Snowflake的目标是打造一个云上的、企业级的数据仓库解决方案:
- 云上的:业务上云已经从Buzz Word变成了现实的趋势,它帮我们节省了成本,让很小的企业可以用上之前只有大企业才能用上的复杂和昂贵的服务,云上可以提供理论上无限的计算和存储资源。
- 企业级:企业级意味着服务的易用性、可互操作性以及高可用性。
Snowflake的主要的特点是支持多租户、支持事务、高度安全,高度可扩展并且可以按需扩展,对ANSI SQL有着完整的支持,而且对半结构化和无结构的数据有着内置的支持。
促使Snowflake出现的背后的思考在于,随着云概念的深入人心,不只是我们业务运行的平台变了(从on-premise到cloud),数据本身也发生了很大的变化:之前的数据多是来自企业内部CRM/ERP等等,数据的种类、规模、结构都是可预测的,而随着云平台、移动互联网、IoT等浪潮的出现, 数据的量越来越大,越来越呈现半结构化或者无结构的特点,这种形式对于传统的数仓解决方案挑战很大,因为传统的数仓都是在数据量可预测、数据结构可预测的情况下进行部署的,并且依赖一系列复杂的ETL任务对数据进行清洗过滤后数据才能使用,为了适应这种新形势,很多公司开始采用大数据的技术栈,比如Hadoop/Spark之类的,但是自建的这些大数据集群往往性能不高,而且缺乏传统数仓所拥有的丰富特性,更重要的是自建大数据的方案需要大量的专业人员、大量的时间投入。Snowflake就是在这种形式下打造出来的,它的主要特性包括:
- Sofaware-as-a-Service(SaaS), 软件即服务,开箱即用,而且提供的都是标准的接口和规范,比如ODBC。而且使用Snowflake 不需要太多的性能调优,物理结构设计等等。
- 关系型服务: Snowflake提供完整的ANSI SQL支持,并且支持事务。这样用户要从传统的数仓解放迁移过来代价非常低。
- 半结构化支持: Snowflake对JSON, Avro等等半结构化数据提供了内置的支持。而且因为采用了自动的schema发现以及面向列的存储使得对非结构化数据的操作跟普通结构化数据的操作性能损失很小。
- Elastic,支持弹性伸缩,因为Snowflake是计算和存储分离的,因此它支持计算和存储单独扩展。而且扩展的过程用户不会感知到。
- 高可用、持久、经济:
- 安全: Snowflake采用了端到端的数据加密措施,数据在硬盘上、在网络传输过程中都是加密的,使得潜在的攻击者甚至包括云服务商都没办法获取用户的明文数据。
数据到处都是加密的不会对性能造成很大的损失么? 而且有一些算法可以直接对压缩过后的数据上进行查询,那如果数据在磁盘上就加密的,那么这些优化措施是不是都没办法用了? 这一点论文上面没有详细说,但是我个人感觉对性能肯定是有影响的,但是对用户来说安全性可能比性能的优先级更高,毕竟要更好的性能可以买更多的机器,但是安全是妥协不了的。
国内这种企业怕上云的难题是不是可以通过引入类似Snowflake这种安全的机制让客户放心呢?
架构
下面是Snowflake的整体架构图:
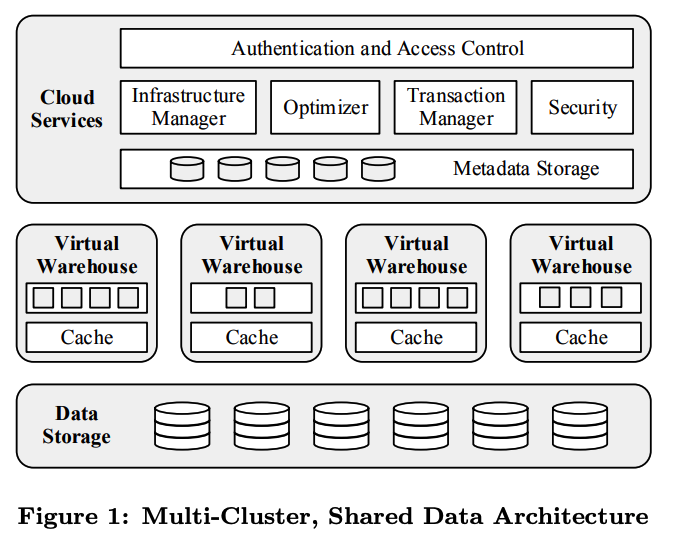
从架构图可以看出,Snowflake架构分三层,从上到依次是“大脑": Cloud Services, ”肌肉“:Virtual Warehouses, 以及底层的数据存储层: Data Storage。
Data Storage
首先作者解释了为什么Snowflake目前是搭建在AWS上的,原因有两个,一是AWS是目前成熟的云服务提供商,二是AWS拥有目前多的潜在客户。而到底是在EC2上自建存储还是直接使用S3服务,论文的作者发现S3实现的非常好,要实现类似的特性很困难,因此Snowflake把更多的时间精力花在了如果做本地文件的缓存以及对于查询倾斜场景的优化上。
保存在S3的数据有两类:一是用户表里面的数据;另外就是计算过程中产生的临时数据,Snowflake计算引擎支持把查询的中间结果保存到S3上,这样使得Snowflake可以支持任意规模的大查询。
而用户的元数据,比如数据库里面有哪些表,表对应到哪些数据文件,文件的统计信息,事务日志等等都是保存在一个可扩展的事务性KV存储里面,而这个是属于上层 Cloud Services那一层的组件。
