❝本文转自赵亚楠的博客,原文:http://arthurchiao.art/blog/k8s-cgroup-zh/,版权归原作者所有。
引言
对于一个编排系统来说,资源管理至少需要考虑以下几个方面:
资源模型的抽象;包括,
有哪些种类的资源,例如,CPU、内存等; 如何用数据结构表示这些资源;
如何描述一个 workload 的资源申请(spec),例如,“该容器需要 4 核和 12GB~16GB 内存”; 如何描述一台 node 当前的资源分配状态,例如已分配/未分配资源量,是否支持超分等; 调度算法:如何根据 workload spec 为它挑选合适的 node;
如何确保 workload 使用的资源量不超出预设范围(从而不会影响其他 workload); 如何确保 workload 和系统/基础服务的限额,使二者互不影响。
k8s 是目前流行的容器编排系统,那它是如何解决这些问题的呢?
k8s 资源模型
对照上面几个问题,我们来看下 k8s 是怎么设计的:
资源模型: 抽象了 cpu/memory/device/hugepage 等资源类型; 抽象了 node 概念; 资源调度: 抽象了 request和limit两个概念,分别表示一个容器所需要的小(request)和大(limit)资源量;调度算法根据各 node 当前可供分配的资源量( Allocatable),为容器选择合适的 node; 注意,k8s 的调度只看 requests,不看 limits。资源 enforcement: 使用 cgroup 在多个层面确保 workload 使用的大资源量不超过指定的 limits。
一个资源申请(容器)的例子:
apiVersion: v1
kind: Pod
spec:
containers:
- name: busybox
image: busybox
resources:
limits:
cpu: 500m
memory: "400Mi"
requests:
cpu: 250m
memory: "300Mi"
command: ["md5sum"]
args: ["/dev/urandom"]
这里面 requests 和 limits 分别表示所需资源的小和大值,
CPU 资源的单位 m是millicores的缩写,表示千分之一核, 因此cpu: 500m就表示需要0.5核;内存的单位很好理解,就是 MB、GB 等常见单位。
Node 资源抽象
$ k describe node <node>
...
Capacity:
cpu: 48
mem-hard-eviction-threshold: 500Mi
mem-soft-eviction-threshold: 1536Mi
memory: 263192560Ki
pods: 256
Allocatable:
cpu: 46
memory: 258486256Ki
pods: 256
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 800m (1%) 7200m (15%)
memory 1000Mi (0%) 7324Mi (2%)
hugepages-1Gi 0 (0%) 0 (0%)
...
分别来看下这几个部分。
Capacity
这台 node 的总资源量(可以简单理解为物理配置), 例如上面的输出显示,这台 node 有 48CPU、256GB 内存等等。
Allocatable
可供 k8s 分配的总资源量, 显然,Allocatable 不会超过 Capacity,例如上面看到 CPU 就少了 2 个,只剩下 46 个。
Allocated
这台 node 目前已经分配出去的资源量,注意其中的 message 也说了,node 可能会超分,所以加起来可能会超过 Allocatable,但不会超过 Capacity。
Allocatable 不超过 Capacity,这个概念上也是很好理解的; 但具体是哪些资源被划出去,导致 Allocatable < Capacity 呢?
