DolphinDB实现了一系列常用的机器学习算法,例如小二乘回归、随机森林、K-平均等,使用户能够方便地完成回归、分类、聚类等任务。这篇教程会通过具体的例子,介绍用DolphinDB脚本语言进行机器学习的流程。本文的所有例子都基于DolphinDB 1.10.9。
1. 第一个例子:对小样本数据进行分类
我们用UCI Machine Learning Repository上的wine数据,用来完成个随机森林分类模型的训练。
1.1 加载数据
将数据下载到本地后,在DolphinDB中用loadText导入:
wineSchema = table(
`Label`Alcohol`MalicAcid`Ash`AlcalinityOfAsh`Magnesium`TotalPhenols`Flavanoids`NonflavanoidPhenols`Proanthocyanins`ColorIntensity`Hue`OD280_OD315`Proline as name,
`INT`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE as type
)
wine = loadText("D:/dataset/wine.data", schema=wineSchema)1.2 数据预处理
DolphinDB的randomForestClassifier函数要求类的标签的取值是[0, classNum)之间的整数。下载得到的wine数据的分类标签为1, 2, 3,需要更新为0, 1, 2:
update wine set Label = Label - 1将数据按7:3分为训练集和测试集。本例编写了一个trainTestSplit函数以便划分。
def trainTestSplit(x, testRatio) {
xSize = x.size()
testSize = xSize * testRatio
r = (0..(xSize-1)).shuffle()
return x[r > testSize], x[r <= testSize]
}
wineTrain, wineTest = trainTestSplit(wine, 0.3)
wineTrain.size() // 124
wineTest.size() // 54
1.3 使用randomForestClassifier进行随机森林分类
对训练集调用randomForestClassifier函数进行随机森林分类。该函数有四个必选参数,分别是:
- ds: 输入的数据源,本例中用
sqlDS函数生成。 - yColName: 数据源中因变量的列名。
- xColNames: 数据源中自变量的列名。
- numClasses: 类的个数。
model = randomForestClassifier(
sqlDS(<select * from wineTrain>),
yColName=`Label,
xColNames=`Alcohol`MalicAcid`Ash`AlcalinityOfAsh`Magnesium`TotalPhenols`Flavanoids`NonflavanoidPhenols`Proanthocyanins`ColorIntensity`Hue`OD280_OD315`Proline,
numClasses=3
)用训练得到的模型,对测试集进行预测:
predicted = model.predict(wineTest)观察预测正确率:
> sum(predicted == wineTest.Label) \ wineTest.size();
0.925926
1.4 模型持久化
用saveModel函数将训练得到的模型保存到磁盘上:
model = loadModel("D:/model/wineModel.bin")
predicted = model.predict(wineTest)用loadModel函数加载磁盘上的模型,并用于预测:
model = loadModel("D:/model/wineModel.bin")
predicted = model.predict(wineTest)2.分布式机器学习
上面的例子只是一个在小数据上的玩具。与常见的机器学习库不同,DolphinDB是为分布式环境而设计的,许多内置的机器学习算法对分布式环境有良好的支持。
本章将介绍如何在DolphinDB分布式数据库上用逻辑回归算法完成分类模型的训练。
现有一个DolphinDB分布式数据库,按股票名分区,存储了各股票在2010年到2018年的每日ohlc数据。
我们将用以下九个变量作为预测的指标:开盘价、高价、低价、收盘价、当天开盘价与前一天收盘价的差、当天开盘价与前一天开盘价的差、10天的移动平均值、相关系数、相对强弱指标(relative strength index, RSI)。
我们将用第二天的收盘价是否大于当天的收盘价作为预测的目标。
2.1 数据预处理
在本例中,原始数据中的空值,可以通过ffill函数填充;对原始数据求10天移动平均值和RSI后,结果的前10行将会是空值,需要去除。我们将用transDS!函数对原始数据应用预处理步骤。本例中,求RSI用到了DolphinDB的ta模块,具体用法参见DolphinDBModules.
