一、 基础知识
你会如何处理实时或准实时数据流?
在大数据时代,有很多方案可以帮助你完成这项任务。
接下来,我将通过一个系列的教程,我将利用Storm、Kafka、ElasticSearch逐步教你搭建一个实时计算系统。
搭建系统之前,我们首先需要了解一些定义。
通过考虑四个不同的属性,帮助你更好地理解大数据:数据量,速度,多样性和准确性。
数据量:海量数据 速度:数据处理的速度 多样性:任何类型的数据,包括结构化和非结构化 准确性:传入和传出数据的准确性
存在具有不同用途的大数据工具:
数据处理工具对数据执行某种形式的计算 数据传输工具将数据收集和引入数据处理工具 数据存储工具在不同处理阶段存储数据
数据处理工具可进一步分类为:
批处理:批处理是要一起处理的数据的集合。批处理允许你将不同的数据点连接、合并或聚合在一起。在整个批处理完成之前,其结果通常不可用。批处理越大,等待从中获取有用信息的时间越长。如果需要更直接的结果,流处理是更好的解决方案。 流处理:流处理器作用于无限制的数据流,而不是连续摄取的一批数据点(“流”)。与批处理过程不同,流中没有明确定义的数据流起点或终点,而且,它是连续的。
 批处理
批处理
 流梳理
流梳理
示例数据和方案
我们将使用一些实际数据来数据规约系统(DRS)。根据维基百科,“数据规约是将数字或字母数字信息…转换为校正,有序和简化的形式。基本概念是将大量数据规约为有意义的形式。”
数据源将是实际的航空公司历史飞行数据,我们的终目标是能够在地图上显示航班历史数据。
我们将构建的终数据处理链路如下图所示:

可以使用SMACK替代上述方案:
Spark:引擎(替代Storm) Mesos:容器 Akka:模型 Cassandra:存储(替代ElasticSearch) Kafka:消息队列
或者,你可以尝试自己使用自己喜欢的编程语言来实现它。

单线程调度程序使用以下方式以循环方式将工作分配给多个处理器(例如,可以是Raspberry Pi的阵列)。MQTT用于数据交换。每个处理器并行处理数据并产生结果,这些结果由收集器收集,收集器负责将其存储到数据库,NAS或实时呈现。由于我们没有与用于接收实时飞行数据的真实传感器(例如雷达)建立任何连接以演示实际流处理,因此我们只能选择批处理(即下载历史飞行数据并离线处理它们)。
我们将首先将数据直接存储到ElasticSearch并在Kibana或其他UI应用程序中可视化它们。
ElasticSearch
ElasticSearch是一个面向文档的分布式搜索引擎,用于处理以文档形式存储数据。
ElasticSearch具有如下优势:
跨多个节点可扩展 搜索结果速度非常快 多语种 面向文档 支持即时搜索 支持模糊搜索 开源,不收费
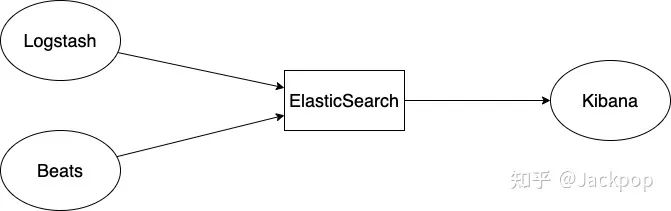
ElasticStack由许多产品组成:
ElasticSearch:我们将在本文中重点介绍的 Kibana:一个分析和可视化平台,可让你轻松地可视化Elasticsearch中的数据并进行分析 LogStash:数据处理管道 Beats:数据传输集合 X-pack:可为Elasticsearch和Kibana添加其他功能,例如安全性(身份验证和授权),性能(监控),报告和机器学习
综上所述,可以使用Beats和/或Logstash将数据导入Elasticsearch,也可以直接通过ElasticSearch的API。Kibana用于可视化ElasticSearch中的数据。
接下来,我们将学习如何安装,启动和停止ElasticSearch和Kibana。在下一篇文章中,我们将提供产品概述,并学习如何将批量航班数据导入ElasticSearch。
1. 安装ElasticSearch & Kibana
访问ElasticSearch网站,下载安装包,解压,然后进行接下,你会发现它包含如下内容:
bin
config
data
jdk
lib
logs
modules
plugins它的主要配置文件是config/elasticsearch.yml。
通过如下命令,可以运行ElasticSearch,
cd <elasticsearch-installation>
bin/elasticsearch使用浏览器打开链接http:// localhost:9200/,如果看到类似以下的内容,那么恭喜你,你已经正常运行ElasticSearch实例了。
{
"name" : "MacBook-Pro.local",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "jyxqsR0HTOu__iUmi3m3eQ",
"version" : {
"number" : "7.9.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "a479a2a7fce0389512d6a9361301708b92dff667",
"build_date" : "2020-08-11T21:36:48.204330Z",
"build_snapshot" : false,
"lucene_version" : "8.6.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
ElasticSearch由一组节点组成(也就是存储数据的ElasticSearch实例),每个节点存储部分数据,同一台计算机上运行多个实例。
http://localhost:9200/_cluster/health?pretty
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : ,
"active_shards" : ,
"relocating_shards" : ,
"initializing_shards" : ,
"unassigned_shards" : ,
"delayed_unassigned_shards" : ,
"number_of_pending_tasks" : ,
"number_of_in_flight_fetch" : ,
"task_max_waiting_in_queue_millis" : ,
"active_shards_percent_as_number" : 100.0
}
集群状态为green,我们看到它仅包含1个节点。数据作为JSON对象(或文档)存储在ElasticSearch中,使用索引将文档组织在群集内。索引是具有相似特征并在逻辑上相关的文档的集合,通过索引,在逻辑上将文档分组在一起,并提供与可伸缩性和可用性相关的配置选项。
数据分布在各个节点中,但是,实际上是如何实现的呢?
