声明一下,本文虽然是自己原创,但是借鉴了网络上的的内容,主要是做知识的归纳总结,如有雷同,纯属我借鉴~
ANTLR(全名:ANotherTool forLanguageRecognition)是基于LL(*)算法实现的语法解析器生成器(parser generator),用Java语言编写,使用自上而下(top-down)的递归下降LL剖析器方法。由旧金山大学的Terence Parr博士等人于1989年开始发展。(好家伙,比我还大)
上面的描述来自维基百科,可以看到 Antlr 可以生成语法解析器,好像也并没有展示它有多厉害。实际上,它的功能十分强大。
你只需要定义一份语法规则的文件,Antlr 会自动的根据你定义的语法规则,帮你进行词法分析和语法分析,并且生成一颗语法树,可以通过 Listener 方式以及 Visitor 模式进行语法树的遍历。
Antlr 的语法分析分为两个阶段
- 个阶段是将字符聚集为单词或者符号的过程称为词法分析,可以实现这一过程的程序叫词法分析器
- 第二个阶段是语法分析输入的词法符号来识别语句结构,生成语法树
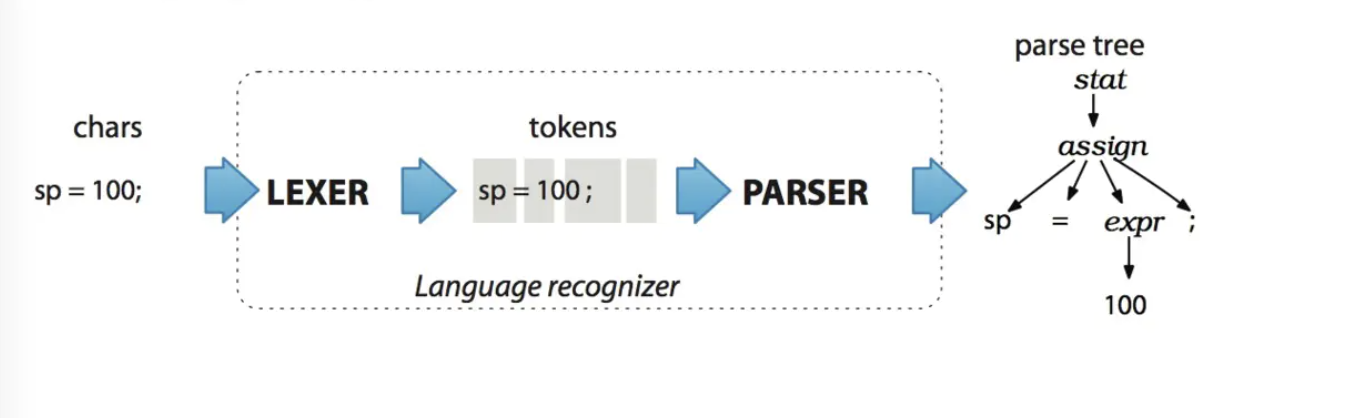
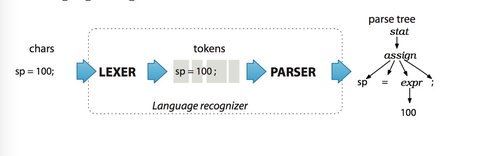
前面的 LEXER 就是词法分析,例子中的 sp = 100; 被分词成四部分(4 个 token),sp、‘=’、100、‘;’,这个过程就是词法分析,然后根据定义的语法规则,后面的 PARSER 就是语法分析,会帮你生成了一个对应的语法树。这一切只需要你提供一份语法规则以及一个输入语句。
