Robusta 是一个 Python 开发的用于 Kubernetes 故障排除的开源平台。它位于你的监控堆栈(Prometheus、Elasticsearch 等)之上,并告诉你警报发生的原因以及如何修复它们。
Robusta 包含三个主要部分,全部开源:
用于 Kubernetes 的自动化引擎 内置自动化以丰富和修复常见警报 其他一些手动故障排除工具
还有一些其他额外的可选组件:
包含 Robusta、Prometheus Operator 和默认 Kubernetes 警报的工具包 用于查看集群中所有警报、变更和事件的 Web UI。
Robusta 会自动执行部署应用程序后发生的所有事情。它有点像用于 DevOps 的 Zapier/IFTTT,强调的是预置的自动化,而不仅仅是“构建你自己的”。例如,当 Pod 崩溃的警报触发时,下面的自动化程序也会将日志发送到 Slack:
triggers:
- on_prometheus_alert:
alert_name: KubePodCrashLooping
actions:
- logs_enricher: {}
sinks:
- slack
每个自动化程序都包含3个部分:
Triggers:何时运行(基于警报、日志、变更等) Actions:要做什么操作(超过50个内置操作) Sinks:将结果发送到何处(Slack等)

架构
Robusta 可以通过 Helm 进行安装和管理。
自动化引擎
Robusta 的主要组件是自动化引擎,它作为两个 Kubernetes Deployments 在集群内运行。
robusta-forwarder:连接到 APIServer 并监控 Kubernetes 的变化,将它们转发给 robusta-runner。robusta-runner:执行 playbooks。

打包的 Prometheus 堆栈(可选)
Robusta 包括一个可选的嵌入式 Prometheus 堆栈,根据佳实践预先配置了 Kubernetes 警报。如果已经在使用 kube-prometheus-stack,则可以将其指向 Robusta。
Web UI(可选)
有一个 Web UI,它提供一个单一的管理面板来监控跨多个集群的所有警报和 pod。
CLI(可选)
robusta 的命令行工具有两个主要用途:
通过自动生成 Helm values 使安装 Robusta 变得更容易 手动触发 Robusta 故障排除工作流程(例如从任何 Java pod 获取 heap dump)
它还具有开发 Robusta 本身有用的一些功能。
使用场景
Robusta 默认情况下会监控下面这些报警和错误,并会提供一些修复建议。
Prometheus Alerts
CPUThrottlingHigh - 显示原因和解决方法 HostOomKillDetected - 显示哪些 Pods 被 killed 掉了 KubeNodeNotReady - 显示节点资源和受影响的 Pods HostHighCpuLoad - 显示CPU使用情况分析 KubernetesDaemonsetMisscheduled - 标记已知错误并建议修复 KubernetesDeploymentReplicasMismatch - 显示 deployment 的状态 NodeFilesystemSpaceFillingUp - 显示磁盘使用情况
其他错误
这些是通过监听 APIServer 来识别的:
CrashLoopBackOff ImagePullBackOff Node NotReady
此外,WARNING 级别及以上的所有 Kubernetes 事件(kubectl get events)都会发送到 Robusta UI。
变更追踪
默认情况下,对 Deployments、DaemonSets 和 StatefulSets 的所有变更都会发送到 Robusta UI,以便与 Prometheus 警报和其他错误相关联。默认情况下,这些更改不会发送到其他接收器(例如 Slack),因为它们是垃圾邮件。
安装
要在你的 K8s 集群中配置 Robusta,首先我们需要安装 Robusta,并连接至少一个目的地(“接收器”)和至少一个源(“触发器”)。
为了配置 robusta,我们需要安装 Robusta CLI 工具,直接使用下面的命令即可安装:
# 需要 Python3.7 或以上版本
pip install -U robusta-cli --no-cache
然后就可以生成 Robusta 配置文件,这会配置安装 Slack 或其他集成工具,也非常推荐开启 cloud UI 工具:
robusta gen-config
上面的命令默认情况下会让我们配置 Slack,所以需要提前做好配置,提供一个 channel 用于接收相关信息,后会生成一个名为 generated_values.yaml 的 Helm values 文件,如果在你的 Slack 频道中收到了如下所示的信息则证明配置是正确的:

然后我们就可以使用 Helm 进行安装了,首先添加 Helm Chart Repo:
helm repo add robusta https://robusta-charts.storage.googleapis.com && helm repo update
然后可以使用下面的命令进行安装:
helm install robusta robusta/robusta -f ./generated_values.yaml \
--set clusterName=<YOUR_CLUSTER_NAME>
如果你使用的是 KinD 测试集群,则可以提供一个 isSmallCluster=tru 的参数,这样可以减少相关资源:
helm install robusta robusta/robusta -f ./generated_values.yaml \
--set clusterName=<YOUR_CLUSTER_NAME> \
--set isSmallCluster=true
比如我这里是 KinD 的测试集群,安装完成后会有如下所示的 Pod 列表:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
alertmanager-robusta-kube-prometheus-st-alertmanager-0 2/2 Running 3 (30m ago) 3h25m
prometheus-robusta-kube-prometheus-st-prometheus-0 2/2 Running 2 (34m ago) 4h21m
robusta-forwarder-579fb4b548-7xqq8 1/1 Running 1 (30m ago) 4h23m
robusta-grafana-797c64d5b4-2dbhl 3/3 Running 3 (30m ago) 4h23m
robusta-kube-prometheus-st-operator-7c5db9ccb9-gczlp 1/1 Running 1 (30m ago) 4h23m
robusta-kube-state-metrics-649fd7db9f-6sd8p 1/1 Running 1 (34m ago) 4h23m
robusta-prometheus-node-exporter-5426b 1/1 Running 1 (30m ago) 4h23m
robusta-prometheus-node-exporter-hx6r4 1/1 Running 1 (30m ago) 4h23m
robusta-prometheus-node-exporter-np4jj 1/1 Running 1 (30m ago) 4h23m
robusta-runner-9f4f56c8b-49s7p 1/1 Running 1 (30m ago) 3h48m
如果安装的时候启用了 Robusta 的 UI 功能,则可以在 Web UI 中看到当前集群的相关监控数据。