ElasticSearch使用分片。
分片是一种将索引分为不同部分的方法,其中每个部分称为分片,分片可水平缩放数据。
如果发生磁盘故障并且存储分片的节点发生故障,该怎么办?
如果我们只有一个节点,那么所有数据都会丢失。
默认情况下,ElasticSearch支持分片复制以实现容错功能。主碎片的副本碎片在存储主碎片的节点以外的节点中创建。主分片和副本分片都称为复制组。在我们只有一个节点的示例中,没有复制发生。如果磁盘出现故障,我的所有数据都会丢失。我们添加的节点越多,通过在节点周围散布碎片就可以提高可用性。
ElasticSearch集群暴露REST API,使得开发者可以通过GET POST PUT DELETE命令进行访问。
有多种方法可以向ElasticSearch发出命令。
通过在浏览器中或使用 curl命令通过Kibana的控制台工具
curl的访问语法如下:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'参数解释:
<VERB>:HTTP请求方法,GETPOSTPUTDELETE<PROTOCOL>或.:如果你在Elasticsearch前面有HTTPS代理,或者使用Elasticsearch安全功能来加密HTTP通信,请使用后者<HOST>:Elasticsearch集群中任何节点的主机名<PORT>:运行Elasticsearch HTTP服务的端口,默认为9200<PATH>:API的endpoint<BODY>:JSON编码的请求正文
例如:
curl -X GET "localhost:9200/flight/_doc/1?pretty"将返回存储在索引中的所有文档,由于我们尚未在ElasticSearch中插入任何文档,因此该查询将返回错误。
前面介绍了ElasticSearch的安装方法,下面介绍一下Kibana的安装。
访问网站下载安装包,解压,通过下方命令运行Kibana:
cd <kibana-installation>
bin/kibana在启动Kibana之前,请确保ElasticSearch已启动并正在运行。
Kibana的目录结构如下:
bin
built_assets
config
data
node
node_modules
optimize
package.json
plugins
src
webpackShims
x-pack运行Kibana(http://localhost:5601)时,会让你提供样本数据或自行探索。
使用浏览器发送下方命令:
GET /_cat/health?v会得到下方信息:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1585684478 19:54:38 elasticsearch green 1 1 6 6 0 0 7 0 - 100.0%_catAPI提供有关属于群集的节点的信息。
有一个更方便的API GET /_cat/indices?pretty,它提供了有关节点的更多详细信息。
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .apm-custom-link ticRJ0PoTk26n8Ab7-BQew 1 0 0 0 208b 208b
green open .kibana_task_manager_1 SCJGLrjpTQmxAD7yRRykvw 1 0 6 99 34.4kb 34.4kb
green open .kibana-event-log-7.9.0-000001 _RqV43r_RHaa-ztSvhV-pA 1 0 1 0 5.5kb 5.5kb
green open .apm-agent-configuration 61x6ihufQfOiII0SaLHrrw 1 0 0 0 208b 208b
green open .kibana_1 lxQoYjPiStuVyK0pQ5_kaA 1 0 22 1 10.4mb 10.4mb在这一部分,我主要介绍了一下搭建数据规约系统涉及到的一些基本概念,以及ElasticSearch、Kibana的安装,确保,这两款关键工具能够正常运行。
在下一篇文章中,我们将看到如何将批量航班数据导入到ElasticSearch,并查看如何实际搜索它们。
二、ElasticSearch操作
在前面这一部分,我已经解释了ElasticSearch的基础知识及其工作原理。
在这一部分,我们将学习如何在ElasticSearch中执行搜索。
CRUD
在开发过程中,主要都在围绕着数据的CRUD进行处理,具体来说就是:
C – Create R – Retrieve or Read U – Update D – Delete
下表将每个CRUD命令与其各自的ElasticSearch HTTP / REST命令进行了一一对应,
| CRUD command | HTTP/REST command |
|---|---|
| Create | PUT or POST |
| Read | GET |
| Update | PUT or POST |
| Delete | DELETE |
上一篇文章中,我们学习了Kibana,接下来,就切换到Kibana的控制台。
1. 创建索引
通过如下命令,创建一个flight索引:
PUT /flight
GET /_cluster/health请注意,现在群集的运行状况已从绿色变为黄色。发生这种情况是因为我们仅运行一个Elasticsearch实例。单节点群集具有完整的功能,但是无法将数据复制到其他节点以提供弹性。副本分片必须有其他可用节点,群集状态才能变为绿色。如果群集状态为红色,则标识某些数据不可用。
为了解决这个问题,您需要安装另一个同样的Elasticsearch,并在elasticsearch.yml中更改node.name;两个实例中的cluster.name必须保持相同(默认为elasticsearch)。
另一种方法是在命令行上将配置参数传递给Elasticsearch。
bin/elasticsearch -Enode.name=node-2 -Epath.data=./node-2/data -Epath.logs=./node-2/logs
