTEX_TYPE列,就是产生等待的Mutex的类型。 对应的等待事件,通常Hash Table 、Cursor stats和Cursor Parent类型的Mutex,对应Cursor : mutex类等待,Library Cache对应library cache : mutex类等待,Cursor Pin对应Cursor : Pin类等待。 硬解析时,所有类型的Mutex都会出现,软软解析通常只会有Cursor Pin型的Mutex。根据出现竞争Mutex的类型,也很容易定位问题的。
1、HASH表和Hash Bucket的Mutex 保护共享池HASH表的,在11G前的版本中,是Library Cache Latch。11G后,已经不再使用这个Latch,而换成了Library Cache 型的Mutex。注意不是Hash Table啊。我以前也是望文生义,觉得HASH表相关的,应该是用HASH Table型Mutex保护,其实不是这样的。 无论软、硬解析,进程都要以独占方式获得Library Cache型Mutex,然后才能访问HASH链。如果遭遇竞争,这里的等待事件是library cache: mutex X。
Latch有Latch Miss,为进一步判断问题,Mutex当然也有Mutex Miss。这里的Mutex Miss,通常是“kglhdgn1 62”。我们可以在V$MUTEX_SLEEP_HISTORY中的LOCATION列找到Mutex Miss值。AWR报告中也有这个值,作为我们进一步判断Mutex问题的依据。 如果我们在一份AWR报告中,在 “Mutex Sleep Summary”部分中看到Location为“kglhdgn1 62”的Mutex竞争激烈,就说明在搜索HASh Bucket后的链表时遇到竞争。
2、句柄的Mutex和Library Cache Lock 在父游标句柄中保存有SQL文本,搜索链表的目的,就是对比每个父游标句柄中的SQL文本,找到目标父游标句柄。找到之后,要再次以独占方式申请持有类型为“Library Cache”的Mutex,如果遇到竞争,此处的等待事件也是library cache: mutex X,为了加以区分,此处的Mutex Miss通常是“kglhdgn2 106”。 在此处的Mutex保护下,进程将进一步获得父游标句柄上的Library cache lock。Library cache lock获得成功,Mutex释放。也就是说,此处的Mutex,代替的是以前版本的Library Cache Lock Latch。 由于要依靠Library Cache Lock实现依赖链,Mutex并没有取代Library Cache Lock,只是把Library Cache Lock Latch替代了。
3、Hash Table型Mutex Hash Table型Mutex很特殊,它可以做为游标版本过多造成竞争的标志。因为它只保护父游标句柄中的“子游标列表”。 关于子游标列表,如下图:
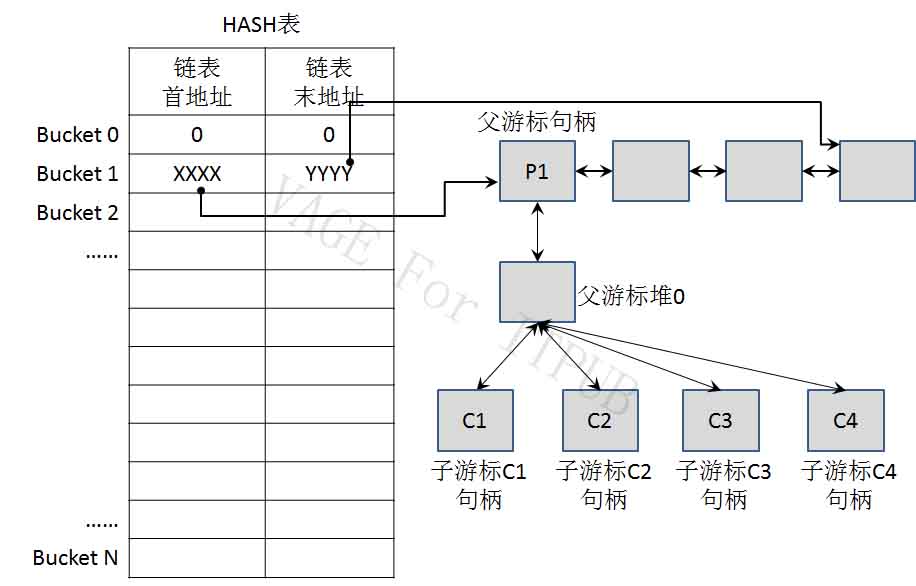
在父游标的堆0中,将记录所有子游标的句柄地址等信息,就是图中的“子游标列表”。除了软软解析,硬、软解析都需要访问子游标列表。 保护子游标列表的Mutex,就是Hash Table型的Mutex。而且Hash Table型Mutex只用来保护子游标列表。 注意,不要望文生义的认为Hash Table型Mutex是用来保护共享池的总Hash表和Bucket的。但其实它们是受Library Cache型Mutex保护。 Hash Table型Mutex发生竞争,一定意味“子游标列表”这块信息的访问,有了竞争。什么才可能让子游标列表的访问遭遇竞争呢?很简单,子游标列表过长。因此,只要发现Hash Table型Mutex有竞争,就一定意味着某些游标版本过多了。