Node 资源切分(预留)
由于每台 node 上会运行 kubelet/docker/containerd 等 k8s 相关基础服务, 以及 systemd/journald 等操作系统本身的进程,因此并不是一台 node 的所有资源都能给 k8s 创建 pod 用。 所以,k8s 在资源管理和调度时,需要把这些基础服务的资源使用量和 enforcement 单独拎出来。
为此,k8s 提出了 Node Allocatable Resources[1] 提案,上面的 Capacity、Allocatable 等术语正是从这里来的。几点说明:
如果 Allocatable 可用,调度器会用 Allocatable,否则会用 Capacity; 用 Allocatable 是不超分,用 Capacity 是超分(overcommit);
计算公式:[Allocatable] = [NodeCapacity] - [KubeReserved] - [SystemReserved] - [HardEvictionThreshold]
分别来看下这几种类型。
SystemReserved
操作系统的基础服务,例如 systemd、journald 等,在 k8s 管理之外。 k8s 不能管理这些资源的分配,但是能管理这些资源的限额(enforcement),后面会看到。
KubeReserved
k8s 基础设施服务,包括 kubelet/docker/containerd 等等。 跟上面系统服务类似,k8s 不能管理这些资源的分配,但是能管理这些资源的限额(enforcement),后面会看到。
EvictionThreshold(驱逐门限)
当 node memory/disk 等资源即将耗尽时,kubelet 就开始按照 QoS 优先级(besteffort/burstable/guaranteed)驱逐 pod, eviction 资源就是为这个目的预留的。 更多信息[2]。
Allocatable
可供 k8s 创建 pod 使用的资源。
以上就是 k8s 的基本资源模型。下面再看几个相关的配置参数。
kubelet 相关配置参数
资源预留(切分)相关的 kubelet 命令参数:
--system-reserved=""--kube-reserved=""--qos-reserved=""--reserved-cpus=""
也可以通过 kubelet 配置文件,例如,
$ cat /etc/kubernetes/kubelet/config
...
systemReserved:
cpu: "2" ## 这就是为什么上面 describe node 输出中, Allocatable 比 Capacity 少 2 个 CPU 的原因,
memory: "4Gi" ## 以及少 4GB 内存
是否需要对这些 reserved 资源用专门的 cgroup 来做资源限额,以确保彼此互不影响:
--kube-reserved-cgroup=""--system-reserved-cgroup=""
默认都是不启用。实际上也很难做到完全隔离。导致的后果就是系统进程和 pod 进程有可能相互影响, 例如,截至 v1.26,k8s 还不支持 IO 隔离,所以宿主机进程(例如 logrotate)IO 飙高, 或者某个 pod 进程执行 java dump 时,会影响这台 node 上所有 pod。
关于 k8s 资源模型就先介绍到这里,接下来进入本文重点,k8s 是如何用 cgroup 来限制 container、pod、基础服务等 workload 的资源使用量的(enforcement)。
k8s cgroup 层次设计
cgroup 基础
cgroup 是 Linux 内核基础设施,可以限制、记录和隔离进程组(process groups) 使用的资源量(CPU、内存、IO 等)。
cgroup 有两个版本,v1 和 v2,二者的区别可参考 Control Group v2 (cgroupv2 权威指南)(KernelDoc, 2021)[3]。 目前 k8s 默认使用的是 cgroup v1,因此本文以 v1 为主。
cgroup v1 能管理很多种类的资源,
$ mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/net_cls type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls)
k8s/kubelet 中只用到了 cpu/memory/pid/hugetlb 等几种类型。
kubelet cgroup runtime driver
k8s 通过配置 cgroup 来限制 container/pod 能使用的大资源量。这个配置有两种实现方式, 在 k8s 中称为 cgroup runtime driver:
cgroupfs
这种比较简单直接,kubelet 往 cgroup 文件系统中写 limit 就行了。 这也是目前 k8s 的默认方式。
systemd
所有 cgroup-writing 操作都必须通过 systemd 的接口,不能手动修改 cgroup 文件。 适用于 k8s cgroup v2 模式。
kubelet cgroup 层级
如下图所示,

kubelet 会在 node 上创建了 4 个 cgroup 层级,从 node 的 root cgroup (一般都是 /sys/fs/cgroup)往下:
Node 级别:针对 SystemReserved、KubeReserved 和 k8s pods 分别创建的三个 cgroup; QoS 级别:在 kubepodscgroup 里面,又针对三种 pod QoS 分别创建一个 sub-cgroup:Pod 级别:每个 pod 创建一个 cgroup,用来限制这个 pod 使用的总资源量; Container 级别:在 pod cgroup 内部,限制单个 container 的资源使用量。
为了使理解方便,接下来我们从底层往上层讲起。
Container 级别 cgroup
前面已经看到过,在创建 pod 使,可以直接在 container 级别设置 requests/limits:
apiVersion: v1
kind: Pod
spec:
containers:
- name: busybox
image: busybox
resources:
limits:
cpu: 500m
memory: "400Mi"
requests:
cpu: 250m
memory: "300Mi"
command: ["md5sum"]
args: ["/dev/urandom"]
kubelet 在这里做的事情很简单:创建 container 时,将 spec 中指定 requests/limits 传给 docker/containerd 等 container runtime。换句话说,底层能力都是 container runtime 提供的,k8s 只是通过接口把 requests/limits 传给了底层。
具体实现见 generateContainerConfig()[4]: 生成一个 ContainerConfig,然后通过 CRI 传给 container runtime。
Pod 级别 cgroup
顾名思义,这种级别的 cgroup 是针对单个 pod 设置资源限额的。 这里有一个很明显但又很容易被忽视的问题:k8s requets/limits 模型的 requests/limits 是声明在 container 上,而不是 pod 上。 一个 pod 经常有多个容器,那 pod 的 requests/limits 就是对它的 containers 简单累加得到吗?