貌似大家都喜欢把这种大规模的元数据往KV存储里面保存,可能是数据量都太多,普通的RDMBS都搞不定了。
Virtual Warehouses
Snowflake把它的计算层称作Virtual Warehouses(VW), 每个VW由多个AWS的EC2的实例组成,用户从来不直接跟EC2实例直接打交道,Snowflake采用类似T恤衫的那种尺寸(XXS -> XXL)来命名VW的规格,这么一层抽象使得VW规格的变化跟底层EC2规格的变化相独立,蛮聪明的。
一个VW由多个EC2的实例组成,Snowflake的用户往往会有多个不同的VW,不同的VW之间的计算资源是隔离的,从而可以针对不同的使用场景,达到计算资源上的隔离。
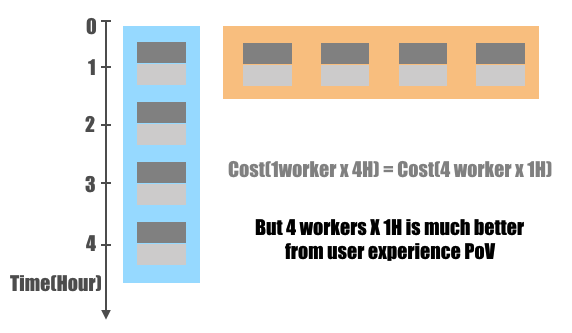
Snowflake是计算时间来计费的,同样的任务用1个节点可能要4个小时,而如果用4个节点可能只需要1个小时。这样对于用户的花销是一样的,但是用户体验就差很多了。因此作者认为Snowflake的这种VW的弹性能力是他们很重要的竞争力。
计算和存储分离之后,把数据从远程S3加载过来的速度还是会比原来直接从本地磁盘读要慢,因此Snowflake给每台Worker节点都配备了高速的SSD硬盘,这个SSD硬盘的作用不是保存原始数据,而是保存被之前Query请求过的热数据,这样保证以有限的空间保存尽可能热的数据。为了提高这种缓存文件的磁盘命中率,Snowflake的查询优化器在调度TableScan的时候会根据表对应的底层文件名以一致性hash的算法把数据加载的请求分到这些worker节点上,从而保证对同样一个文件的请求可以尽量落到同一个worker节点上去,可以提高命中率。
这里每个Worker节点的文件数据缓存的设计我觉得很有意思。从上面大的架构来看Snowflake做了计算和存储的分离,而是如果看到缓存这个细微处,你会发现计算和存储又绑定到一起了,只不过这个绑定是很弱的绑定,而且存储的热数据,不是全量数据。
大数据计算里面经常会出现的一种常见是查询倾斜(skew), snowflake的应对办法是他们称为 File Stealing 的一种做法,这种做法主要针对的 TableScan 的算子,当一个worker读取完分配给它的所有的文件读取任务之后,它会问它的兄弟节点有没有需要帮助的,如果有它会帮兄弟节点去加载数据,从而改善查询倾斜的问题。
在执行引擎方面Snowflake不是在新的关系型数据库或者是Hadoop体系上修改得来的,而是他们基于用户对于大数据场景好的性价比打造出来的,他们对这个执行引擎给的三个关键词是: 列存、向量化执行(加延迟物化)以及Pushed-based执行机制。前两个关键词比较好理解,这里重点说一下Pushed-based执行机制,我们常用的Volcano-style的模型是pull-based的也就是下游主动找上游要数据,而push-based则是反过来,上游主动给下游推数据。pushed-based执行引擎能够提高缓存的效率。
Cloud Services
跟Virtual Warehouses层面每个客户都是资源独占不同的是,Cloud Services层面的资源是所有租户共用的,只是在逻辑层面做了隔离,这也很好理解,这一层面没有特别大的CPU Intensive的计算,所有租户共用可以提高资源利用率。
Snowflake 的查询优化器采用的典型的 Cascade 风格,以及从上往下的Cost-Based Optimization, Snowflake在数据插入、更新、加载的时候自动维护查询优化所需要的所有的元数据。
并发控制、事务完全是在Cloud Services这一层实现的,因为Snowflake服务的是分析类的查询,因此事务是通过 Snapshot Isolation的方式来实现的,所谓的Snapshot Isolation, 指的是一个查询能看的数据是这个查询开始时整个系统的一个快照,跟类似系统一样,Snowflake也是通过MVCC来实现Snapshot Isolation的。
Snowflake系统里面的数据文件都是只读的,当用户对数据进行更新的时候,系统会产生新的文件,把老的文件替换掉,但是每个文件本身是只读的,这样的模式特别适合S3这种存储的工作原理,同时也方便实现MVCC -- 只要让每个查询始终读查询开始时的对应的版本的文件就好了。