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open flight w696u4y3SYWuGW--8VzW6Q 1 1 0 0 208b 208b2. 创建文档
下面,向我们的索引添加一些示例数据:
PUT /flight/_doc/1
{
"Icao":"A0835D",
"Alt":2400,
"Lat":39.984322,
"Long":-82.925616
}也可以使用curl命令:
curl -X PUT "localhost:9200/flight/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"Icao":"A0835D",
"Alt":2400,
"Lat":39.984322,
"Long":-82.925616
}'在这种情况下,ElasticSearch将为我们的文档生成一个自动ID。这是ElasticSearch返回的结果:
Content-Type对于查询成功至关重要, 我们创建了一个ID = 1的新排期。我们也可以使用POST代替PUT,但是在这种情况下,我们无法传递ID。
在这种情况下,ElasticSearch将为我们的文档生成一个自动ID。
下面是ElasticSearch返回的结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : ,
"failed" :
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "flight",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"Icao" : "A0835D",
"Alt" : 2400,
"Lat" : 39.984322,
"Long" : -82.925616
}
}
]
}
}结果文档存储在键值_source内。
3. 删除文档
如果你知道文档索引,可以直接通过索引进行删除:
DELETE /flight/_doc/14. 删除索引
通过下方命令删除索引:
DELETE /flight5. 批量导入数据
我们的方案是处理航班数据,理想情况下,这些数据是从多个传感器(雷达)实时获得的,但是由于这很难实现。
因此,我们将使用可从此处下载的批量历史飞行数据。
在下载批处理文件的目录中,发送以下命令(每个.json文件):
curl -H "Content-Type: application/x-ndjson" -XPOST http://localhost:9200/flights/_bulk --data-binary "@2016-07-01-1300Z.json"请注意,内容类型是application/x-ndjson,而不是application/x-json。
另外,请注意,我们将数据表示为二进制以便保留换行符。
磁瓦ElasticSearch需要json文档满足特定格式:
{"index":{"_id":4800770}}
{"Rcvr":1,"HasSig":false,"Icao":"494102", "Bad":false,"Reg":"CS-PHB", ...}
...这意味着你必须将每个下载的.json文件转换为上述格式。
如果你不想花时间手动修改.json文档,则在下一篇文章中,我们将开发一个Java程序来解析它们,并使用ElasticSearch的REST API将文件插入ElasticSearch中。
6. 搜索查询
ElasticSearch是一款搜索相关的工具,它允许你进行符合条件的搜索查询。
GET /flight/_search?pretty
{ "query": {
"match_all" : {
}
}
}上面的搜索查询匹配索引对应的所有文档。也可以这样简化:
GET /flight/_search下面是根据给定字段Icao进行查询:
GET /flight/_search?pretty
{ "query": {
"match" : {
"Icao" : "A0835D"
}
}
}也可以用嵌入URL进行搜索:
GET /flight/_search?q=Icao:A0835D也可以这样写:
GET /flight/_search?pretty
{ "query": {
"query_string": {
"query": "Icao:A0835D"
}
}
}除了“match”和“query_string”以外,还可以使用“term”。使用“ term”表示匹配。
GET /flight/_search?pretty
{ "query": {
"term": {
"Mil": true
}
}
}你也可以使用“term”来搜索值数组。
除此之外,还可以使用通配符“wildcard”进行搜索,包括*/?。
GET /flight/_search?pretty
{ "query": {
"wildcard": {
"Call": "NJ*"
}
}
}7. 更新文档
如果你知道索引的ID,可以通过_updateAPI进行更新。
POST /flight/_update/4800770
{
"doc": {
"Mil": true
}
}使用上述命令,我们也可以将新字段添加到文档中。
附带说明一下,ElasticSearch的文档是不可变的!
因此,当我们请求更新文档时,ElasticSearch会在后台进行操作,它检索文档,更改其字段并为具有相同ID的文档重新索引,从而对它进行替换。
可以使用脚本发送更复杂的查询,
POST /flight/_update/4800770
{
"script": {
"source": "ctx._source.FlightsCount++"
}
}ctx表示上下文。
还有许多其他更新文档的方法,例如,upserts,即根据文件是否已存在有条件地更新或插入文件。
POST /flight/_update/4800771
{
"script": {
"source": "ctx._source.FlightsCount++"
},
"upsert": {
"Rcvr":1,
"HasSig":false,
"Icao":"AE4839",
...
