虽然每位开发人员都掌握了一种甚至多种编程语言,但你是否曾想过自己动手创建一种编程语言?
首先,我们来看看什么是编程语言:
编程语言是用来定义计算机程序的形式语言。它是一种被标准化的交流技巧,用来向计算机发出指令,一种能够让程序员准确地定义计算机所需要使用数据的计算机语言,并地定义在不同情况下所应当采取的行动。
简而言之,编程语言就是一组预定义的规则。然后,我们需要通过编译器、解释器等来解释这些规则。所以我们可以简单地定义一些规则,然后,再使用任何现有的编程语言来制作一个可以理解这些规则的程序,也就是我们所说的解释器。
编译器:编译器能够将代码转换为处理器可以执行的机器代码(例如 C++ 编译器)。
解释器:解释器能够逐行遍历程序并执行每个命令。
下面,我们来试试看创建一个超级简单的编程语言,在控制台中输出洋红色的字体,我们给它起个名字:Magenta(洋红色)。
建立编程语言
在本文中,我将使用 Node.js,但你可以使用任何语言,基本思路依然是一样的。首先,我们来创建一个 index.js 文件。
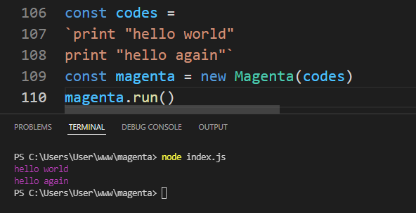
class Magenta { constructor(codes) { this.codes = codes } run() { console.log(this.codes) }} // For now, we are storing codes in a string variable called `codes`// Later, we will read codes from a fileconst codes =`print "hello world"print "hello again"`const magenta = new Magenta(codes)magenta.run()这段代码声明了一个名为 Magenta 的类。该类定义并初始化了一个对象,而该对象负责将我们通过变量 codes 提供的文本显示到控制台。我们在文件中直接定义了变量 codes:几个带有“hello”的消息。
下面,我们来创建词法分析器。
什么是词法分析器?
我们拿英文举个例子:How are you?
此处,“How”是副词,“are”是动词,“you”是代词。后还有一个问号(?)。我们可以按照这种方式,通过JavaScript编程将句子或短语划分为多个语法组件。还有一种方法是,将这些句子或短语分割成一个个标记。将文本分割成标记的程序就是词法分析器。

由于我们的这个编程语言非常小,它只有两种类型的标记,每一种只有一个值:
1. keyword
2. string
我们可以使用正则表达式,从字符串 codes 中提取标记,但性能会非常慢。更好的方法是遍历字符串 codes 中的每个字符并提取标记。下面,我们在 Magenta 类中创建一个方法tokenize(这就是我们的词法分析器)。
完整的代码如下:
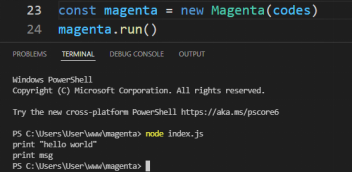
class Magenta { constructor(codes) { this.codes = codes } tokenize() { const length = this.codes.length // pos keeps track of current position/index let pos = let tokens = [] const BUILT_IN_KEYWORDS = ["print"] // allowed characters for variable/keyword const varChars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_' while (pos < length) { let currentChar = this.codes[pos] // if current char is space or newline, continue if (currentChar === " " || currentChar === "\n") { pos++ continue } else if (currentChar === '"') { // if current char is " then we have a string let res = "" pos++ // while next char is not " or \n and we are not at the end of the code while (this.codes[pos] !== '"' && this.codes[pos] !== '\n' && pos < length) { // adding the char to the string res += this.codes[pos] pos++ } // if the loop ended because of the end of the code and we didn't find the closing " if (this.codes[pos] !== '"') { return { error: `Unterminated string` } } pos++ // adding the string to the tokens tokens.push({ type: "string", value: res }) } else if (varChars.includes(currentChar)) { let res = currentChar pos++ // while the next char is a valid variable/keyword charater while (varChars.includes(this.codes[pos]) && pos < length) { // adding the char to the string res += this.codes[pos] pos++ } // if the keyword is not a built in keyword if (!BUILT_IN_KEYWORDS.includes(res)) { return { error: `Unexpected token ${res}` } } // adding the keyword to the tokens tokens.push({ type: "keyword", value: res }) } else { // we have a invalid character in our code return { error: `Unexpected character ${this.codes[pos]}` } } } // returning the tokens return { error: false, tokens } } run() { const { tokens, error } = this.tokenize() if (error) { console.log(error) return } console.log(tokens) }}在终端中运行node index.js,就会看到控制台中输出的标记列表。

定义规则和语法
我们想看看 codes 的顺序是否符合某种规则或语法。但首先我们需要定义这些规则和语法是什么。由于我们的这个编程语言非常小,它只有一种简单的语法,即关键字 print 后跟一个字符串。
keyword:print string
因此,我们来创建一个 parse 方法,循环遍历 codes 并提取标记,看看是否形成了有效的语法,并根据需要采用采取必要的行动。
class Magenta { constructor(codes) { this.codes = codes } tokenize(){ /* previous codes for tokenizer */ } parse(tokens){ const len = tokens.length let pos = while(pos < len) { const token = tokens[pos] // if token is a print keyword if(token.type === "keyword" && token.value === "print") { // if the next token doesn't exist if(!tokens[pos + 1]) { return console.log("Unexpected end of line, expected string") } // check if the next token is a string let isString = tokens[pos + 1].type === "string" // if the next token is not a string if(!isString) { return console.log(`Unexpected token ${tokens[pos + 1].type}, expected string`) } // if we reach this point, we have valid syntax // so we can print the string console.log('\x1b[35m%s\x1b[0m', tokens[pos + 1].value) // we add 2 because we also check the token after print keyword pos += 2 } else{ // if we didn't match any rules return console.log(`Unexpected token ${token.type}`) } } } run(){ const {tokens, error} = this.tokenize() if(error){ console.log(error) return } this.parse(tokens) }}如下所示,我们的编程语言已经能够正常工作了!

由于字符串变量 codes 是硬编码的,因此输出其中包含的字符串意义也不大。因此,我们将codes 放入一个名为 code.m 的文件中。这样,变量 codes(输出数据)与编译器的实现逻辑就互相分离了。我们使用 .m 作为文件扩展名,以此来表明该文件包含 Magenta 语言的代码。
下面,我们来修改代码,从该文件中读取codes:
// importing file system moduleconst fs = require('fs')//importing path module for convenient path joiningconst path = require('path')class Magenta{ constructor(codes){ this.codes = codes } tokenize(){ /* previous codes for tokenizer */ } parse(tokens){ /* previous codes for parse method */ } run(){ /* previous codes for run method */ }} // Reading code.m file// Some text editors use \r\n for new line instead of \n, so we are removing \rconst codes = fs.readFileSync(path.join(__dirname, 'code.m'), 'utf8').toString().replace(/\r/g, "")const magenta = new Magenta(codes)magenta.run()
创建一门编程语言
到这里,我们就成功地从零开始创建了一种微型编程语言。其实,编程语言也可以非常简单。当然,像 Magenta 这样的语言不太可能用于实践,也不足以成为流行框架,但我们可以通过这个例子学习如何创建一门编程语言。
原文地址:https://css-tricks.com/lets-create-a-tiny-programming-language/

