你好鸭,Kirito 今天又来分享性能优化的骚操作了。
在很多追求性能的程序挑战赛中,经常会遇到一个操作:将 String 转换成 Integer/Long。如果你没有开发过高并发的系统,或者没有参加过任何性能挑战赛,可能会有这样的疑问:这有啥好讲究的,Integer.valueOf/Long.valueOf 又不是不能用。实际上,很多内置的转换工具类只满足了功能性的需求,在高并发场景下,可能会是热点方法,成为系统性能的瓶颈。
文章开头,我先做一下说明,本文的测试结论出自:https://kholdstare.github.io/technical/2020/05/26/faster-integer-parsing.html 。测试代码基于 C++,我会在翻译原文的同时,添加了部分自己的理解,以协助读者更好地理解其中的细节。
问题提出
假设现在有一些文本信息,固定长度为 16 位,例如下文给出的时间戳,需要尽可能快地解析这些时间戳
timestamp
1585201087123567
1585201087123585
1585201087123621
方法体如下所示:
std::uint64_t parse_timestamp(std::string_view s)
{
// ???
}
问题提出后,大家不妨先思考下,如果是你,你会采取什么方案呢?带着这样的思考,我们进入下面的一个个方案。
Native 方案
我们有哪些现成的转换方案呢?
继承自 C 的 std::atollstd::stringstreamC++17 提供的 charconvboost::spirit::qi
评测程序采用 Google Benchmark 进行对比评测。同时,我们以不做任何转换的方案来充当 baseline,以供对比。(baseline 方案在底层,相当于将数值放进来了寄存器中,所以命名成了 BM_mov)
下面给出的评测代码不是那么地关键,只是为了给大家展示评测是如何运行的。
static void BM_mov(benchmark::State& state) {
for (auto _ : state) {
benchmark::DoNotOptimize(1585201087123789);
}
}
static void BM_atoll(benchmark::State& state) {
for (auto _ : state) {
benchmark::DoNotOptimize(std::atoll(example_timestamp));
}
}
static void BM_sstream(benchmark::State& state) {
std::stringstream s(example_timestamp);
for (auto _ : state) {
s.seekg();
std::uint64_t i = ;
s >> i;
benchmark::DoNotOptimize(i);
}
}
static void BM_charconv(benchmark::State& state) {
auto s = example_timestamp;
for (auto _ : state) {
std::uint64_t result = ;
std::from_chars(s.data(), s.data() + s.size(), result);
benchmark::DoNotOptimize(result);
}
}
static void BM_boost_spirit(benchmark::State& state) {
using boost::spirit::qi::parse;
for (auto _ : state) {
std::uint64_t result = ;
parse(s.data(), s.data() + s.size(), result);
benchmark::DoNotOptimize(result);
}
}

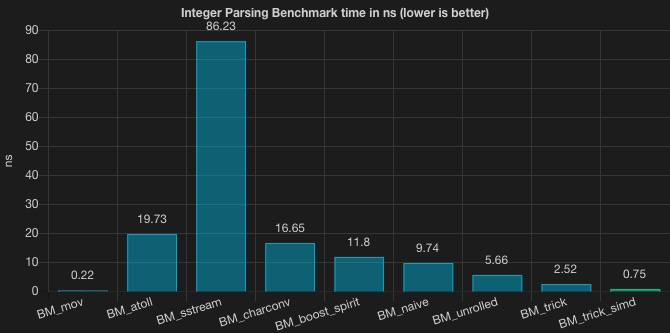
可以发现 stringstream 表现的非常差。当然,这并不是一个公平的比较,但从测评结果来看,使用 stringstream 来实现数值转换相比 baseline 慢了 391 倍。相比之下, <charconv> 和 boost::spirit 表现的更好。
既然我们已经知道了目标字符串包含了要解析的数字,而且不需要做任何的数值校验,基于这些前提,我们可以思考下,还有更快的方案吗?
