POLARDB是阿里巴巴自主研发的云原生关系型数据库,目前兼容三种数据库引擎:MySQL、PostgreSQL、Oracle。POLARDB的计算能力高可扩展至1000核以上,存储容量可达100TB。
POLARDB融合了商业数据库稳定、可靠、高性能的特征,同时具有开源数据库简单、可扩展、高速迭代的优势,适合各个行业公司的创新业务使用。本专场中,来自阿里云、江娱互动以及猿辅导的各位技术大咖一起共同探讨了下一代云原生数据库POLARDB。
1、云原生数据库的演进方向和客户价值
阿里云智能数据库总经理曹伟为大家介绍了云原生数据库的演进方向以及阿里云POLARDB数据库的产品能力。

阿里云RDS和POLARDB都属于OLTP的关系性数据库,那就让我们先看下全球关系型数据库的市场情况。
如今,关系型数据库依旧是“老大哥”,但是过去的十年中关系型数据库领域也发生了一些微妙的变化。伴随着开源运动的兴起和MySQL、PostgreSQL等数据库的出现,很多用户开始在生产系统中大量使用开源数据库,因此商业数据库的市场受到了一定的挤压。
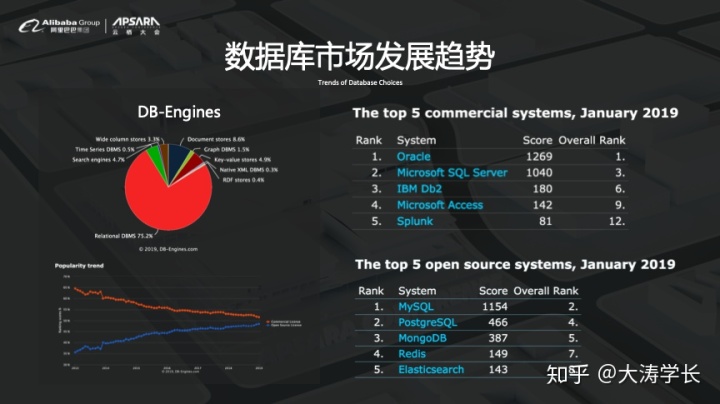
开源数据库的出现影响了整个数据库市场的格局和版图,也为阿里巴巴在数据库市场提供了一个重大的机会。经过十年的时间,阿里云数据库做到了“,全球领先”。当然,影响数据库格局的重要因素除了开源之外,还有云计算的兴起。
在云时代,数据库的演化经历了从采购License自建到云上托管数据库再到云原生数据库的转变。过去云是云,数据库是数据库,数据库只是部署在云上。但在云原生时代,数据库和云是合二为一的,云就是数据库,数据库就是云。
云原生数据库具有以下的几个发展趋势:
弹性:弹性不仅仅是规格的弹性,而是未来CPU、容量等计算资源都可以按量付费。
HTAP:之前TP和AP是分开处理的,TP使用关系型数据库,而AP使用大数据存储。未来则会融合两者,提供一个入口跑事务,一个入口跑报表和BI。
智能:智能让数据库更加实用,未来数据库的磁盘备份、内存调度等都不需要DBA来操作,而是全部由数据库自己来完成。此外,数据库还能够自动完成诊断和修复。
混合云:因为一些合规的要求,并不是所有数据都能跑在云上,因此还需要使用这种云上云下互联的生态。
云原生数据库已经成为了一种趋势,智能和混合负载成为了用户使用数据库必须依赖的特性。而由于这些特性具有非常高的技术门槛,因此在未来的两到三年内,云原生技术落后的数据库厂商必将会被淘汰。
对于很多企业而言,如果采用自建数据库方案,那么无论是对于研发还是运维而言,都会带来很多痛点,比如:
活动上线时造成压力突增,而数据库却来不及升级;
业务发展很快,来不及进行拆库,也来不及分库分表;
应用扩容之后,上百台ECS连接一台数据库,因此在高并发下性能很差;
使用读写分离,但是刚更新的数据却查询不到;
主从复制经常中断;
一次全量数据备份需要大量时间,并且必须锁表等。
