

<configuration><property><name>yarn.app.mapreduce.am.resource.mb</name><value>1024</value></property><property><name>yarn.app.mapreduce.am.command-opts</name><value>-Xmx768m</value></property><property><name>mapreduce.framework.name</name><value>yarn</value><description>Execution framework.</description></property><property><name>mapreduce.map.cpu.vcores</name><value>1</value><description>The number of virtual cores required for each map task.</description></property><property><name>mapreduce.reduce.cpu.vcores</name><value>1</value><description>The number of virtual cores required for each map task.</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>mapreduce.map.memory.mb</name><value>1024</value><description>Larger resource limit for maps.</description></property><property><name>mapreduce.map.java.opts</name><value>-Xmx768m</value><description>Heap-size for child jvms of maps.</description></property><property><name>mapreduce.reduce.memory.mb</name><value>1024</value><description>Larger resource limit for reduces.</description></property><property><name>mapreduce.reduce.java.opts</name><value>-Xmx768m</value><description>Heap-size for child jvms of reduces.</description></property><property><name>mapreduce.jobtracker.address</name><value>jobtracker.alexjf.net:8021</value></property></configuration>
首先,使用以下命令启动DFS:
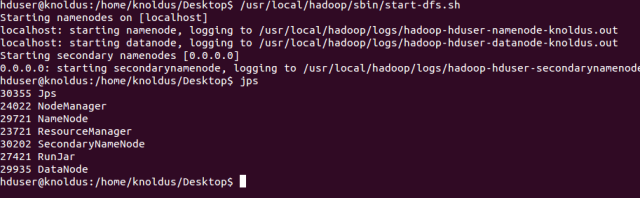

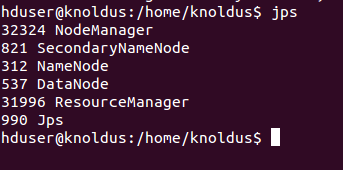
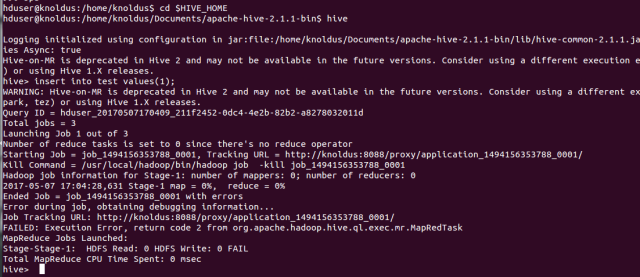





 唔~要这个 ↓↓↓
唔~要这个 ↓↓↓