Naive 方案
我们可以通过一个再简单不过的循环方案,一个个地解析字符。
inline std::uint64_t parse_naive(std::string_view s) noexcept
{
std::uint64_t result = ;
for(char digit : s)
{
result *= 10;
result += digit - '0';
}
return result;
}

虽然这层 for 循环看起来呆呆的,但如果这样一个呆呆的解决方案能够击败标准库实现,何乐而不为呢?前提是,标准库的实现考虑了异常场景,做了一些校验,这种 for 循环写法的一个前提是,我们的输入一定是合理的。
之前我的文章也提到过这个方案。显然, naive 的方案之后还会有更优的替代方案。
循环展开方案
记得我们在文章的开头加了一个限定,限定了字符串长度固定是 16 位,所以循环是可以被省略的,循环展开之后,方案可以更快。
inline std::uint64_t parse_unrolled(std::string_view s) noexcept
{
std::uint64_t result = ;
result += (s[] - '0') * 1000000000000000ULL;
result += (s[1] - '0') * 100000000000000ULL;
result += (s[2] - '0') * 10000000000000ULL;
result += (s[3] - '0') * 1000000000000ULL;
result += (s[4] - '0') * 100000000000ULL;
result += (s[5] - '0') * 10000000000ULL;
result += (s[6] - '0') * 1000000000ULL;
result += (s[7] - '0') * 100000000ULL;
result += (s[8] - '0') * 10000000ULL;
result += (s[9] - '0') * 1000000ULL;
result += (s[10] - '0') * 100000ULL;
result += (s[11] - '0') * 10000ULL;
result += (s[12] - '0') * 1000ULL;
result += (s[13] - '0') * 100ULL;
result += (s[14] - '0') * 10ULL;
result += (s[15] - '0');
return result;
}
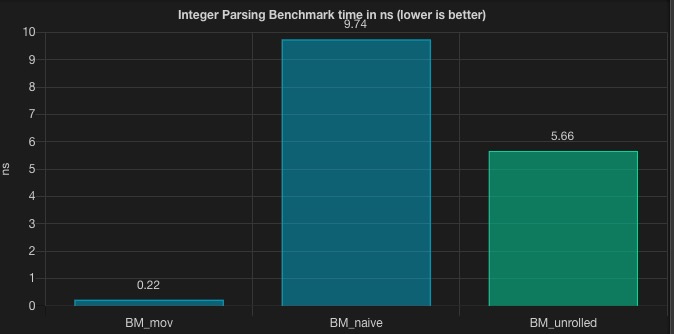
关于循环展开为什么会更快,可以参考我过去关于 JMH 的文章。
byteswap 方案
先思考下,如果继续围绕上述的方案进行,我们可能只有两个方向:
并发执行加法和乘法计算,但这种 CPU 操作似乎又不能通过多线程之类的手段进行加速,该如何优化是个问题 将乘法和加法运算转换成位运算,获得更快的 CPU 执行速度,但如果转换又是个问题
相信读者们都会有这样的疑问,那我们继续带着这样疑问往下看原作者的优化思路是什么。
紧接着上述的循环展开方案,将 “1234” 解析为 32 位整数对应的循环展开操作绘制为图,过程如下:

我们可以看到,乘法和加法的操作次数跟字符的数量是线性相关的。由于每一次乘法都是由不同的乘数进行,所以我们不能只乘“一次”,在乘法的后,我们还需要将所有结果相加。乍一看,好像很难优化。
下面的优化技巧,需要一些操作系统、编译原理相关的知识作为辅助,你需要了解 byteswap 这个系统调用,了解大端序和小端序的字节序表示方法(后面我也会分享相关的文章),如果你不关心这些细节,也可以直接跳到本段的后,直接看结论。
理解清楚下图的含义,需要理解几个概念:
字符 1对应的 ascii 值是31,相应的2对应32,4对应34在小端序机器上(例如 x86),字符串是以大端序存储的,而 Integer 是以小端序存储的 byteswap 可以实现字节序调换
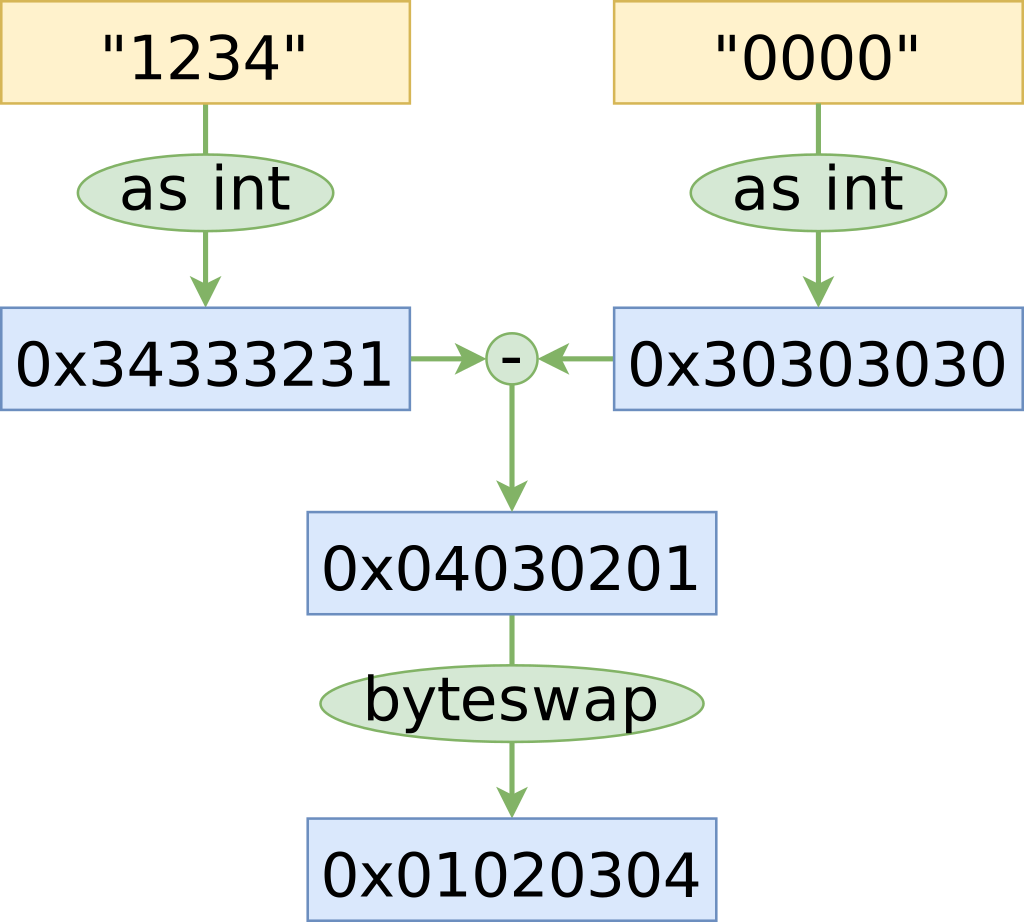
上图展示了十六进制表示下的转换过程,可以在更少的操作下达到终的解析状态。
将上图的流程使用 C++ 来实现,将 String 重新解释为 Integer,必须使用 std::memcpy(避免命名冲突),执行相减操作,然后通过编译器内置的 __builtin_bswap64 在一条指令中交换字节。到目前为止,这是快的一个优化。
template <typename T>
inline T get_zeros_string() noexcept;
template <>
inline std::uint64_t get_zeros_string<std::uint64_t>() noexcept
{
std::uint64_t result = ;
constexpr char zeros[] = "00000000";
std::memcpy(&result, zeros, sizeof(result));
return result;
}
inline std::uint64_t parse_8_chars(const char* string) noexcept
{
std::uint64_t chunk = ;
std::memcpy(&chunk, string, sizeof(chunk));
chunk = __builtin_bswap64(chunk - get_zeros_string<std::uint64_t>());
// ...
}
我们看上去得到了想要的结果,但是这个方案从时间复杂度来看,仍然是 O(n) 的,是否可以在这个方案的基础上,继续进行优化呢?