并不是。这是因为,
某些资源是这个 pod 的所有 container 共享的; 每个 pod 也有自己的一些开销,例如 sandbox container; Pod 级别还有一些内存等额外开销;
因此,为了防止一个 pod 的多个容器使用资源超标,k8s 引入了 引入了 pod-level cgroup,每个 pod 都有自己的 cgroup。 后面会介绍如何根据 containers requests/limits 计算一个 pod 的 requests/limits。
QoS 级别 cgroup
实际的业务场景需要我们能根据优先级高低区分几种 pod。例如,
高优先级 pod:无论何时,都应该首先保证这种 pod 的资源使用量; 低优先级 pod:资源充足时允许运行,资源紧张时优先把这种 pod 赶走,释放出的资源分给中高优先级 pod; 中优先级 pod:介于高低优先级之间,看实际的业务场景和需求。
k8s 针对这种需求提供了 cgroups-per-qos 选项:
// pkg/kubelet/apis/config/*.go
// Enable QoS based Cgroup hierarchy: top level cgroups for QoS Classes
// And all Burstable and BestEffort pods are brought up under their specific top level QoS cgroup.
CgroupsPerQOS bool
如果设置了 kubelet --cgroups-per-qos=true 参数(默认为 true), 就会将所有 pod 分成三种 QoS,优先级从高到低:Guaranteed > Burstable > BestEffort。 三种 QoS 是根据 requests/limits 的大小关系来定义的:
Guaranteed: requests == limits, requests != 0, 即 正常需求 == 大需求,换言之 spec 要求的资源量必须得到保证,少一点都不行;Burstable: requests < limits, requests != 0, 即 正常需求 < 大需求,资源使用量可以有一定弹性空间;BestEffort: request == limits == 0, 创建 pod 时不指定 requests/limits 就等同于设置为 0,kubelet 对这种 pod 将尽力而为;有好处也有坏处:
好处:node 的资源充足时,这种 pod 能使用的资源量没有限制; 坏处:这种 pod 的 QoS 优先级低,当 node 资源不足时,先被驱逐。
每个 QoS 对应一个子 cgroup,设置该 QoS 类型的所有 pods 的总资源限额, 三个 cgroup 共同构成了 kubepods cgroup。 每个 QoS cgroup 可以认为是一个资源池,每个池子内的 pod 共享资源。
Node 级别 cgroup
所有的 k8s pod 都会落入 kubepods cgroup; 因此所有 k8s pods 占用的资源都已经能够通过 cgroup 来控制,剩下的就是那些 k8s 组件自身和操作系统基础服务所占用的资源了,即 KubeReserved 和 SystemReserved。 k8s 无法管理这两种服务的资源分配,但能管理它们的限额:有足够权限给它们创建并设置 cgroup 就行了。 但是否会这样做需要看 kubelet 配置,
--kube-reserved-cgroup=""--system-reserved-cgroup=""
默认为空,表示不创建,也就是系统组件和 pod 之间并没有严格隔离。 但概念上二者始终是存在的,因此前面几节介绍的内容构成了 k8s cgroup 的四个层级:
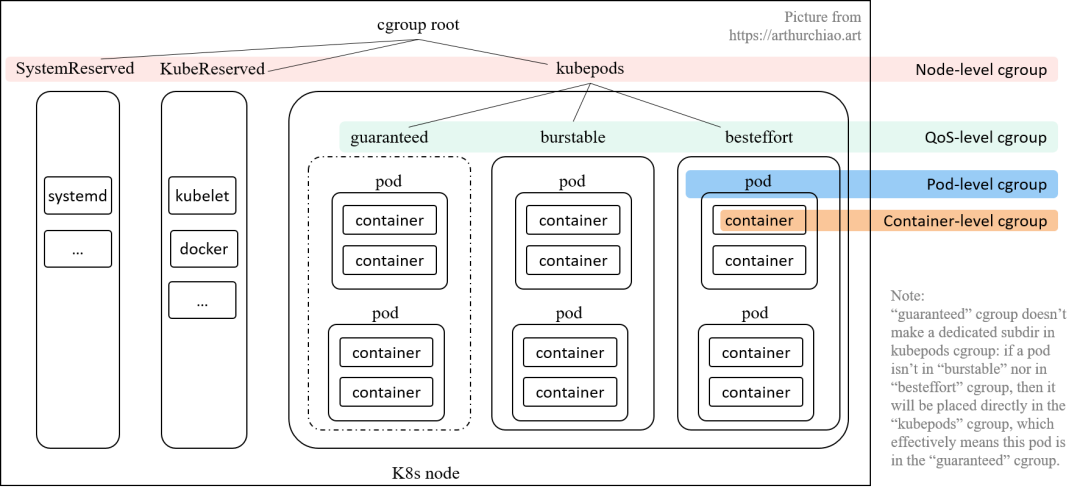
cgroup (v1) 配置目录
接下来看不同 cgroup 分别对应到 node 上哪些目录。
kubelet cgroup root