这些都是互联网公司在使用自建数据库时会遇到的问题。那么,如何解决这些问题呢?答案就是需要一个强大的云原生数据库。
因此,阿里云提供了POLARDB数据库。POLARDB基于业界先进的Shared-Everything架构,简单而言,就是借助高速的RDMA网络将所有数据库节点连接在同一网络下。POLARDB采用计算与存储分离的架构,数据节点是无状态的,因此一旦发生宕机可以随时进行迁移。
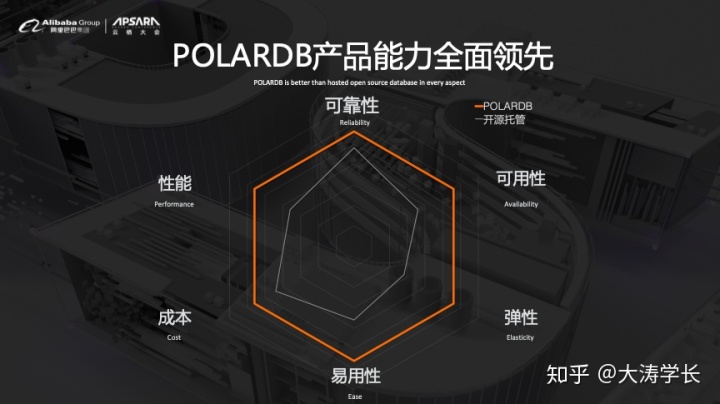
对于企业级数据库而言,一般会从可靠性、可用性、性能、弹性、成本和易用性这六个方面进行评价。
在可靠性方面,POLARDB基于Parallel Raft协议并借助RDMA能够做到RPO=0。此外,POLARDB基于TCP的远程物理复制技术实现了跨AZ的容灾。
在可用性方面,POLARDB借助Parallel Raft复制技术使得单节点存储切换RTO控制在10毫秒以内,基于Warm Buffer Pool技术使得读写节点重启速度加快4倍以上,并且基于跨节点物理复制技术使得日志并发应用的节点间延迟控制在100毫秒以内。
在性能方面,POLARDB使用了高速硬件和用户态I/O协议栈,使得计算节点的写延迟小于100us,而读带宽大于4GB/s。除此之外,还在I/O上进行了优化,借助Parallel Query技术使得TPC-H性能提升超过25倍。
在成本方面,POLARDB这样的云原生数据库的成本往往低于传统的托管数据库。这是因为企业在使用POLARDB时可以按需扩容,弹性伸缩,而这是在实现存储与计算分离的云原生架构诞生之前无法实现的。目前来看,相较于RDS,使用POLARDB将会使得成本降低约44%,这就是技术释放的红利。
在易用性方面,POLARDB可以兼容RDS,并且可以在阿里云上一键将RDS替换为POLARDB,此外还提供了智能读写分离、性能洞察以及SQL审计等的功能。
此外,POLARDB在2019年也实现了技术的全面升级。首先,POLARDB MySQL 8.0兼容版于9月12日正式发布,这是全球个兼容MySQL 8.0版本的云原生数据库。其次,POLARDB分布式数据库服务也正式发布,其存储容量支持多超过100TB。再次,POLARDB的高性能存储引擎X-Engine即将发布,X-Engine存储引擎具有高性能和高压缩率,并且经历了2018年双11的实战考验。此外,POLARDB对于Oracle的语法兼容性特性也即将实现商业化,能够为用户带来将近6倍的成本降低。此外,本次的云栖大会上还正式发布了POLARDB一体机,它能够更好地帮助用户在私有云上使用POLARDB数据库。
目前,阿里云POLARDB数据库已经成了增长快的云数据库产品,未来也将会提供更多的特性,为客户带来更多的价值。
2、POLARDB MySQL存储引擎优化实践
杨辛军(Jimmy Yang) 阿里云智能技术专家为大家介绍了阿里云POLARDB 8.0基于MySQL 8.0所做的存储引擎优化实践。