4、堆的Mutex和Library Cache Pin 在Mutex出现前,堆,Heap,它的访问受的Library Cache Pin锁保护。现在,大部分时间,堆的访问受Mutex保护。大部分场景中的Library Cache Pin都替代掉了。在小部分情况下,Library Cache Pin还在,但它的获取、释放不再用Library Cache Pin Latch保护,而是改用Mutex。 在硬解析时,为访问在父游标、子游标和SQL针对对象的Shared pool Heap,还是需要Library Cache Pin的。甚至子游标上还需要独占的Library Cache Pin。但是,我们已经看不到Library Cache Pin Latch的影响,Mutex负责保护Library Cache Pin的获得和释放。 软解析时父、子游标上都不需要Library Cache Pin,但在游标针对对象上,还是需要共享模式的Library Cache Pin,同时由Mutex负责保护它。 而在软软解析时,访问子游标堆中的执行时,已经完全不需要Library Cache Pin了,只需要Cursor Pin型的Mutex。 如果可以让软软解析的执行停在解析之后、关闭游标之前。我们仍会在x$kglob视图中的kglpmd列查到此时游标上有2号(共享模式)的Library Cache Pin,其实这是Mutex。已经不是Library Cache Pin了。
第 五 部分 通过Mutex判断性能问题
Mutex造成的性能问题,根据等待事件、发生竞争的Mutex类型,还是比较容易判断出问题根源的。
Mutex在解析、绑定环节使用,Mutex的性能问题,主要原因是以下几种: 1)、硬解析过多 2)、软解析过多 3)、软软解析过多 4)、子游标版本过多且访问频繁 5)、频繁修改绑定变量值
解决方案也是很明显的,如果是硬解析过多,则增大共享池、使用绑定变量等方法,提高软解析比例。 如果是软解析过多,修改Session_cache_cursor,增大软软解析频率。 如果软软解析过多呢,可以使用“一次解析、多次执行”方式,减少解析次数。 什么是一次解析多次执行呢?看下面这段原始的动态游标PL/SQL程序块: SQL> declare 2 mcur number; 3 mstat number; 4 v_name varchar2(40); 5 begin 6 mcur:=dbms_sql.open_cursor; 7 for i in 1..1000 loop 8 dbms_sql.parse(mcur,'select name from vage where id=:x',dbms_sql.native); 9 dbms_sql.bind_variable(mcur,':x',1); 10 mstat:=dbms_sql.execute(mcur); 11 mstat:=dbms_sql.fetch_rows(mcur); 12 dbms_sql.define_column(mcur,1,v_name,40); 13 dbms_sql.column_value(mcur,1,v_name); 14 dbms_output.put_line('查询结果:'||v_name); 15 end loop; 16 dbms_sql.close_cursor(mcur); 17 end; 18 /
