Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。
关于hbase的介绍,大家可以自行到官网介绍去了解,此文章着重介绍如何安装。
本例采用三台机器(centos7):
master01(192.168.47.130),slave01(192.168.47.131),slave02(192.168.47.132)
安装Apache Hive前提是要先安装hadoop集群,并且hive只需要在hadoop的namenode节点集群里安装即可(需要在有的namenode上安装),可以不在datanode节点的机器上安装。 本例在master01(本例的hadoop集群的namenode所在机器)节点上安装。
本例使用的安装包为:apache-hive-2.3.3-bin.tar.gz 下载地址:http://archive.apache.org/dist/hive/hive-2.3.3/
1,安装Hadoop
由于 Hive是运行上Hadoop的。故安装Hive之前,需先安装Hadoop, 关于Hadoop的安装可以参考之前的文章链接:手把手教你安装Apache Hadoop
2,安装Hive
本例Hive安装在master01(hadoop集群的namenode节点)机器上。
master01机器使用命令:tar -zxvf apache-hive-2.3.3-bin.tar.gz 解压hive安装文件,使用命令:mv ./apache-hive-2.3.3-bin /usr/local/ 将hive移动到/usr/local/目录下。
所有的配置文件位于:ll apache-hive-2.3.3-bin/conf/
2.1 配置hive-evn.sh
使用命令:cp ./apache-hive-2.3.3-bin/conf/hive-evn.sh.template ./apache-hive-2.3.3-bin/conf/hive-evn.sh 复制并重命名hive-evn.sh.template为hive-env.sh-文件。
使用命令:vim ./apache-hive-2.3.3-bin/conf/hive-evn.xml 打开
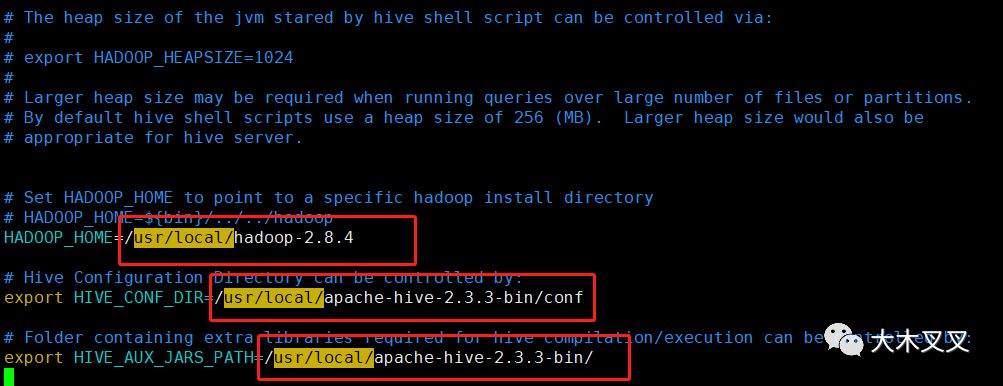
配置红框中的hadoop和hive环境变量地址,实际情况根据自己安装的目录配置。
2.2 配置hive-site.xml
使用命令:cp apache-hive-2.3.3-bin/conf/hive-default.xml.template apache-hive-2.3.3-bin/conf/hive-site.xml复制并重命名hive-default.xml.template为hive-site.xml文件。
下面第3步具体配置内容。
2.3 配置hive-log4j2.properties
使用命令:cp apache-hive-2.3.3-bin/conf/hive-log4j2.properties.template apache-hive-2.3.3-bin/conf/hive-log4j2.properties复制并重命名hive-log4j2.properties.template为hive-log4j2.properties文件。