POLARDB实现了快速高效的物理复制,使得IO操作减少了50%,同时能够达到100T的存储容量。与此同时,相比于原本的逻辑复制,POLARDB的物理复制更加可靠、高效,并且对于性能影响几乎不可见。传统的逻辑复制比物理复制延迟大很多,而且可能会出现系统堵塞,对业务造成影响,物理复制则不会产生这样的影响。此外,POLARDB基于共享存储还实现了非堵塞、低延迟的DDL复制,并且支持快速动态的读扩展,高支持扩展到16个只读节点。
POLARDB是全球个具有高效物理复制的,共享存储并兼容MySQL 8.0的云数据库。POLARDB不仅包含了MySQL 8.0的所有重要功能,还在MySQL内核引擎的基础之上进行了大量的优化。
虽然POLARDB使用了物理复制,但是基于客户对于数据进行数据分析和传输需要Binlog的考虑,POLARDB也支持了Binlog。在性能优化方面,POLARDB新的“Copy Page”功能减少了主节点Flush Constraint。POLARDB对于逻辑锁系统进行了分区,减少了mutex的冲突,并且将死锁检测实现了并行化。POLARDB对于Transaction System也进行了优化,使用Lock Free数据结构来管理Transaction System的Lists。
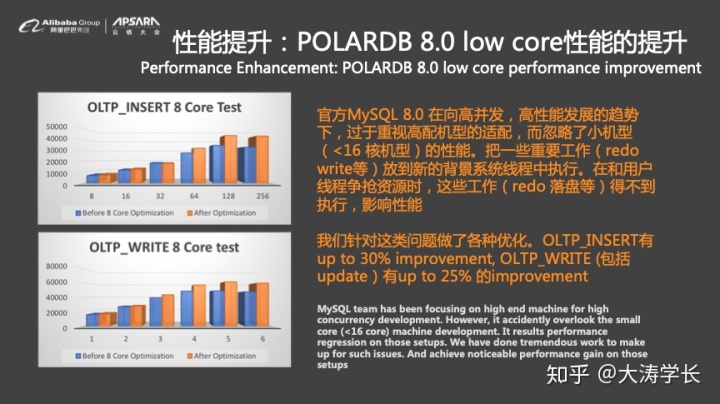
相比于POLARDB 5.6版本,POLARDB 8.0版本在性能表现上有了显著提升,在关键情况下都有了数倍的改进。相比于MySQL 8.0的官方版本,POLARDB 8.0的优化改进所带来的效果也非常明显,尤其是物理复制方面具有显著的优势,在Insert情况下POLARDB性能可达到MySQL的约6倍。

官方MySQL向8.0版本演进时过于重视高配机型的适配,而忽略了小型机的性能。而云上用户大部分还是用的8核、16核的小型机,因此使用MySQL8.0的性能会发生退化。因此,阿里云POLARDB数据库针对于这个问题进行了一系列优化。
相较于MySQL 8.0,阿里云POLARDB 8.0版本提供了更多的内核引擎功能,比如独立可扩展的共享Buffer Pool、行级压缩、全球实例支持、并行DDL、分区表自建索引以及自建分区表等。
3、POLARDB MySQL并行查询优化详解
阿里云智能技术专家封仲淹为大家详细介绍了POLARDB基于MySQL 8.0内核所做的并行查询优化。
并行查询是POLARDB 8.0版本重磅推出的一个特性,阿里云POLARDB团队投入了大量人力和物力来开发这个特性,并且从目前来看,客户对于并行查询的反馈非常好。
首先思考一个问题:为什么需要并行查询?阿里使用MySQL的历史已经过了十余年,在MySQL使用中遇到的所有问题,阿里基本都遇到过。其中令人头痛的问题就是当MySQL表的数据量特别大时,查询会非常的慢。大部分方案都是通过拆库将数据量缩小。