k8s 的 cgroup 路径都是相对于它的 cgroup root 而言的。 cgroup root 是个 kubelet 配置项,默认为空,表示使用底层 container runtime 的 cgroup root,一般是 /sys/fs/cgroup/。
/kubepods(node 级别配置)
cgroup v1 是按 resource controller 类型来组织目录的, 因此,/kubepods 会按 resource controller 对应到 /sys/fs/cgroup/{resource controller}/kubepods/,例如:
/sys/fs/cgroup/cpu/kubepods//sys/fs/cgroup/memory/kubepods/
前面已经介绍了每台 k8s node 的资源切分, 其中 Allocatable 资源量就是写到 kubepods 对应 cgroup 文件中, 例如 allocatable cpu 写到 /sys/fs/cgroup/kubepods/cpu.share。 这一工作是在 kubelet containerManager Start()[5] 中完成的。
QoS 级别配置
QoS cgroup 是 /kubepods 的 sub-cgroup,因此路径是 /kubepods/{qos}/,具体来说,
Burstable: 默认 /sys/fs/cgroup/{controller}/kubepods/burstable/; BestEffort: 默认 /sys/fs/cgroup/{controller}/kubepods/besteffort/; Guaranteed:这个比较特殊,直接就是 /sys/fs/cgroup/{controller}/kubepods/, 没有单独的子目录。这是因为这种类型的 pod 都设置了 limits, 就无需再引入一层 wrapper 来防止这种类型的 pods 的资源使用总量超出限额。
Pod 级别配置
Pod 配置在 QoS cgroup 配置的下一级,
Guaranteed Pod:默认 /sys/fs/cgroup/{controller}/kubepods/{pod_id}/; Burstable Pod:默认 /sys/fs/cgroup/{controller}/kubepods/burstable/{pod_id}/; BestEffort Pod:默认 /sys/fs/cgroup/{controller}/kubepods/besteffort/{pod_id}/。
Container 级别配置
Container 级别配置文件在 pod 的下一级:
Guaranteed container:默认 /sys/fs/cgroup/{controller}/kubepods/{pod_id}/{container_id}/; Burstable container:默认 /sys/fs/cgroup/{controller}/kubepods/burstable/{pod_id}/{container_id}/; BestEffort container:默认 /sys/fs/cgroup/{controller}/kubepods/besteffort/{pod_id}/{container_id}/。
问题讨论
requests/limits 对应到具体 cgroup 配置文件
CPU
Spec 里的 CPU requests/limits 一般都是以 500m 这样的格式表示的,其中 m 是千分之一个 CPU, kubelet 会将它们转换成 cgroup 支持的单位,然后写入几个 cpu. 开头的配置文件。其中,
requests 经过转换之后会写入 cpu.share, 表示这个 cgroup 少可以使用的 CPU; limits 经过转换之后会写入 cpu.cfs_quota_us, 表示这个 cgroup 多可以使用的 CPU;
Memory