},
}8. 删除文档
使用_delete_by_query API可以删除文档:
POST /flight/_delete_by_query
{
"query": {
"match_all": {}
}
}9. 批量查询
批量API可帮助我们通过一个查询对许多文档执行同样的操作。
该API包含4个动作:索引,创建,更新,删除:
POST /_bulk
{ "index": { "_index" : "flight", "_id": 10519389 } }
{ "Rcvr":1,"HasSig":true,"Sig":0,"Icao":"A0835D","Bad":false, ... }
{ "create": { "_index" : "flight", "_id": 4800770 } }
{"Rcvr":1,"HasSig":false,"Icao":"494102","Bad":false, ... }
{ "update": { "_index" : "flight", "_id": 4800770 } }
{ "doc": {"Mil": true } }
{ "delete": { "_index" : "flight", "_id": 4800770 } }索引和创建操作之间的区别如下:如果文档已经存在,则创建将引发错误,而索引将替换文档。
如果批量查询要针对相同的索引运行,那么我们可以像这样简化查询:
POST /flight/_bulk
{ "index": { "_id": 10519389 } }
{ "Rcvr":1,"HasSig":true,"Sig":0,"Icao":"A0835D","Bad":false, ... }
{ "create": { "_id": 4800770 } }
{"Rcvr":1,"HasSig":false,"Icao":"494102","Bad":false, ... }
{ "update": { "_id": 4800770 } }
{ "doc": {"Mil": true } }
{ "delete": { "_id": 4800770 } }10. 映射
ElasticSearch是如何映射数据的呢?
动态映射意味着没有明确定义映射,或者至少没有为某些字段定义。
ElasticSearch是通过检查文档字段的值类型来完成的。
要查看数据映射,请在Kibana中执行以下内容:
GET /flight/_mapping我们也可以通过下方命令手动添加映射关系,
PUT /flight/_mapping
{
"properties": {
"location": {
"type": "geo_point"
}
}
}请注意,一旦创建了字段映射,就不能对其进行修改。的方法是删除并重新创建索引。
在下面的示例中,我们手动创建了各种禁用动态映射的映射。
PUT /flight/_mapping
{
"dynamic": false,
"properties": {
"Rcvr": {
"type": "integer"
},
"Icao": {
"type": "text"
},
...
"location": {
"type": "geo_point"
}
}
}如果你更新了映射,请在禁用动态映射的情况下发出以下查询来更新ElasticSearch,
POST /flight/_update_by_query?conflicts_proceed在这部分,我重点介绍了如何使用ElasticSearch的常用功能。
在下一一部分中,我们将学习如何在将json文件转换为ElasticSearch的批量API所需的格式之后,以及通过使用JSON库解析json文件,并将批处理json文件导入到ElasticSearch中。
三、数据导入
在第二部分中,我们学习了如何在ElasticSearch中执行搜索。但是,我们无法使用其批量API将.json数据文件导入ElasticSearch。
在这部分中,我们将进行一些编程,并学习一些有关如何将.json飞行数据文件导入ElasticSearch的方法:
通过将.json数据文件转换为ElasticSearch的API需要的格式 通过解析.json数据文件,使用JSON库(例如gson)提取其值,然后使用ElasticSearch的REST API导入数据
数据转换
ElasticSearch对数据格式有特定的格式要求:
{``"index"``:{``"_id"``:4800770}}
{``"Rcvr"``:1,``"HasSig"``:``false``,``"Icao"``:``"494102"``, ``"Bad"``:``false``,``"Reg"``:``"CS-PHB"``, ...}
...
这就意味着,你需要把下载的每一份json数据按照上述格式进行转换。主要满足如下2点:
在每个数据文档前面加入一行以 index开头的数据把 "Id":<value>修改为{"_id":<value>}
我们可以通过编写简单的Java程序,快速把json文件转换成对应格式:
package com.jgc;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import static java.util.stream.Collectors.toList;
/**
* Converts a flight data json file to a format that can be imported to
* ElasticSearch using its bulk API.
*/
public class JsonFlightFileConverter {
private static final Path flightDataJsonFile =
Paths.get("src/main/resources/flightdata/2016-07-01-1300Z.json");
public static void main(String[] args) {
List<String> list = new ArrayList<>();
try (Stream<String> stream = Files.lines(flightDataJsonFile.toAbsolutePath())) {
list = stream
.map(line -> line.split("\\{"))
.flatMap(Arrays::stream)
.collect(toList());
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(list);
}
}
后,通过简单的拼接,输出我们想要的结果:
final String result = list.stream().skip(3)
.map(s -> "{" + s + "\n")
.collect(Collectors.joining());
System.out.println(result);
现在,可以看到输出已经非常接近我们想要的结果:
{"Id":4800770,"Rcvr":1,"HasSig":false,"Icao":"494102", ...