分治方案
从初的 Native 方案,到上一节的 byteswap 方案,我们都只是优化了 CPU 操作,并没有优化复杂度,既然不满足于 O(n),那下一个复杂度可能性是什么?O(logn)!我们可以将每个相邻的数字组合成一对,然后将每对数字继续组合成一组四个,依此类推,直到我们得到整个整数。
如何同时处理邻近的数字,这是让算法跑进 O(logn) 的关键
该方案的关键之处在于:将偶数位的数字乘以 10 的幂,并且单独留下奇数位的数字。这可以通过位掩码(bitmasking)来实现
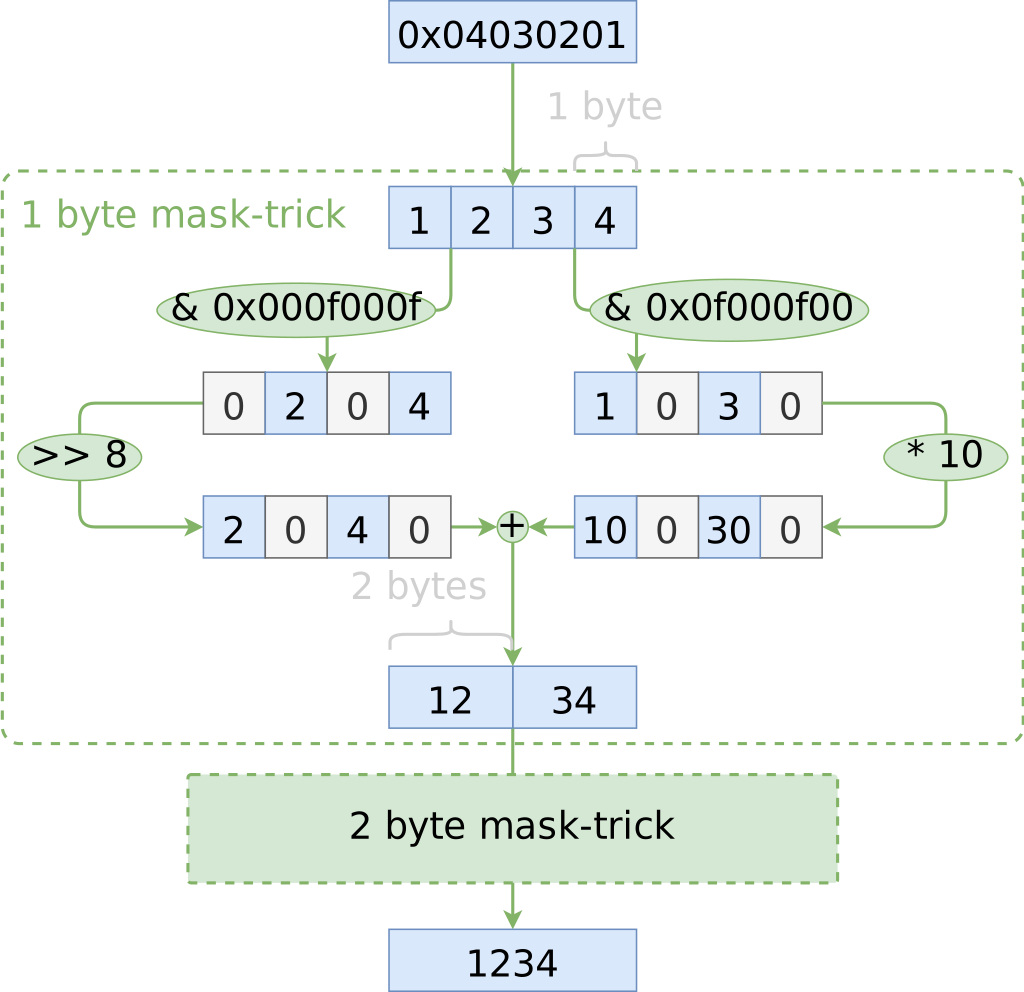
通过 bitmasking,我们可以一次对多个数字进行操作,将它们组合成一个更大的组合
通过使用这个掩码技巧来实现前文提到的 parse_8_chars 函数。使用 bitmasking 的另一好处在于,我们不用减去 '0' ,因为位掩码的副作用,使得我们正好可以省略这一步。
inline std::uint64_t parse_8_chars(const char* string) noexcept
{
std::uint64_t chunk = ;
std::memcpy(&chunk, string, sizeof(chunk));
// 1-byte mask trick (works on 4 pairs of single digits)
std::uint64_t lower_digits = (chunk & 0x0f000f000f000f00) >> 8;
std::uint64_t upper_digits = (chunk & 0x000f000f000f000f) * 10;
chunk = lower_digits + upper_digits;
// 2-byte mask trick (works on 2 pairs of two digits)
lower_digits = (chunk & 0x00ff000000ff0000) >> 16;
upper_digits = (chunk & 0x000000ff000000ff) * 100;
chunk = lower_digits + upper_digits;
// 4-byte mask trick (works on pair of four digits)
lower_digits = (chunk & 0x0000ffff00000000) >> 32;
upper_digits = (chunk & 0x000000000000ffff) * 10000;
chunk = lower_digits + upper_digits;
return chunk;
}
trick 方案
综合前面两节,解析 16 位的数字,我们将它分成两个 8 字节的块,运行刚刚编写的 parse_8_chars,并对其进行基准测试!