在查询剪枝上,Snowflake采用的目前常用的技术:在每个数据文件上保存数据的一些统计数据: min, max之类的,通过对这些元数据进行扫描可以判断是否要扫整个文件,从而可以避免扫描所有的文件。论文同时也论述了一下为什么这种数仓的系统用索引技术不合适:
- 索引依赖对文件随机读,而这是S3这种系统不擅长的。
- 索引会降低查询、加载的效率,数仓数据量都特别的大,降低了加载的效率在需要做数据恢复的时候是很大的问题。
- 索引需要用户手动创建,而这跟Snowflake SaaS的口号,让用户用的爽的目标相背离。
计算和存储分离的架构
这里值得注意的一点是,Snowflake采用了目前非常流行的计算和存储分离的架构,计算层是单独的 Virtual Warehouses, 每个客户的计算层都是单独的,而且这些计算层的机器都是无状态的,并不和底层的数据有任何的映射关系。论文特别花篇幅讨论了一下这种架构的优劣。
在计算和存储分离架构之前占主流的是一种叫做 Shared-Nothing 的架构。Shared-Nothing 指的是对于很大的一个表的数据,系统把它按照某种规则拆分成N份,拆分之后由N个worker来分别处理其中的一个分区,这样的好处是架构比较简单,所有worker上的处理逻辑都是一样的,worker节点之间因为不共享任何数据,查询执行的过程中没有资源的争抢,效率很高,而且拆分之后普通的机器就可以计算很大的查询,不再需要什么特殊的高配机器。
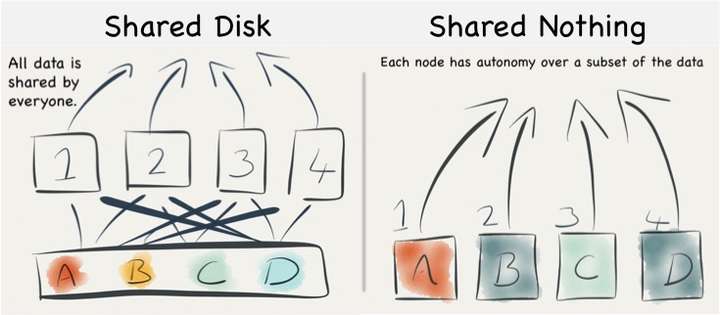
但是与此同时 Shared-Nothing 也有一个很大的缺点: 它把计算资源和存储资源捆绑在了一起,这在下面这些场景下是会有问题的:
- 异构的工作负载:不同的使用场景对于机器配置的要求是不一样的,一个对于数据导入很好的配置(IO intensive)对于复杂的在线查询(CPU-intensive)就不一定适合,而为了支持所有的场景,后机器的配置要取个折中,从而无法达到好的性价比。
- Worker节点上下线:当集群的节点数发生变化(升级,扩缩容等等)的时候,Shared-Nothing 需要对数据重新进行分布,而这个是需要消耗大量的计算资源的,在这期间用户在线查询的性能会受到影响。
- 在线升级:集群的软件版本会有升级的需要。虽然理论上可以一个接着一个地升级,但是工程实现会很复杂。
因此Snowflake采用了计算和存储分离的架构。首先存储层采用S3,我们可以认为这一层可以独立无限扩展的,而计算层因为跟存储层没有关系,可以根据的需要任意进行扩缩容量也是可以自行扩展。而且可以避免上面列出的几个问题: 对于异构工作负载的问题,用户可以为不同的场景分配不同的计算层机器,用完了之后可以释放掉。节点上下线的问题,因为计算层跟存储没有任何关系,在节点线的时候不需要对数据进行任何重新分布的操作,因此比Shared-Nothing要简单;后在线升级,还是因为计算层没有任何状态,升级的时候可以先升级一部分机器,让老版本和新版本共存。
当然计算和存储分离之后,因为数据读取都要经过网络,还是会带来一定的性能损耗,因此Snowflake在计算的机器上做了一些热文件的缓存,而由于缓存的数据都是热的,Snowflake采用了高性能的SSD来做本地磁盘的额存储介质。Snowflake把他们这种架构叫做 Multi-Cluster, Shared-Data Architecture 架构。
计算和存储分离,看起来跟上图里面的Shared-Disk很像,个人理解区别在于Shared-Disk里面存储只是一块Disk,不同的节点会有争抢。而计算和存储分离之后,存储变成了一个服务,它内部会对数据做多副本保存,降低资源争抢的概率,从而可以缓解Shared-Disk架构的一些问题。
总结
Snowflake作为一种比较典型的企业级数仓解决方案,在其中可以看到很多成熟的做法,比如基于文件元数据信息的剪枝策略;计算和存储分离的架构。也有一些很有意思的创新比如计算和存储分离之后,计算又和本地的热数据”绑定“回一起;计算层可以随意弹性扩展等等。这里面的很多策略值得类似的云上数仓服务借鉴。