实际上,我们可以将后一个代码片段添加到原始流中,如下所示:
String result = "";
try (Stream<String> stream = Files.lines(flightDataJsonFile.toAbsolutePath())) {
result = stream
.map(line -> line.split("\\{"))
.flatMap(Arrays::stream)
.skip(3)
.map(s -> "{" + s + "\n")
.collect(Collectors.joining());
} catch (IOException e) {
e.printStackTrace();
}
现在,我们需要在每行的上方插入新行,其中包含文档的索引,如下所示:
{"index":{"_id":4800770}}
我们可以创建一个函数,这样处理会更加简洁明了:
private static String insertIndex(String s) {
final String[] keyValues = s.split(",");
final String[] idKeyValue = keyValues[].split(":");
return "{\"index\":{\"_id\":"+ idKeyValue[1] +"}}\n";
}
这样,就可以对每个输入进行转换,给出我们需要的输出。
我们还需要解决的更多细节,从每个文档中删除后一个逗号。
private static String removeLastComma(String s) {
return s.charAt(s.length() - 1) == ',' ? s.substring(, s.length() - 1) : s;
}
这时候,数据处理代码就变成了下面这个样子:
public class JsonFlightFileConverter {
public static void main(String[] args) {
if (args.length == 1) {
Path inDirectoryPath = Paths.get(args[]);
if (inDirectoryPath != null) {
Path outDirectoryPath = Paths.get(inDirectoryPath.toString(), "out");
try {
if (Files.exists(outDirectoryPath)) {
Files.walk(outDirectoryPath)
.sorted(Comparator.reverseOrder())
.map(Path::toFile)
.forEach(File::delete);
}
Files.createDirectory(Paths.get(inDirectoryPath.toString(), "out"));
} catch (IOException e) {
e.printStackTrace();
}
try (DirectoryStream ds = Files.newDirectoryStream(inDirectoryPath, "*.json")) {
for (Path inFlightDataJsonFile : ds) {
String result = "";
try (Stream stream =
Files.lines(inFlightDataJsonFile.toAbsolutePath())) {
result = stream
.parallel()
.map(line -> line.split("\\{"))
.flatMap(Arrays::stream)
.skip(3)
.map(s -> createResult(s))
.collect(Collectors.joining());
Path outFlightDataJsonFile =
Paths.get(outDirectoryPath.toString(),
inFlightDataJsonFile.getFileName().toString());
Files.createFile(outFlightDataJsonFile);
Files.writeString(outFlightDataJsonFile, result);
}
} catch (IOException e) {
e.printStackTrace();
}
}
} else {
System.out.println("Usage: java JsonFlightFileConverter ");
}
...
使用ElasticSearch的批量API导入数据
需要再次强调,文件必须以空行结尾。如果不是,则添加一个(实际上前面的程序已经在文件末尾添加了换行符)。
在产生新的.json文件的目录(输出目录)内,执行以下命令:
curl -H "Content-Type: application/x-ndjson" -XPOST http://localhost:9200/flight/_bulk --data-binary "@2016-07-01-1300Z.json"请注意,内容类型是application / x-ndjson,而不是application / x-json。
还要注意,我们将数据表示为二进制以便保留换行符。文件名为2016-07-01-1300Z.json。
ElasticSearch中任何具有相同ID的现有文档都将被.json文件中的文档替换。
后,可以发现有7679文件被导入:
"hits" : {
"total" : {
"value" : 7679,
"relation" : "eq"
},
GET /_cat/shards?v
返回结果:
index shard prirep state docs store ip node
flight 0 p STARTED 7679 71mb 127.0.0.1 MacBook-Pro.local
flight 0 r UNASSIGNED解析JSON数据
将这些文档导入ElasticSearch的另一种方法是将JSON数据文件解析到内存中,并使用ElasticSearch的REST API将其导入ElasticSearch。
有许多库可用于解析Java中的JSON文件:
GSon Jackson mJson JSON-Simple JSON-P
我们将使用Google的GSon库,但其他任何JSON库都可以完成此工作。
GSon提供了多种表示JSON数据的方法,具体使用哪一种,则取决于下一步,即如何将数据导入到ElasticSearch。
ElasticSearch API要求数据的格式为:Map<String, Object>,这是我们将解析后的JSON数据存储到的位置。
首先,将下面依赖加入到pom.xml中:
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.6</version>
</dependency>
使用下方代码解析json数据:
package com.jcg;
import com.google.gson.Gson;
import com.google.gson.internal.LinkedTreeMap;
import com.google.gson.reflect.TypeToken;
import java.io.BufferedReader;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
import java.util.Map;
public class JsonFlightFileReader {