2.4 配置hive-exec-log4j2.properties
使用命令:cp apache-hive-2.3.3-bin/conf/hive-exec-log4j2.properties.template apache-hive-2.3.3-bin/conf/hive-exec-log4j2.properties复制并重命名hive-exec-log4j2.properties.template为hive-exec-log4j2.properties文件。
2.5 在hdfs上新建目录
使用以下命令在hdfs上创建目录:
hdfs dfs -mkdir -p /user/hive/warehouse (hive-size.xml文件中配置hive.metastore.warehouse.dir的value值对应)
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod -R 777 /user/hive/warehouse
hdfs dfs -chmod -R 777 /user/hive/tmp
hdfs dfs -chmod -R 777 /user/hive/log
2.6 在本地磁盘新建tmp目录
数据命令:mkdir ./apache-hive-2.3.3-bin/tmp 在hive安装目录下创建tmp文件夹。
并在 hive-site.xml 中修改
把
{system:java.io.tmpdir}改成 /usr/local/apache-hive-2.3.3-bin/tmp把
{system:user.name}改成{user.name}
2.7 配置hive环境变量
输入命令:vim ~/.bashrc

其中具体的目录按照自己的安装目录配置。配置环境变量可以方便启动或者停止hive时不需要带上完整目录。
输入命令:source ~/.bashrc 使环境变量生效。
3,Hive初始化
由于Hive的元数据(如表定义)存储在derby数据库或者mysql里面。所有在使用hive之前需要,配置元数据的数据库。
3.1 使用derby数据库(本例不使用)
Apache Derby是一个完全用java编写的数据库,Derby是一个Open source的产品,基于Apache License 2.0分发。Apache Derby非常小巧,核心部分derby.jar只有2M,所以既可以做为单独的数据库服务器使用,也可以内嵌在应用程序中使用。下载链接http://db.apache.org/derby/。
初始化derby作为hive元数据存储命令:
$HIVE_HOME/bin/schematool -dbType "derby" -initSchema
使用derby数据库的优缺点如下:
好处:不需要额外安装
缺点:derby只允许单连接,无法两个客户端连接到hive(不适合多人使用);
不建议使用derby数据库。
3.2 使用mysq数据库(本例使用)
本例使用mysql数据库作为hive的元数据存储, 关于mysql的安装,可以参考链接https://blog.csdn.net/lym152898/article/details/77319676。
3.3 拷贝数据库驱动包