至于这个语法规则怎么写,就要遵循 Antlr4 的语法了,对于上面的这个图,我一直没有找到对应的语法规则,就自己写了个简易的,大概结构是我这个样子,大家注意看树的根以及各叶子节点的命名与我下图中规则对应的命名方式。可以通过右击 stat 选择 Test Rule stat,查看语法树的生成,从左边输入语句,右边会产生对应的语法树。
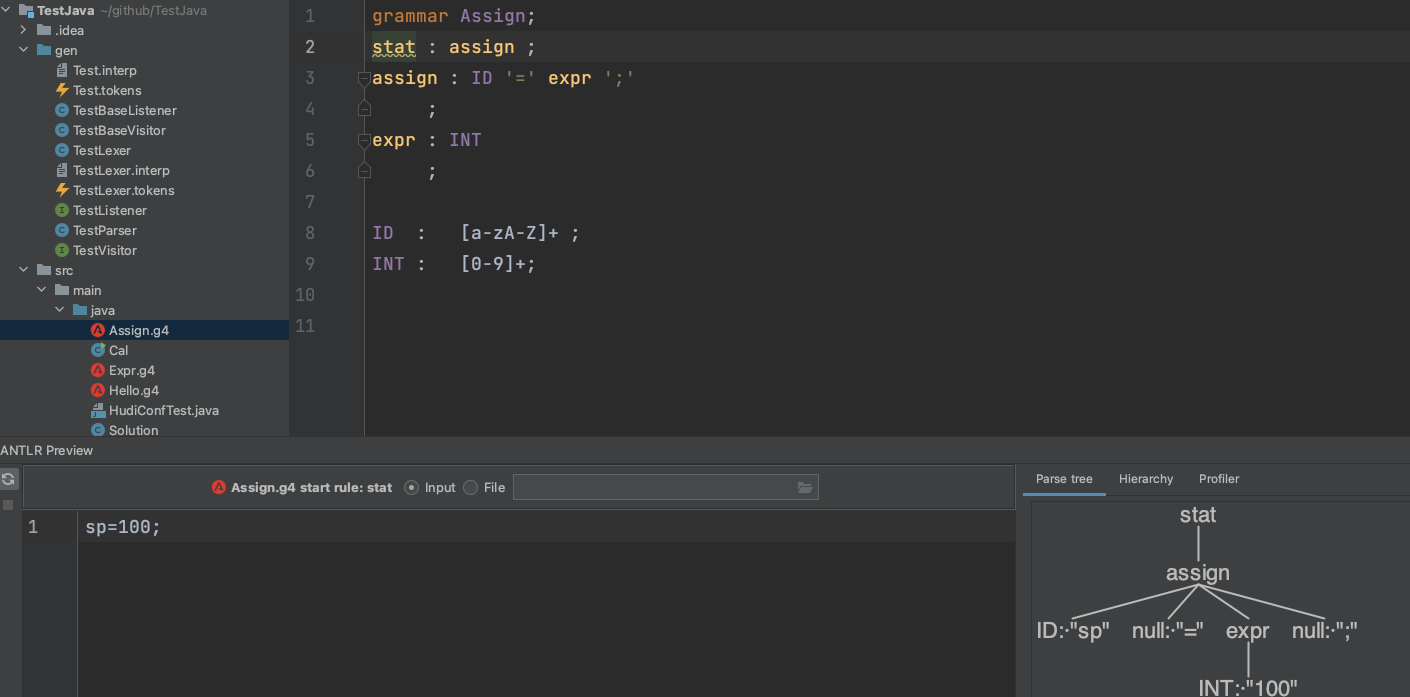
这个只是让大家可以直观的了解到 Antlr 可以做什么,但其实它还在幕后做了很多事情。接下来通过一个计算器的例子,让我们用代码去操纵 Antlr,完成我们想要的功能。
这个例子的目的就是支持简单的四则运算,例子从网上找来的,但是可以清楚的知道使用 Antlr 实现我们需求的过程,由于在 Trino 中使用的是 Visitor 模式,所以这个例子也是使用了 Visitor 模式对语法树进行遍历。
grammar Test; // 规则需要命名为 Test.g4
prog: stat+ ; // 右击 prog -> Generate ANTLR Recognizer
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ; // match identifiers
INT : [0-9]+ ; // match integers
NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal)
