原创:小姐姐味道(微信公众号ID:xjjdog),欢迎分享,转载请保留出处。任何不保留此声明的转载都是抄袭。
近xjjdog的状态很差。也许是春天到了,也许是万物相互有感应的结果,小王的状态也很差。是我影响了他,让他在这个虚拟的世界里不断的yy又不断的沉沦。在此,xjjdog向这个虚拟的小王说一声:对不起,是我没有赋予你一马平川的能力,让你演了5集像韩剧一样又臭又长的电视剧。
但毕竟这种又臭又长是一种格调 ,小王决定认真的研究这个妹子,就如同他当年认真的研究Linux的命令一样。如果妹子是一张白纸,他会在上面书写什么呢?如果不是,他又能修改什么呢?但首先,他需要拿起笔。
你可能已经了解到,ll -l命令的列,能够显示linux的文件类型。请对此有一个大体的印象,因为后面的很多命令,会用到这些知识。
-
-表示普通文件 -
d表示目录文件 -
l表示链接文件,比如快捷方式 -
s套接字文件 -
c字符设备文件,比如/dev/中的很多文件 -
b表示块设备文件,比如一些磁盘 -
p管道文件
Linux上的文件可以没有后缀,而且可以创建一些违背直觉的文件。比如后缀是png,但它却是一个压缩文件(通常不会这么做)。大学时,就有聪明的同学这样藏小电影,效果很好。
查看文件的具体类型,可以使用file命令,它很聪明,能够识别很多文件格式。
[root@localhost ~]# file /etc
/etc: directory
[root@localhost ~]# file /etc/group
/etc/group: ASCII text
[root@localhost ~]# file /dev/log
/dev/log: socket
[root@localhost ~]# file /dev/log
/dev/log: socket
[root@localhost ~]# file /bin
/bin: symbolic link to `usr/bin'
复制代码本小节的操作,面向的就是ASCII text类型的,普通文本文件。接下来,我们要创建一些文件。然后写入一些内容到文件里,以便进行后续的操作。
1、创建一个文件
1.1、数字序列

使用重定向符,能够直接生成文件。下面,我要生成10到20的数字,每一个数字单独一行,写入一个叫做spring的文件。巧的很,seq命令可以完成这个过程。
seq 10 20 >> spring
复制代码我们在前面提到过>的意思,是将前面命令的输出,重定向到其他地方。在这里,我们用了两个>,它依然是重定向的意思,但表示的是,在原来文件的基础上,追加内容。
也就是编程语言里的w+和a+的意思。
1.2、查看内容

n,甚至可以打印行号。效果如下:
[root@localhost ~]# cat spring
10
11
12
13
14
15
16
17
18
19
20
[root@localhost ~]# cat -n spring
1 10
2 11
3 12
4 13
5 14
6 15
7 16
8 17
9 18
10 19
11 20
复制代码除了查看文件内容,cat命令通常用在更多的地方。只有和其他命令联合起来,它才会觉得生活有意义。
# 合并a文件和b文件到c文件
cat a b>> c
# 把a文件的内容作为输入,使用管道处理。我们在后面介绍
cat a | cmd
# 写入内容到指定文件。在shell脚本中非常常用。我们在后面会多次用到这种写法
cat > index.html <<EOF
<html>
<head><title></title></head>
<body></body>
</html>
