In this era of Digital Transformation where a growing numbers of companies move their application data to the Public cloud, NewSQL has become a center of attention due to its key offers like Horizontal scalability, SQL Support and a great way for users to access the data using APIs. Large Enterprises thinking about their long-term architecture should consider the implications on the database layer and the potential for a more distributed and flexible database architecture, which will make NewSQL vendors worth exploring. Cloud enabled new applications require new databases and the NewSQL db engine designed to support these applications. Most of the Customers are moving away from their old data warehouse platforms to “Data Lake” because they don’t have the flexibility they need with the existing Traditional DWH. So the current innovation on the Database field promising the database landscape continuous to shift further and its just a beginning of end of NoSql or I can say its one more opportunity for IT professionals to be part of this NewSQL Journey.

Cloud Database : A cloud database is a database that typically runs on a Public cloud computing platform but not limited to Public cloud but also compatible for Private and Hybrid Cloud Environment.
There are two * of cloud database: VM (IaaS) and Database As a Service (DBaaS)
Database as a Service (DBaaS)
Database as a Service (DBaaS) is a method of storing and managing data in the Cloud Computing environment. DBaaS service providers are hosting your database using appropriate database infrastructure through PaaS on the cloud. Google Cloud Spanner is DBaaS Service Offering Model ( Part of GCP — Google Cloud Platform ) is the best of RDBMS+NoSQL Database.

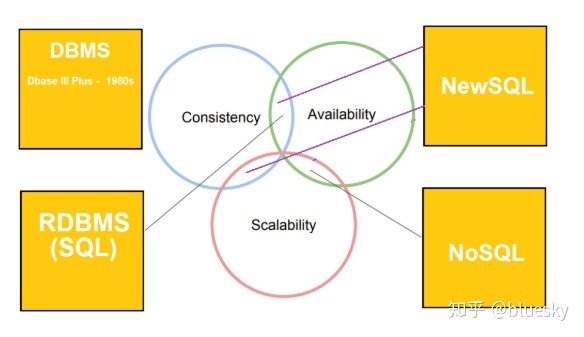
There are Three * of database technology: Relational Databases (Structured-SQL) ; Non-Relational Databases (Unstructured-NoSQL); NewSQL. The DBaaS Model shifting most of the Database Admin tasks to Service Operator : Configuration, Scalability, Performance Tuning, Backup, Recovery, Monitoring, Security, Access Control etc.
A database can be highly scalable and distributed (NoSQL approach), or it can be transactionally consistent (RDBMS approach).
Key Features of Google Cloud Spanner:
Google Cloud Spanner designed to achieve all these features. Google Spanner is a automatic Synchronously-Replicated Globally-Distributed Multi-Version Database and the key features are given below:
99.999% SLA: Google Cloud Spanner uses Google Infrastructure ( private wide area network ) and TruTime Technology , so the data is highly available.
Externally Consistent: 2-Phase Commits and Custom Paxos
Fully Managed: Replication and Maintenance are Automatic
Easily Scalable: The biggest advantage is Spanner supports horizontal scalability concept and designed for horizontal scalability for read & write mode i.e its only database that supports read & write mode scalability or we can say scales-out both writes and reads without any application changes. ( AWS RDS only supports read mode scalability ).
ACID Transactions: Google Cloud Spanner supports ACID Transactions.
SQL Query Support: Google Cloud Spanner supports SQL Language.
Enterprise Grade Security: Data-layer encryption, IAM integration for access and control.
Cloud Spanner — A NewSQL Database for “always-on” Enterprises
Google Cloud Spanner is a cloud native, enterprise grade and fully managed relational database service offering high availability, horizontally scalability with consistent global ACID transactions. It is the only enterprise-grade NewSQL , globally-distributed and strongly consistent database service built for the cloud specifically to combine the benefits of relational & NoSQL Database. This combination delivers high-performance transactions and strong consistency across rows, regions, and continents with an industry-leading 99.999% availability SLA, no planned downtime, and enterprise-grade security.