use ta
def preprocess(t) {
ohlc = select ffill(Open) as Open, ffill(High) as High, ffill(Low) as Low, ffill(Close) as Close from t
update ohlc set OpenClose = Open - prev(Close), OpenOpen = Open - prev(Open), S_10 = mavg(Close, 10), RSI = ta::rsi(Close, 10), Target = iif(next(Close) > Close, 1, 0)
update ohlc set Corr = mcorr(Close, S_10, 10)
return ohlc[10:]
}加载数据后,通过sqlDS生成数据源,并通过transDS!用预处理函数转化数据源:
ohlc = database("dfs://trades").loadTable("ohlc")
ds = sqlDS(<select * from ohlc>).transDS!(preprocess)
2.2 调用logisticRegression函数训练
函数logisticRegression有三个必选参数:
- ds: 输入的数据源。
- yColName: 数据源中因变量的列名。
- xColNames: 数据源中自变量的列名。
上一节已经生成了输入的数据源,可以直接用作参数。
model = logisticRegression(ds, `Target, `Open`High`Low`Close`OpenClose`OpenOpen`S_10`RSI`Corr)用训练的模型对一支股票的数据进行预测并计算分类准确率:
aapl = preprocess(select * from ohlc where Ticker = `AAPL)
predicted = model.predict(aapl)
score = sum(predicted == appl.Target) \ aapl.size() // 0.7565223. 使用PCA为数据降维
主成分分析(Principal Component Analysis, PCA)是一个机器学习中的使用技巧。如果数据的维度太高,学习算法的效率可能很低下,通过PCA,将高维数据映射到低维空间,同时尽可能小化信息损失,可以解决维度灾难的问题。PCA的另一个应用是数据可视化。二维或三维的数据能便于用户理解。
以对wine数据进行分类为例,输入的数据集有13个因变量,对数据源调用pca函数,观察各主成分的方差权重。将normalize参数设为true,以对数据进行归一化处理。
xColNames = `Alcohol`MalicAcid`Ash`AlcalinityOfAsh`Magnesium`TotalPhenols`Flavanoids`NonflavanoidPhenols`Proanthocyanins`ColorIntensity`Hue`OD280_OD315`Proline
pcaRes = pca(
sqlDS(<select * from wineTrain>),
colNames=xColNames,
normalize=true
)返回值是一个字典,观察其中的explainedVarianceRatio,会发现压缩后的前三个维度的方差权重已经非常大,压缩为三个维度足够用于训练:
> pcaRes.explainedVarianceRatio;
[0.209316,0.201225,0.121788,0.088709,0.077805,0.075314,0.058028,0.045604,0.038463,0.031485,0.021256,0.018073,0.012934]我们只保留前三个主成分:
components = pcaRes.components.transpose()[:3]将主成分分析矩阵应用于输入的数据集,并调用randomForestClassifier进行训练。
def principalComponents(t, components, yColName, xColNames) {
res = matrix(t[xColNames]).dot(components).table()
res[yColName] = t[yColName]
return res
}
ds = sqlDS(<select * from wineTrain>)
ds.transDS!(principalComponents{, components, `Class, xColNames})
model = randomForestClassifier(ds, yColName=`Class, xColNames=`col0`col1, numClasses=3)对测试集进行预测时,也需要提取测试集的主成分:
model.predict(wineTest.principalComponents(components, `Class, xColNames))4. 使用DolphinDB插件进行机器学习
除了内置的经典机器学习算法,DolphinDB还提供了一些插件。利用这些插件,我们可以方便地用DolphinDB地脚本语言调用第三方库进行机器学习。本节将以DolphinDB XGBoost插件为例,介绍使用插件进行机器学习的方法。
4.1 加载XGBoost插件
从DolphinDB Plugin的GitHub页面下载已经编译好的XGBoost插件到本地。然后在DolphinDB中运行loadPlugin(pathToXgboost),其中pathToXgboost是下载的PluginXgboost.txt的路径:
pathToXgboost = "C:/DolphinDB/plugin/xgboost/PluginXgboost.txt"
loadPlugin(pathToXgboost)4.2 调用插件函数进行训练、预测
同样使用wine数据。XGBoost插件的训练函数xgboost::train的语法为xgboost::train(Y, X, [params], [numBoostRound=10], [xgbModel]),我们将训练数据wineTrain的Label列单独取出来作为输入的Y,将其他列保留作为输入的X:
Y = exec Label from wineTrain
X = select Alcohol, MalicAcid, Ash, AlcalinityOfAsh, Magnesium, TotalPhenols, Flavanoids, NonflavanoidPhenols, Proanthocyanins, ColorIntensity, Hue, OD280_OD315, Proline from wineTrain训练前需要设置参数params字典。我们将训练一个多分类模型,故将params中的objective设为"multi:softmax",将分类的类别数num_class设为3。其他常见的参数有:
- booster: 可以取"gbtree"或"gblinear"。gbtree采用基于树的模型进行提升计算,gblinear采用线性模型。
- eta: 步长收缩值。每一步提升,会按eta收缩特征的权重,以防止过拟合。取值范围是[0,1],默认值是0.3。
- gamma: 小的损失减少值,仅当分裂树节点产生的损失减小大于gamma时才会分裂。取值范围是[0,∞],默认值是0。
- max_depth: 树的大深度。取值范围是[0,∞],默认值是6。
- subsample: 采样的比例。减少这个参数的值可以避免过拟合。取值范围是(0,1],默认值是1。
- lambda: L2正则的惩罚系数。默认值是0。
- alpha: L1正则的惩罚系数。默认值是0。
- seed: 随机数种子。默认值是0。
其他参数参见XGBoost的官方文档。
在本例中,我们将设置objective, num_class, max_depth, eta, subsample这些参数:
params = {
objective: "multi:softmax",
num_class: 3,
max_depth: 5,
eta: 0.1,
subsample: 0.9
}训练模型,预测并计算分类准确率:
model = xgboost::train(Y, X, params)
testX = select Alcohol, MalicAcid, Ash, AlcalinityOfAsh, Magnesium, TotalPhenols, Flavanoids, NonflavanoidPhenols, Proanthocyanins, ColorIntensity, Hue, OD280_OD315, Proline from wineTest
predicted = xgboost::predict(model, testX)
sum(predicted == wineTest.Label) \ wineTest.size() // 0.962963同样,可以将模型持久化或加载已有模型:
xgboost::saveModel(model, "xgboost001.mdl")
model = xgboost::loadModel("xgboost001.mdl")通过指定xgboost::train的xgbModel参数,对已有的模型进行增量训练:
model = xgboost::train(Y, X, params, , model)附录:DolphinDB机器学习函数
A. 机器学习训练函数
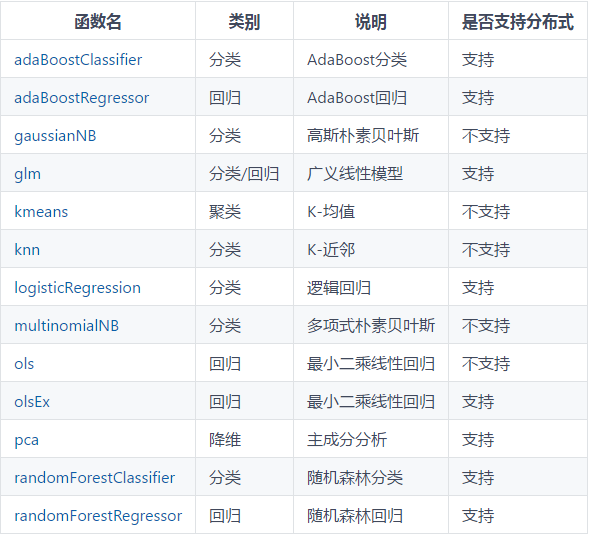
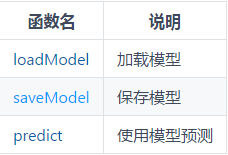
B. 机器学习工具函数
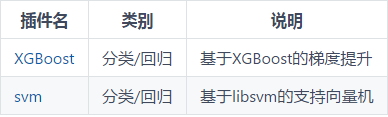
C. 机器学习插件
来源 https://zhuanlan.zhihu.com/p/154479716
