介绍
训练好的模型要给业务调用,deepjavalibrary/djl:Java 中与引擎无关的深度学习框架 (github.com) 可以完成这件事,它支持使用 Java 调用 PyTorch、TensorFlow、MXNet、ONNX、PaddlePaddle 等引擎的模型(也支持部分引擎的模型构建和训练),本文只介绍调用 PaddlePaddle 引擎的模型调用。
调用模型流程:
- 导出模型(我更喜欢 ONNX 格式,它在 CPU 上推理也挺快的,可以快速测试,但有的算子不支持导出),确认模型输入输出
- 编写 Java 加载模型以及处理输入输出的代码
PaddleDetection 模型导出
导出模型
Anaconda 配置一个 PaddleDetection 的环境,cpu 版本即可(paddlepaddle==2.2.2),下载 PaddleDetection 工程,修改工程中 configs/runtime.yml 的属性 use_gpu 为 false。
下面以行人检测模型 configs/pphuman/pedestrian_yolov3/pedestrian_yolov3_darknet.yml 为例介绍整个流程,导出模型:
$ python tools/export_model.py -c configs/pphuman/pedestrian_yolov3/pedestrian_yolov3_darknet.yml -o weights=https://paddledet.bj.bcebos.com/models/pedestrian_yolov3_darknet.pdparams --output_dir pedestrian_yolov3_darknet
再转换为 ONNX:
$ paddle2onnx --model_dir pedestrian_yolov3_darknet/pedestrian_yolov3_darknet --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file pedestrianYolov3.onnx --enable_onnx_checker True
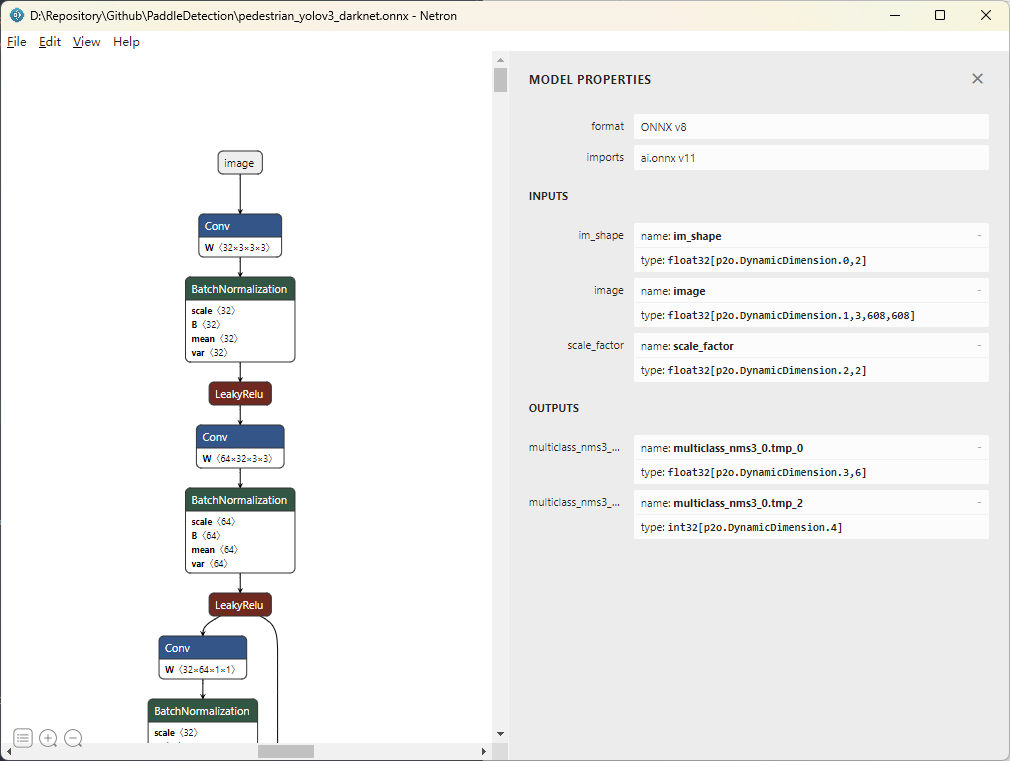
确认输入输出
在 PaddleDetection 模型导出教程 中查看模型输入输出参数,再通过 Netorn 打开前面导出的 ONNX 模型详细确认
Java 读取模型及推理
依赖
<dependencies>
<dependency>
<groupId>ai.djl</groupId>
<artifactId>api</artifactId>
</dependency>
<!--混合引擎,因为有的引擎 NDArray 不支持-->
<dependency>
<groupId>ai.djl.mxnet</groupId>
<artifactId>mxnet-engine</artifactId>
</dependency>
<dependency>
<groupId>ai.djl.onnxruntime</groupId>
<artifactId>onnxruntime-engine</artifactId>
</dependency>
<dependency>
<groupId>ai.djl</groupId>
<artifactId>model-zoo</artifactId>
</dependency>
<!--使用 openpnp 的 opencv 加快图片读取-->
<dependency>
<groupId>ai.djl.opencv</groupId>
<artifactId>opencv</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>ai.djl</groupId>
<artifactId>bom</artifactId>
<version>0.20.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
处理输入输出
确定输入参数为图片原形状 im_shape、图片(需要归一化)image、比例 scale_factor,输出为预测框和预测数量,参数详细说明见前面提到的 PaddleDetection 模型导出教程中的说明。
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.output.BoundingBox;
import ai.djl.modality.cv.output.DetectedObjects;
import ai.djl.modality.cv.output.Rectangle;
import ai.djl.modality.cv.transform.Normalize;
import ai.djl.modality.cv.transform.Resize;
import ai.djl.modality.cv.transform.ToTensor;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.*.DataType;
import ai.djl.translate.NoBatchifyTranslator;
import ai.djl.translate.Pipeline;
import ai.djl.translate.TranslatorContext;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
// 非批量输入输出应实现 NoBatchifyTranslator 接口,而不是 Translator
public class PedestrianTranslator implements NoBatchifyTranslator<Image, DetectedObjects> {
private final Pipeline pipeline;
private final float threshold;
private final List<String> classes;
private final float imageWidth = 608f;
private final float imageHeight = 608f;
public PedestrianTranslator(float threshold) {
// 定义图片预处理过程
pipeline = new Pipeline();