WS : [ \t]+ -> skip ; // toss out whitespace当我们定义好规则后,使用 Idea 的 Antlr 插件可以根据你的规则生成一些文件,包含了 Java 文件以及其他的一些东西。
通过右击规则中的 pro,选择 Generate ANTLR Recognizer,可以生成一些文件
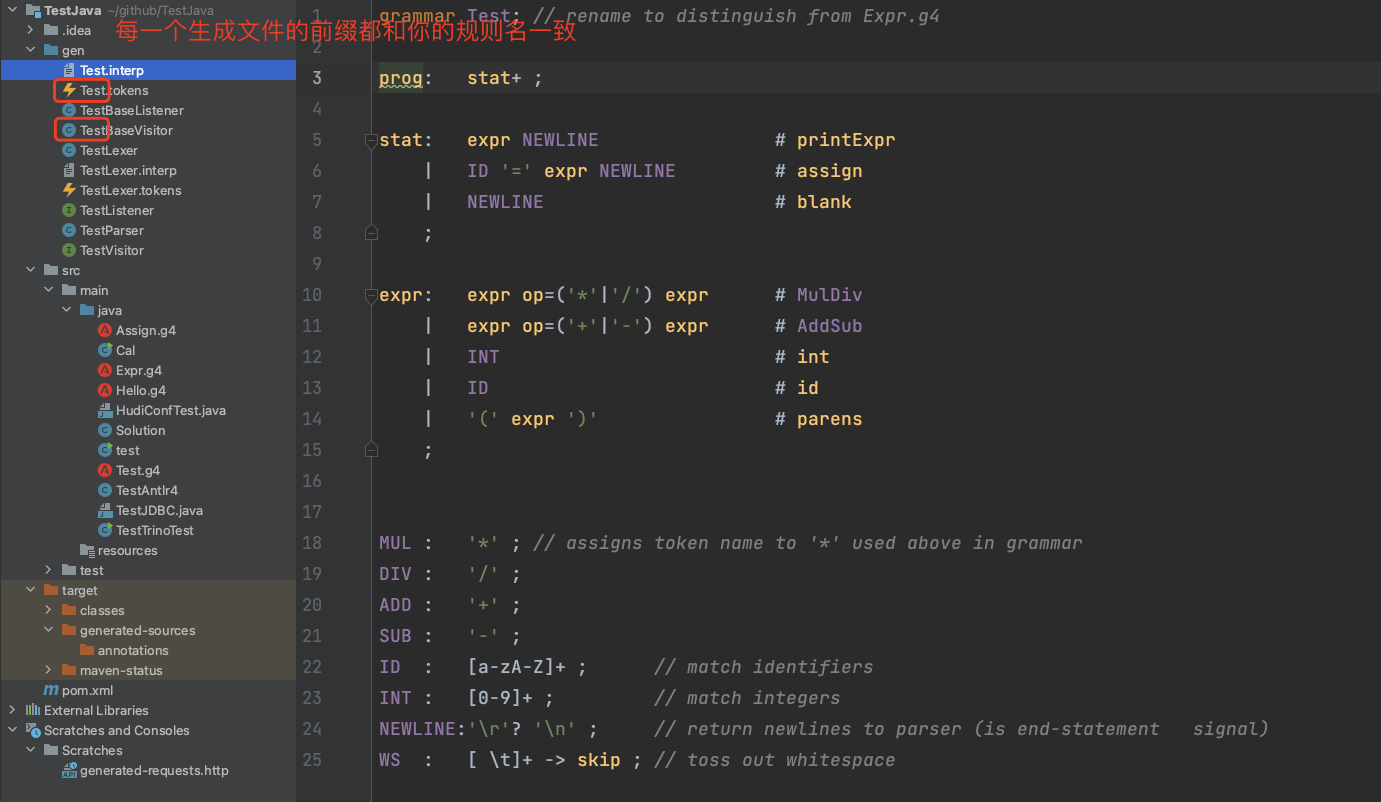
由于我们要使用 Visitor 模式,所以我们需要关注 TestBaseVisitor 这个类
// Generated from /Users/shenjinxin/github/TestJava/src/main/java/Test.g4 by ANTLR 4.9.1
import org.antlr.v4.runtime.tree.AbstractParseTreeVisitor;
/**
* This class provides an empty implementation of {@link TestVisitor},
* which can be extended to create a visitor which only needs to handle a subset
* of the available methods.
*
* @param <T> The return type of the visit operation. Use {@link Void} for
* operations with no return type.