内存的单位在 requests/limits 和在 cgroup 配置文件中都是一样的,所以直接写入 cgroup 内存配置文件。 limits 写入的是 memory.limit_in_bytes。
其他
略。
requests/limits 与调度的关系
requests 和 limits 分别和 k8s 里的一个重要概念相关,下面分别讨论一下。
根据 requests 调度
调度只看 requests: 如果一个 node 的 Allocatable 剩余资源大于 pod 的 requests ,就允许这个 pod 调度到这台 node 上。 limits 是限额(enforcement)用的,确保资源不会用超,在调度时用不到。
requests/limits 都是可选字段,设置与否,会导致这个 pod 进入不同的 QoS 类别; 虽然资源是在 container 级别设置的,但 QoS 是 pod 级别的。
根据 limits 限额(enforcement)
资源的隔离目前是用 cgroup 来实现的,它有两个版本,目前 k8s 默认用的 v1,本文内容也以 v1 为主。
kubelet 计算 pod requets/limits 的过程
前面已经介绍过,k8s spec 里的 requests/limits 是打在 container 上的,并没有打在 pod 上。 因此 pod 的 requests/limits 需要由 kubelet 综合统计 pod 的所有 container 的 request/limits 计算得到。 CPU 和内存的计算方式如下:
## 计算 pod 的 CPU request,通过 cpu.shares 能实现小值控制
pod<pod_id>/cpu.shares = sum(pod.spec.containers.resources.requests[cpu])
## 计算 pod 的 CPU limit,通过 cpu.cfs_quota_us 能实现大值控制
pod<pod_id>/cpu.cfs_quota_us = sum(pod.spec.containers.resources.limits[cpu])
## 计算 pod 的 Memory limit
pod<pod_id>/memory.limit_in_bytes = sum(pod.spec.containers.resources.limits[memory])
注意,
如果其中某个 container 的 cpu 字段只设置了 request 没设置 limit, 则 pod 将只设置
cpu.shares,不设置cpu.cfs_quota_us。如果所有 container 都没有设置 cpu request/limit(等效于
requests==limits==0), 则将 pod cpu.share 将设置为 k8s 定义的小值 2。pod<UID>/cpu.shares = MinShares ## const value 2这种 pod 在 node 空闲时多能使用整个 node 的资源;但 node 资源紧张时,也先被驱逐。
具体的计算过程:ResourceConfigForPod()[6]。
资源使用量超出 limits 的后果
CPU:
Container CPU 使用量可能允许超过 limit,也可能不允许; Container CPU 使用量超过 limit 之后,并不会被干掉。
Memory:
如果 container 的内存使用量超过 request,那这个 node 内存不足时, 这个 Pod 可能会被驱逐; Container 的内存使用量超过 limit 时,可能会被干掉(OOMKilled)。如果可重启,kubelet 会重启它。
Node 资源紧张时,按 QoS 分配资源比例
Kubelet 寻求大资源效率,因此默认没有设置资源限制, Burstable and BestEffort pods 可以使用足够的的空闲资源。 但只要 Guaranteed pods 需要资源,这些低优先级的 pods 就必须及时释放资源。 如何释放呢?