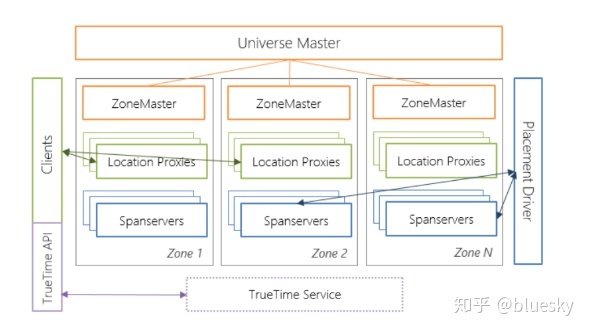
Spanner Architecture Overview
Cloud Spanner was designed to offer horizontal scalability and a developer-friendly SQL interface. Each deployed Spanner instance called Universe (Spanner Deployment) :
Basic Architecture elements:
Replica consistency: Using Paxos protocol; Concurrency Control: Using two phase locking Transaction coordination: 2 phase commit; Timestamps for transactions: Multiple timestamped versions of data items maintained
The Cloud Spanner deployment having the below components
Universe Master — Master-process, coordinating the work of many Spanner zones. Universe master displays zone status information.
Spanner Zones : A zone is the unit of administrative deployment and a cluster in each zone contains multiple span servers. Zones are distributed across Data Centers. Each Zone contains one zone-master and 100 to 1000s of spanservers.
ZoneMaster (one per zone) : Zonemasters assign data to spanservers which server clients.
Poxos: Paxos is a consensus protocol. The major issue Cloud Spanner addresses is database replication on a global scale and it provides data consistency even if multiple users conduct transactions which required to connect to data centers across globe. Cloud Spanner eliminates that bottleneck by using the Paxos system of protocols, which relies on an algorithm to create consensus among globally distributed nodes to determine which location, largely based on data gravity is the most authoritative to conduct the commit.
Spanserver: Spanserver serves data to clients and each spanserver is responsible for 100 to 1000 tablets which hold the key-value mappings. Data is replicated across spanservers ( could be multiple data-centers ) in the unit of tablets. To support replication, each spanserver implements a Paxos state machine on top of each tablet.
Location proxy : Location proxies help clients locate spanservers
Placement driver: A process that controls the movement of data between different Zone.
TrueTime: This is an implementation of synchronized clocks using GPS receivers and atomic clocks in every data center. TrueTime gives Cloud Spanner a crucial piece of information for write activity i.e the system can absolutely determine the serial order of writes, even across distributed nodes. Using this information, consistency issues across nodes in a cluster can be determined and prevented. TrueTime API sync
Spanner supports read-write transactions, read-only transactions and snapshot reads. Standalone writes are implemented as read-write transactions; non-snapshot standalone reads are implemented as read-only transactions. A snapshot read is a read in the past. Concurrency control achieving using two phase locking and Transaction coordination using 2 phase commit. Read-write transactions use 2-phase locking and 2-phase commit. The client first issues reads to the leader of the appropriate group which acquires read locks and reads the most recent data. When a client has completed all reads and buffered all writes then it starts 2-phase commit. Read-write transactions can be assigned commit timestamps by the coordinator leader at any time when all locks have been acquired but before any locks have been released. In Cloud Spanner when data is locked during write operations, spanner only has to lock cells ( a cell is particular column in a particular row) rather then lock the entire row which minimizes contention and accelerates transaction commitment.
Creating a Cloud Spanner database is very easy using Google Cloud Console and just need to setting the number of nodes required and selecting the regional location.
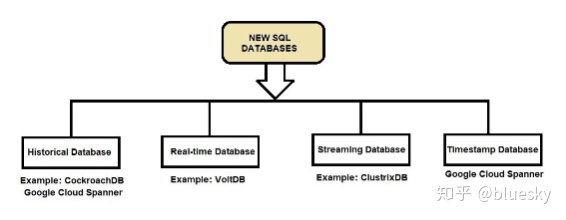
* of NewSQL Databases
There are 3 * of NewSQL and there are no competitors to Google’s Spanner database. Spanner relies on a TrueTime implementation. There are no other known implementations of databases which utilize a time system like TrueTime.
Comparison between SQL , NoSQL and NewSQL Databases