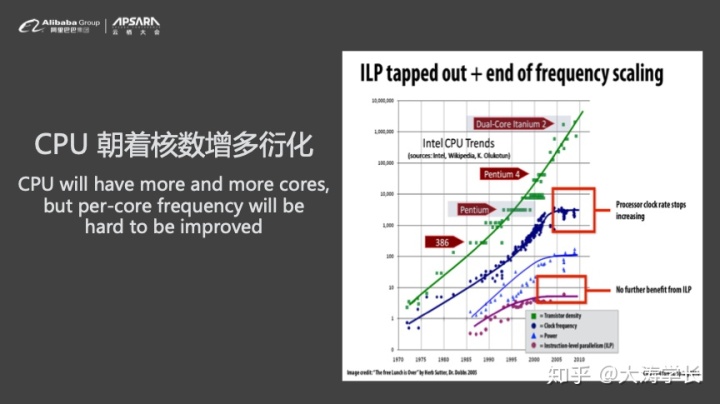
此外,业界的一个趋势CPU单核频率达到了瓶颈,增长放缓。而我们对于计算能力的诉求是永无止境的,因此CPU只能向着多核演进。而MySQL属于传统事务型数据库,其无法并行执行单条Query,因此无法充分利用多核的作用。业界的通用做法就是并行查询,如今几乎所有商业数据库都提供并行查询的能力,将任务分摊给多个线程并行计算,大幅度缩短计算时间。
那么,如何实现并行查询呢?并行查询首要关注的就是数据分区,这样才能使得每个Worker同时工作,互不干扰。由优化器决定分区的数量,并且让 Worker与分区动态绑定,实现“能者多劳”,防止热点问题的出现,使得计算更加均匀,保障了并行查询的线性性能提升。在并行计算里面,将单线程Plan Tree改为了多线程,划分Worker和Leader两个角色,尽可能将所有算子下推到Worker中,利用Worker并行能力加速,而让Leader做汇总和反馈。
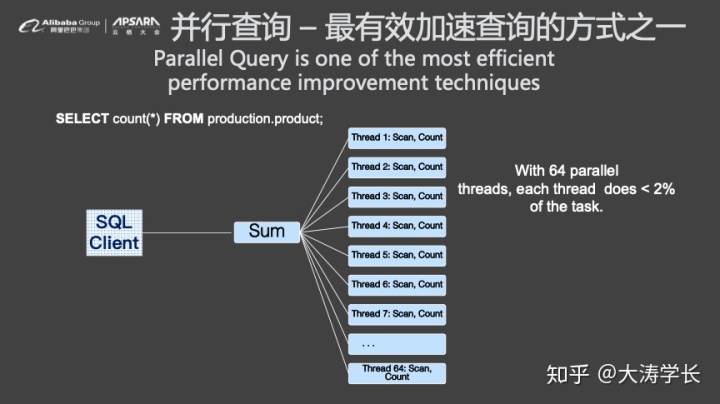
那么,并行查询的效果如何呢?在TPCH 100G数据量的情况下,使用POLARDB并行查询时发现70%的查询可以被加速,40%的加速比超过10倍,几乎能够将CPU能力完全发挥出来。

与此同时,并行查询还具有线性增长的能力,这意味着当数据量大的时候,只需要给与足够多的CPU和内存,处理能力就能够实现线性增长。在TPCH 5G、10G、20G以及40G四种数据量维度下,不断调整并发度,而性能曲线基本上出现线性增长趋势。
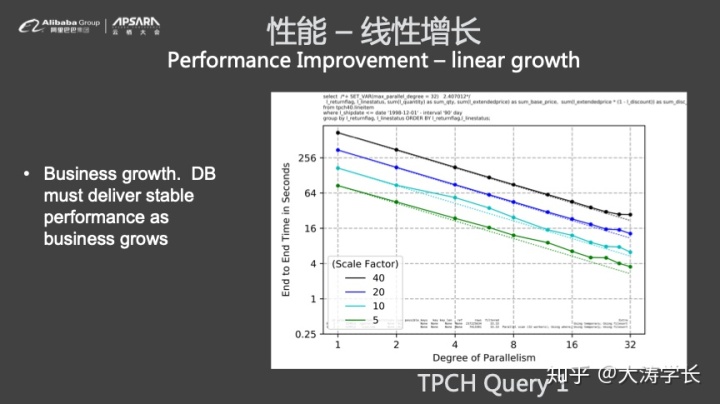
使用并行查询也比较简单,用户可以在控制台、Session或者SQL中进行设置自己需要的并发度。在未来,POLARDB会实现自动的DOP以及ResourceManager,并将支持Subquery、GIS和Blob以及Procedure等。
4、POLARDB 兼容Oracle能力解密与迁移
阿里云智能技术专家蔡松露为大家深度了揭秘POLARDB是如何实现兼容Oracle能力的。
之前POLARDB主要兼容MySQL、PostgreSQL等开源数据库,而现在POLARDB也已经兼容了Oracle,这和之前兼容开源数据库是不同的。之所以要兼容Oracle主要有几个方面的原因,首先目前公有云已经进入了深水区,因此需要更多地深入线下的存储和计算场景;其次在如今的政治环境中,国家层面对于“去O”有了新的要求,而目前国内市场还属于真空。基于以上背景、机遇和挑战,阿里云推出了POLARDB兼容Oracle的产品。而如何实现真正的兼容,以及如何将数据从Oracle迁移到POLARDB都存在很多挑战。