EOF
复制代码由于我们的文件不大,cat命令没有什么危害。但假如文件有几个GB,使用cat就危险的多,这只叫做猫的小命令,会在终端上疯狂的进行输出,你可以通过多次按ctrl+c来终止它。
2、平和的查看文件

既然cat命令不适合操作大文件,那一定有替换的方案。less和more就是。由于less的加载速度比more快一些,所以现在一般都使用less。它主要的用途,是用来分页浏览文件内容,并提供一些快速查找的方式。less是一个交互式的命令,你需要使用一些快捷键来控制它。
这次我们使用seq生成一千万行记录,足足有76MB大小,然后用less打开它。
[root@localhost ~]# seq 10000000 > spring
[root@localhost ~]# du -h spring
76M spring
[root@localhost ~]# less spring
复制代码关于less,一般操作如下:
-
空格向下滚屏翻页 -
b向上滚屏翻页 -
/进入查找模式,比如/1111将查找1111字样 -
q退出less -
g到开头 -
G去结尾 -
j向下滚动 -
k向上滚动,这两个按键和vim的作用非常像
3、文件头尾
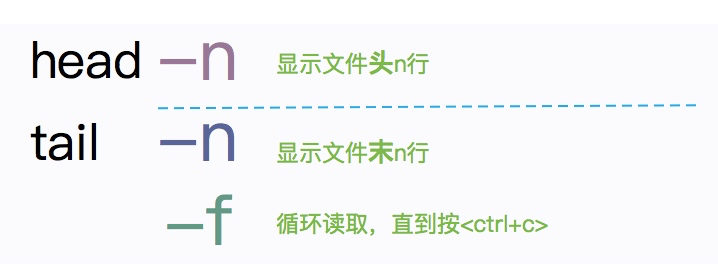
head可以显示文件头,tail可以显示文件尾。它们都可以通过参数-n,来指定相应的行数。
[root@localhost ~]# head -n 3 spring
1
2
3
[root@localhost ~]# tail -n 3 spring
9999998
9999999
10000000
复制代码对于部分程序员来说,tail -f或许是常用的命令之一。它可以在控制终端,实时监控文件的变化,来看一些滚动日志。比如查看nginx或者tomcat日志等等。通常情况下,日志滚动的过快,依然会造成一些困扰,需要配合grep命令达到过滤效果。
# 滚动查看系统日志
tail -f /var/log/messages
# 滚动查看包含info字样的日志信息
tail -f /var/log/messages | grep info
复制代码对于tail命令来说,还有一个大写的参数
F。这个参数,能够监控到重新创建的文件。比如像一些log4j等日志是按天滚动的,tail -f无法监控到这种变化。
4、查找文件

考虑下面这个场景。我们需要找一个叫做decorator.py的文件,这个文件是个幽灵,可能存在于系统的任何地方。find命令,能够胜任这次捉鬼行动。
我们使用find命令,从根目录找起,由于系统的文件过多,下面的命令可能会花费一段时间。
[root@localhost site-packages]# find / -name decorator.py -type f
/usr/lib/python2.7/site-packages/decorator.py
复制代码使用time命令,可以看到具体的执行时间。执行还是挺快的么!秒出!
[root@localhost site-packages]# time find / -name decorator.py -type f
/usr/lib/python2.7/site-packages/decorator.py
real 0m0.228s
user 0m0.098s
sys 0m0.111s
复制代码find命令会查出一个路径的集合。通常是查询出来之后,进行额外的处理操作,一般配合xargs命令使用(xargs读取输入,然后逐行处理),至于find的exec参数?忘了它吧,不好用!