对于 CPU 等 compressible resources,可以通过 CPU CFS shares,针对每个 QoS 分配一定比例的资源,确保在 CPU 资源受限时,每个 pod 能获得它所申请的 CPU 资源。
对于 burstable cgroup,
/burstable/cpu.shares = max(sum(Burstable pods cpu requests), MinShares) ## MinShares == 2
burstableLimit := allocatable — qosMemoryRequests[PodQOSGuaranteed]*percentReserve/100
/burstable/memory.limit_in_bytes = burstableLimit
对于 bestEffort cgroup,
/besteffort/cpu.shares = MinShares ## MinShares == 2
bestEffortLimit := burstableLimit — qosMemoryRequests[PodQOSBurstable]*percentReserve/100
/besteffort/memory.limit_in_bytes = bestEffortLimit
这几个 cgroup 初始化之后[7], kubelet 会调用 UpdateCgroups()[8] 方法来定期更新这三个 cgroup 的 resource limit。
k8s cgroup 相关代码实现
调用栈和重要结构体
kubelet 中所有 cgroup 操作都由内部的 containerManager 模块完成。
实现主要在 pkg/kubelet/cm[9]。
启动时的调用栈:cmd->kubelet->NewContainerManger,
containerManagerImpl.Start
|-cm.cpuManager.Start
|-cm.memoryManager.Start
|
|-cmd.setupNode(activePods)
| |-validateSystemRequirements(cm.mountUtil)
| | |-expectedCgroups := sets.NewString("cpu", "cpuacct", "cpuset", "memory")
| |-cm.createNodeAllocatableCgroups()
| |-cm.qosContainerManager.Start(cm.GetNodeAllocatableAbsolute, activePods)
| |-cm.enforceNodeAllocatableCgroups()
| |-cm.manage system containers (not managed by kubelet) if needed
| |-cm.periodicTasks = append(cm.periodicTasks, func() { // manage kubelet itself if it's deploed as a container
| | ensureProcessInContainerWithOOMScore
| | cont := getContainer(os.Getpid()) // return the cgroup id field in "cat /proc/<pid>/cgroup" output
| | cm.KubeletCgroupsName = cont // this container's cgroup id
| |})
|
|-cm.deviceManager.Start
重要内部结构体 struct containerManagerImpl,
// https://github.com/kubernetes/kubernetes/blob/v1.26.0/pkg/kubelet/cm/container_manager_linux.go#L100
type containerManagerImpl struct {
cadvisorInterface cadvisor.Interface
systemContainers []*systemContainer // External containers being managed.
periodicTasks []func() // Tasks that are run periodically
subsystems *CgroupSubsystems // Holds all the mounted cgroup subsystems
cgroupManager CgroupManager // Interface for cgroup management
capacity v1.ResourceList // Capacity of this node.
internalCapacity v1.ResourceList // Capacity of this node, including internal resources.
cgroupRoot CgroupName // Absolute cgroupfs path, e.g. /sys/fs/cgroup
qosContainerManager QOSContainerManager // Interface for QoS cgroup management
deviceManager devicemanager.Manager // Interface for exporting and allocating devices reported by device plugins.
cpuManager cpumanager.Manager // Interface for CPU affinity management.
memoryManager memorymanager.Manager // Interface for memory affinity management.
topologyManager topologymanager.Manager // Interface for Topology resource co-ordination
draManager dra.Manager // Interface for Dynamic Resource Allocation management.
}
以上可以看出,k8s 1.26.0 实现了对下列资源的支持,
QoS Device CPU Memory
但是还没有实现对 IO 的支持,所以我们还无法通过 k8s cgroup v1/v2 来做 IO 的隔离。
containerManagerImpl.Start()
func (cm *containerManagerImpl) Start(node *v1.Node, activePods ActivePodsFunc,
sourcesReady config.SourcesReady, podStatusProvider status.PodStatusProvider,
runtimeService internalapi.RuntimeService, localStorageCapacityIsolation bool) error {
// Initialize CPU manager
cm.cpuManager.Start(cpumanager.ActivePodsFunc(activePods), sourcesReady, podStatusProvider, runtimeService, containerMap)
// Initialize memory manager
containerMap := buildContainerMapFromRuntime(ctx, runtimeService)
cm.memoryManager.Start(memorymanager.ActivePodsFunc(activePods), sourcesReady, podStatusProvider, runtimeService, containerMap)
cm.nodeInfo = node
if localStorageCapacityIsolation {
rootfs := cm.cadvisorInterface.RootFsInfo()
for rName, rCap := range cadvisor.EphemeralStorageCapacityFromFsInfo(rootfs) {
cm.capacity[rName] = rCap
}
}
cm.validateNodeAllocatable() // Ensure that node allocatable configuration (system/kube/eviction reserved) is valid.
