本文简单介绍一下SAP HANA数据库开发的概览和一些特性。
架构介绍
本文简单介绍一下SAP HANA数据库开发的概览和一些特性。
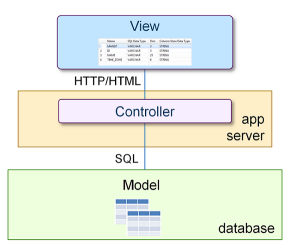
传统的数据库应用程序使用ODBC和JDBC等接口与SQL一起管理和查询数据,使用常见的模型-视图-控制器(MVC)开发体系结构,如下图所示:
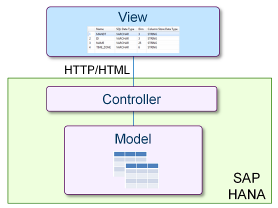
但基于SAP HANA的开发给出了另一种选择,它自带了一个应用服务器,可以将传统的控制器(Controller)放在数据库服务器上:
HANA自带的应用服务器被称为XS引擎,支持服务器端的XS脚本、ODATA服务、定时JOB等功能:
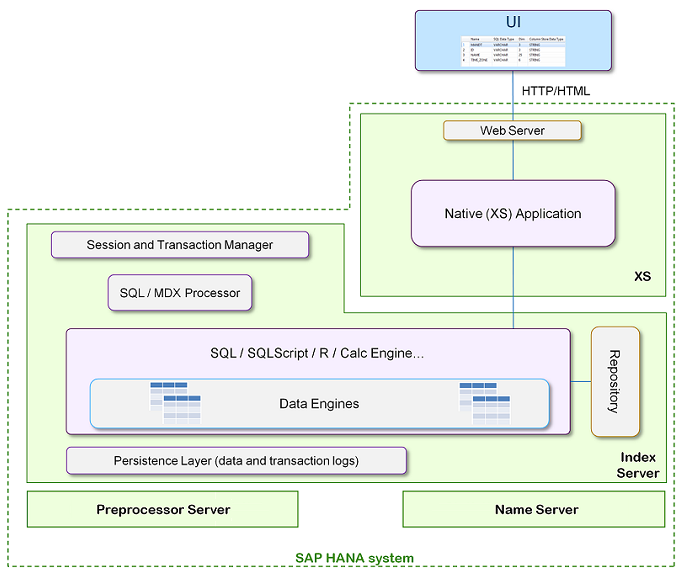
简单示意图如下:

实际项目中可以根据情况选择采用哪些功能,其大的差异就是是否用到HANA的XS引擎,也就是HANA自带的应用服务器,根据我的经验,下述场景可以考虑启用XS引擎:
① 直接在HANA平台开发整个应用,前端使用SAPUI5库,业务逻辑使用HANA服务端的JS Script,数据库表也都使用HANA。
② 有定时Job调用存储过程的场景。
③ 使用OData方式为外部提供数据(Restful API)。
功能组件介绍
SAP HANA开发提供的大部分功能如下图所示:
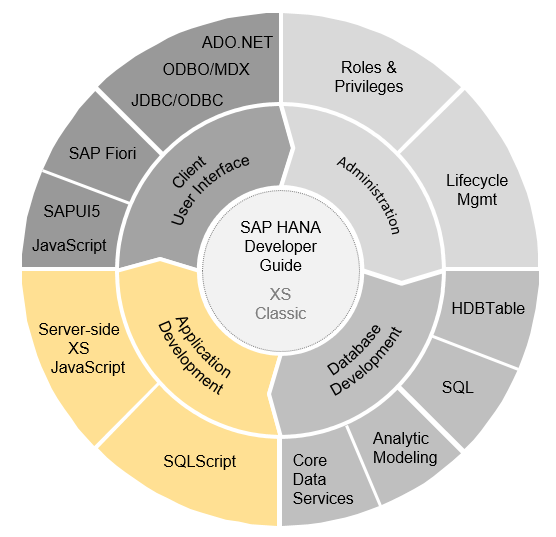
① Database Development:是SAP HANA基础的部分,也就是传统的数据库开发,包含数据库表、视图、存储过程等。SAP HANA的特性是通过定义设计期对象,将它们激活变成运行期对象,便于管理;而且HANA的图形化建模优点也很多。
② Administration:也是相对基础的部分,数据库的权限控制、生命周期控制等。SAP HANA除了基本的数据库权限外,还支持数据模型的行级别权限控制、基于SAP XS引擎开发的WEB App的权限控制等。
③ Client User Interface:SAP HANA和其他系统或终端用户的交互部分,包括访问数据库的方式(ODBC、JDBC等)、SAP UI库、JS脚本等。
④ Application Development:主要是应用服务器服务端的开发,服务端的JS脚本,SQL脚本等。
常用功能介绍
作者近通过SAP HANA实现了一个数据处理系统,通过这个系统来简单介绍一下用到的功能,主要包括CDS、计算视图、存储过程。
系统的技术架构如下:
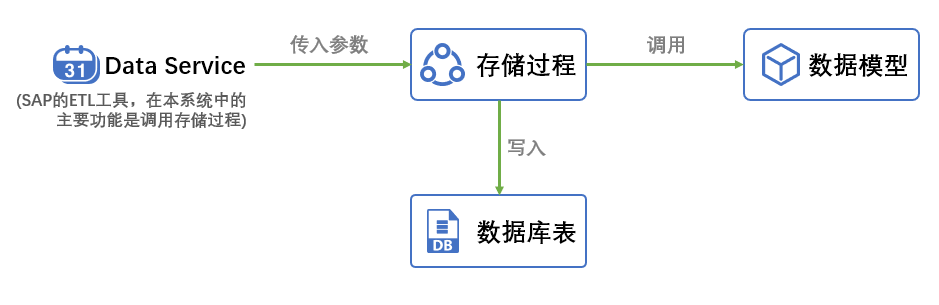
SAP HANA开发中,数据库对象分为运行期对象和设计期对象。
运行期对象与传统关系型数据库类似,指数据库中的表、存储过程、视图等数据库对象;设计期对象是HANA特有的一种为了便于数据库开发、使开发项目更易于维护的一种对象,将设计期对象激活后会自动在数据库中创建对应的运行期对象。

通过使用设计期对象,使数据库开发的相关代码能够放到服务器端,并以声明的形式创建运行期数据库对象;这样对于数据库开发的项目管理、代码管理、权限管理等方面都有一定好处,但相对来说步骤更加繁琐,不过显然优点更多,对于设计期对象HANA也有很多细节上的优化。
本系统的技术架构相对简单,但是业务逻辑比较复杂,是财险的预期现金流准备系统。详细的业务处理逻辑在后续文章中介绍,下图是数据库开发的项目结构:
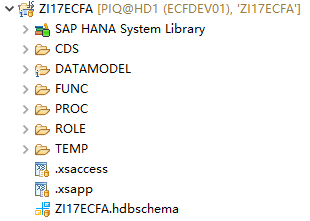
可以看到整个项目是按数据库对象的类型划分,每个文件夹下再按功能模块划分,整个项目结构大概如下图所示:

接下来介绍一下这些用到的设计期对象,和它们激活后的效果:
1. CDS
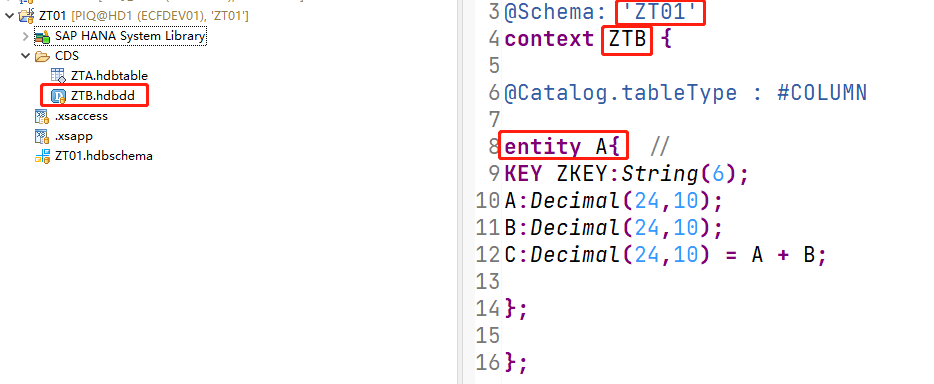
在SAP HANA开发中,有3种方式创建数据库表,1是直接通过DDL语句,create table;2是通过.hdbtable设计期对象生成数据库表;3是通过.hdbdd设计期对象生成数据库表。