测试
默认情况下,Robusta 会在 Kubernetes pod 崩溃时发送通知,这里我们创建一个 crashing 的 pod 来进行测试,该测试应用的资源清单如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: crashpod
spec:
selector:
matchLabels:
app: crashpod
template:
metadata:
labels:
app: crashpod
spec:
containers:
- image: busybox
command: ["sh"]
args:
- "-c"
- "wget -O - https://gist.githubusercontent.com/odyssomay/1078370/raw/35c5981f8c139bc9dc02186f187ebee61f5b9eb9/gistfile1.txt 2>/dev/null; exit 125;"
imagePullPolicy: IfNotPresent
name: crashpod
restartPolicy: Always
直接应用该清单即可(或者执行 robusta demo 命令也可以),正常启动后很快该 pod 就会崩溃:
$ kubectl get pods -A
NAME READY STATUS RESTARTS AGE
crashpod-64d8fbfd-s2dvn /1 CrashLoopBackOff 1 7s

而且还可以看到完整的 pod 崩溃日志,这个对于监控报警是非常有意义的。同样如果开启了 Robusta UI,在 Web UI 页面中也可以看到类似的消息。
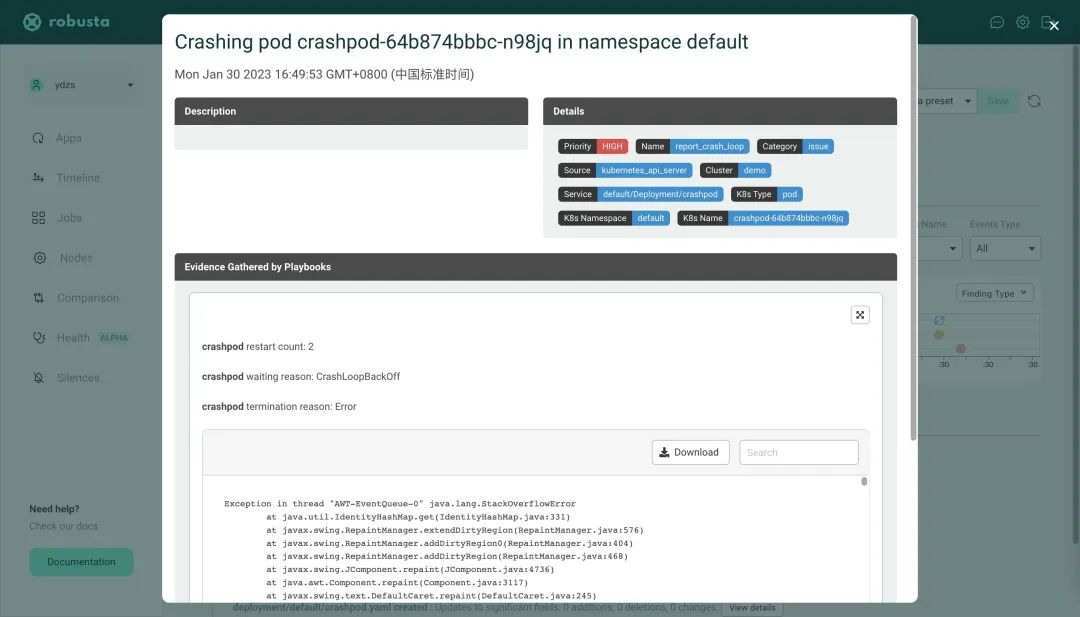
自动化基础
为了演示 Robusta 自动化是如何工作的,我们将配置一个在 Deployment 发生变化时发送 Slack 消息的自动化。
首先添加下面内容到 generated_values.yaml 文件中:
customPlaybooks:
- triggers:
- on_deployment_update: {}
actions:
- resource_babysitter:
omitted_fields: []
fields_to_monitor: ["spec.replicas"]
然后更新 Robusta:
helm upgrade robusta robusta/robusta --values=generated_values.yaml
更新后我们来更改一个 Deployment 的副本数:
kubectl scale --replicas NEW_REPLICAS_COUNT deployments/DEPLOYMENT_NAME
正常然后 Slack 的频道就会收到对应的一条如下所示消息通知了:

如果启用了 Robusta UI,所有的报警和变更也都会出现在 timeline 下面:

我们也可以点击查看变更的内容:

当然我们还可以利用 Robusta 来做很多事情,可以自己来实现 playbook 操作,关于 Robusta 的更多使用可以参考官方文档 https://docs.robusta.dev 了解更多信息。
本文转载自:「k8s技术圈」,原文:https://url.hi-linux.com/BveTx,版权归原作者所有。
