本文将对Flink Transformation中各算子进行详细介绍,并使用大量例子展示具体使用方法。Transformation各算子可以对Flink数据流进行处理和转化,是Flink流处理非常核心的API。如之前文章所述,多个Transformation算子共同组成一个数据流图。
Flink的Transformation是对数据流进行操作,其中数据流涉及到的常用数据结构是DataStream,DataStream由多个相同的元素组成,每个元素是一个单独的事件。在Scala中,我们使用泛型DataStream[T]来定义这种组成关系,T是这个数据流中每个元素对应的数据类型。在之前的股票数据流处理的例子中,数据流中每个元素的类型是股票价格StockPrice,整个数据流的数据类型为DataStream[StockPrice]。在Java中,这种泛型对应的数据结构为DataStream<T>。
在使用这些算子时,需要在算子上进行用户自定义操作,一般使用Lambda表达式或者继承模板类并重写函数两种方式完成这个用户自定义的过程。下文将用map算子来演示如何使用Lambda表达式或者重写函数的方式实现对算子的自定义。
读者可以使用Flink Scala Shell或者Intellij Idea来进行练习:
Flink的Transformation转换主要包括四种:单数据流基本转换、基于Key的分组转换、多数据流转换和数据重分布转换。本文先介绍单数据流基本转换,完整的代码在github上:https://github.com/luweizheng/flink-tutorials
map
map算子对一个DataStream中的每个元素使用用户自定义的map函数进行处理,每个输入元素对应一个输出元素,终整个数据流被转换成一个新的DataStream。输出的数据流DataStream[OUT]类型可能和输入的数据流DataStream[IN]不同。
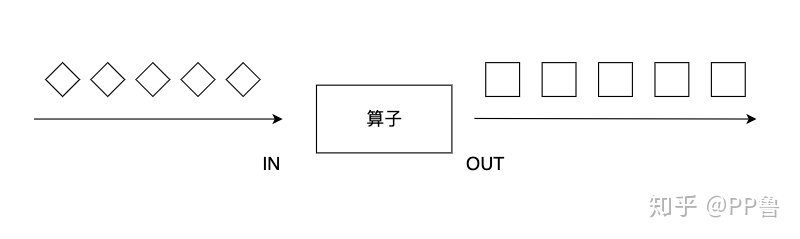
我们可以重写MapFunction或RichMapFunction来自定义map函数,RichMapFunction的定义为:RichMapFunction[IN, OUT],其内部有一个map虚函数,我们需要对这个虚函数重写。
val dataStream: DataStream[Int] = senv.fromElements(1, 2, -3, , 5, -9, 8)
// 继承RichMapFunction
// 个泛型是输入类型,第二个参数是泛型类型
class DoubleMapFunction extends RichMapFunction[Int, String] {
override def map(input: Int): String =
("overide map Input : " + input.toString + ", Output : " + (input * 2).toString)
}
val richFunctionDataStream = dataStream.map {new DoubleMapFunction()}上面的代码清单重写了RichMapFunction中的map函数,将输入结果乘以2,转化为字符串后输出。我们也可以不用显示定义DoubleMapFunction这个类,而是使用匿名类:
// 匿名类
val anonymousDataStream = dataStream.map {new RichMapFunction[Int, String] {
override def map(input: Int): String = {
("overide mapInput : " + input.toString + ", Output : " + (input * 2).toString)
}
}}自定义map函数简便的操作是使用Lambda表达式。
// 使用=>构造Lambda表达式
val lambda = dataStream.map ( input => (input * 2).toDouble )上面的代码清单中,我们对某整数数据流进行操作,输入元素均为Int,输出元素均为Double。
也可以使用下划线来构造Lambda表达式:
// 使用 _ 构造Lambda表达式
val lambda2 = dataStream.map { _.toDouble * 2 }注意,使用Scala进行Flink编程,自定义算子时可以使用圆括号(),也可以使用花括号{}。
