背景与挑战
在对象存储技术出现和普及之前,HDFS(Hadoop分布式文件系统)是市场上为数不多的开源、免费、高性价比(相对于昂贵的SAN系统)PB级存储系统,大量用于企业数据归档场景。同时,HDFS之上衍生了很多针对不同技术要求的分布式计算框架,使其适用于非结构化数据的清洗规整、流式计算和机器学习等场景。另一方面,数据仓库作为主数据系统,保存着企业内部具商业价值的历史数据,同时支撑日常的经营分析和商业决策。在很多大型机构中,这两套系统是共存的。因此,如何实现与以HDFS为基础的大数据平台之间的高效数据互访,是每一款现代数据仓库产品需要考虑和解决的问题。
作为业界相当领先的开源企业级数据仓库产品,Greenplum Database(下面简称GPDB)主要提供了两种方式:PXF和GPHDFS。虽然二者都利用了GPDB的外部表功能,但是前者需要额外安装部署PXF服务器进程,在复杂的IT环境中流程繁琐、极易出错,终端用户体验不佳。所以,在初期规划和实现HashData数据仓库访问HDFS的功能时,即采用GPHDFS的技术路线:通过增加一种访问HDFS的外部表协议,让各个计算节点直连HDFS集群,不通过任何中间节点或者系统,大幅降低使用门槛的同时,保证两个系统之间数据交换的效率。
在进一步阐述实现细节之前,我们先简单回顾一下GPDB自带的GPHDFS在实际使用过程中面临的挑战(这是一个大型银行客户的真实反馈):
1. 需要额外安装软件
每个节点安装Java;
每个节点安装Kerberos客户端;
每个节点安装Hadoop客户端;
2. 配置复杂、易出错
配置gpadmin用户的Java环境变量;
更改数据库参数;
针对每个HDFS集群,每个节点配置Hadoop core-site.xml、yarn-site.xml和hdfs-site.xml;
3. 无法同时访问多套HDFS系统
每个数据库会话只能访问一套HDFS系统(与环境变量设置相关), 无法同时访问多套HDFS系统(例如将不同HDFS上的数据进行关联)。
HashData的GPHDFS实现
继承于GPDB,HashData原生支持多种外部表协议,除了上述的GPHDFS,还包括FILE(文件系统)、GPFDIST(文件服务器)、OSS(对象存储)等, 可用于实现数据的高速加载与卸载。下面为GPHDFS外部表的示意图:
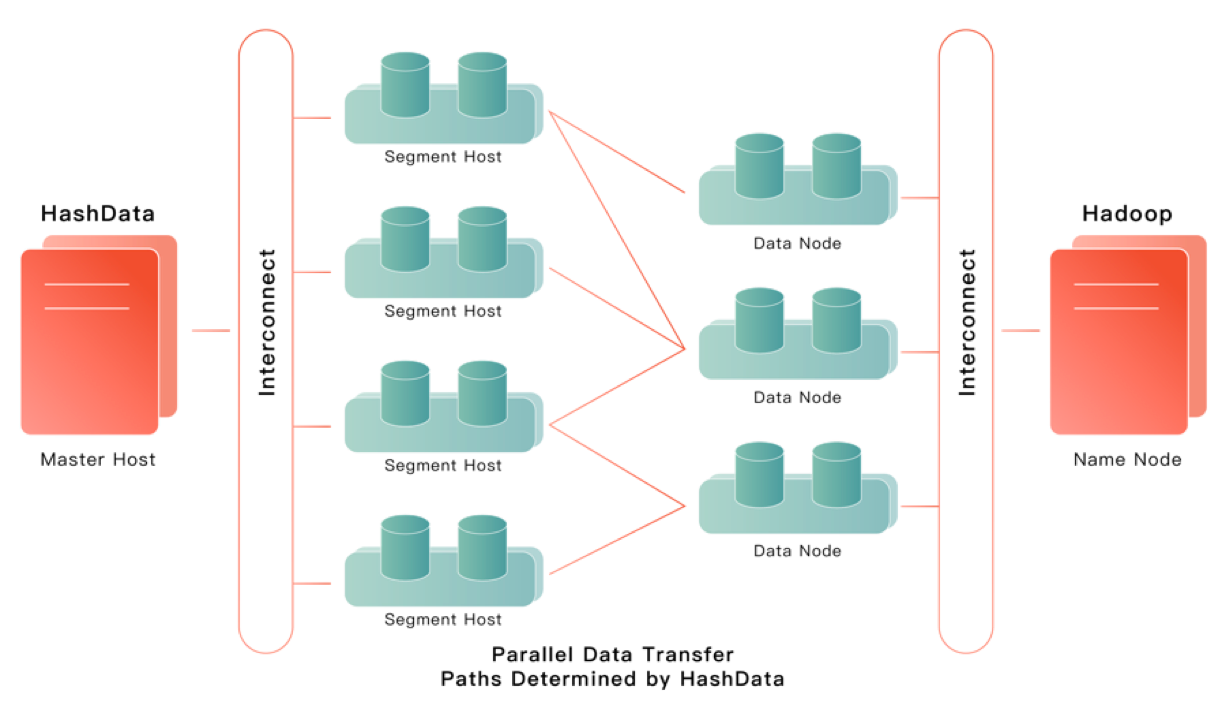
技术架构层面,HashData的GPHDFS实现跟GPDB的GPHDFS是一致的,更多的差异是体现在实现细节层面。首先,我们采用C++原生实现的libhdfs3作为访问HDFS的客户端,在规避了安装、部署、配置Java运行环境以及Hadoop客户端等纷繁复杂、极易出错环节的同时,降低系统CPU和内存使用率。
其次,引入类似Oracle数据源配置文件的gphdfs.conf文件,将多个HDFS系统相关的访问信息集中起来,简化访问配置的管理;修改HDFS外部表定义的语法,省略大量的配置选项(放到gphdfs.conf文件),大幅降低用户的使用难度。因为解耦了Hadoop客户端(包括环境变量的配置)和HDFS系统的对应关系,新的GPHDFS能够在同一条SQL语句中同时访问多个HDFS(这些HDFS系统可以由多个不同的Hadoop厂商提供)外部表,极大方便复杂大数据系统中的多源数据融合。
后,受益于PostgreSQL灵活优雅的扩展框架(当然,也包括GPDB的外部表框架),可以轻松实现在不修改数据库内核代码的情况下以扩展插件的方式将这个新的GPHDFS功能放到各个开源版本的GPDB,替换原来的实现。
应用实践
Hadoop集群采用Kerberos验证情况下配置
安装kinit(每个节点都安装):
yum install krb5-libs krb5-workstation配置krb5.conf(每个节点配置):
[realms]HADOOP.COM = {admin_server = host1kdc = host1kdc = host2}
拷贝kerberos的认证用户的keytab文件到每个节点:
gpscp -f hostfile user.keytab =:/home/gpadmin/key_tab/ 配置gphdfs.conf文件(每个节点都配置):
hadoop_cluster1:hdfs_namenode_host: pac_cluster_masterhdfs_namenode_port: 9000hdfs_auth_method: kerberoskrb_principal: gpadmin/hdw-68212b9b-master0@GPADMINCLUSTER2.COMkrb_principal_keytab: /home/gpadmin/hadoop.keytabhadoop_rpc_protection: privacyis_ha_supported: truedfs.nameservices: myclusterdfs.ha.namenodes.mycluster: nn1,nn2dfs.namenode.rpc-address.mycluster.nn1: 192.168.111.70:8020dfs.namenode.rpc-address.mycluster.nn2: 192.168.111.71:8020dfs.namenode.http-address.mycluster.nn1: 192.168.111.70:50070dfs.namenode.http-address.mycluster.nn2: 192.168.111.71:50070dfs.client.failover.proxy.provider.mycluster: org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailover...hadoop_cluster2:...