inline std::uint64_t parse_trick(std::string_view s) noexcept
{
std::uint64_t upper_digits = parse_8_chars(s.data());
std::uint64_t lower_digits = parse_8_chars(s.data() + 8);
return upper_digits * 100000000 + lower_digits;
}
static void BM_trick(benchmark::State& state) {
for (auto _ : state) {
benchmark::DoNotOptimize(parse_trick(example_stringview));
}
}
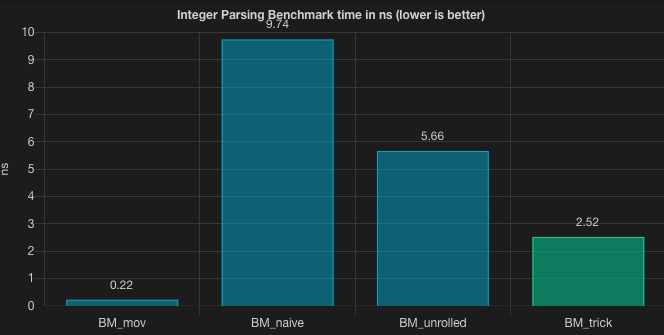
看上去优化的不错,我们将循环展开方案的基准测试优化了近 56% 的性能。能做到这一点,主要得益于我们手动进行一系列 CPU 优化的操作,虽然这些并不是特别通用的技巧。这样算不算开了个不好的头呢?我们看起来对 CPU 操作干预地太多了,或许我们应该放弃这些优化,让 CPU 自由地飞翔。
SIMD trick 方案
你是不是以为上面已经是终方案了呢?不,优化还剩后一步。
我们已经得到了一个结论
同时组合多组数字以实现 O(logn) 复杂度
如果有 16 个字符或 128 位的字符串要解析,还可以使用 SIMD。感兴趣的读者可以参考SIMD stands for Single Instruction Multiple Data。Intel 和 AMD CPU 都支持 SSE 和 AVX 指令,并且它们通常使用更宽的寄存器。
SIMA 简单来说就是一组 CPU 的扩展指令,可以通过调用多组寄存器实现并行的乘法运算,从而提升系统性能。我们一般提到的向量化运算就是 SIMA。
让我们先设置 16 个字节中的每一个数字:
inline std::uint64_t parse_16_chars(const char* string) noexcept
{
auto chunk = _mm_lddqu_si128(
reinterpret_cast<const __m128i*>(string)
);
auto zeros = _mm_set1_epi8('0');
chunk = chunk - zeros;
// ...
