总体架构
谷歌设计Spanner的一个重要目标是对全球范围内的数据库进行管理,为了更加清晰有效地划分和管理数据,Spanner划分了多个层级。其中,的是Universe,在论文中谷歌表示目前只有三个Universe,包括一个用于测试或后台运行的Universe,一个用于部署或生产的Universe和一个仅用于生产的Universe。每个Universe下面包含多个Zone,每个Universe使用UniverseMaster和PlaceDriver检测和管理Zone,这里的Zone就相当于Bigtable的Server,对应实际情况中的一台或多台物理机器。而每个Zone中有一个ZoneMaster管理多个LocationProxy和数百至数千个SpannerServer,其中,LocationProxy负责将客户端的请求转发到对应的SpannerServer。论文中给出的示意图如下:
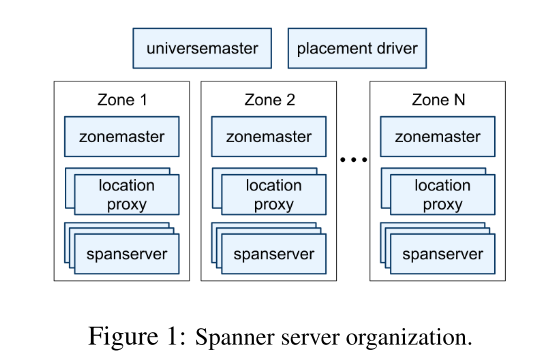
论文中仅仅披露了SpannerServer的具体内容,所以下面我们也只讨论SpannerServer。由于Spanner是为了代替Bigtable而设计的,所以SpannerServer的内部架构其实和Bigtable有一点类似,但是Spanner又作出了很多优化。内部架构的示意图如下:
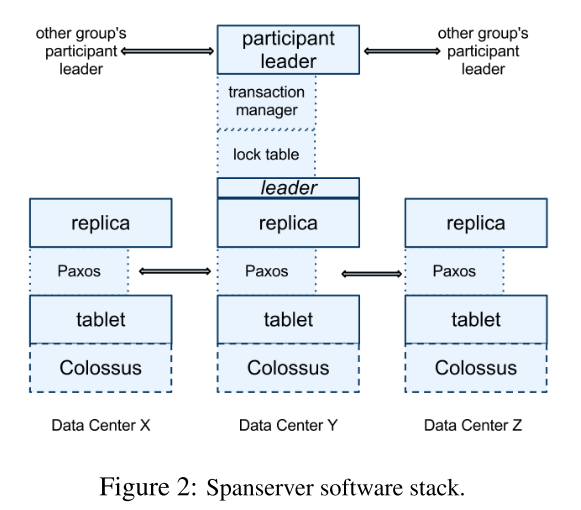
这张示意图以三副本的情况为例介绍了Spanner Server的内部架构。Spanner和Bigtable相似的地方在于,他们都基于分布式的文件系统GFS,这里的Colossus是第二代GFS,具体的实现细节仍未公布,而且他们都使用了Tablet作为单位管理存储数据,但是,这里的Tablet和Bigtable中Tablet是有些不同的。但是再上面一层就有些不同了,因为Bigtable中数据基于爬虫获得而且使用了SSTable存储数据,这保证了数据的性,所以在Bigtable中没有使用具体的算法保证数据的一致性,但也因为这一点,Bigtable没有很好地支持事务。Spanner中使用了多副本的机制备份数据,同时在副本之间使用Single Paxos算法保证了数据一致性,在这里,谷歌可能是为了提高Paxos算法的性能并降低耦合,他们并不是把整个机器作为Paxos算法的基本角色,而是将机器中的数据分割为多个Paxos Group,每个机器中的相同数据被标识为同一Group,每次运行Paxos算法都仅由关联的Paxos Group参与。再往上一层就是各机器之间的关系了,Spanner使用主从结构管理副本,Leader节点要额外维护LockTable和Transaction Manager,其中LockTable的作用类似Bigtable中的Chubby,用于协调各副本之间的并发操作,Transaction Manager则用于管理分布式事务。Leader节点还要负责所有的写操作和和其他节点的沟通。
Paxos Group仍然是很大的操作单位,想要更加灵活地进行数据迁移工作就需要更小的数据单位。于是Spanner将每个Paxos Group分割为多个Directory,而每个Directory包含若干个拥有连续前缀Key的数据。不得不说,这里的连续前缀Key有点像SSTable的设计。Spanner将Directory作为物理位置记录的单元,同时也是均衡负载和数据迁移的基础单元。这很好理解,均衡负载是把请求转发到拥有相同数据的机器,数据迁移是把数据从一台机器复制到另一台机器,这两者都需要目的机器的物理地址,所以小只能把Directory作为单位。
Spanner把在Paxos Group之间迁移Directory设计为后台任务,但是由于数据迁移可能造成读写阻塞,所以它不被设计成事务。操作的时候是先将实际数据移动到指定位置,然后再用一个原子的操作更新元数据,完成整个移动过程。
这里要特别说明的是,Spanner中的Tablet和Bigtable中的Tablet有些不同。Bigtable中的Tablet可以简单地看做是若干连续的有序记录,而Spanner中的Tablet则被设计成一种容器,其不一定是连续的有序记录,而可能包括多个副本的数据。