拷贝jar文件mysql-connector-java-5.1.42.jar到hive安装目录的lib文件夹下。

3.4 配置hive-size.xml
使用命令: vim ./apache-hive-2.3.3-bin/conf/hive-site.xml打开
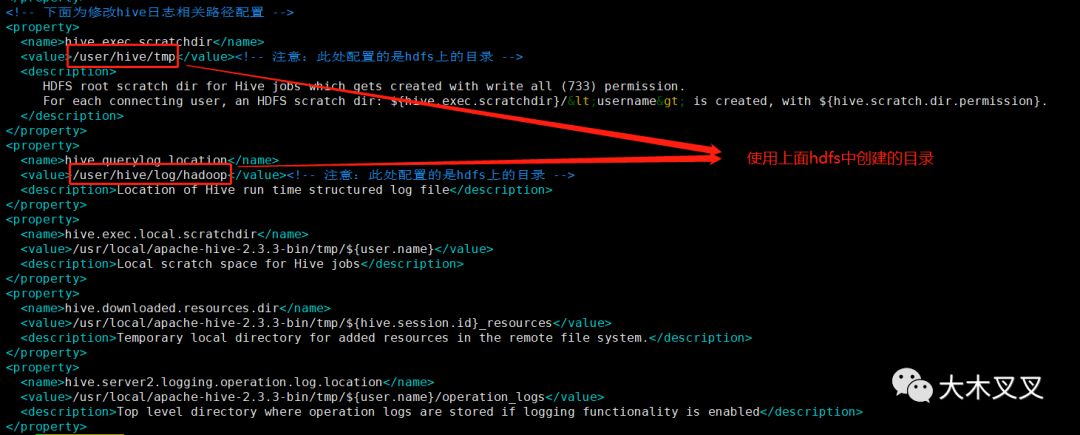

3.5 初始化hive原数据
使用命令: schematool -dbType mysql -initSchema 初始化数据库,初始化完毕后,进入mysql客户查看多了一个名为hive的数据库。
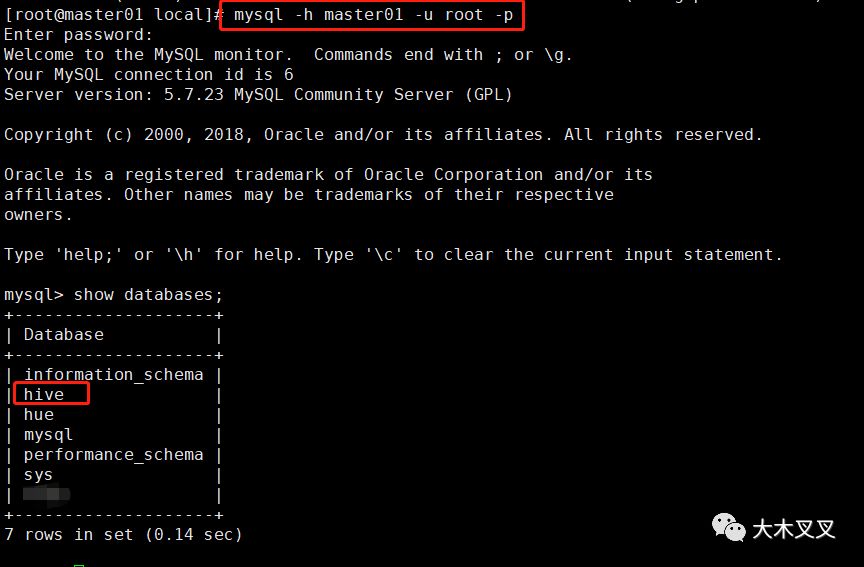
上图可以看出mysql中初始化生成了一个名为hive的数据库。
4,Hive启动
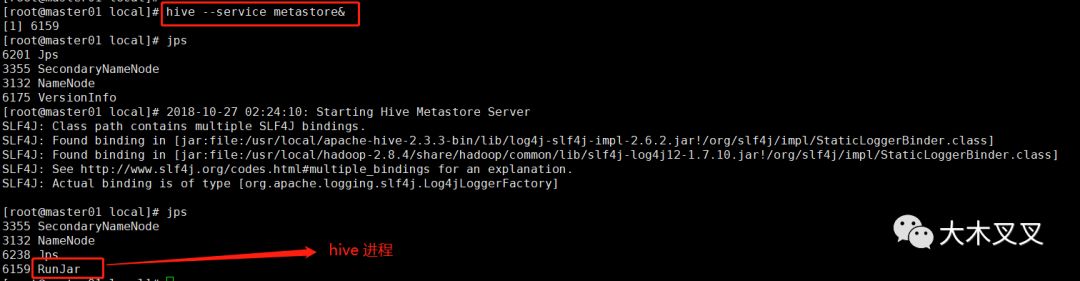
4.1 启动hive服务端
使用命令:
hive --service metastore 2>&1 >> /dev/null & 或 hive --service metastore & 启动
hive --service hiveserver2 & 启动
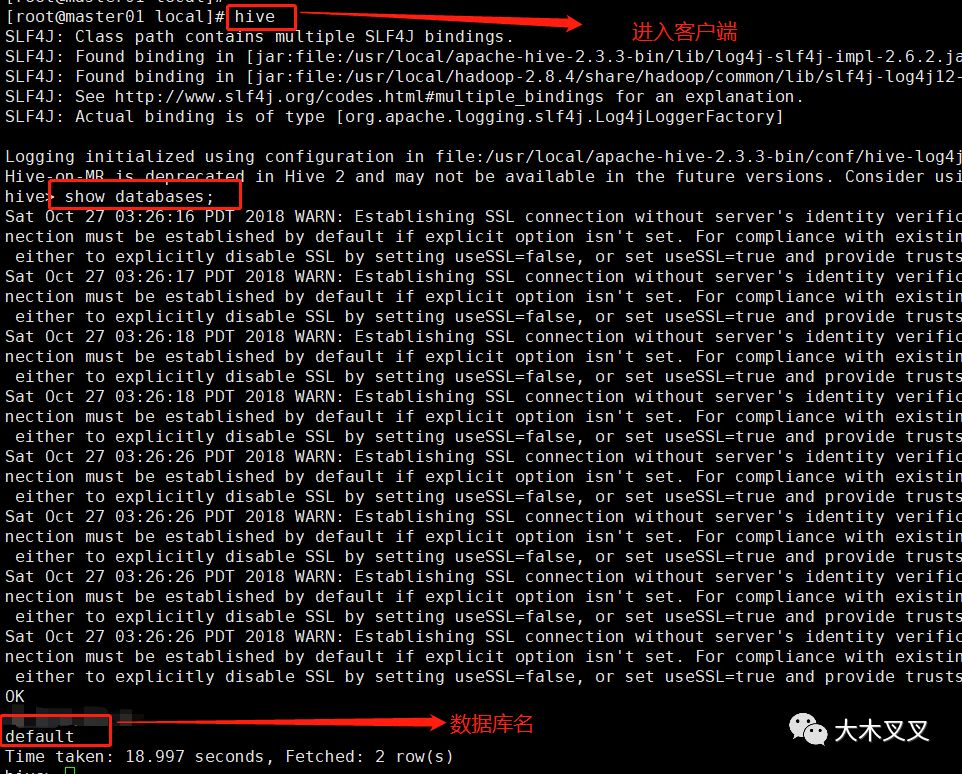
4.2 启动hive客户端
使用命令:hive 启动客户端; 使用命令:show databases; 查看hive的数据库, 数据库存储在hdfs的/user/hive/warehouse文件夹中。
5,Hive操作
进入hive客户端后操作。
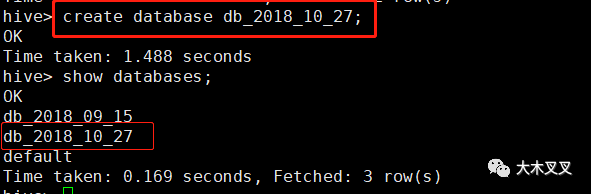