第二种方式每个文件只能创建一张表,且语法与数据库SQL语句接近,能定义的技术细节更多,例如可以定义字段的comment,而且数据类型的声明语法与SQL语法基本一致,示例如下:
// To define an HDB table with main sql type columns, you can use the following code.// In the example below a schema should exist.table.schemaName = "ZT01";table.tableType = COLUMNSTORE; ROWSTORE is an alternative valuetable.columns =[{name = "MY_COL1"; sqlType = VARCHAR; length = 200; defaultValue = "Sample value";comment = "String Type"; },{name = "MY_COL2"; sqlType = INTEGER; defaultValue = "1";},{name = "MY_COL3"; sqlType = NVARCHAR; length = 200; defaultValue = "Sample value";comment = "String Type";},{name = "MY_COL4"; sqlType = DECIMAL; precision = 4; scale = 3;defaultValue = "1.4";},{name = "MY_COL5"; sqlType = DATE; nullable = false; defaultValue = "20140216";},{name = "MY_COL6"; sqlType = TIME; nullable = false; defaultValue = "101010";},{name = "MY_COL7"; sqlType = TIMESTAMP; nullable = false; defaultValue = "2011-12-31 23:59:59"; },{name = "MY_COL8"; sqlType = TINYINT; nullable = false; },{name = "MY_COL9"; sqlType = CLOB; nullable = true; },{name = "MY_COL10"; sqlType = BLOB; nullable = true; } ,{name = "MY_COL11"; sqlType = TEXT; nullable = true; },{name = "MY_COL12"; sqlType = CHAR; nullable = true; },{name = "MY_COL13"; sqlType = NCHAR; nullable = true; },{name = "MY_COL14"; sqlType = NCLOB; nullable = true; },{name = "MY_COL15"; sqlType = SMALLINT; nullable = false; },{name = "MY_COL16"; sqlType = BIGINT; nullable = false; },{name = "MY_COL17"; sqlType = SMALLDECIMAL; },{name = "MY_COL18"; sqlType = DOUBLE; nullable = false; },{name = "MY_COL19"; sqlType = REAL; nullable = false; },{name = "MY_COL20"; sqlType = SECONDDATE; nullable = false;},{name = "MY_COL21"; sqlType = ALPHANUM; nullable = false;},{name = "MY_COL22"; sqlType = VARBINARY; nullable = false;} ,{name = "MY_COL23"; sqlType = FLOAT; },{name = "MY_COL24"; sqlType = SHORTTEXT;length = 20; }];//table.indexes =// [// {name = "MYINDEX3"; unique = true; order = DSC; indexColumns = ["MY_COL2"];},// {name = "MYINDEX4"; unique = true; order = ASC; indexColumns = ["MY_COL1", "MY_COL4"];}//];table.primaryKey.pkcolumns = ["MY_COL1", "MY_COL2"];
第三种方式是HANA特有的语法,每个文件可以定义多个数据库表,或者可以定义数据库视图;通过这种方式创建的数据库表可以支持更多特性,但是也有一定局限,例如可以定义一个C列,C=A+B,这样每次insert的时候只需要插入A列和B列,C列值将自动计算并插入。
namespace ZT01.CDS;@Schema: 'ZT01'context ZTB {@Catalog.tableType : #COLUMNentity A {KEY ZKEY:String(6);A:Decimal(24,10);B:Decimal(24,10);C:Decimal(24,10) = A + B;};};
当然这种语法也有一些局限,不能使用复杂公式、只支持列式存储等。
不过通常我们只需要创建数据库表,指定数据类型即可,用不到一些特别的特性。当需要对表进行分区时,可以先激活CDS对象,再通过SQL DDL语句对表进行分区。所以项目中除了创建CDS定义文件,通常会创建一个.sql文件,激活CDS文件后在服务器端执行sql文件,用来增加表的comment、分区等。
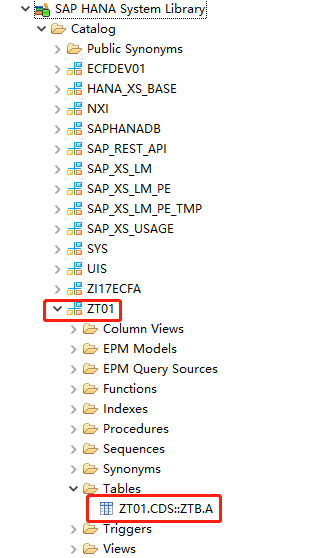
当我激活一个CDS设计期对象时:
会在数据库的catalog下面生成运行期对象,表名包含设计期对象的路径信息:
2. 计算视图
计算视图与HANA Modeling的内容基本一致,HANA建模可以参考之前的文章:
3. User-Defined Function
通过User-Defined Function可以将一些常用的或者较为复杂的逻辑抽离出来,模型中只需要通过输入参数调用,就可以返回计算结果。
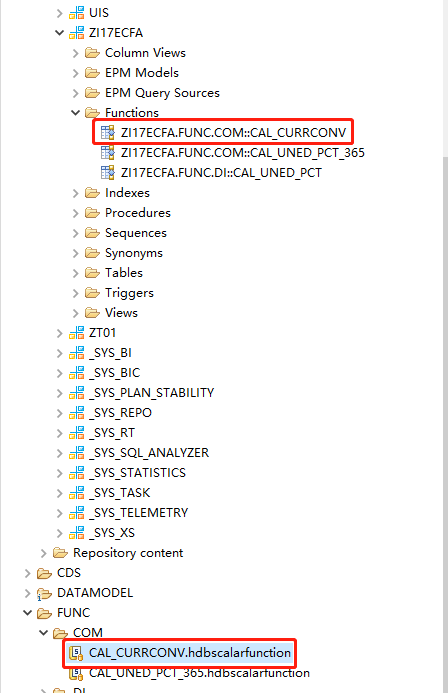
例如创建一个汇率转换的Function:
FUNCTION "ZI17ECFA"."ZI17ECFA.FUNC.COM::CAL_CURRCONV"/************************************************************# CREATE DATE : 2022-01-19# Latest Contact Info : xxxx@deloitte.com.cn# DESC : 汇率转换# MODIFY_NAME |MODIFY_DATE |MODIFY_DETAIL# libowen |2022-01-19 |CREATE#************************************************************/(IN_AMT DECIMAL(24, 10),IN_CURR_F NVARCHAR(5),IN_CURR_T NVARCHAR(5),IN_CURR_DATE DATE)RETURNS OUT_AMT DECIMAL(24, 10)LANGUAGE SQLSCRIPTSQL SECURITY INVOKER ASBEGINDECLARE CURRENCYRATE DECIMAL(24, 10) := 1;IF :IN_CURR_F = :IN_CURR_TTHEN OUT_AMT := :IN_AMT;ELSESELECT CURRENCYRATE INTO CURRENCYRATE FROM "_SYS_BIC"."ZI17ECFA.DATAMODEL.COM/EXRATE"WHERE CURRENCY = :IN_CURR_F AND EXCURRENCY = :IN_CURR_T AND EXDATE = :IN_CURR_DATE;OUT_AMT := :IN_AMT * :CURRENCYRATE;END IF;END;