pipeline.add(new Resize((int) imageWidth, (int) imageHeight)) // resize 为模型图片输入格式,变成 608 * 608 * 3,HWC
.add(new ToTensor()) // HWC -> CHW
.add(new Normalize(new float[]{0.485f, 0.456f, 0.406f}, new float[]{0.229f, 0.224f, 0.225f})) // 归一化
.add(array -> array.expandDims()); // CHW -> NCHW
// 预测阈值
this.threshold = threshold;
// 类别
classes = Collections.singletonList("pedestrian");
}
@Override
public NDList processInput(TranslatorContext ctx, Image input) {
// 内存管理器,负责 NDArray 的内存回收
NDManager manager = ctx.getNDManager();
// 通过构造函数定义好的管道把图片转换到模型需要的图片格式。NDList 是一个集合,与 List<NDArray> 类似
NDList ndList = pipeline.transform(new NDList(input.toNDArray(manager, Image.Flag.COLOR)));
// 添加原图尺寸参数
ndList.add(, manager.create(new float[]{input.getHeight(), input.getWidth()}).expandDims());
// 添加原图片尺寸与输入图片尺寸的比值
ndList.add(manager.create(new float[]{input.getHeight() / 608f, input.getWidth() / 608f}).expandDims());
return ndList;
}
@Override
public DetectedObjects processOutput(TranslatorContext ctx, NDList list) {
// 获取个参数预测结果,第二个预测数量没什么用
NDArray result = list.get();
/*
result demo:
ND: (3, 6) cpu() float32
[[ 0. , 0.9759, 10.0805, 276.1631, 298.1623, 586.246 ],
[ 0. , 0.955 , 486.306 , 221.0572, 585.966 , 480.4897],
[ 0. , 0.8031, 295.0543, 206.104 , 395.3066, 485.3789],
]
*/
// 获取类别
int[] classIndices = result.get(":, 0").toType(DataType.INT32, true).flatten().toIntArray();
// 获取置信度
double[] probs = result.get(":, 1").toType(DataType.FLOAT64, true).toDoubleArray();
// 获取预测的目标数量
int detected = Math.toIntExact(probs.length);
// 获取矩形框左上角 x 坐标比例(第 2 列)
NDArray xMin = result.get(":, 2:3").clip(, imageWidth).div(imageWidth);
// 获取矩形框左上角 y 坐标比例(第 3 列)
NDArray yMin = result.get(":, 3:4").clip(, imageHeight).div(imageHeight);
// 获取矩形框右上角 x 坐标比例(第 4 列)
NDArray xMax = result.get(":, 4:5").clip(, imageWidth).div(imageWidth);
// 获取矩形框右上角 y 坐标比例(第 5 列)
NDArray yMax = result.get(":, 5:6").clip(, imageHeight).div(imageHeight);
// 转为可以直接绘制的数据,分别是矩形框左上角的 x 和 y 坐标、矩形框的宽和高,均为比例
float[] boxX = xMin.toFloatArray();
float[] boxY = yMin.toFloatArray();
float[] boxWidth = xMax.sub(xMin).toFloatArray();
float[] boxHeight = yMax.sub(yMin).toFloatArray();
// 封装成 DetectedObjects 对象输出
List<String> retClasses = new ArrayList<>(detected);
List<Double> retProbs = new ArrayList<>(detected);
List<BoundingBox> retBB = new ArrayList<>(detected);
for (int i = ; i < detected; i++) {
// 类别不存在或者置信度低于预测阈值则跳过
if (classIndices[i] < || probs[i] < threshold) {
continue;
}
retClasses.add(classes.get());
retProbs.add(probs[i]);
retBB.add(new Rectangle(boxX[i], boxY[i], boxWidth[i], boxHeight[i]));
}
return new DetectedObjects(retClasses, retProbs, retBB);
}
}
这里涉及的 NDArray 操作比较多,使用官方实现的 Transform 和 Pipeline 可以简化代码,不过手动调 NDImageUtils 更清晰。简单说几个 API:
- expandDims:增加维度,比如 Pipeline 的一个 Transform Lambda 将 CHW 前面加一个维度变成 NCHW
- get:查看 NDIndex API(方法注释上均有代码样例说明)、百度 numpy 索引切片或 NDArray 教程,搞懂