从第7行到第15行是一个1000次的循环,第8行是解析,第9行是绑定。它们都在循环之中。解析和绑定的次数,都将是1000次。这种方式,是“一次解析、一次绑定”。再看下面这段程序: SQL> declare 2 mcur number; 3 mstat number; 4 v_name varchar2(40); 5 begin 6 mcur:=dbms_sql.open_cursor; 7 dbms_sql.parse(mcur,'select name from vage where id=:x',dbms_sql.native); 8 for i in 1..1000 loop 9 dbms_sql.bind_variable(mcur,':x',1); 10 mstat:=dbms_sql.execute(mcur); 11 mstat:=dbms_sql.fetch_rows(mcur); 12 dbms_sql.define_column(mcur,1,v_name,40); 13 dbms_sql.column_value(mcur,1,v_name); 14 dbms_output.put_line('查询结果:'||v_name); 15 end loop; 16 dbms_sql.close_cursor(mcur); 17 end; 18 /
从第8行到第15行是循环,第7行是解析,第9行是绑定。 原来在循环中的解析,拿到了循环之外,它只会有一次。也就是说,解析次数只有一次。 绑定还在循环内,每次为绑定变量赋予不同的值。绑定的过程,将执行1000次。这种方式,就是“一次解析、多次绑定”。
放在程序,“一次解析多次绑定”还是容易理解的,但是如果是在有中间件的三层应用架构中,是否可以有“一次解析多次绑定”呢?当然可以。下面,我们用一组图来说明这个问题。
图15
如上图,比如有这样一个三层的企业网架构,假设终端用户要执行登录操作:
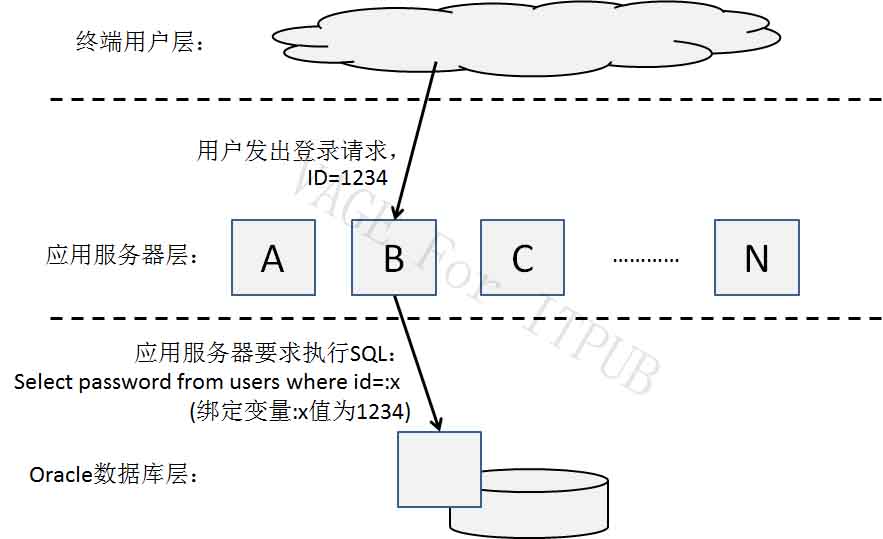
图16
某终用户发出登录请求,ID为1234,此登录请求被传送到应用服务器B。在应用服务器B上,登录程序一定有如下步骤的代码: 1. 打开Cursor 2. 解析Cursor:Select password from users where id=:x 3. 绑定,将绑定变量:x的值设为1234 4. 执行、抓取、…… 5. 关闭Cursor 应用服务器B依次执行这些代码,以完成用户的登录请求。当执行到步骤5“关闭Cursor”时,应用服务器B将跳过此步骤,Cursor不会被关闭。 接下来,另一用户也发出了登录请求,ID为4321,此请求也被传到应用服务器B,如下图:
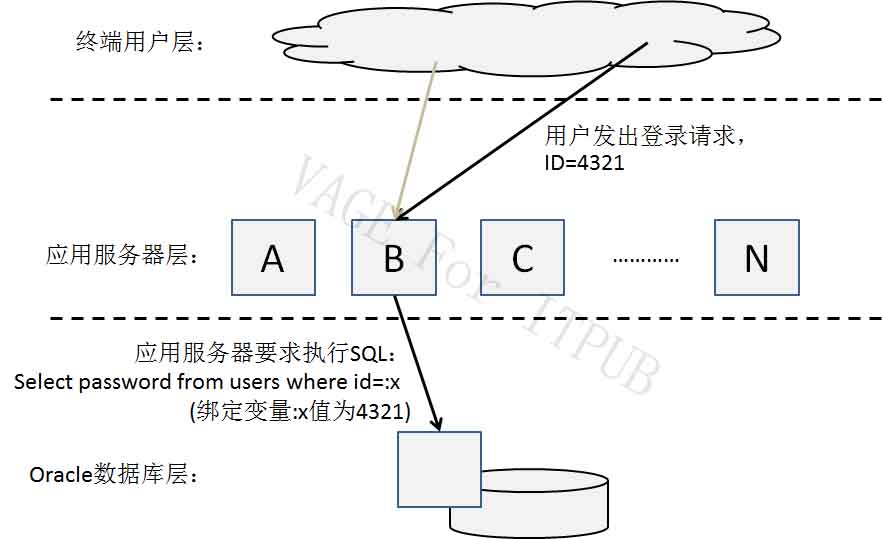
图17
仍是如下的代码: 1. 打开Cursor 2. 解析Cursor:Select password from users where id=:x 3. 绑定,将绑定变量:x的值设为1234 4. 执行、抓取、…… 5. 关闭Cursor 由于“Select password from users where id=:x”的Cursor已经被应用服务器B缓存,本次执行代码,不再需要第1、2步骤,直接将绑定变量:x的值,定为4321,然后就继续下面的执行、抓取等步骤即可。这就是不使用PL/SQL程序的“一次解析,多次执行”。 “一次解析,多次执行”,这必将减少解析次数,降低解析时的争用。因此如果一个繁忙的系统,如果面临软软解析竞争,除了前文中将一条SQL分成多条外,另一种方法,就是本章所述的“一次解析,多次执行”。 对于一个繁忙的系统,在应用服务器层缓存适量的游标,对于减少解析带来的竞争、减少数据库服务器CPU消耗,都是很有帮助的。 应用服务器缓存游标,不需要在数据库端作任何操作,通常应用服务器中会有类似“Cache Cursor Number”的设置,只需要设置这个参数,就可以指定每台应用服务器缓存游标的数量。 需要注意,应用服务器缓存游标,不同于数据库的session_cached_cursors。在应用服务器端被缓存的Cursor,因为游标没有被关闭,其所占共享池内存都不可被覆盖。而session_cached_cursors缓存的游标,前文已经有过介绍,其子游标堆6内存是可以被覆盖的。两相比较,应用服务器缓存的游标将占用更多的共享池内存。 在AWR报告前面,“Instance Efficiency Percentages”部分中,有一项性能指标:“Execute to Parse %:”,执行和解析的比,这个值越高越好。如果这个值为90%,代表平均一次解析、九次执行。如果这个值为40%,哪就是平均一次解析、四次执行。