cm.setupNode(activePods) // Setup the node
if hasEnsureStateFuncs { // Run ensure state functions every minute.
go wait.Until(func() {
for _, cont := range cm.systemContainers {
cont.ensureStateFunc(cont.manager)
}
}, time.Minute, wait.NeverStop)
}
go wait.Until(func() {
for _, task := range cm.periodicTasks { task() }
}, 5*time.Minute, wait.NeverStop)
cm.deviceManager.Start(devicemanager.ActivePodsFunc(activePods), sourcesReady)
}
func (cm *containerManagerImpl) setupNode(activePods ActivePodsFunc) error {
validateSystemRequirements(cm.mountUtil)
// Setup top level qos containers only if CgroupsPerQOS flag is true
if cm.NodeConfig.CgroupsPerQOS {
cm.createNodeAllocatableCgroups()
cm.qosContainerManager.Start(cm.GetNodeAllocatableAbsolute, activePods)
}
// Enforce Node Allocatable (if required)
cm.enforceNodeAllocatableCgroups()
systemContainers := []*systemContainer{} // containers not managed by kubelet
if cm.SystemCgroupsName != "" {
cont := newSystemCgroups(cm.SystemCgroupsName)
cont.ensureStateFunc = func(manager cgroups.Manager) error {
return ensureSystemCgroups("/", manager)
}
systemContainers = append(systemContainers, cont)
}
if cm.KubeletCgroupsName != "" {
cont := newSystemCgroups(cm.KubeletCgroupsName)
cont.ensureStateFunc = func(_ cgroups.Manager) error {
return ensureProcessInContainerWithOOMScore()
}
systemContainers = append(systemContainers, cont)
} else {
cm.periodicTasks = append(cm.periodicTasks, func() {
ensureProcessInContainerWithOOMScore(os.Getpid(), cm.KubeletOOMScoreAdj)
cont := getContainer(os.Getpid()) // return the cgroup id field in "cat /proc/<pid>/cgroup" output
cm.KubeletCgroupsName = cont // this container's cgroup id
})
}
cm.systemContainers = systemContainers
}
检查几种必须要支持的 cgroup 资源类型
启动时会检查几种必须要支持的 cgroup 类型:
// https://github.com/kubernetes/kubernetes/blob/v1.26.0/pkg/kubelet/cm/container_manager_linux.go#L161
// checks if the required cgroups subsystems are mounted.
// As of now, only 'cpu' and 'memory' are required.
// cpu quota is a soft requirement.
func validateSystemRequirements(mountUtil mount.Interface) (features, error) {
...
expectedCgroups := sets.NewString("cpu", "cpuacct", "cpuset", "memory")
}
kubelet 启动配置
cgroup 相关的几个参数,可以通过命令行或者 kubelet config 文件配置:
查看配置文件:
root@node: $ grep -i cgroup /etc/kubernetes/config
kubeletCgroups: ""
systemCgroups: ""
cgroupRoot: "" ## if empty, default to "/" in the code
cgroupsPerQOS: true
cgroupDriver: cgroupfs
通过 k8s metrics API 查看 requests/limits 信息
$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/default/pods/smoke-pod-01" | jq -C .
{
"kind": "PodMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "smoke-pod-01",
"selfLink": "/apis/metrics.k8s.io/v1beta1/namespaces/default/pods/smoke-pod-01",
},
"containers": [
{
"name": "netperf",
"usage": {
"cpu": "0",
"memory": "1808Ki"
}
}
]
}
定期获取 pod CpuLoad 信息
kubelet INFO 日志中会定期打印类似下面的信息:
Task stats for "/sys/fs/cgroup/cpu,cpuacct/kubepods/pod<pod_id>/<container_id>": {NrSleeping:1 NrRunning:0 NrStopped: NrUninterruptible: NrIoWait:0}
代码:
// vendor/github.com/google/cadvisor/utils/cpuload/netlink/reader.go
// Returns instantaneous number of running tasks in a group.
// * Caller can use historical data to calculate cpu load.
// * path is an absolute filesystem path for a container under the CPU cgroup hierarchy.