# 删除当前目录中的所有class文件
find . | grep .class$ | xargs rm -rvf
# 找到/root下一天前访问的文件,type后面的类型参见文章开头
find /root -atime 1 -type f
# 查找10分钟内更新过的文件
find /root -cmin -10
# 找到归属于root用户的文件
find /root -user root
# 找到大于1MB的文件,进行清理
find /root -size +1024k -type f | xargs rm -f
复制代码find的参数非常非常多,记不住怎么办?除了常用的,其实都可以通过man命令查看。man的操作也和vi非常的类似,输入/EXAMPLES,会看到很多样例。不过我觉得还是上面列出的这些命令更加的适用。
4.1、数据来源
在上图中,你会看到mtime,ctime,atime类似的字样,它们的数据来自于何处呢?接下来我们顺理成章的看一下stat命令。
[root@localhost ~]# stat spring
File: ‘spring’
Size: 78888897 Blocks: 154080 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 8409203 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:admin_home_t:s0
Access: 2019-11-04 18:01:46.698635718 -0500
Modify: 2019-11-04 17:59:38.823458157 -0500
Change: 2019-11-04 17:59:38.823458157 -0500
Birth: -
复制代码这不就是文件属性么?从文件大小,到文件类型,甚至到后修改、访问时间,都可以从这里获取。Linux文件系统以块为单位存储信息,为了找到某一个文件所在存储空间的位置,会用i节点(inode) 对每个文件进行索引,你可以认为它是一个文件指针。
- 文件的字节数
- 文件拥有者user
- 文件所属组group
- 文件的读、写、执行权限
- 文件的时间戳
- ctime指inode上一次变动的时间
- mtime指文件内容上一次变动的时间
- atime指文件上一次打开的时间。
- 链接数,即有多少文件名指向这个inode (ln命令)
- 文件数据block的位置(具体的数据位置)
关于inode是一个比较大的话题,也是比较重要的知识点,有兴趣的可以自行搜索。我们只需要知道这些信息是从这里来的就可以了。
4.2、小练习
如果我只想获取Modify这个数值,可以组合使用一下上面学到的命令。首先获取后三行,然后获取首行。效果如下:
[root@localhost ~]# stat spring | tail -n 3 | head -n 1
Modify: 2019-11-04 17:59:38.823458157 -0500
复制代码下面几个命令,效果是与上面等价的,输出结果也是一模一样。正所谓条条大路通罗马,接下来,我们首先介绍一下出现频率较高的grep。另外,我们在上面的这些命令中,多次使用了|,这是Linux中非常重要的管道概念,下面也会着重介绍。
stat spring | head -n 7 | tail -n 1
stat spring | grep Modify
stat spring | sed -n '7p'
stat spring | awk 'NR==7'
复制代码5、字符串匹配

grep用来对内容进行过滤,带上--color参数,可以在支持的终端可以打印彩色,参数n则用来输出具体的行数,用来快速定位。这是一个必须要熟练使用的命令。
比如:查看nginx日志中的POST请求。
grep -rn --color POST access.log
复制代码推荐每次都使用这样的参数。
如果我想要看某个异常前后相关的内容,就可以使用ABC参数。它们是几个单词的缩写,经常被使用。
- A after 内容后n行
- B before 内容前n行
- C 内容前后n行
就像是这样:
# 查看Exception关键字的前2行和后10行
grep -rn --color Exception -A10 -B2 error.log
#查找/usr/下所有import关键字,已经它们所在的文件和行数
grep -rn --color import /usr/
复制代码
6、管道
在上面的命令中,我们多次用到了|,这貌似可以完成一些神奇的事情。|是pipe的意思,它可以把多个命令联系起来。通常,命令有下面的关联方式:
-
;顺序执行,如mkdir a;rmdir a -
&&条件执行,如mkdir a && rmdir a -
||条件执行,如mkdir a || rmdir a,后面的命令将不执行 -
|管道,前面命令的输出,将作为后面命令的输入
前三种的命令关联,是非常简单有逻辑的,非常的好理解。而管道,却有自己的特点。