POLARDB目前兼容了MySQL 5.6、MySQL 8.0以及PostgreSQL 11,此外还高度兼容了Oracle,因为Oracle语法本身非常复杂,因此整体兼容度可以达到95%左右。除了兼容Oracle之外,基于POLARDB本身的能力可以在Proxy层实现自定义读写分离和自动负载均衡。Oracle在引擎层能够提供多写能力,但是POLARDB提供的是一写多读能力。存储层的Polar Store类似于Oracle的ASM。POLARDB本身的能力基本都被其兼容Oracle的产品复用了。
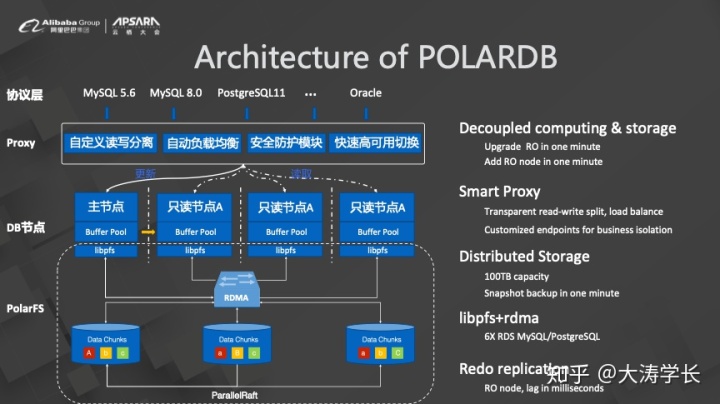
POLARDB Oracle版本从几个层次做了兼容,首先是操作界面能够完全兼容,对于DBA而言迁移成本基本为0。其次,对于应用开发而言,目前POLARDB使用的PG开源的SDK。而对于引擎架构而言,POLARDB的架构基本和Oracle类似。目前使用的存储也是和ASM对标的。

兼容只是起点,使用POLARDB不只是获得了对于Oracle的兼容性,还提供了更强大的能力。不仅能够获得云原生能力,兼容更多的数据生态,并且还提供了更多的数据增值服务以及业界的解决方案,其背后是整个阿里巴巴生态的技术能力。
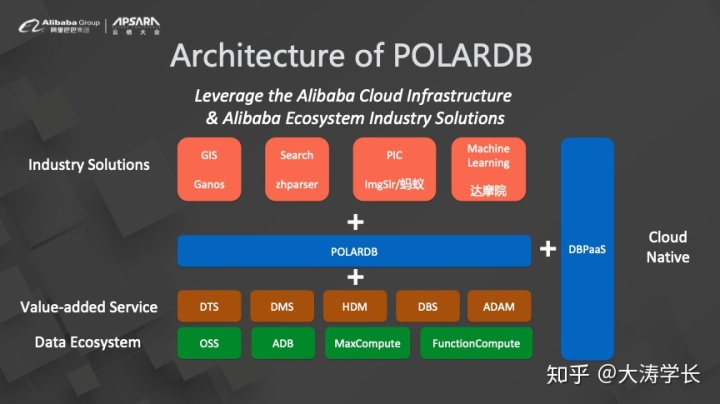
本次云栖大会上发布的POLARDB一体机使用了云原生的管控系统,沉淀了阿里巴巴之前在公有云上积累的管控经验。一体机使用了软硬一体化设计,实现了整机柜交付,并且集成了大量的成熟新硬件。主要面向政企行业,能够实现从Oracle一键迁移。一体机使用K8S底座,能够方便与自有系统集成。
Oracle数据库迁移需要经过评估、测试、迁移、管理、分析诊断以及付费等诸多环节,而阿里云为用户在各个阶段提供了非常完善的功能。

总结而言,对于Oracle的兼容性可以分为五个维度:
工具和生态:兼容DBA、开发者等相关人员的使用习惯;
SQL语法:对应用而言需要改造成本接近于零;
性能:避免性能退化;
成本:可以将成本做到极低;
部署:线上线下实现混合云架构。
那么,如何做迁移呢?阿里云提供了数据库和应用迁移(ADAM),其包含了采集、画像、评估、改造以及迁移系统,能够帮助企业大限度降低ORACLE数据库和应用迁移上云的风险、技术难度和实施周期。ADAM脱胎于阿里巴巴内部“去O”的实践,能够帮助用户做到一键上云。
5、使用云原生技术构建可扩展的游戏数据库架构
江娱互动CTO罗田唯为大家介绍了如何使用云原生技术构建可扩展的游戏数据库架构。
江娱互动是一家专注于小游戏公司,头部产品是“世界争霸”小游戏。 “世界争霸”小游戏首先算是一个大型社交系统,目前的服务数量达到了200多个,超过1百万日活,每天5亿次用户请求。其次是大型数据库系统,目前有200多个数据库实例,总数据量在10TB之上。后,游戏还是大型日志系统,这对于分析玩家很重要,“世界争霸”每天日志量在50TB之上。
对于游戏产业而言,面对着低延迟、重支付和全球同服的挑战。面对海量的请求、数据和日志,服务器数量多、架构复杂以及带来运维压力大,还有研发团队能力不足、研发周期短以及要求高的挑战,完全由自己团队负责是无法搞定的。