除了“一次解析,多次绑定”外,还有一种方法解析过度软软解析。看下面这段程序: SQL> declare 2 mcur number; 3 mstat number; 4 v_name varchar2(40); 5 begin 6 mcur:=dbms_sql.open_cursor; 7 for i in 1..9000000 loop 8 dbms_sql.parse(mcur,'select name from vage where id=1',dbms_sql.native); 9 mstat:=dbms_sql.execute(mcur); 10 -- mstat:=dbms_sql.fetch_rows(mcur); 11 -- dbms_sql.define_column(mcur,1,v_name,40); 12 -- dbms_sql.column_value(mcur,1,v_name); 13 -- dbms_output.put_line('查询结果:'||v_name); 14 end loop; 15 dbms_sql.close_cursor(mcur); 16 end; 17 /
这段程序在循环中频繁解析select name from vage where id=1。如果在多个会话中同时执行这段程序,大量的软软解析,必须会导致Cursor:pin S竞争。如何解决呢?把程序改为如下方式即可。 在255号会话执行如下程序: SQL> declare 2 mcur number; 3 mstat number; 4 v_name varchar2(40); 5 begin 6 mcur:=dbms_sql.open_cursor; 7 for i in 1..9000000 loop 8 dbms_sql.parse(mcur,'select /*+SESS_255*/ name from vage where id=1',dbms_sql.native); 9 mstat:=dbms_sql.execute(mcur); 10 -- mstat:=dbms_sql.fetch_rows(mcur); 11 -- dbms_sql.define_column(mcur,1,v_name,40); 12 -- dbms_sql.column_value(mcur,1,v_name); 13 -- dbms_output.put_line('查询结果:'||v_name); 14 end loop; 15 dbms_sql.close_cursor(mcur); 16 end; 17 /
在另一个256会话,将第8行改为: 8 dbms_sql.parse(mcur,'select /*+SESS_256*/ name from vage where id=1',dbms_sql.native); 如果再有其他会话也要频繁解析这条SQL,可以将“/*+SESS_256*/”这串字符再改一下。这样,让不同的会话执行不同的SQL,就不会再有软软解析的竞争了。 可以在中间件层应用服务器中,修改程序代码,让不同的应用服务器解析文本略有区别的SQL,这样就可以避免同一SQL大并发软软解析。
先到这里吧,这篇帖子信息量应该比较多了,后面有机会再为大家继续解读Mutex。