5.1 创建数据库:
5.2 创建普通表:
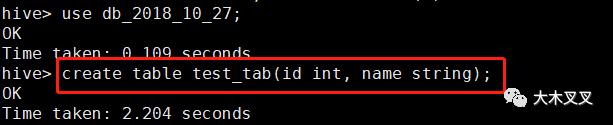
5.3 插入数据
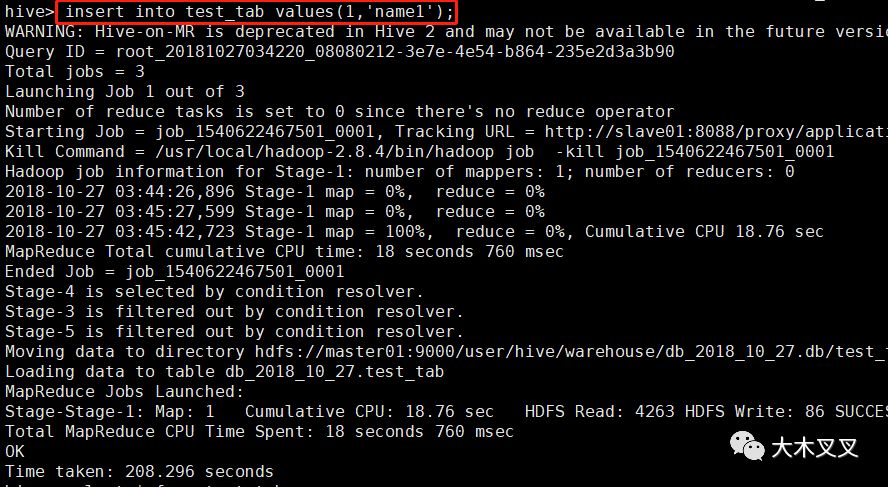
5.4 查询数据

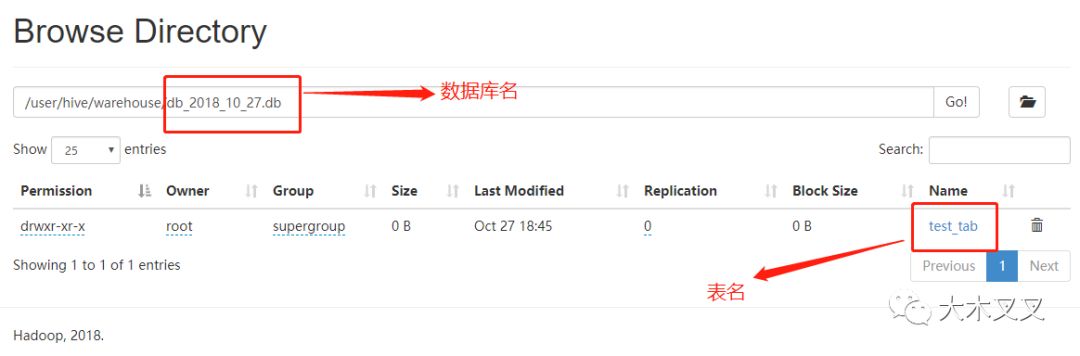
5.5 hdfs查看表数据
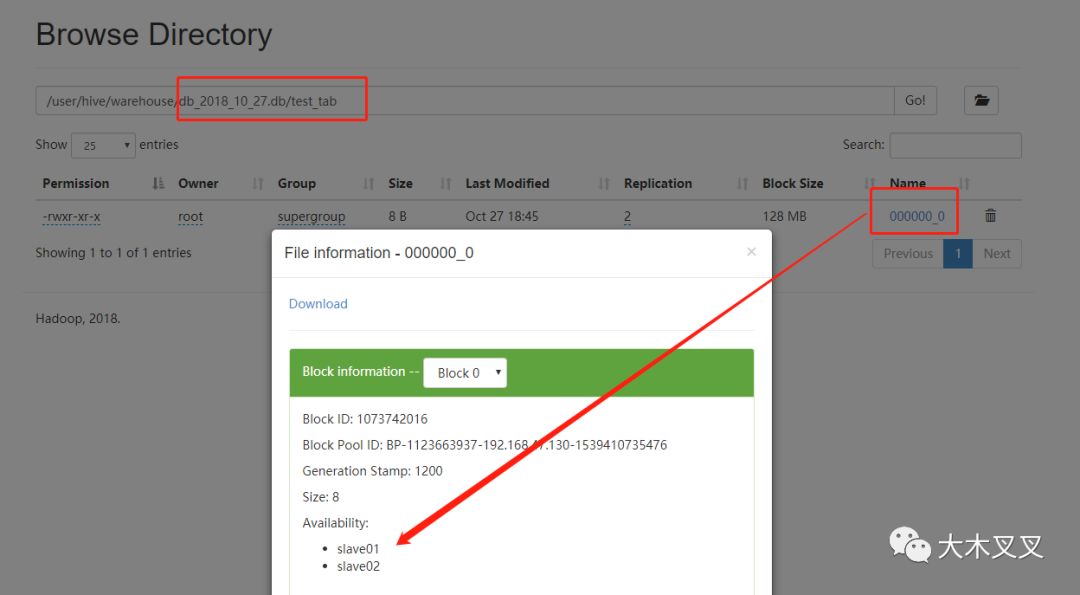
5.6 hdfs查看数据
5.7 创建指定分隔符的文件型表
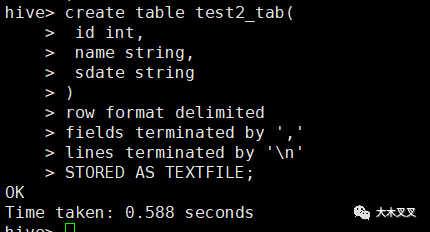
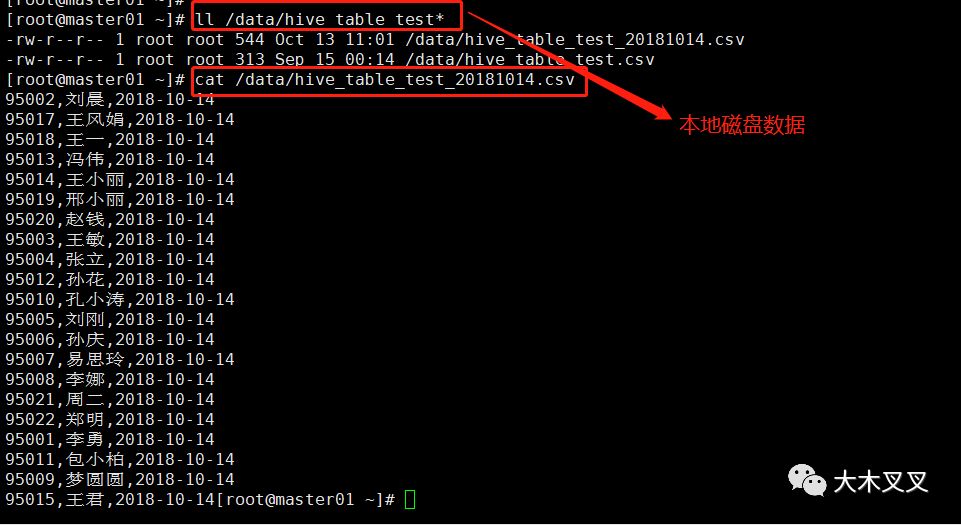
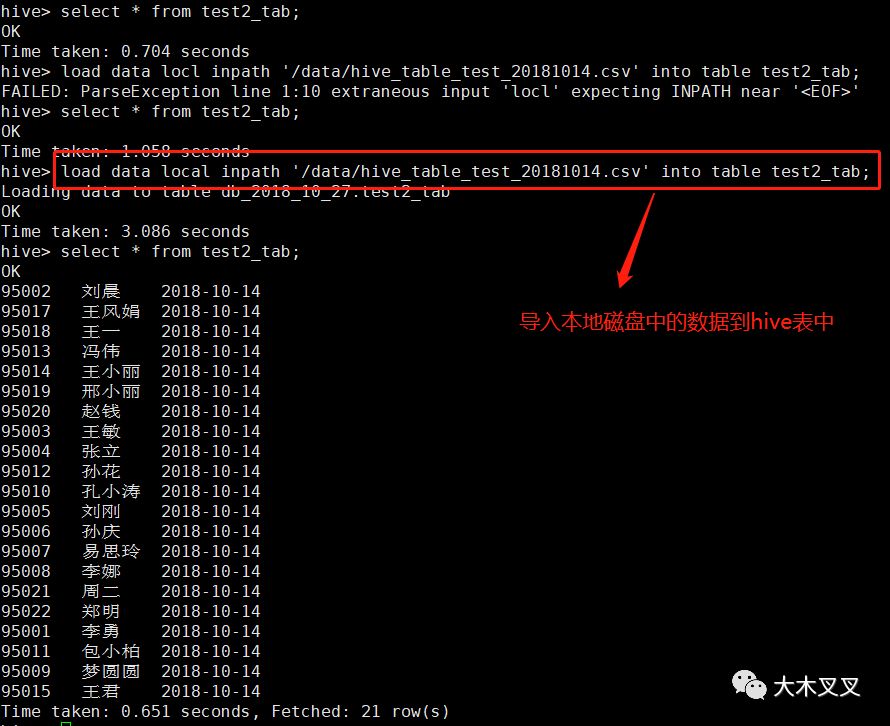
5.8 导入【本地磁盘文件】数据到hive表中
语法:load data local inpath '本地磁盘文件路径' into table '表名';
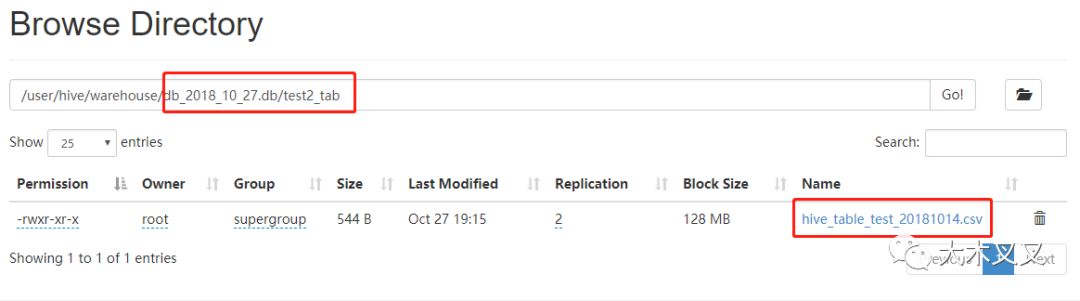
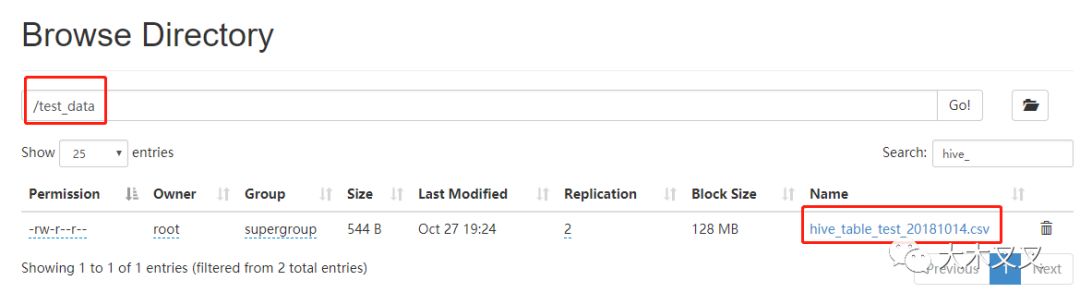
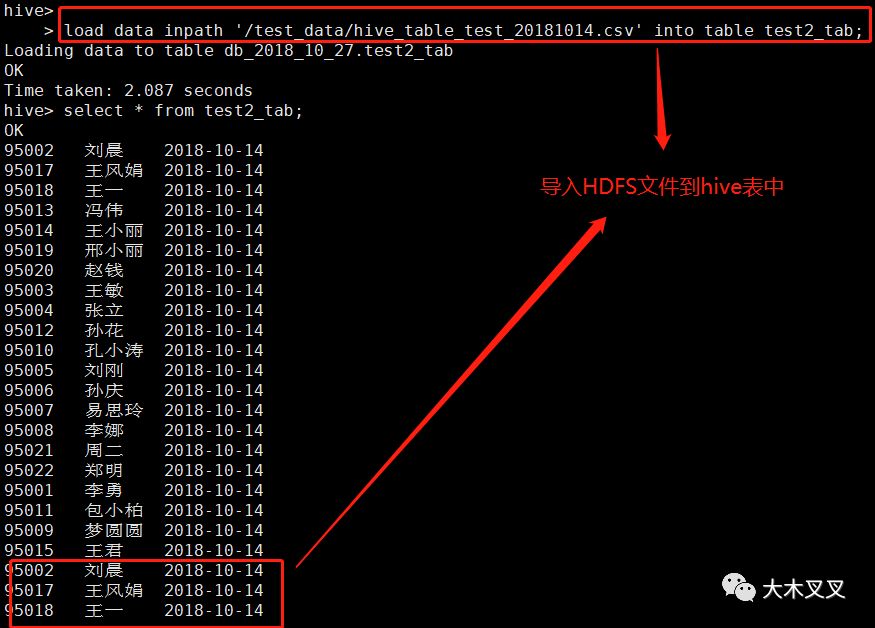
5.9 导入【HDFS文件】数据到hive中
语法:load data inpath 'HDFS文件路径' into table '表名';

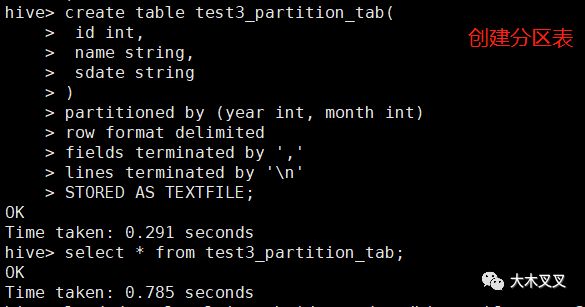
5.10 创建分区表