private static final String flightDataJsonFile = "src/main/resources/flightdata/2016-07-01-1300Z.json";
private static final Gson gson = new Gson();
public static void main(String[] args) {
parseJsonFile(flightDataJsonFile);
}
private static void parseJsonFile(String file) {
try (BufferedReader reader = Files.newBufferedReader(Paths.get(file))) {
Map<String, Object> map = gson.fromJson(reader,
new TypeToken<Map<String, Object>>() { }.getType());
List<Object> acList = (List<Object>) (map.get("acList"));
for (Object item : acList) {
LinkedTreeMap<String, Object> flight =
(LinkedTreeMap<String, Object>) item;
for (Map.Entry<String, Object> entry : flight.entrySet()) {
String key = entry.getKey();
Object value = entry.getValue();
String outEntry = (key.equals("Id") ? "{" + key : key) + " : " + value + ", ";
System.out.print(outEntry);
}
System.out.println("}");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
通过下述方法可以使用数据:
Map<String, Object> map = gson.fromJson(reader, new TypeToken<Map<String, Object>>() {}.getType());
List<Object> acList = (List<Object>) (map.get("acList"));
使用ElasticSearch REST API导入数据
首先,在pom.xml中加入下方依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.10.0</version>
</dependency>
我们可以通过RestClient与ElasticSearch进行交互:
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200, "http"));
.setDefaultHeaders(new Header[]{
new BasicHeader("accept", "application/json"),
new BasicHeader("content-type", "application/json")})
.setFailureListener(new RestClient.FailureListener() {
public void onFailure(Node node) {
System.err.println("Low level Rest Client Failure on node " +
node.getName());
}
}).build();
创建好RestClient之后,下一步就是创建一个Request,并将json数据传递给它:
Request request = new Request("POST", "/flight/_doc/4800770");
String jsonDoc = "{\"Rcvr\":1,\"HasSig\":false,\"Icao\":\"494102\",...]}";
request.setJsonEntity(jsonDoc);
后,我们发送请求。
有两种方式,同步:
Response response = restClient.performRequest(request);
if (response.getStatusLine().getStatusCode() != 200) {
System.err.println("Could not add document with Id: " + id + " to index /flight");
}
异步:
Cancellable cancellable = restClient.performRequestAsync(request,
new ResponseListener() {
@Override
public void onSuccess(Response response) {
System.out.println("Document with Id: " + id + " was successfully added to index /flight");
}
@Override
public void onFailure(Exception exception) {
System.err.println("Could not add document with Id: " + id + " to index /flight");
}
});
后,不要忘记关闭restClient连接:
} finally {
try {
restClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
这部分,我们重点介绍了如何将.json数据批处理文件导入到ElasticSearch。
我们看到了如何通过两种方式做到这一点:
使用ElasticSearch的批量API, 使用JSON库解析.json文件
你可以根据自己的情况自行选择其中一种方法。
四、Logstash
在本系列文章的第3部分关于实时流处理的文章中,我们学习了如何使用ElasticSearch的批量API以及利用REST API将.json航班数据文件导入ElasticSearch。
在这篇文章中,我们将介绍另一种方式,Logstash。
Logstash介绍
Logstash是一个开源的数据收集引擎,具有实时流水线功能。
它从多个源头接收数据,进行数据处理,然后将转化后的信息发送到stash,即存储。
Logstash允许我们将任何格式的数据导入到任何数据存储中,不仅仅是ElasticSearch。
它可以用来将数据并行导入到其他NoSQL数据库,如MongoDB或Hadoop,甚至导入到AWS。
数据可以存储在文件中,也可以通过流等方式进行传递。
Logstash对数据进行解析、转换和过滤。它还可以从非结构化数据中推导出结构,对个人数据进行匿名处理,可以进行地理位置查询等等。
一个Logstash管道有两个必要的元素,输入和输出,以及一个可选的元素,过滤器。
输入组件从源头消耗数据,过滤组件转换数据,输出组件将数据写入一个或多个目的地。
所以,我们的示例场景的Logstash架构基本如下。
我们从.json文件中读取我们的航班数据,我们对它们进行处理/转换,应用一些过滤器并将它们存储到ElasticSearch中。
Logstash安装
有几种选择来安装Logstash。
一种是访问网站下载你平台的存档,然后解压到一个文件夹。
你也可以使用你的平台的包管理器来安装,比如yum、apt-get或homebrew,或者作为docker镜像来安装。