同样,激活设计期对象会在catalog下面生成运行期对象。
可以在SQL中调用这个Function:
SELECT "ZI17ECFA"."ZI17ECFA.FUNC.COM::CAL_CURRCONV" (IN_AMT,IN_CURR_F,IN_CURR_T,IN_CURR_DATE) AS AMT_CONV FROM DUNNY;
4. 存储过程
语法和SQL基本一致,只是开头的
CREATE PROCEDURE ......
变为 PROCEDURE ......
放一个模板作为示例:
PROCEDURE "ZI17ECFA"."ZI17ECFA.PROC.ASS::PROC_0011_R_MSR_IC"/**********************************************************# CREATE DATE : 2022-03-01# DESC : 分入-计量粒度结果-投资成分# MODIFY_NAME |MODIFY_DATE |MODIFY_DETAIL# libowen |2022-03-01 |CREATE#**********************************************************/(IN P_IN_JOB_SESSION VARCHAR(255), --IDOUT P_OUT_WF_STATUS VARCHAR(1), --工作流状态IN IN_EPERIOD NVARCHAR(6), --评估期间IN IN_BUKRS NVARCHAR(4) --公司代码)LANGUAGE SQLSCRIPTSQL SECURITY INVOKERASBEGIN/*************************声明变量*************************/DECLARE RUN_STATUS NVARCHAR(2) DEFAULT 'S';DECLARE INS_ROW_COUNT BIGINT DEFAULT ;DECLARE PARAMETERS_LIST NVARCHAR(1000) DEFAULT 'IN_EPERIOD = ?; IN_BUKRS = ?;';DECLARE l_successful BIGINT := ;DECLARE l_offset BIGINT := ;/********************程序主体逻辑**BEGIN********************/DECLARE EXIT HANDLER FOR SQLEXCEPTION BEGIN -- Catch the exception and exitRUN_STATUS := 'E';P_OUT_WF_STATUS := :RUN_STATUS;PARAMETERS_LIST := 'IN_EPERIOD = '||:IN_EPERIOD||'; '||'IN_BUKRS = '||:IN_BUKRS||';';CALL "ZI17ECFA"."ZI17ECFA.PROC.CONF::PROC_LOG_INS"(NEWUID(),CURRENT_TIMESTAMP,:P_IN_JOB_SESSION,::CURRENT_OBJECT_NAME,:PARAMETERS_LIST,:RUN_STATUS,::ROWCOUNT,::SQL_ERROR_CODE,::CURRENT_LINE_NUMBER,LEFT(::SQL_ERROR_MESSAGE,5000));END;PARAMETERS_LIST := 'IN_EPERIOD = '||:IN_EPERIOD||'; '||'IN_BUKRS = '||:IN_BUKRS||';';SELECTCOUNT(*) into l_successfulFROM"_SYS_BIC"."ZI17ECFA.DATAMODEL.ASS.COM/CAL_0002_R_MSR_IC"(PLACEHOLDER."$$IN_EPERIOD$$" => :IN_EPERIOD,PLACEHOLDER."