来源:柯三
来源:juejin.im/post/5e0443ae6fb9a0162277a2c
来源:柯三
来源:juejin.im/post/5e0443ae6fb9a0162277a2c
total 总内存 used 已用内存 free 空闲内存 buff/cache 已使用的缓存 avaiable 可用内存


# 再谈SQL Join
# 回顾
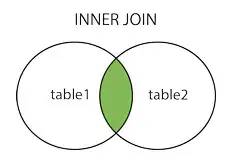
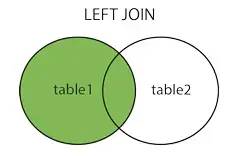


可以通过增加索引来优化join语句的执行速度 可以通过冗余信息来减少join的次数 尽量减少表连接的次数,一个SQL语句表连接的次数不要超过5次
# 缓冲区
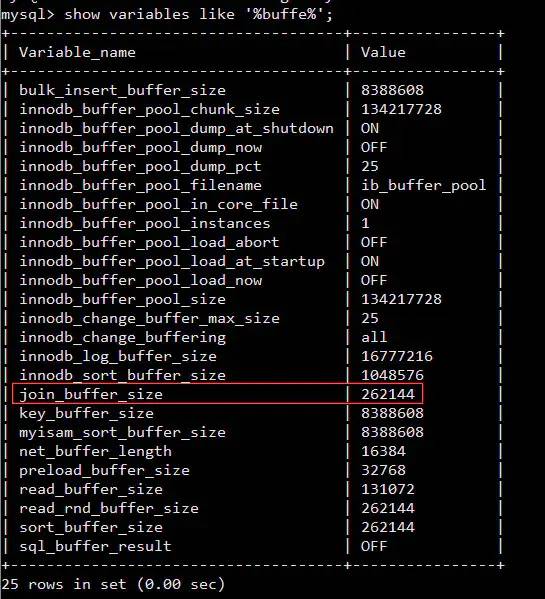
# 一个大前提
InnoDB以页(page)为基本的IO单位,每个页的大小为16KB InnoDB会为每个表创建用于存储数据的.ibd文件
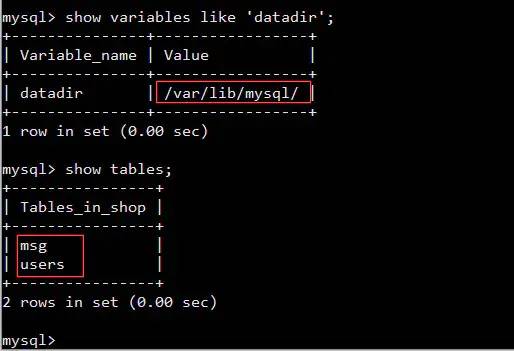



buff/cache 里面存的是什么? 为什么buff/cache 占了那么多内存,可用内存即availlable还有1.1G? 为什么你可以通过两条命令来清理buff/cache占用的内存,而想要释放used只能通过结束进程来实现?

存储器层次结构的本质是,每一层存储设备都是较低一层设备的缓存

相关资料:http://tldp.org/LDP/sag/html/buffer-cache.html

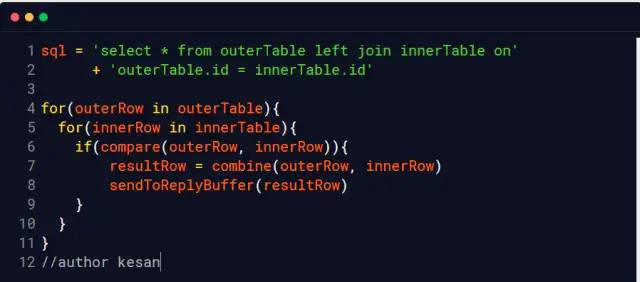
# Join算法


# 总结
# 参考资料
《深入理解计算机系统》- 第6章 存储器层次结构
《Experiments and fun with the Linux disk cache》作者通过几个例子来说明硬盘缓存对程序执行性能的影响
《Linux ate my ram》 Free参数的解释
How to clear the buffer/pagecache (disk cache) under Linux 文章开头送分题命令的解释
MySQL 是怎样运行的:从根儿上理解 MySQL
Block bested loop 来自MariaDB官方文档解释了Block-Nested-Loop算法的实现

——End——
——End——