确保你已经定义了一个环境变量JAVA_HOME,指向JDK 8或11或14的安装(Logstash自带嵌入式AdoptJDK)。
Logstash工作流
一旦你安装了它,让我们通过运行基本的Logstash工作流来测试你的Logstash安装情况。
bin/logstash -e 'input { stdin { } } output { stdout {} }'上面的工作流接受来自stdin(即你的键盘)的输入,并将其输出到stdout(即你的屏幕)。
上面的工作流中没有定义任何过滤器。一旦你看到logstash被成功启动的消息,输入一些东西(我输入的是Hello world),按ENTER键,你应该看到产生的消息的结构格式,像下面这样。
[2021-02-11T21:52:57,120][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Hello world
{
"message" => "Hello world",
"@version" => "1",
"@timestamp" => 2021-02-11T19:57:46.208Z,
"host" => "MacBook-Pro.local"
}然而,通常Logstash是通过配置文件来工作的,配置文件告诉它该做什么,即在哪里找到它的输入,如何转换它,在哪里存储它。Logstash配置文件的结构基本上包括三个部分:输入、过滤和输出。
你在输入部分指定数据的来源,在输出部分指定目的地。在过滤器部分,你可以使用支持的过滤器插件来操作、测量和创建事件。
配置文件的结构如下面的代码示例所示。
input {...}
filter {...}
output{...}你需要创建一个配置文件,指定你要使用的组件和每个组件的设置。在config文件夹中已经存在一个配置文件样本,logstash-sample.conf。
其内容如下所示。
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}这里input部分定义了Logstash应该从哪里获取数据。这里有一个可用的输入插件列表。
我们的输入不是来自Beats组件,而是来自文件系统,所以我们使用文件输入组件。
input {
file {
start_position => "beginning"
path => "/usr/local/Cellar/logstash-full/7.11.0/data/flightdata/test.json"
codec => "json"
}
}我们使用start_position参数来告诉插件从头开始读取文件。
需要注意,数据路径必须是的。
我们使用的是json编解码器,除了json,还可以使用纯文本形式。
在下载的数据中,可以找到一个名为test.json的文件。它只由2条航班数据组成的文件。
输出块定义了Logstash应该在哪里存储数据。我们将使用ElasticSearch来存储我们的数据。
我们添加了第二个输出作为我们的控制台,并使用rubydebugger格式化输出,第三个输出作为文件系统,后两个用于测试我们的输出。我们将输出存储在output.json中。
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "testflight"
}
file {
path => "/usr/local/Cellar/logstash-full/7.11.0/data/output.json"
}
stdout {
codec => rubydebug
}
}此外,还可以定义过滤器来对数据进行转换。
Logstash提供了大量的过滤器,下面介绍一些非常常用的的过滤器:
grok:解析任何任意文本并添加结构,它包含120种内置模式 mutate:对字段进行一般的转换,例如重命名、删除、替换和修改字段 drop:丢弃一个数据 clone:复制一个数据,可能增加或删除字段 geoip:添加IP地址的地理位置信息 split:将多行消息、字符串或数组分割成不同的数据
可以通过执行下方命令查看 Logstash 安装中安装的全部插件列表。
$ bin/logstash-plugin list你会注意到,有一个JSON过滤器插件。这个插件可以解析.json文件并创建相应的JSON数据结构。
正确地选择和配置过滤器是非常重要的,否则,你终的输出中没有数据。
所以,在我们的过滤块中,我们启用json插件,并告诉它我们的数据在消息字段中。
filter {
json {
source => "message"
}
}到此为止,完成的配置文件config/testflight.conf内容如下:
input {
file {
start_position => "beginning"
path => "/usr/local/Cellar/logstash-full/7.11.0/data/flightdata/test.json"
codec => "json"
}
}
filter {
json {
source => "message"
}
}
output {
# elasticsearch {
# hosts => ["http://localhost:9200/"]
# index => "testflight"
# }
file {
path => "/usr/local/Cellar/logstash-full/7.11.0/data/output.json"
}
stdout {
codec => rubydebug
}
}你可以通过如下命令进行一下测试:
bin/logstash -f config/testflight.conf --config.test_and_exit
...
Configuration OK
[2021-02-11T23:15:38,997][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash如果配置文件通过了配置测试,用以下命令启动Logstash。
bin/logstash -f config/testflight.conf --config.reload.automatic
...--config.reload.automatic配置选项可以实现自动重载配置,这样你就不必每次修改配置文件时都要停止并重新启动Logstash。
如果一切顺利,你应该会看到如下的输出结果。
{
"CMsgs" => 1,
"@version" => "1",
"PosTime" => 1467378028852,
"Rcvr" => 1,
"EngMount" => ,
"Tisb" => false,
"Mil" => false,
"Trt" => 2,
"Icao" => "A0835D",
"Long" => -82.925616,
"InHg" => 29.9409447,
"VsiT" => 1,
"ResetTrail" => true,
"CallSus" => false,
"@timestamp" => 2021-02-14T18:32:16.337Z,
"host" => "MacBook-Pro.local",
"OpIcao" => "RPA",
"Man" => "Embraer",
"GAlt" => 2421,
"TT" => "a",
"Bad" => false,
"HasSig" => true,
"TSecs" => 1,
"Vsi" => 2176,
"EngType" => 3,
"Reg" => "N132HQ",
"Alt" => 2400,
"Species" => 1,
"FlightsCount" => ,
"WTC" => 2,
"Cos" => [
[] 39.984322,
[1] -82.925616,
[2] 1467378028852.0,
[3] nil