数据模型
Spanner和Bigtable的数据模型差别也很大,其数据模型如下。很容易地可以发现,其从Bigtable中类似于关系型的数据库变成了类似于K-V的数据库。
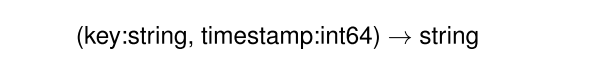
这种变化重要的原因是Bigtable的数据模型仅适用于类似PageRank等数据格式长期稳定且不怎么变化的任务,如果任务需要快速版本迭代可能就不再使用。
另一方面,在Google内部有一个Megastore数据库,尽管要忍受性能不够的折磨,但是在Google有300多个应用在用它,包括Gmail, Picasa, Calendar, Android Market和AppEngine。而这仅仅因为Megastore支持一个类似关系数据库的语法和同步复制。所以,Spanner决定支持数据库的语法,论文中说这种语法类似于SQL语句。其结果如下:
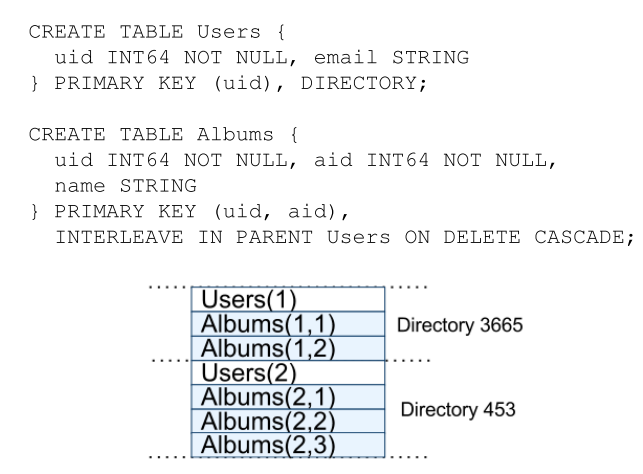
可以看到,Spanner底层的存储结构仍然是K-V的形式,但是在创建Albums的表时,其指出了父类表为User,那么在Directory中组织成了上图中关联的User和Albums相邻的形式。那么在进行SQL查询的时候,就可以通过顺序读写得到数据,相比随机读写要快得多。
TrueTime
前面讨论了Spanner总体架构,内部架构以及数据模型,平常的论文可能到此就结束了,但是这篇论文到这里进入重要的部分,因为Spanner引入了一个开创性的想法,使用TrueTime标记时间。而TrueTime指的是真实的时间戳,谷歌使用GPS和原子钟两个物理元件得到这个时间。正常情况下使用GPS获取该时间,如果GPS由于电波影响不能工作,那么原子钟就会接替任务直到GPS恢复工作。Spanner中提供了三个和其相关的API,如下图所示:

其中,TT.now()返回的值称为TTinterval,它不是一个确切的时刻,而是一段时间,包括早时间戳Earlist和晚时间戳Latest。因为全球范围内的时间总是不可能完全同步,各机器的通信也有延迟,所以只要在一个时间段内,他们就认为是同步的。另外两个函数的伪代码定义如下
TT.after(t) = TT.now().earliest > t.latest
TT.before(t) = TT.now().latest < t.earliestSpanner给每个数据中心都安装了TrueTime系统,有了这三个API,Spanner就能判断两个时间戳的先后关系了,再以此为基础,就能实现很多功能。
并发控制
TrueTime是相当强大的工具,下面的表列举了Spanner支持的事务类型:
Leader Leases
在讨论事务之前,我们回到Paxos算法上。与Raft使用的解决方案不同,Spanner不使用Heartbeats来检测是否有失效节点,而是使用Lease来规定Leader的任期。如果Leader执行了写操作,那么它的Lease会自动延长。否则,Spanner默认每十秒Leader要发起续租Lease的请求,当收到Quorum的投票后会延长,反之就失去Lease,转变为Follower。
在这里,Spanner要求单个Paxos Group中的Leader Lease中的TrueTime要不相交,因为一旦相交,就意味同一时刻有两个Leader,这是不被允许的。所以,当Leader退出系统或者降级为Follower时,要保证TT.after(t)对每个副本都成立。
读写事务
Spanner保证了强外部一致性:如果一个事务T2开始(Start)在事务T1提交之后发生,那么T2的提交(Commit)时间肯定比T1的提交时间大。简单地说,早到早完成,迟到迟完成。
Spanner使用2PC提交事务,为了保证外部一致性,Spanner对每个事务作出以下两点要求:
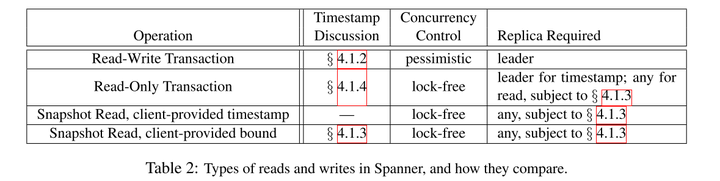
Start:事务T的协调者Leader分配了一个提交时间戳S,S不小于TT.now().latest并且S不早于Commit请求到达时间
Commit Wait:Spanner保证只有当当前时间晚于事务T的提交时间后,其他成员才能看见。