$$IN_BUKRS$$" => :IN_BUKRS);DELETE FROM "ZI17ECFA"."ZI17ECFA.CDS.ASS::COM.R_MSR_IC"WHERE EPERIOD = :IN_EPERIOD AND (:IN_BUKRS = 'ALL' OR BUKRS = :IN_BUKRS); -- DELETEWHILE l_offset < l_successful DO -- Insert result in chunks of 10 million, so that commit buffer is not overloadedINSERT INTO "ZI17ECFA"."ZI17ECFA.CDS.ASS::COM.R_MSR_IC"("EPERIOD","EDATE","RI_TYPE","SUBPRISKCODE","ORG_ID","BUKRS","RBUSA","CHANNEL","CUSTTYPE","HBBS","ICG_ID","MSR_APPROACH","PL_FLG","ICP_ID","NI_FLG","CCY","INT_REC_MM","C_RECIC_PREM_CP","C_RECIC_PREMBD_CP")SELECT"EPERIOD","EDATE","RI_TYPE","SUBPRISKCODE","ORG_ID","BUKRS","RBUSA","CHANNEL","CUSTTYPE","HBBS","ICG_ID","MSR_APPROACH","PL_FLG","ICP_ID","NI_FLG","CCY","INT_REC_MM","C_RECIC_PREM_CP","C_RECIC_PREMBD_CP"FROM"_SYS_BIC"."ZI17ECFA.DATAMODEL.ASS.COM/CAL_0002_R_MSR_IC"(PLACEHOLDER."$$IN_EPERIOD$$" => :IN_EPERIOD,PLACEHOLDER."$$IN_BUKRS$$" => :IN_BUKRS) LIMIT 10000000 OFFSET :L_OFFSET with hint(no_cs_limit);L_OFFSET := L_OFFSET + 10000000 ;INS_ROW_COUNT := INS_ROW_COUNT + ::ROWCOUNT;END WHILE; -- Insert resultsRUN_STATUS := 'S';IF RUN_STATUS = 'S' THEN -- success logCALL "ZI17ECFA"."ZI17ECFA.PROC.CONF::PROC_LOG_INS"(NEWUID(),CURRENT_TIMESTAMP,:P_IN_JOB_SESSION,::CURRENT_OBJECT_NAME,:PARAMETERS_LIST,:RUN_STATUS,:INS_ROW_COUNT,'',::CURRENT_LINE_NUMBER,'');END IF;P_OUT_WF_STATUS := :RUN_STATUS;/********************程序主体逻辑****END********************/END;/* CALL SyntaxCALL "ZI17ECFA"."ZI17ECFA.PROC.DI::PROC_0011_R_MSR_IC"(P_IN_JOB_SESSION => '',P_OUT_WF_STATUS =>?,IN_EPERIOD => '201912',IN_BUKRS => 'ALL');*/
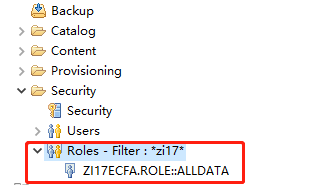
5. Role
定义角色,用于分配权限,示例语法如下:
role ZI17ECFA.ROLE::ALLDATA {schema ZI17ECFA:ZI17ECFA.hdbschema: ALTER,CREATE ANY,DEBUG,DELETE,DROP,EXECUTE,INDEX,INSERT,REFERENCES,SELECT,TRIGGER,UPDATE;}
激活后会在role里面查看到:
感谢大家阅读。
本文章仅代表作者个人看法。