Hadoop集群未采用Kerberos验证情况下配置
配置gphdfs.conf文件(每个节点都配置):
hadoop_cluster1:hdfs_namenode_host: pac_cluster_masterhdfs_namenode_port: 9000hdfs_auth_method: simplekrb_principal: gpadmin/hdw-68212b9b-master0@GPADMINCLUSTER2.COMkrb_principal_keytab: /home/gpadmin/hadoop.keytabhadoop_rpc_protection: privacyis_ha_supported: truedfs.nameservices: myclusterdfs.ha.namenodes.mycluster: nn1,nn2dfs.namenode.rpc-address.mycluster.nn1: 192.168.111.70:8020dfs.namenode.rpc-address.mycluster.nn2: 192.168.111.71:8020dfs.nameno`de.http-address.mycluster.nn1: 192.168.111.70:50070dfs.namenode.http-address.mycluster.nn2: 192.168.111.71:50070dfs.client.failover.proxy.provider.mycluster: org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailover...hadoop_cluster2:...
| 参数 | 说明 |
| hdfs_namenode_host | 配置HDFS的Host信息 |
| hdfs_namenode_port | 配置HDFS的端⼝信息 |
| hdfs_auth_method | 配置HDFS身份验证模式,普通的HDFS使⽤Simple,带有Kerberos的使⽤Kerberos |
| krb_principal | Kerberos中⽤户 |
| krb_principal_keytab | ⽤户⽣成的Keytab放置的位置 |
| hadoop_rpc_protection | 与HDFS core-site.xml中的配置⼀样 |
| hadoop_cluster2 | 被访问的第二个Hadoop集群名称,如果还有其他Hadoop集群,可以依次配置 |
| 其它参数 | Hadoop集群启⽤⾼可⽤的情况下配置,未启⽤可以不配置 |
访问hadoop_cluster1集群:
写入数据到HDFS:
CREATE WRITABLE EXTERNAL TABLE ext_w_t1(id int,name text) LOCATION(‘gphdfs://tmp/test1/ hdfs_cluster_name=hadoop_cluster1’) format ‘csv’;INSERT INTO ext_w_t1 VALUES(1,'hashdata');
读取HDFS数据:
CREATE READABLE EXTERNAL TABLE ext_r_t1(id int,name text) LOCATION(‘gphdfs://tmp/test1/ hdfs_cluster_name=hadoop_cluster1’) format ‘csv’;SELECT * FROM ext_r_t1;
要访问hadoop_cluster2集群,需要在创建的外部表时,设置hdfs_cluster_name=hadoop_cluster2。
HashData GPHDFS落地使用情况
2019年之前,作为GPDB全球使用规模大、场景复杂、负载高的客户,某大型国有银行在x86物理服务器上运行着数十套各个版本的GPDB集群,以及由单一厂商提供的Hadoop集群。2019年开始,随着大数据云平台项目的实施,该客户开始逐步将大数据分析业务迁移到云化Hadoop和云端数据仓库系统(HashData数据仓库)。到目前为止,已上线20多套HashData计算集群,以及数套至少由两家不同厂商提供的Hadoop集群。通过使用HashData提供的新GPHDFS功能,客户可以实现每天在近百个MPP生产集群(包括原有的GPDB集群和新的HashData集群)方便、敏捷和高效地完成数千个访问多套HDFS系统的作业。