:和, - clip:限制数值,数值越界就取该方法传入的值
加载模型
import ai.djl.MalformedModelException;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.output.DetectedObjects;
import ai.djl.repository.zoo.Criteria;
import ai.djl.repository.zoo.ModelNotFoundException;
import ai.djl.repository.zoo.ZooModel;
import ai.djl.training.util.ProgressBar;
import java.io.IOException;
import java.nio.file.Paths;
public class Models {
public static ZooModel<Image, DetectedObjects> getModel() throws ModelNotFoundException, MalformedModelException, IOException {
return Criteria.builder()
.optEngine("OnnxRuntime") // 选择引擎
.set*(Image.class, DetectedObjects.class) // 设置输入输出
.optModelPath(Paths.get("D:\\Repository\\Github\\PaddleDetection\\pedestrian_yolov3_darknet.onnx")) // 设置模型地址。Jar 包、Zip 包根据 API 自行配置
.optProgress(new ProgressBar()) // 进度条
.optTranslator(new PedestrianTranslator(.5f)) // 默认的转换器,不是线程安全的
.build().loadModel();
}
}
推理
import ai.djl.Device;
import ai.djl.MalformedModelException;
import ai.djl.inference.Predictor;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.ImageFactory;
import ai.djl.modality.cv.output.DetectedObjects;
import ai.djl.repository.zoo.ModelNotFoundException;
import ai.djl.repository.zoo.ZooModel;
import ai.djl.translate.TranslateException;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class Inference {
public static void main(String[] args) throws IOException, MalformedModelException, TranslateException, ModelNotFoundException {
String imageFilePath = "C:\\Users\\DELL\\Desktop\\2.png";
// 加载模型
try (ZooModel<Image, DetectedObjects> model = Models.getModel()) {
// 新建一个推理,使用 GPU
try (Predictor<Image, DetectedObjects> predictor = model.newPredictor(Device.gpu())) {
Image image = ImageFactory.getInstance().fromFile(Paths.get(imageFilePath));
// 推理
DetectedObjects result = predictor.predict(image);
// 绘制矩形框
image.drawBoundingBoxes(result);
image.save(Files.newOutputStream(Paths.get("output.png")), "png");
}
}
}
}
CPU GPU 配置
没有配置 cuda 的话自动下载 CPU 所需的文件,有 cuda 的话会自动寻找匹配 cuda 版本的文件,目前官网上的 cuda 版本是 10.2 和 11.2。
也可以通过配置 jar 来指定 CPU 还是 GPU,以 ONNX 为例(详见DJL Hybrid engines ONNX):
<dependency>
<groupId>ai.djl.onnxruntime</groupId>
<artifactId>onnxruntime-engine</artifactId>
<version>0.20.0</version>
<scope>runtime</scope>
<exclusions>
<exclusion>
<groupId>com.microsoft.onnxruntime</groupId>
<artifactId>onnxruntime</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.microsoft.onnxruntime</groupId>
<artifactId>onnxruntime_gpu</artifactId>
<version>1.13.1</version>
<scope>runtime</scope>
</dependency>
注意
- 需要知道的是导出的模型的输入和输出,否则不知道怎么写 Translator
- DJL 运行所需的文件挺大的,它会在次运行时下载,网卡流量在动就等会吧(在
/${HOME}/.djl.ai/下) - 通常次推理比较慢,建议预热一次
- 多线程建议每个线程一个 Predictor
Jupyter Notebook
附上可以直接运行的 notebook:d2l/paddledetection.ipynb at master · hligaty/d2l (github.com)。Maven 下载依赖比较慢,建议手动下载依赖放到 /${HOME}/.ivy2/cache/ 下。