*/
public class TestBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements TestVisitor<T> {
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitProg(TestParser.ProgContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitPrintExpr(TestParser.PrintExprContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitAssign(TestParser.AssignContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitBlank(TestParser.BlankContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitParens(TestParser.ParensContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitMulDiv(TestParser.MulDivContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitAddSub(TestParser.AddSubContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitId(TestParser.IdContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitInt(TestParser.IntContext ctx) { return visitChildren(ctx); }
}里面的每一个方法都是 visitXXXX 模式,可以看到这 9 个方法都是从我们规则中提取出来的,比如 visitProg(), visitPrintExpr(),后面的几个都是我们 # 后面自定义的名字。
我们现在需要做的就是实现这些方法,自定义一个访问器类继承 TestBaseVisitor<T> ,同时需要右击 gen 目录,Mark Directory as -> SourceRoot,否则不能识别 Antlr 生成的类
import java.util.HashMap;
import java.util.Map;
public class TestAntlr4 extends TestBaseVisitor<Integer>{
// map 中存放的是赋值的结果,比如 a = 5,map 中存放 a:5
Map<String, Integer> map = new HashMap<>();
// 每一个参数都是来自于 TestParse.XXXXContext,XXXX 也就是我们在规则中定义的名字
// 完成变量赋值
@Override
public Integer visitAssign(TestParser.AssignContext ctx) {
String id = ctx.ID().getText();
int value = visit(ctx.expr());
map.put(id, value);
return value;
}
// 输出数值
@Override
public Integer visitPrintExpr(TestParser.PrintExprContext ctx) {
Integer value = visit(ctx.expr());
System.out.println(value);
return ;
}
// 匹配括号
@Override
public Integer visitParens(TestParser.ParensContext ctx) {
return visit(ctx.expr());
}
//通过 op 进行识别是乘还是除
@Override
public Integer visitMulDiv(TestParser.MulDivContext ctx) {
int left = visit(ctx.expr());