对上面的几种方式比较可见,Lambda表达式更为简洁,但是可读性差,其他人不容易读懂代码逻辑。重写函数的方式代码更为臃肿,但定义更清晰。此外,RichFunction还提供了一系列其他方法,包括open、close、getRuntimeContext和setRuntimeContext等虚函数方法,重写这些方法可以创建状态数据、对数据进行广播,获取累加器和计数器等,这部分内容将在后面介绍。
filter
filter算子对每个元素进行过滤,过滤的过程使用一个filter函数进行逻辑判断。对于输入的每个元素,如果filter函数返回True,则保留,如果返回False,则丢弃。
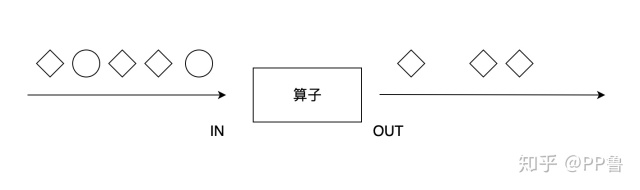
我们可以使用Lambda表达式过滤掉小于等于0的元素:
val dataStream: DataStream[Int] = senv.fromElements(1, 2, -3, , 5, -9, 8)
// 使用 => 构造Lambda表达式
val lambda = dataStream.filter ( input => input > )
// 使用 _ 构造Lambda表达式
val lambda2 = dataStream.map { _ > }也可以继承FilterFunction或RichFilterFunction,然后重写filter方法,我们还可以将参数传递给继承后的类。比如,MyFilterFunction增加一个构造函数参数limit,并在filter方法中使用这个参数。
// 继承RichFilterFunction
// limit参数可以从外部传入
class MyFilterFunction(limit: Int) extends RichFilterFunction[Int] {
override def filter(input: Int): Boolean = {
if (input > limit) {
true
} else {
false
}
}
}
val richFunctionDataStream = dataStream.filter(new MyFilterFunction(2))flatMap
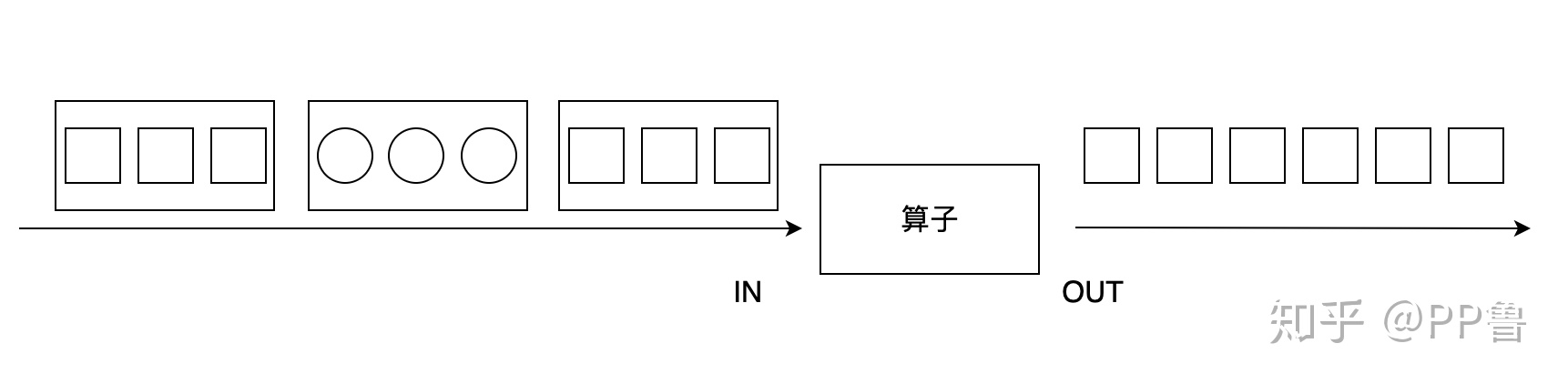
flatMap算子和map有些相似,输入都是数据流中的每个元素,与之不同的是,flatMap的输出可以是零个、一个或多个元素,当输出元素是一个列表时,flatMap会将列表展平。如下图所示,输入是包含圆形或正方形的列表,flatMap过滤掉圆形,正方形列表被展平,以单个元素的形式输出。
val dataStream: DataStream[String] = senv.fromElements("Hello World", "Hello this is Flink")
// split函数的输入为 "Hello World" 输出为 "Hello" 和 "World" 组成的列表 ["Hello", "World"]
// flatMap将列表中每个元素提取出来
// 后输出为 ["Hello", "World", "Hello", "this", "is", "Flink"]
val words = dataStream.flatMap ( input => input.split(" ") )
val words2 = dataStream.map { _.split(" ") }因为flatMap可以输出零到多个元素,我们可以将其看做是map和filter更一般的形式。
// 只对字符串数量大于15的句子进行处理
val longSentenceWords = dataStream.flatMap {
input => {
if (input.size > 15) {
input.split(" ")
} else {
Seq.empty
}
}
}如果我们只想对长句子进行处理,则可以在flatMap中使用判断语句,对于不需要的部分,我们直接返回空结果Seq.empty。
注意,虽然flatMap可以完全替代map和filter,但Flink仍然保留了这三个API,主要因为map和filter的语义更明确,更明确的语义有助于提高代码的可读性。map可以表示一对一的转换,代码阅读者能够确认对于一个输入,肯定能得到一个输出;filter则明确表示发生了过滤操作。
