背景
中国科学院“地球大数据科学工程”A类战略性先导科技专项(简称“地球大数据专项”)于2018年1月1日正式立项。该工程以建成具有全球影响力、国际化、开放式的国际地球大数据科学中心为目标,致力于推动并实现地球大数据技术创新、重大科学发现和一站式全方位宏观决策系统。
地球大数据专项一个典型的应用例子是:定量统计分析黄河三角洲过去40年的变化,包括湿地海岸线、河岸生态系统以及土地利用类型等。传统的做法是派遣科研人员到实地考察,这是几乎不能完成的任务。我们希望通过该工程,基于对地检测卫星过去40年拍摄到的黄河三角洲的遥感图片,利用深度学习和海量地理数据处理技术,地量化具体变化指标。
产品形态上,地球大数据专项的目标是打造中国版的“谷歌地球”,设置了包括地球大数据卫星、数据一路一带、全景美丽中国和大数据云服务平台等在内的共9个子项目。其中,大数据云服务平台是整个专项的技术基座,通过将资源、环境、生物、人文、生态等领域的数据汇聚起来,构建一个数据存储、分析处理和共享平台,并在此基础上提供数字地球科学服务。
面临挑战
作为一个雄心勃勃的项目技术基座,地球大数据云服务平台自然面临着一系列技术挑战:
数据规模庞大,结构众多:
• 支持38PB基础存储量,每年新增5PB数据;
• 对地观测、地面观测、基础地理等多种业务模式;
• 涵盖结构化、半结构化、非结构化格式;
应用场景广泛:
• 支持33个院系、129个单位使用;
• 涵盖资源、环境、生物、生态多个领域,不同学科的融合;
科学计算特性:
• 满足高性能计算需求及数据格式多样化;
数据存储和访问:
• 支持100+PB的数据规模及灵活访问方式;
共享与隔离:
• 方便数据共享及计算性能的隔离;
解决方案
作为地球大数据专项的外协单位,我们与中科院网络中心、中科院计算所一起参与规划建设了大数据云服务平台,利用HashData数据仓库为整个工程提供海量数据的存储和处理分析能力。大数据云平台整体架构图如下:
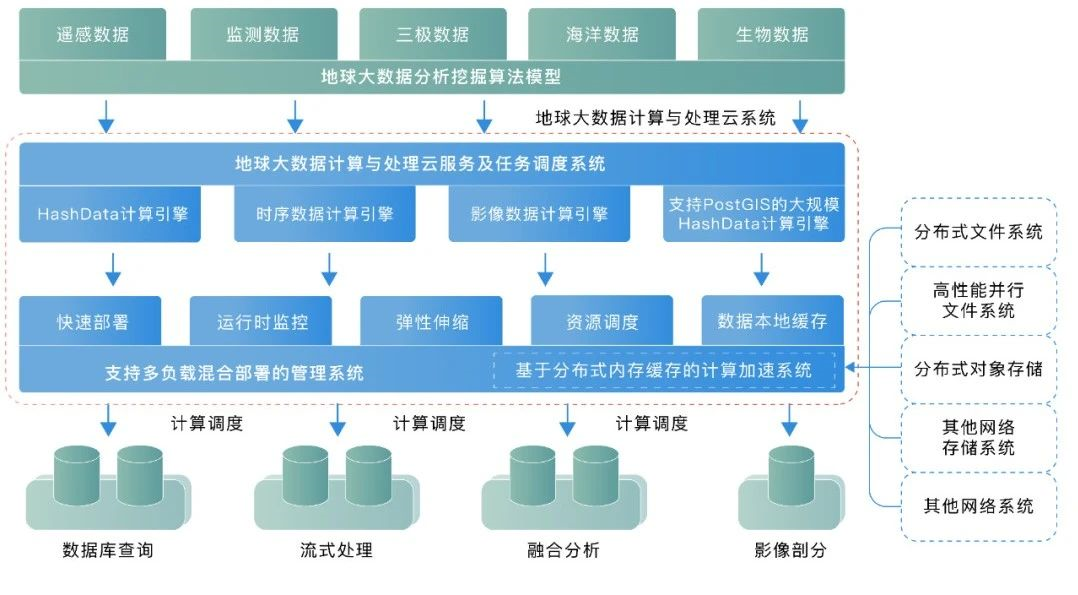
其次,对象存储作为整个地球大数据云平台的数据持久层,能够以非常低的成本存储提供海量存储能力,包括结构化、半结构化和非结构化数据,有很高的可用性和持久性,满足专项日益增长的数据量。结合HashData湖仓一体的能力,用户可以通过统一的SQL接口对各种数据进行高性能的融合分析处理。
再次,借助HashData数据仓库元数据、计算和存储三者分离、多集群统一数据存储的架构(参考文章《HashData多集群共享统一存储架构》),每个科研院系单位都可以创建自己的计算集群,确保计算性能隔离的同时,又能够实现数据在不同院系之间的充分共享,加速科研进度。
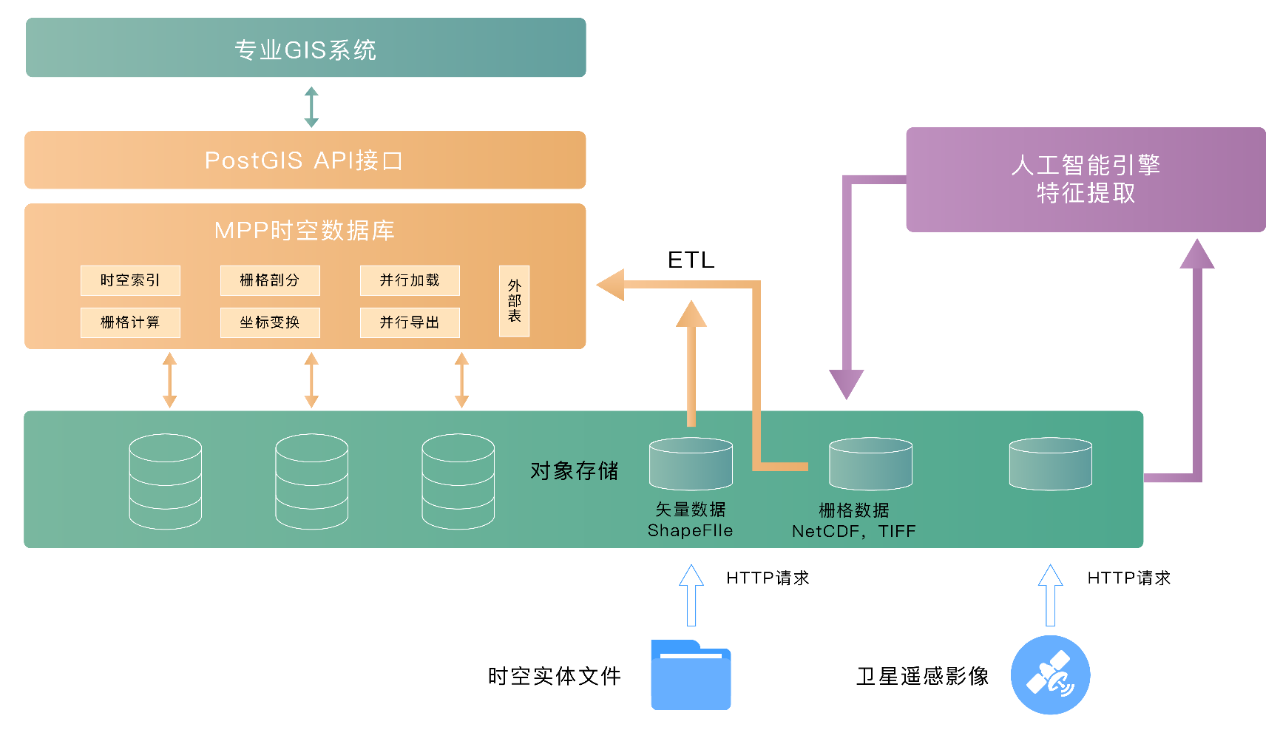
后,通过基于HashData的MPP计算引擎实现分布式PostGIS功能,进行矢量和栅格数据处理,架构示意如下:
总结
HashData数据仓库云服务已于2020年12月30号在地球大数据云平台上线,可为130余家科研院所提供大数据分析服务。除了为大数据云平台包括地球共享服务系统、CASEarth Databank系统和数据丝路地球大数据系统等其它系统提供支撑外,同时还为科学院内部院系提供通用的数据仓库服务,用于多种应用场景,包括寒旱所的地表观测数据处理,遥感所的植被分布统计,和地质所的地质勘探数据分析。在地理信息数据处理性能方面,相对于之前的解决方案,HashData数据仓库也有很大的提升,例如数据加载提速近100倍,栅格数据叠加分析提速近70倍。
随着地球大数据云平台的逐步成熟稳定,HashData数据仓库将支撑越来越多的数据存储、分析和共享任务,为中科院数字地球科学研究做出更多贡献。