int right = visit(ctx.expr(1));
if (ctx.op.getType() == TestParser.MUL) {
return left * right;
}
return left / right;
}
// 通过 op 识别是加还是减
@Override
public Integer visitAddSub(TestParser.AddSubContext ctx) {
int left = visit(ctx.expr());
int right = visit(ctx.expr(1));
if (ctx.op.getType() == TestParser.ADD) {
return left + right;
}
return left - right;
}
@Override
public Integer visitId(TestParser.IdContext ctx) {
String id = ctx.ID().getText();
if (map.containsKey(id)) {
return map.get(id);
}
return ;
}
@Override
public Integer visitInt(TestParser.IntContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
}此时我们的自定义访问器类已经写好了,接下来需要将我们访问器类与语法树关联起来
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class Cal {
public static void main(String[] args) throws IOException {
String inputFile = null;
if (args.length > ) {
inputFile = args[];
}
InputStream is = System.in;
if (inputFile != null) {
is = new FileInputStream(inputFile);
}
// 从文件中读取输入
ANTLRInputStream input = new ANTLRInputStream(is);
// 阶段的词法分析
TestLexer lexer = new TestLexer(input);
// 词法分析进行分词,获取 token
CommonTokenStream tokens = new CommonTokenStream(lexer);
// 第二阶段的语法分析
TestParser parser = new TestParser(tokens);
// 生成语法树
ParseTree tree = parser.prog();
// 实例化访问器类,只需要调用 visit 方法就可以实现我们想要的功能
TestAntlr4 test = new TestAntlr4();
test.visit(tree);
}
}
对于语法树的遍历顺序是这样的
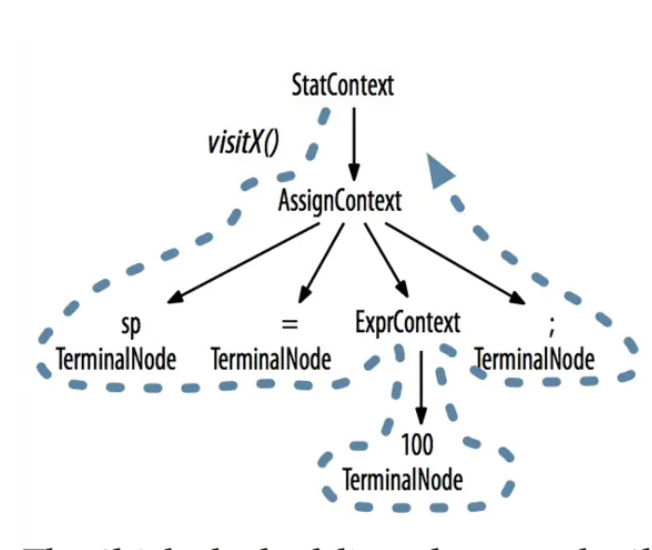
例如我们输入 1 + 2 * 3,根据语法树解析的结果,可以分析得到的是 7
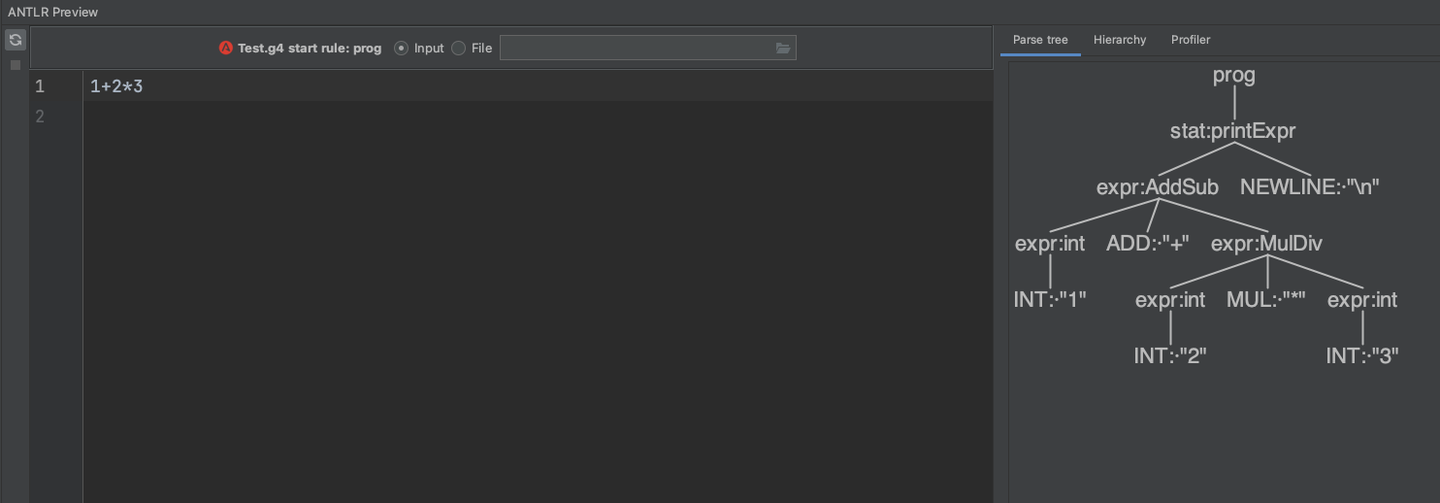
至此,我们就完成了 Antlr4 实现计算器的功能,当然了也支持括号以及乘除。主要目的是为了让大家了解 Antlr4 的使用流程。将这个例子看懂后,就可以自行去看 Trino 的 trino-parse 相关的代码了,只不过 trino 的语法规则更多,更复杂而已。
上文中,我发现 1 + 2 * 3 的时候,得到的是 7,说明乘除法的优先级是比加减法高的,因此我又手动改了 Test.g4 规则中 乘除和加减的前后顺序,发现此时的语法树已经变了
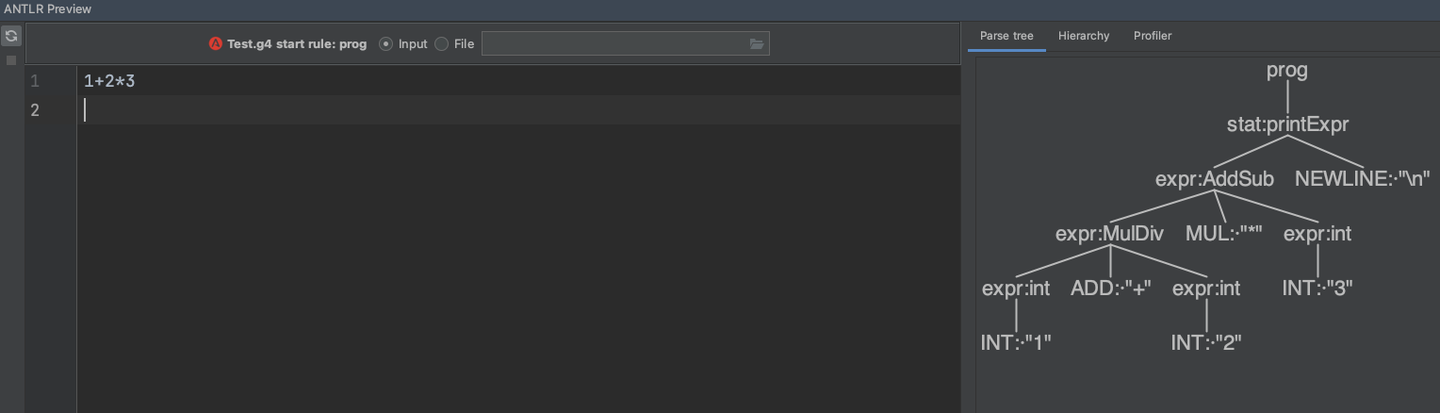
根据我们的遍历顺序,可以知道,先计算了 1 + 2 然后才计算的 * 3 后结果是 9,所以在咱们自定义的规则里,可以自己说了算,hhh~
本文的内容,主要是参考了两个链接,
还有一个
还有本书 Antlr 权威指南,想深入学习 Antlr 的可以去看看
原文链接:https://zhuanlan.zhihu.com/p/379236899