接触过编程语言的都知道stdin、stdout、stderr的概念。让我们重新组织一下针对于管道的定义:前面命令的输出(stdin),将作为后面命令的输入(stdout)。
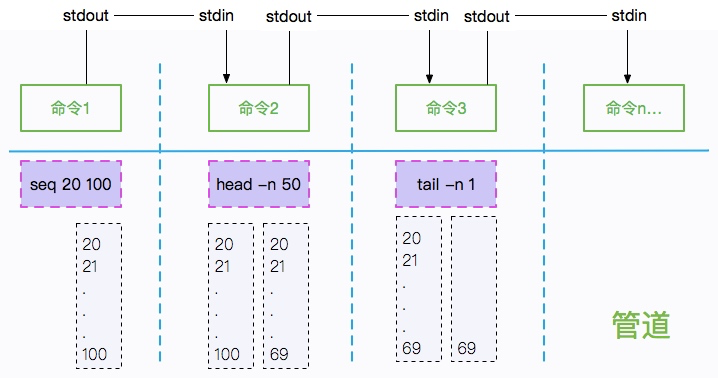
我们拿一行命令来说明。
seq 20 100 | head -n 50 | tail -n 1
复制代码上面命令,将输出69。69是个神奇的数字,它是怎么办到的呢?我们来一张小图,一切就豁然开朗了。
关于输入输出和错误,linux使用一个数字进行缩写,这在一些脚本中,甚至在一些安装文件中,会经常用到。
- 0 表示stdin标准输入
- 1 表示stdout标准输出
- 2 表示stderr标准错误
通过类似2>&1的语法,可以把错误信息定向到标准输出。我们用命令来证明一下。
# 错误信息无法输出到文件
[root@localhost ~]# cat aaaaaaaaa > b
cat: aaaaaaaaa: No such file or directory
[root@localhost ~]# cat b
# 错误信息被重定向了
[root@localhost ~]# cat aaaaaaaaa > b 2>&1
[root@localhost ~]# cat b
cat: aaaaaaaaa: No such file or directory
复制代码7、排序

在了解管道的工作原理之后,就可以介绍一下sort命令了。它通常可以和uniq(去重)命令联合,完成一些排序、去重的操作。首先使用cat命令,生成如下内容的文件。
cat > sort.txt <<EOF
1 11
3 22
2 44
4 33
5 55
6 66
6 66
EOF
复制代码接下来让这两个命令上台表演一下。 sort可以使用-t指定分隔符,使用-k指定要排序的列。但是空格,是不需要做这些画蛇添足的指定的。
# 根据列倒序排序
[root@localhost ~]# cat sort.txt | sort -n -k1 -r
6 66
6 66
5 55
4 33
3 22
2 44
1 11
# 统计每一行出现的次数,并根据出现次数倒序排序
# 此时,行数由7变成了6
[root@localhost ~]# cat sort.txt | sort | uniq -c | sort -n -k1 -r
2 6 66
1 5 55
1 4 33
1 3 22
1 2 44
1 1 11
复制代码注意:uniq命令,一般用在已经经过排序的结果集上。所以,很多情况需要首先使用sort命令进行排序后,再使用uniq命令。新手经常会忘记步,造成命令不能正常运行。
8、小结
本小节,我们从文件的属性开始说起,了解了几个对文件操作的常用命令。并顺便介绍了管道的概念。下面,我们来练习一下。
找到系统中所有的grub.cfg文件,并输出它的行数。
分析:首先需要使用find命令,找到这些文件。然后使用xargs逐行处理。后,使用wc命令,统计确切的行数。
[root@localhost grub2]# find / | grep grub.cfg | xargs wc -l
141 /boot/grub2/grub.cfg
复制代码输出系统的group列表
cat /etc/group | awk -F ':' '{print $1}'
复制代码下面这个命令输出nginx日志的ip和每个ip的pv,pv高的前10
# 2019-06-26T10:01:57+08:00|nginx001.server.ops.pro.dc|100.116.222.80|10.31.150.232:41021|0.014|0.011|0.000|200|200|273|-|/visit|sign=91CD1988CE8B313B8A0454A4BBE930DF|-|-|http|POST|112.4.238.213
awk -F"|" '{print $3}' access.log | sort | uniq -c | sort -nk1 -r | head -n10
复制代码9、思考&扩展
1、Linux的终端,是如何实现彩色的文字的?我要如何输出一个绿色的Hello World?
2、软链接与硬链接有什么区别?
3、了解几个偏门但又不是非常偏的命令。
-
cut有了awk,几乎不怎么会用cut了 - tr
- col
- paste
- join
- split
End
潮湿的眼神,忧郁的裤裆。
或许,保守才是小王大的伤痛,是因也是果,是果躲不过。这种性格,一开始就决定了,到了30多岁,他还是孑然一身。
世事洞明皆学问,人情炼达即文章。下一小节,我将带小王了解:条条道路通罗马,铁树也能开出花。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。
4 sort 4 uniq 7 tail 5 less 3 more 3 stat 3 head 5 find 7 grep 6 cat 6 seq 2 tr 1 col 1 paste 1 join 1 split 1 awk 9