“世界争霸”小游戏数据总量很大,单表数据量也大,并且QPS也很高。如果使用自建数据库方案,使用MySQL数据库,并且使用Cobar中间件做分库分表。自建数据库的方案缺点很明显,架构比较复杂,搭建和维护的成本都非常高,并且稳定性难以保障。如果采用上云的传统方案就是使用阿里云RDS来替代MySQL,这样的缺点也是这种方案不够灵活,这样的方案对于传统电商而言可能够用,但是对于游戏而言是不足够的,虽然搭建和维护比较方便,但是稳定性却不够好。
从2019年5月使用POLARDB以来,江娱互动目前已经成为了POLARDB华北区大客户。POLARDB的优点在于存储和计算分离,扩展性强,并且单表容量大,小表性能平稳,同等规格下是RDS性能的7倍,并且相较于RDS能够节省一半成本。POLARDB稳定性也非常高,SLA接近于。
6、大规模实时互动课堂下的POLARDB实践
猿辅导研发架构师李阳明为大家介绍了在线教育公司猿辅导的大规模实时互动课堂下的POLARDB实践。
猿辅导是一家在线教育公司,正在为超过2.5亿的中小学生和家长提供多元化的智能教育服务,主营业务为在线题库、拍照搜题、实时互动课堂、直播云辅导等。
猿辅导对于实时互动课堂的定义包含三个要素:实时可互动、活动类型丰富以及用户体验稳定一致。对于在线课程测验这个典型场景主要面对的挑战有三条,即流量规模比较大,业务需求多样和业务变更频繁。首先,对于猿辅导这样的面向K12在线教育而言,流量会有明显的周期差异,存在明显的波峰和波谷,中小学生往往会在工作日的晚上或者周末才有时间上课。此外,房间规模也不同,猿辅导有上千个千人班级,还有若干十万人的班级,而这两种班级的流量是不同的。其次,猿辅导的业务需求比较多样,不同年级的功能侧重点不同,不同角色关心的内容也不同。

猿辅导初使用MySQL + Redis方案,MySQL落盘核心数据并提供回放服务,Redis则实现各种榜单供直播使用。这种方案的问题是Redis数据无法复用,导致写多份,并且单机MySQL存在性能瓶颈无法支持更高的QPS。后来猿辅导就引入了POLARDB数据库,并将统计功能进行了微服务化,去掉了Redis。
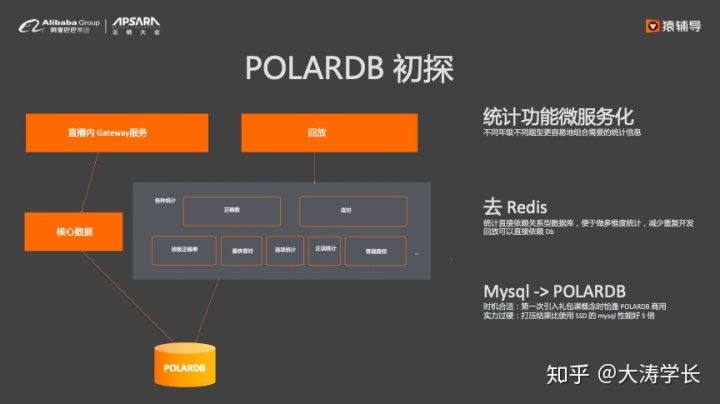
这样的方案运行了半年,也遇到了三点主要的问题:处理能力被高估、缺乏隔离和缺乏扩展性。于是猿辅导借助POLARDB实现的数据库架构的再次演进,实现了数据库的垂直拆分、水平拆分、读写分离和提交异步化。

猿辅导现在的数据库架构还存在着一些遗留的问题,比如负载均衡策略不可配、回放带来数据负担以及课堂外数据统计也是一个负担。因此,猿辅导也进行了一些负载均衡方面的优化,比如支持按照负载进行Shard调度,也支持手工指定房间的Shard,而且使得基础组件支持动态下发分片信息。
本文作者:Roin123
本文为云栖社区原创内容,未经允许不得转载。
