Lucene作为强大的开源的全文检索引擎,其倒排索引机制可以快速的根据term值找到docid,此外lucene也可以保存明细数据,通过docid将明细数据返回,并且有两种方式-行存、列存。
一次查询的流程

上图是lucene一次查询的流程,首先是从倒排索引中获取docid,之后再从行存或者列存中找到数据。只有建立索引的字段才会生成term和term对应的docid列表。当然,如果字段需要分词,就对分词器的切分后的每个分词单元建立term和对应的doclist。否则整个字段作为一个term,并建立doclist。从图中也可以看到两个关系:
1)索引与数据是独立存储的,两者之间是通过docid关联。
2)行存和列存是独立存储的,他们只和docid关联,彼此无关联。
数据存储文件结构
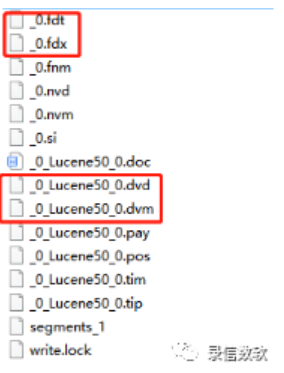
上图是lucene中的文件结构,其中fdx、fdt是行存数据文件,dvm、dvd是列存数据文件。
重编码
在数据存储系统中,对磁盘的占用是很敏感,因为相同的数据信息占用磁盘越多,意味着硬件成本越高,读取相同数据信息的io资源随之升高。如果按照已有的数据格式(比如java中的int、long)存储数据将会造成很大的数据浪费,可以见下图:

上图中long和int二进制表示中红色高位是不起作用的,也就是被“浪费”了。因为long和int的序列化方式是不可控的,只要在int范围的数据就会占用四个字节。Lucene对此解决方案是-重编码。重编码在lucene文件存储中被广泛用于数值类型数据的压缩,可以极大的减少空间的浪费,通过将byte(字节)重组,以bit(位)为单位,尽可能的利用每一个bit(位)。下面是一个重编码的例子:
int[] ints = {3,16,7,12}
二进制表示:
{0000 0011,0001 0000,0000 0111,0000 1100 }
选择其中有效位大那个作为定长,也就是16->1 0000,下面就是重编码之后的结果