}
现在,主角变成了 madd 该系统调用。这些 SIMD 函数与我们使用位掩码技巧所做的操作完全一样——它们采用同一个宽寄存器,将其解释为一个由较小整数组成的向量,每个乘以一个特定的乘数,然后将相邻位的结果相加到一个更宽的整数向量中。所有操作一步完成。
// The 1-byte "trick" in one instruction
const auto mult = _mm_set_epi8(
1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10
);
chunk = _mm_maddubs_epi16(chunk, mult);
2 字节方案其实还有另一条指令,但不幸的是我并没有找到 4 字节方案的指令,还是需要两条指令。这是完整的 parse_16_chars 方案:
inline std::uint64_t parse_16_chars(const char* string) noexcept
{
auto chunk = _mm_lddqu_si128(
reinterpret_cast<const __m128i*>(string)
);
auto zeros = _mm_set1_epi8('0');
chunk = chunk - zeros;
{
const auto mult = _mm_set_epi8(
1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10, 1, 10
);
chunk = _mm_maddubs_epi16(chunk, mult);
}
{
const auto mult = _mm_set_epi16(1, 100, 1, 100, 1, 100, 1, 100);
chunk = _mm_madd_epi16(chunk, mult);
}
{
chunk = _mm_packus_epi32(chunk, chunk);
const auto mult = _mm_set_epi16(, , , , 1, 10000, 1, 10000);
chunk = _mm_madd_epi16(chunk, mult);
}
return ((chunk[] & 0xffffffff) * 100000000) + (chunk[] >> 32);
}
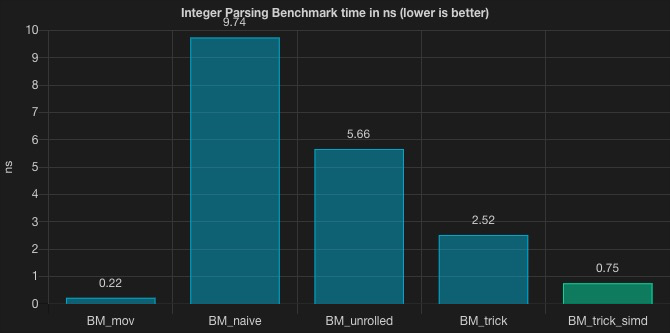
0.75 nanoseconds! 是不是大吃一惊呢.
总结
有人可能会问,你为啥要用 C++ 来介绍下,不能用 Java 吗?我再补充下,本文的测试结论,均来自于老外的文章,文章出处见开头,其次,本文的后半部分的优化,都是基于一些系统调用,和 CPU 指令的优化,这些在 C++ 中实现起来方便一些,Java 只能走系统调用。
在近过去的性能挑战赛中,由于限定了不能使用 JNI,使得选手们只能将方案止步于循环展开方案,试想一下,如果允许走系统调用,加上比赛中字符串也基本是固定的长度,完全可以采用 SIMD 的 trick 方案,String 转 Long 的速度会更快。

实际上,在之前 polarDB 的比赛中,普哥就给我介绍过 bswap 的向量化方案,这也是为啥 Java 方案就是比 C++ 方案逊色的原因之一,C++ 在执行一些 CPU 指令集以及系统调用上,比 Java 方便很多。
如何看待这一系列的优化呢?从 std::stringstream 的 86.23 到 sima trick 方案的 0.75,这个优化的过程是令人兴奋的,但我们也发现,越往后,越是用到一些底层的优化技巧,正如方案中的 trick 而言,适用性是有限的。也有一种声音是在说:花费这么大精力去优化,为啥不去写汇编呢?这又回到了“优化是万恶之源”这个话题。在业务项目中,可能你不用过多关注 String 是如何转换为 Long 和 Integer 的,可能 Integer.valueOf 和 Long.valueOf 就可以满足你的诉求,但如果你是一个需要大数据解析系统,String 转换是系统的瓶颈之一,相信本文的方案会给你一定的启发。
另外对于 SIMD 这些方案,我想再多说一句。其实一些性能挑战赛进行到后,大家的整体方案其实都相差无几,无非是参数差异,因为比赛场景通常不会太复杂,后前几名的差距,就是在一些非常小的细节上。正如 SIMA 提供的向量化运算等优化技巧,它就是可以帮助你比其他人快个几百毫秒,甚至 1~2s。这时候你会感叹,原来我跟大神的差距,就是在这些细节上。但反观整个过程,似乎这些优化并不能帮助程序设计竞赛发挥更大的能量,一个比赛如果只能依靠 CPU 优化来实现区分度,我觉得一定不是成功的。所以,对于主办方而言,禁用掉一些类库,其实有效的避免了内卷,于参赛者而言,算是一种减负了。希望以后的比赛也都朝着让选手花更多精力去优化方案,而不是优化通用的细节上。
再回到 String 解析成 Long/Integer 的话题上。在实际使用时,大家也不用避讳继续使用 Integer.valueOf 或者 Long.valueOf,大多数情况下,这不是系统的瓶颈。而如果你恰好在某些场景下遇到了 String 转换的瓶颈,希望本文能够帮到你。