论文中的符号表示如下

事务事件事务事件请求到达中事务完成事件该事务完成的真实时间事务的时间戳
那么上述的要求就变为
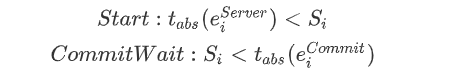
有如下推断

所以,只要满足上述两个要求,就能实现外部一致性。而Spanner中使用Coordinate Leader来实现这两个要求。
另外,还需要保证任意时间读取到的数据都是可靠的安全的。Spanner通过规定安全时间保证任意时间的读。论文中安全时间的定义为

算法能保证的安全时间事务管理器能保证的安全时间
其中,Paxos算法能保证的安全时间是近Paxos算法写入数据的时间。事务管理器能保证的安全时间在,没有事务处于Prepare阶段的情况下,是无限大的。因为它无法确定第二阶段的事务可能发生什么。如果有事务已经完成Prepare阶段,那么它的值就是完成Prepare阶段的事务中早的时间-1。在这个时间前,事务管理器能保证所有已提交的数据都被看见。只要读取的数据在这个时间之前,那么这个数据就是安全的。
以下是读写事务的具体流程
- 执行读操作时,Spanner先找到相关数据的副本,然后加上读锁并读取新的数据。在事务开启的时候,客户端会发送Keeplive消息防止超时。
- 当客户端完成了所有的读操作并缓存了所有的写操作,就准备开始2PC。客户端选择一个Coordinator Group,并给每一个相关的Leader发送Coordinator的id和缓存的写数据。
- 每个和事务相关的Leader(除了Coordinator Leader)会尝试得到一个写锁,然后选取一个比现有事务晚的时间戳并通过Paxos发送给其他副本。(这里是为了保证上面的假设)
- Coordinator Leader一开始也会上个写锁,但是会跳过Prepare阶段。当接受到其他Leader的时间戳之后,他会选择一个提交时间戳。这个提交的时间戳必须满足Start保证并且大于所有完成Prepare阶段的时间戳(安全读取保证)。然后将这个信息通过Paxos记录下来。
- Coordinator必须等到TT.after(S)成立才能在副本提交事务。这是为了满足Commit Wait保证。这需要等两倍时间误差,大约是20ms。
- 然后Coordinator将提交时间戳发送给客户端还有其他的副本。
只读事务
一个只读的事务会分2阶段来执行:先给该事务分配一个时间戳,然后执行事务的读操作。相当于通过快照读来读取时刻S的值。那么只需要保证如下要求,由于时间永远向前,所以能保证读取的是新的数据。
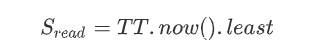
以下是只读事务的具体流程
- 由于读操作涉及多个Paxos Group,所以要通过协商阶段决定这个值Scope。
- 如果Scope只被一个Paxos Group处理,那么客户端会把只读事务发给那个的Leader。我们把LastTS()定义为Paxos组里后一个写操作提交的时间戳。如果没有prepare阶段的事务,那么让S = LastTS()就能满足要求。
- 如果Scope会被多个Paxos Group处理,Spanner当前的实现是一个简单的方案。客户端会让S = TT.now().latest,然后以S时间戳执行读操作。所有事务里的读操作都会被发送到数据足够新的副本。
总结
谷歌充分了利用了使用Bigtable的丰富经验,设计出了Spanner。Spanner的全球架构和内部架构虽然精巧,但和Amazon的Aurora比起来也没有过人的地方。但是,TrueTime的提出和其在事务中的使用实在令人惊叹。以前的工作,比如2PC的交互和Raft中的Index,又或者是现在流行的消息队列,几乎都是通过自增的主键或者是逻辑上的前置条件判断事务的先后。Spanner简单粗暴却优雅地使用了时间,这一永远自增不会重复的量解决了这个问题。同时使用时间还直接解决了全球范围内的数据同步这一问题,而这一问题直接使用逻辑上的先后是无法实现的。这应该是我在6.824这门课上读到的强的也是令人赞叹的系统了。
来源 https://zhuanlan.zhihu.com/p/338578860