行存存储
行存存储本质是通过docid获取整行数据,适用于多列数据展示,数据文件对应fdx,fdt,其中fdt存储数据,fdx是fdt文件的索引。
fdx、fdt两个文件的组织结构是类似树形结构,保证可以根据docid快速获取整行数据。
这个图中每个block对应1024个chunk,每个chunk对应128个doc,这样可以快速根据block定位到属于哪个chunk,再根据每个chun到具体的doc的位置。其中block是fdx中的概念,chunk是fdt中的概念。
1)fdx文件结构
除去不重要的文件头和尾信息之外,存储的是每个block的信息,每个block的信息有
Chunk个数
起始docid
平均个数
存储每个chunk个数占用的字节数
存储每个chunk的个数
起始fdt文件偏移量
平均chunk大小
存储每个chunk对应fdt地址占用的字节数
存储每个chunk对应的fdt地址
其中查询的流程是根据每个block的起始docid快速定位到给定的docid是属于哪个block,接着根据chunk个数数组定位到属于哪个chunk,找到对应的数组下标,然后从chunk地址数组中找到该chunk对应的fdt文件地址。其中在存储chunk包含doc个数和chunk对应fdt文件地址的时候使用“存储真实值和平均值的差值来代替存储真实值”的方法,可以起到压缩数据的作用,下面是一个采用该方法的例子:
[10000,9888,10002,99997,10003] => [0,-2,2,-3,3]
转换之后的存储个数明显变少,接着在对转换之后的数组使用重编码的方法继续压缩。由于fdx并不存储真实数据,只是一些索引信息,所以一般是需要常驻内存的,用于加快数据的搜索。
2) fdt文件结构
Fdt文件就简单不少了,主要存储的是一个多个chunk块的信息:
起始docid
当前chunk包含的doc个数
每个doc包含的字段的个数
每个doc的长度
具体的每行数据,每行数据又包括每个列的列编号、列长度、列值。
可以发现numStoredFields和lengths都是数值型数组,所以这两个部分的数据存储都采用了重编码的机制。数据量真正大的地方是存储每行数据,由于是行存,每个列的树交叉存储,所以版很难做存储结构上的优化,此处使用的全局压缩算法,lucene提供了三种压缩算法:
DeflateCompressor
LZ4FastCompressor
LZ4HighCompressor
每种压缩算法的性能和耗时不同,下面是做了简单测试:
压缩算法
数据量
压缩比(压缩后/压缩前)
耗时
DeflateCompressor
300M
0.49
12.5s
LZ4HighCompressor
300M
0.62
8.6s
LZ4FastCompressor
300M
0.67
7s
压缩比分别是DeflateCompressor > LZ4HighCompressor> LZ4FastCompressor,但是对应的压缩时间就是相反的。压缩比高就要更多的时间去压缩。Lucene默认采用了LZ4HighCompressor压缩算法,兼顾性能和耗时。
Fdt文件一般都是比较大的,不会常驻内存,只有在需要的时候才会加载到内存中。
列存存储
列存存储本质是通过docid获取一例数据,减少需要加载的数据量,列存使用场景:排序、facet、地理位置查询等,对应的数据文件dvm , dvd。其中dvd存储列存数据,dvm是dvd文件的索引。
1) dvd/dvm文件结构
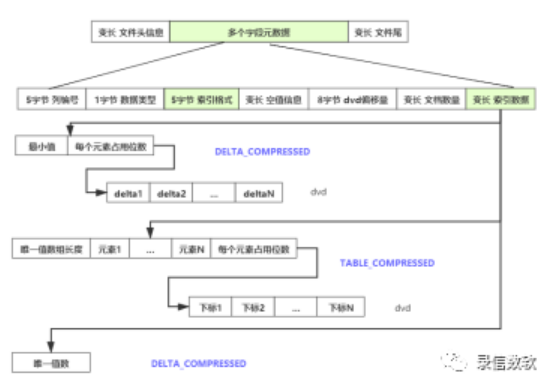
由于是列存存储所以每个列的数据是连续存储的,每个字段的元数据也是连续存储的,这样有利于数据的加载,其中dvm文件存储的内容主要有:
列编号
列的数据类型
索引格式
空值信息
当前列对应的dvd文件的地址
文档的数量
索引数据
由于每个列的数据是存储在一起的,所以这里可以有不同的数据存储格式,lucene提供了种四种:
CONST_COMPRESSED只有一个常量值和空值的情况下采用这种格式。这种格式很简单,直接把该常量值写入 dvm中,解压时,直接读取 dvm中的常量即可。
TABLE_COMPRESSED当不满足i且值小于等于 256 个,采用这种格式,把这些值放到一个数组中,排好序,然后把值写到 meta 中,把每个文档的值在数组中的下标重编码之后写到 dvd文件 中即可。
GCD_COMPRESSED当不满足上述两个,且大公约数不是0&1时,采用这种结构,大公约数压缩格式:(value - minValue) / gcd,重编码之后存储在dvd文件中。

GCD_COMPRESSED把小值写到 meta 中,用值减去小值,得到差值,写到 data 中。比较适用所有值差别不大的情况。
LSQL是一款基于分布式架构下实时的、多维的、交互式的查询、统计、分析数据库,是为探索性分析与即席分析而设计的数据库,基于自研分布式索引+大数据技术,添加时序索引,同时具备时序数据库的能力,可以对万亿级别的数据做到秒级数据检索及统计分析服务。对于多种业务场景只需一套数据库便可一站式解决。
————————————————
版权声明:本文为CSDN博主「么么惠」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44253169/article/details/104867309