],"message" => "{\"Id\":10519389,\"Rcvr\":1,\"HasSig\":true,\"Sig\":0,\"Icao\":\"A0835D\",\"Bad\":false,\"Reg\":\"N132HQ\",\"FSeen\":\"\\/Date(1467378028852)\\/\",\"TSecs\":1,\"CMsgs\":1,\"Alt\":2400,\"GAlt\":2421,\"InHg\":29.9409447,\"AltT\":0,\"Lat\":39.984322,\"Long\":-82.925616,\"PosTime\":1467378028852,\"Mlat\":true,\"Tisb\":false,\"Spd\":135.8,\"Trak\":223.2,\"TrkH\":false,\"Type\":\"E170\",\"Mdl\":\"2008 EMBRAER-EMPRESA BRASILEIRA DE ERJ 170-200 LR\",\"Man\":\"Embraer\",\"CNum\":\"17000216\",\"Op\":\"REPUBLIC AIRLINE INC - INDIANAPOLIS, IN\",\"OpIcao\":\"RPA\",\"Sqk\":\"\",\"Vsi\":2176,\"VsiT\":1,\"WTC\":2,\"Species\":1,\"Engines\":\"2\",\"EngType\":3,\"EngMount\":0,\"Mil\":false,\"Cou\":\"United States\",\"HasPic\":false,\"Interested\":false,\"FlightsCount\":0,\"Gnd\":false,\"SpdTyp\":0,\"CallSus\":false,\"ResetTrail\":true,\"TT\":\"a\",\"Trt\":2,\"Year\":\"2008\",\"Cos\":[39.984322,-82.925616,1467378028852.0,null]}",
"Lat" => 39.984322,
"TrkH" => false,
"Op" => "REPUBLIC AIRLINE INC - INDIANAPOLIS, IN",
"Engines" => "2",
"Sqk" => "",
"Id" => 10519389,
"Gnd" => false,
"CNum" => "17000216",
"path" => "/usr/local/Cellar/logstash-full/7.11.0/data/flightdata/test.json",
"Cou" => "United States",
"HasPic" => false,
"FSeen" => "/Date(1467378028852)/",
"Interested" => false,
"Mdl" => "2008 EMBRAER-EMPRESA BRASILEIRA DE ERJ 170-200 LR",
"Spd" => 135.8,
"Sig" => ,
"Trak" => 223.2,
"Year" => "2008",
"SpdTyp" => ,
"AltT" => ,
"Type" => "E170",
"Mlat" => true
}数据转换
首先,让我们从输出中删除path, @version, @timestamp, host和message,这些都是logstash添加的。
filter {
json {
source => "message"
}
mutate {
remove_field => ["path", "@version", "@timestamp", "host", "message"]
}
}mutate过滤器组件可以删除不需要的字段。
重新运行:
bin/logstash -f config/flightdata-logstash.conf –-config.test_and_exit
bin/logstash -f config/flightdata-logstash.conf --config.reload.automatic接下来,我们将_id设置为Id。
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "testflight"
document_id => "%{Id}"
}我们在输出组件中通过设置document_id来实现。
然而,如果你重新运行logstash,你会发现Id字段仍然存在。
有一个窍门,在过滤插件中把它改名为[@metadata][Id],然后在输出中使用,@metadata字段被自动删除。
filter {
json {
source => "message"
}
mutate {
remove_field => ["path", "@version", "@timestamp", "host", "message"]
rename => { "[Id]" => "[@metadata][Id]" }
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "flight-logstash"
document_id => "%{[@metadata][Id]}"
}
...现在让我们尝试解析日期。如果你还记得,这是我们在上一篇文章中没有做的事情,我们需要将日期转换为更适合人们熟悉的格式。
例如:
"FSeen" => "\/Date(1467378028852)\/"需要将时间1467378028852转化成容易阅读的格式,并且去掉前后多余的字符串,通过gsub组件可以实现这项功能:
gsub => [
# get rid of /Date(
"FSeen", "\/Date\(", "",
# get rid of )/
"FSeen", "\)\/", ""
]这里通过gsub去掉了数据中/Date()\等多余部分,输出结果为:
"FSeen" : "1467378028852"然后把时间戳转换成熟悉的格式:
date {
timezone => "UTC"
match => ["FSeen", "UNIX_MS"]
target => "FSeen"
}UNIX_MS是UNIX时间戳,单位是毫秒。我们匹配字段FSeen并将结果存储在同一字段中,输出结果为:
"FSeen" : "2016-07-01T13:00:28.852Z",上述转换的完整代码如下:
mutate {
gsub => [
# get rid of /Date(
"FSeen", "\/Date\(", "",
# get rid of )/
"FSeen", "\)\/", ""
]
}
date {
timezone => "UTC"
match => ["FSeen", "UNIX_MS"]
target => "FSeen"
}在这部分中,我们学习了如何使用Logstash将.json航班数据批量文件导入到ElasticSearch中。Logstash是一个非常方便的方式,它有很多过滤器,支持很多数据类型,你只需要学习如何编写一个配置文件就可以了!
Logstash是否适合实时数据处理?
答案是:要看情况
Logstash主要是为批处理数据而设计的,比如日志数据,也许不适合处理来自传感器的实时航班数据。
不过,你可以参考一些参考资料,这些资料描述了如何创建可以扩展的Logstash部署,并使用Redis作为Logstash代理和Logstash中央服务器之间的中介,以便处理许多事件并实时处理它们。
作者:Jackpop
链接:https://www.zhihu.com/question/469207536/answer/2550197723