// NOTE: non-hierarchical load is returned. It does not include load for subcontainers.
func (r *NetlinkReader) GetCpuLoad(name string, path string) (info.LoadStats, error) {
cfd := os.Open(path)
defer cfd.Close()
stats := getLoadStats(r.familyID, cfd, r.conn)
klog.V(4).Infof("Task stats for %q: %+v", path, stats)
return stats, nil
}
通过 container pid 查看 cgroup 信息
$ cat /proc/1606/cgroup
11:net_cls: /kubepods/besteffort/pod<pod_id>/<ctn_id>
10:cpu,cpuacct:/kubepods/besteffort/pod<pod_id>/<ctn_id>
9:memory: /kubepods/besteffort/pod<pod_id>/<ctn_id>
8:blkio: /kubepods/besteffort/pod<pod_id>/<ctn_id>
7:devices: /kubepods/besteffort/pod<pod_id>/<ctn_id>
6:hugetlb: /kubepods/besteffort/pod<pod_id>/<ctn_id>
5:pids: /kubepods/besteffort/pod<pod_id>/<ctn_id>
4:freezer: /kubepods/besteffort/pod<pod_id>/<ctn_id>
3:cpuset: /kubepods/besteffort/pod<pod_id>/<ctn_id>
2:perf_event: /kubepods/besteffort/pod<pod_id>/<ctn_id>
1:name=systemd:/kubepods/besteffort/pod<pod_id>/<ctn_id>
::/
$ cat /sys/fs/cgroup/memory/kubepods/burstable/pod<pod_id>/memory.limit_in_bytes
1073741824
参考资料
Layer-by-Layer Cgroup in Kubernetes[10], blog, 2021 https://gist.github.com/mcastelino kcgroups.md[11], blog, 2022 Node Allocatable Resources[12], k8s proposal, 2018 Control Group v2 (cgroupv2 权威指南)(KernelDoc, 2021)[13] 源码解析:K8s 创建 pod 时,背后发生了什么(一)(2021)[14]
引用链接
Node Allocatable Resources: https://github.com/kubernetes/design-proposals-archive/blob/main/node/node-allocatable.md
[2]更多信息: https://github.com/kubernetes/design-proposals-archive/blob/main/node/kubelet-eviction.md#enforce-node-allocatable
[3]Control Group v2 (cgroupv2 权威指南)(KernelDoc, 2021): http://arthurchiao.art/blog/cgroupv2-zh/
[4]generateContainerConfig(): https://github.com/kubernetes/kubernetes/blob/v1.26.0/pkg/kubelet/kuberuntime/kuberuntime_container.go#L297
[5]Start(): https://github.com/kubernetes/kubernetes/blob/v1.26.0/pkg/kubelet/cm/container_manager_linux.go#L564
[6]ResourceConfigForPod(): https://github.com/kubernetes/kubernetes/blob/v1.26.0/pkg/kubelet/cm/helpers_linux.go#L119
[7]初始化之后: https://github.com/kubernetes/kubernetes/blob/v1.26.0/pkg/kubelet/cm/qos_container_manager_linux.go#L81
[8]UpdateCgroups(): https://github.com/kubernetes/kubernetes/blob/v1.26.0/pkg/kubelet/cm/qos_container_manager_linux.go#L305
[9]pkg/kubelet/cm: https://github.com/kubernetes/kubernetes/blob/v1.26.0/pkg/kubelet/cm/
[10]Layer-by-Layer Cgroup in Kubernetes: https://medium.com/geekculture/layer-by-layer-cgroup-in-kubernetes-c4e26bda676c
[11]https://gist.github.com/mcastelino kcgroups.md: https://gist.github.com/mcastelino/b8ce9a70b00ee56036dadd70ded53e9f
[12]Node Allocatable Resources: https://github.com/kubernetes/design-proposals-archive/blob/main/node/node-allocatable.md
[13]Control Group v2 (cgroupv2 权威指南)(KernelDoc, 2021): http://arthurchiao.art/blog/cgroupv2-zh/
[14]源码解析:K8s 创建 pod 时,背后发生了什么(一)(2021): http://arthurchiao.art/blog/what-happens-when-k8s-creates-pods-1-zh/