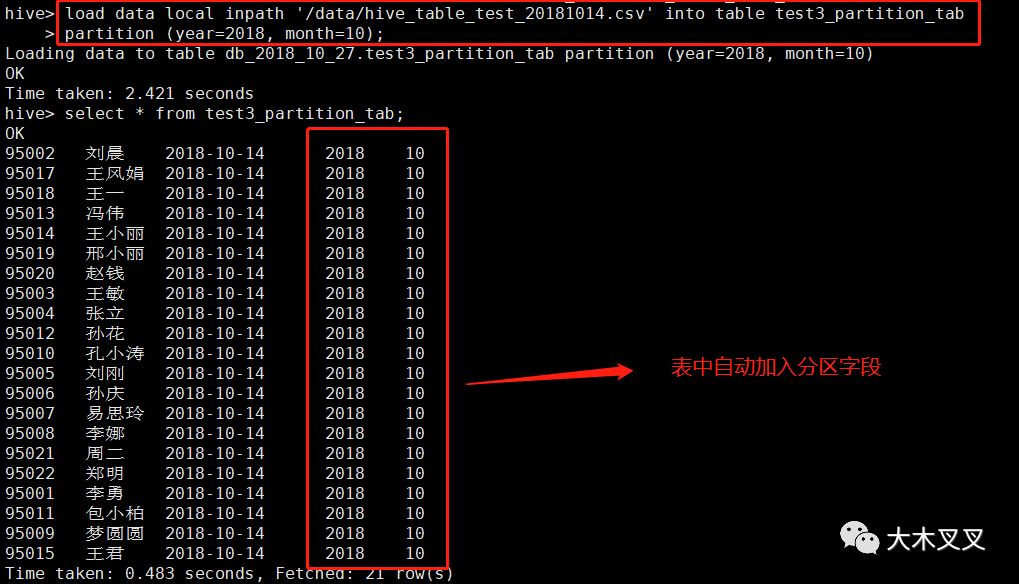
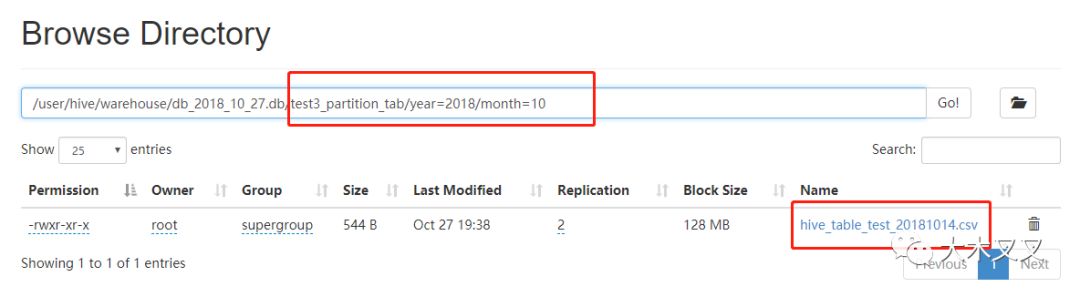
可以看出在hdfs中按year,month分目录(分区原理)。
5.10 其他的hive命令
关于其他的hive shell操作,可参考链接:https://www.cnblogs.com/guanhao/p/5641675.html ,此处不做过多的介绍。
6,Hbase导入Hive
关于Apache Hbase的安装和介绍参考链接: 手把手教你安装Apache HBase
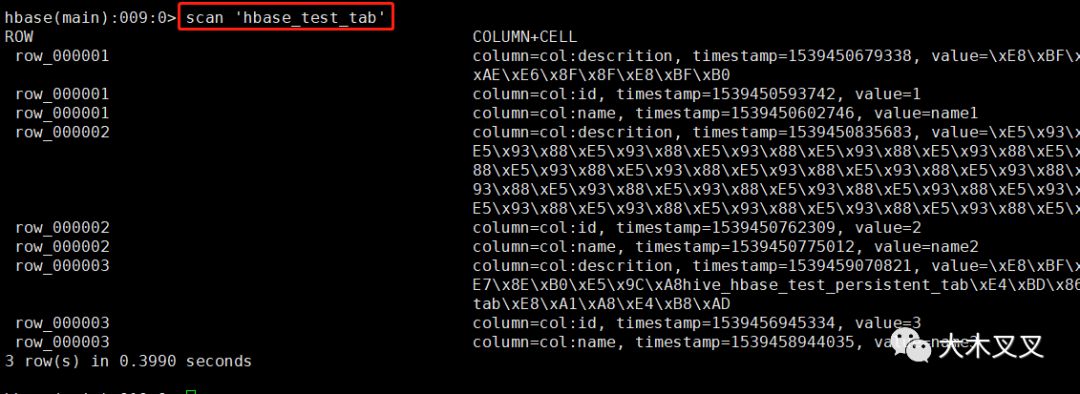
6.1 查看要导入hive的Hbase的表数据
6.2 hive创建关联Hbase的hbase_test_tab表的表hive_hbase_test_tab
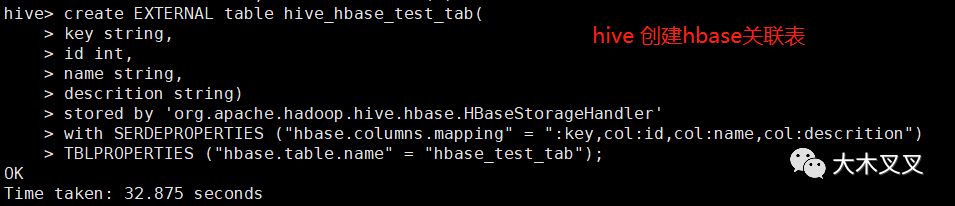
上图中创建了一个关联hbase中hbase_test_tab表的hive表hive_hbase_test_tab。
注意:external 修饰词代表外部表(external table),即数据不是由hive自身管理的,由hdfs管理,即此处的HBase管理。
6.3 hive查询表hive_hbase_test_tab数据

我们可以看到hbase中表hbase_test_tab的数据,可以从hive表hive_hbase_test_tab中查询到。
6.4 hbase插入数据,查看hive表的变化
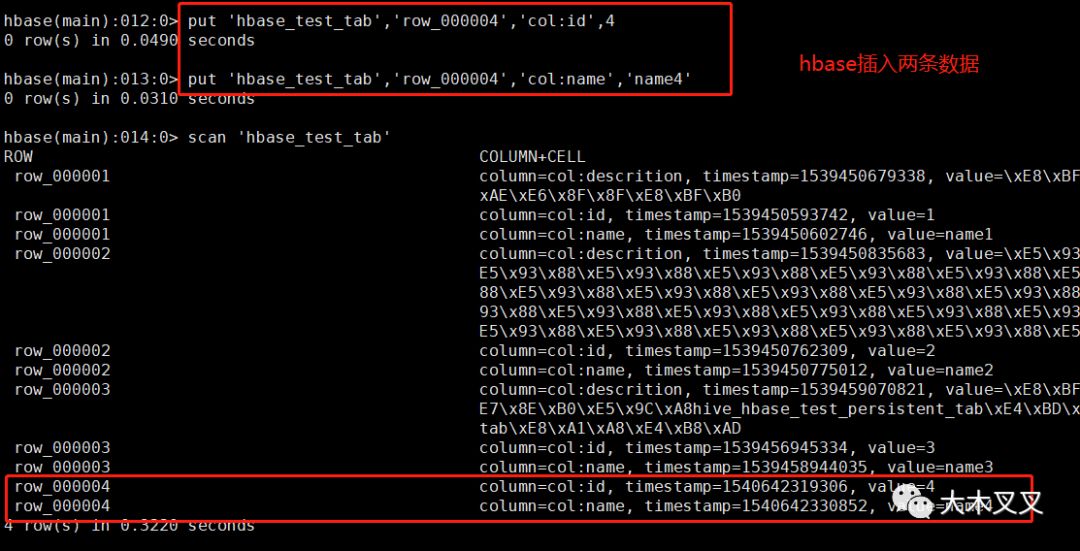

我们可以看到,hbase刚插入的数据,hive中可以查询出来,说明hive中这张表使用外部(非hive自行管理)hbase中的数据。会跟着hbase的数据动态变化。
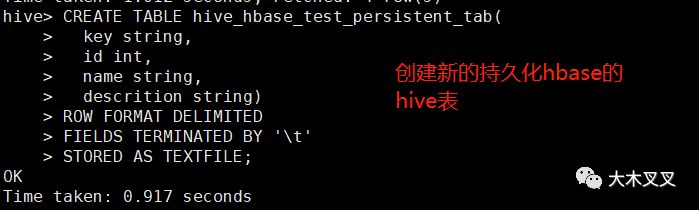
6.5 hbase持久化到hive表
若想把hbase中的数据持久化到hive表中,不让hive查到的数据跟随着hbase的变化。一种方式是,创建新的hive表,然后将hive关联hbase的表结果集插入到新表中。
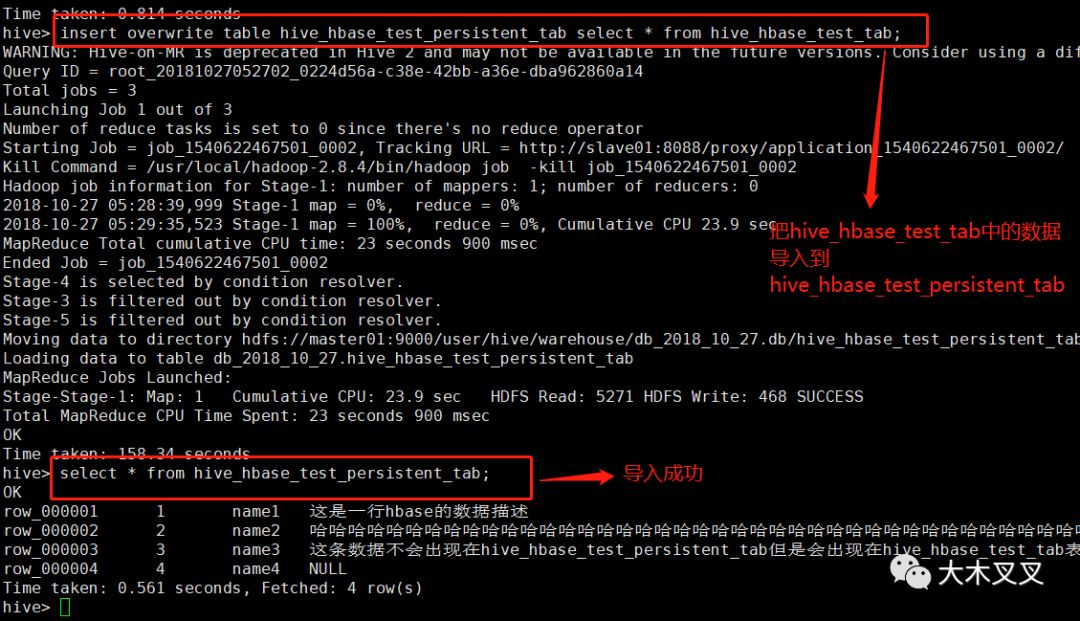
可以看到新的hive数据表也有数据了。再来看看hadfs中两个表的区别。
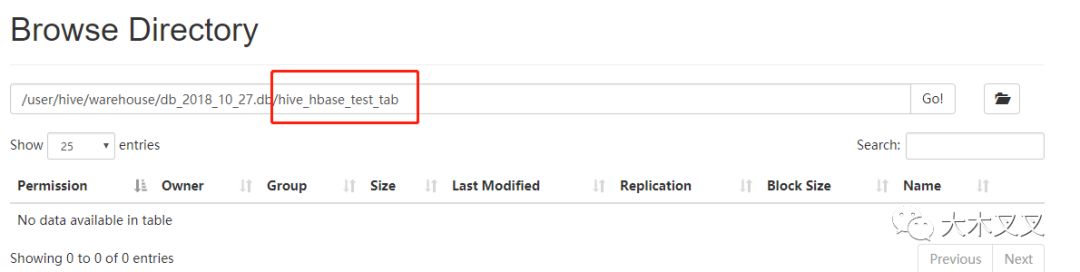
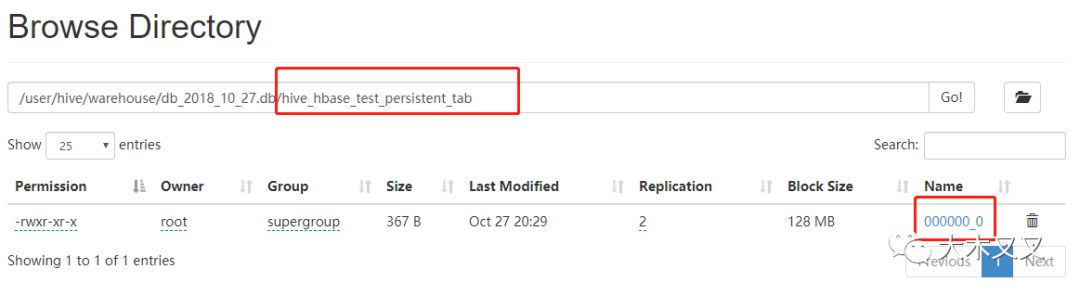
从上面可以看出hive_hbase_test_tab在HDFS中不占任何资源,而hive_hbase_test_persistent_tab中占资源。
6.6 验证hive持久化表是否跟随hbase变化
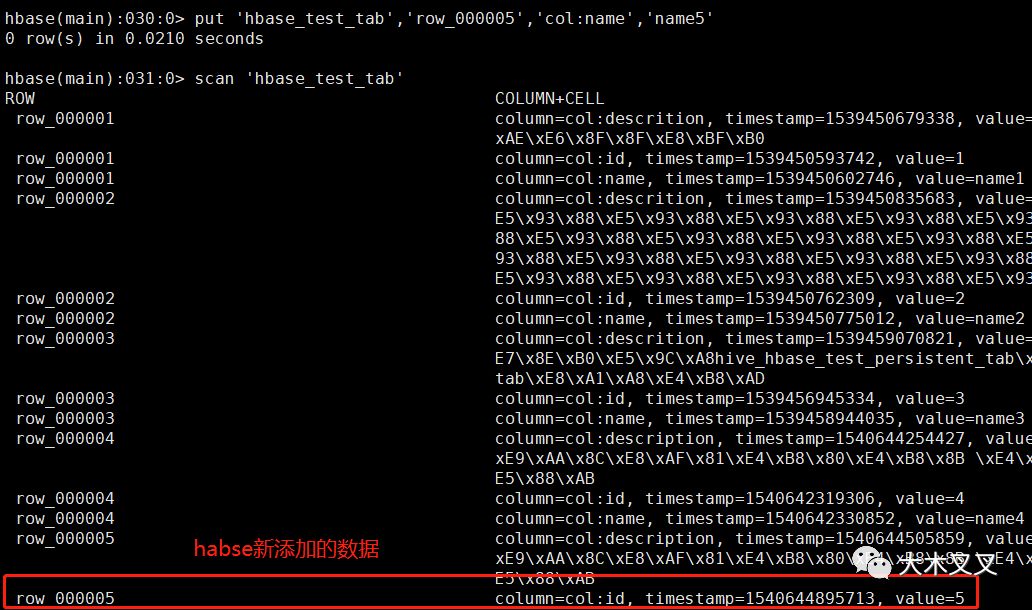
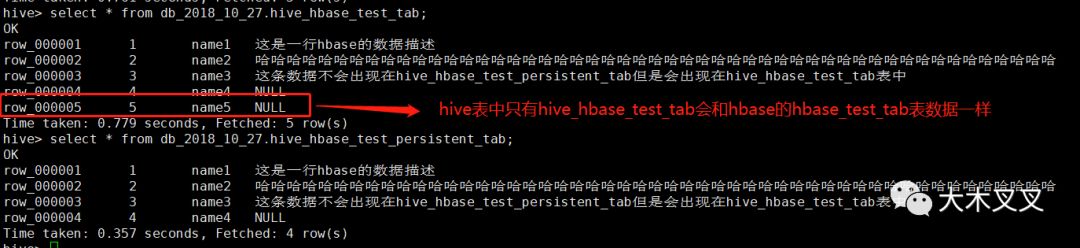
可以看出hive中的只有和hbase关联的外部表数据才会跟随hbase数据变化而变化。
7,总结
关于更多关于hive的知识,请到互联网中自行查找,本教程介绍到这。

来自:https://mp.weixin.qq.com/s/sAldjSGK5zu1r4cjX9xUlQ
