前言
前段时间写了一篇关于 MySQL 锁的文章,一些小伙伴们在阅读之后产生了一些疑问,这些问题还挺有代表性的,所以在这里做个实验,来用事实探究一番。
那篇文章提到了记录锁(Record Locks),顾名思义锁的是记录,作用在索引上的记录。
锁是作用在索引上这句话可能不太好理解,并且对于在可重复读和读提交两个隔离级别下,关于是否命中二级索引的锁之间的阻塞也不太清晰。
这句话读着可能有点拗口,没事,我来给你看几个实验,对这一切就异常清晰了。
实验的 MySQL 版本为:5.7.26。
实验一:隔离级别为读提交,锁定非索引列的实验
先建个非常简单的表,只有主键索引,没有二级索引。
CREATE TABLE `yes` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(45) DEFAULT NULL, `address` varchar(45) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4隔离级别如下:
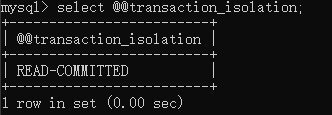
关闭自动提交事务:
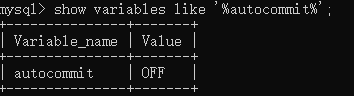
已经准备好的数据:

此时,发起事务 A,执行如下语句,且事务未提交:
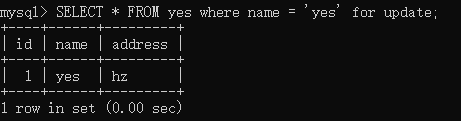
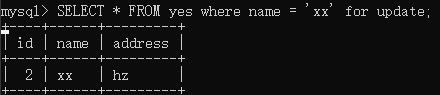
接着,再发起事务 B,执行如下语句:

你可能以为事务 B 不会被阻塞,因为事务 B 锁的是name=xx和事务A锁name=yes讲道理相互之间没有冲突,但是从结果来看,事务 B 被阻塞了,调用select * from innodb_lock_waits;看下谁等谁

可以看到,事务6517(B)在等待事务6516(A)。
此时,调用 SELECT * FROM innodb_locks; 查看相关锁的信息

锁的类型就是行级锁,此时的锁为 X 锁,锁的索引就是主键索引,这个结果表明的意思是事务 B(6517)想要 id 为 1 的记录锁,但是这个记录此时被事务A(6516)占有。
是的,这里的 1 其实不是指个记录的意思,是 id 为 1 的记录。
可能有人疑惑, 为啥 lock_data 为 1 ?
(我没看过源码,个人推断如下:)执行 select ... for update ,由于 name 字段没有索引,索引事务 A、B 只能加锁到主键索引上,此时需要搜索 name 为 yes 的记录,但是又没有索引,只能全表扫描,恰巧扫描条记录就符合要求了,于是上锁,然后接着往后扫描,后面不符合条件所以没有上锁。此时事务 B 加锁,过程和事务 A 一样需要从条记录开始扫描上锁,但此时条记录已经被事务 A 锁了,所以条记录就冲突了,而条记录的 id 就是为 1,因此 lock_data 为 1。
现在,我把事务 A 提交,则事务 B 里面能立马得到结果。
从上面这个实验可以得知,如果查询条件上锁,但是没有对应的二级索引可以命中,那么锁就会锁到主键(聚簇)索引上。
而聚簇索引的非叶子节点只有主键的信息,没有 name 的信息,所以只能按顺序的全表扫描,加锁符合条件的记录,但是在扫描过程中遇到已经被加锁的记录就会被阻塞,即使这个记录不是目标记录。
看下面这个实验,你就清晰了。
这个实验其实就是把事务 A、B的语句执行的顺序换了一下。
此时,新起一个事务 C,先执行如下语句,锁的是id为2的记录:
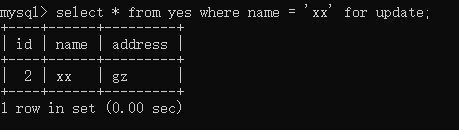
然后,再起一个事务 D,执行:

此时同样被阻塞了,但是查看下锁信息你会发现:
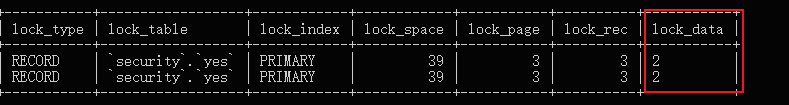
lock_data 变为 id 为 2 的记录了,也就是说事务 C 扫描了 id 为 1 的记录之后,发现不符合条件,就释放了,(不然 lock_data 的值应该为 1)然后继续扫描 id 为 2 的记录,符合条件,于是上锁。
而事务 D 也扫描了 id 为 1 的记录,符合条件,于是上锁,然后接着向后扫描到 id 为 2 的记录,但是此时已经被事务C 加锁了,于是被阻塞。
这结果也符合了我上面的推断。
我们再继续实验。
这次来试试 update 的,此时新起事务 E :
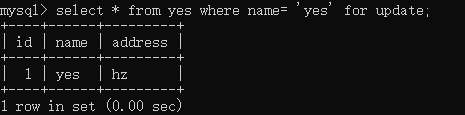
再起一个事务 F :

并没有发生阻塞,这其实是符合我们预期的。但从中我们可以得知,在读提交级别下,即使没有索引,update 的全表扫描并不是和select ... for update那样全表按顺先加锁再判断条件,而是先找到符合的记录,然后再上锁。
我们再继续实验。
此时,把上面的事务都提交之后,再新起一个事务 G 执行以下语句,且不提交事务:
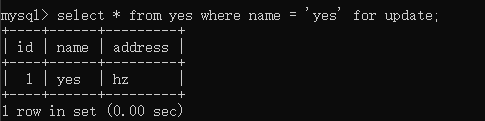
接着,再起一个事务 H 执行以下语句:

可以看到,事务 H 没有被阻塞,丝滑。
说明在读提交级别下,锁的只是已经存在的记录,对于插入还是防不住的,即使插入的 name 是 yes,也一样不会被阻塞。

实验二:隔离级别为可重复读,锁定非索引列的实验
隔离级别为可重复读:
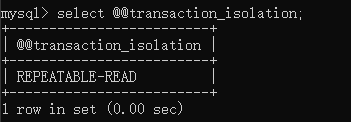
还是之前的数据:
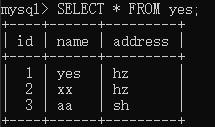
此时,发起事务 A,执行如下语句,且事务未提交:
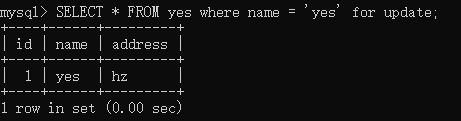
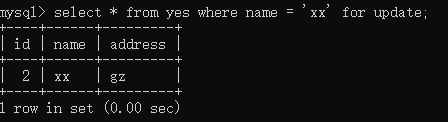
接着,再发起事务 B,执行如下语句:

意料之中的结果,即事务 B 被阻塞,锁信息如下,还是 id 为 1 的记录出了锁冲突。

此时提交事务A、B,然后再新起一个事务 C:
然后再新起一个事务 D:

没错,事务 C、D 就是和 A、B 来个反顺序执行,重点来了,此时的锁信息如下:
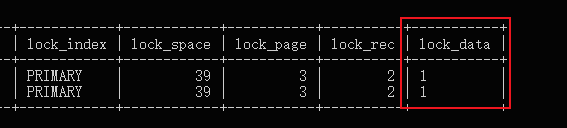
可以看到,冲突的还是 id 为 1 的这条记录,那说明事务 C 在全表扫描,从条开始遍历,即使访问到了不符合条件的记录,加锁之后在事务提交之前就不会释放!
这里就和读已提交有差别了。
我们再继续实验,此时提交事务A、B、C、D之后,再新起一个事务 E:
接着,再起事务 F 执行如下语句:

可以看到,事务 F 被阻塞了,此时再看下锁的一些信息:

起冲突的 lock_data 是大记录(supremum),这个记录之前的文章提过的,MySQL页默认有大和小两条记录,不存储数据,作用类似于链表的 dummy 节点。
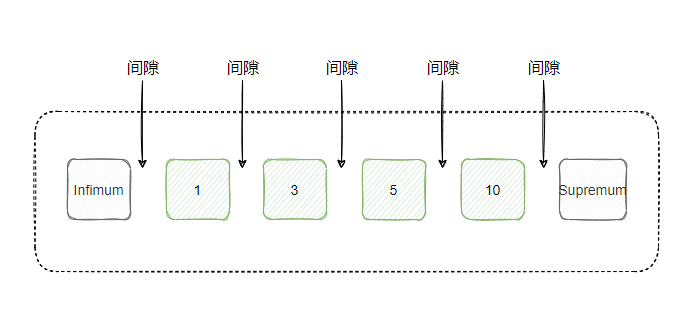
从这个结果来看,这个大记录也被事务 F 锁了,这个表的 ID 是自增的,所以此时的插入记录,刚好要插入到后面,这样就发生了冲突。
这其实有点出乎我的意料,我以为事务 F 插入应该是被事务 E 加的间隙锁给挡了才对。
这时候,我又做了个实验,我先造了一条 id 为 6 的记录,此时表内的数据如下:
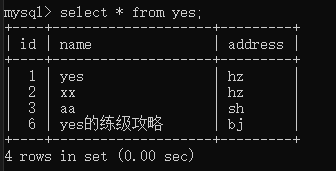
同样再起一个事务执行,且未提交:
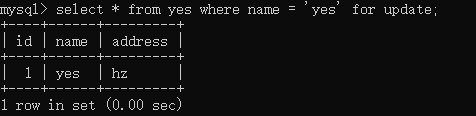
接着,我再起一个事务执行插入,但是指明了插入的 id 是 4 ,这样这条记录会将插入到记录 id 为 6 的前面。

此时被阻塞了,查看锁信息:

看到截图的 X,GAP 没,结果显示插入的事务需要记录锁+间隙锁,但是被前一个事务占用的 id 为 6 的记录锁给阻塞了。
这涉及到我的盲区了,上面的插入还只要记录锁,这时候的插入就又要申请间隙锁了?但是也不是因为间隙被阻塞啊?我之后再找个时间研究下,如果有大佬知道,请评论区指导我下。
我们再继续实验,清理下数据,还原到初始状态:
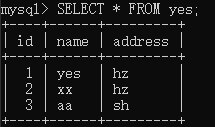
启动一个事务 G 执行:

接着再启动一个事务 H 执行:

此时发生了阻塞,看下锁的信息:

可以看到,可重复读级别下 update 的加锁与读提交不太一样,加锁的 lock_data 是 1,说明事务 G 扫描的 id 为 1 的记录之后没有释放锁。
如果把事务G、H 的启动顺序反过来,也就是先执行 H 的语句再执行 G 的语句,结果也是一样的,同样加锁的 lock_data 是 1,这说明可重复读的 update 不是先判断条件是否符合再上锁,而是先上锁再判断条件是否符合。
update 都会被阻塞,终结论就是:
在可重复读级别下,加锁非索引列导致的全表记录上锁会使得所有插入和修改都会被阻塞。
小结一下:
此时把读者问题列上:
留言的回答语境是在可重复读级别下,现在我再来总结回答下:
在读提交级别下:
如果锁定的列为非索引列,加锁都是加到主键索引上的,select ..for update的加锁的顺序是从前往后全表扫描的顺序,遍历的记录先上锁,上锁之后发现不满足条件,则释放锁,然后继续往后遍历,直到全表扫描结束。
insert 都不会被阻塞。
而 update 其它字段值,其实也是找记录,如果找到的记录已经被上锁了,那么就会阻塞,如果找到的记录没有被锁则不会被阻塞。
在可重复读级别下:
如果锁定的列为非索引列,加锁都是加到主键索引上的,select ..for update的加锁的顺序是从前往后全表扫描的顺序,遍历的记录先上锁,上锁之后发现不满足条件,则不会释放锁,然后继续往后遍历,直到全表扫描结束。
所以只要有一个全表扫描的加锁,则 insert 的时候就会被阻塞。
而 update 其它字段值,其实也是找记录,如果找到的记录已经被上锁了,那么就会阻塞,如果找到的记录没有被锁则不会被阻塞。
与之相关的还有一个问题:

图里已经有答案了,包括前面的截图也可以看到所有的 lock_type 都是 RECORD ,也就是行级锁。
实验三:隔离级别为读提交,锁定索引列的实验
此时在 name 列建立索引。
CREATE TABLE `yes` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(45) DEFAULT NULL, `address` varchar(45) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`)) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4同样准备数据如下:
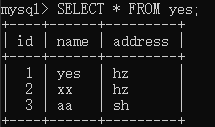
发起事务 A,执行如下语句,且事务未提交:
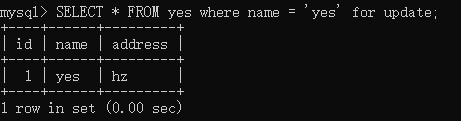
接着发起事务 B,执行如下语句:
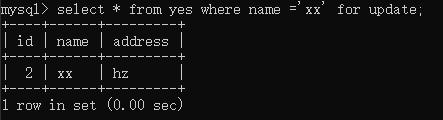
可以看到,不会被阻塞,丝滑。
这个结果符合认知,因为此时 name 已经有索引了,在读提交级别下,只会在 name 索引上加相关记录的锁,而不会加全表行锁,因此事务 A、B 之间不会被阻塞。
此时再起一个事务 C,执行如下语句:

可以看到,发生了阻塞,此时查看锁信息:

可以看到,锁的索引确实变成了 idx_name,lock_data 显示锁的是 yes 这个记录,id 为 1。
从结果看:在可以命中二级索引的情况下,锁的是对应的二级索引。
我们继续做实验。
将上面所有事务提交之后。
启动事务 C 执行以下语句,且未提交事务:
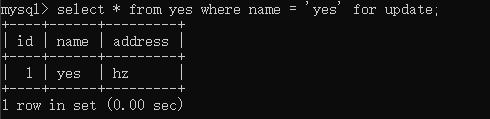
接着,事务 D 执行以下语句:

并不会发生阻塞,丝滑地插入了数据。

执行 name 一样的插入,也不会阻塞。
所以在读提交级别下,对插入都不会产生阻塞。
关于 update 我就不实验了,和实验一的差别就是加锁索引换成了 name 的索引,其他表现一致。
实验四:隔离级别为可重复读,锁定索引列的实验
同样准备数据如下:
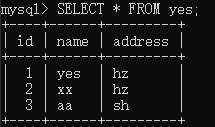
在可重复读级别下,事务A执行:
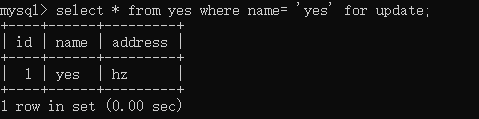
接着,事务 B 执行:

此时发生了阻塞,查看锁信息:

这是预期之内的阻塞,因为按照 name 为索引,yes这条记录是排在后的(字母序),为了防止幻读,可重读隔离级别下会在对应记录前后加入间隙锁,而新的记录的插入恰巧需要排 yes 这条记录的后面。
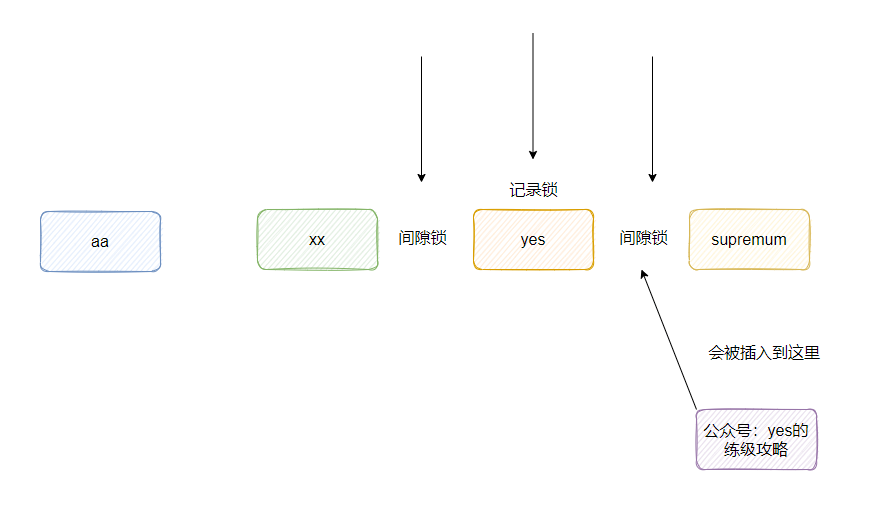
但是从截图结果来看此时lock_mode是记录锁,且 lock_data 是 supremum,这又涉及到我的盲区了,难道是后的记录插入比较特殊?所以不是因为间隙锁被阻塞,而是被大记录行锁阻塞?
此时把事务A、B都提交了 ,然后我们再执行事务 C:
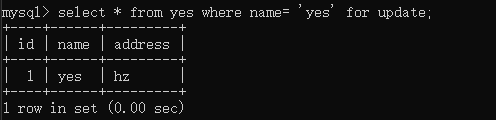
接着再执行事务 D:

此时的插入不会被阻塞,因为事务 C 锁的是记录 yes 左右的间隙和 yes 本身,而事务B提交了,因此事务D插入的不是被锁定的位置。
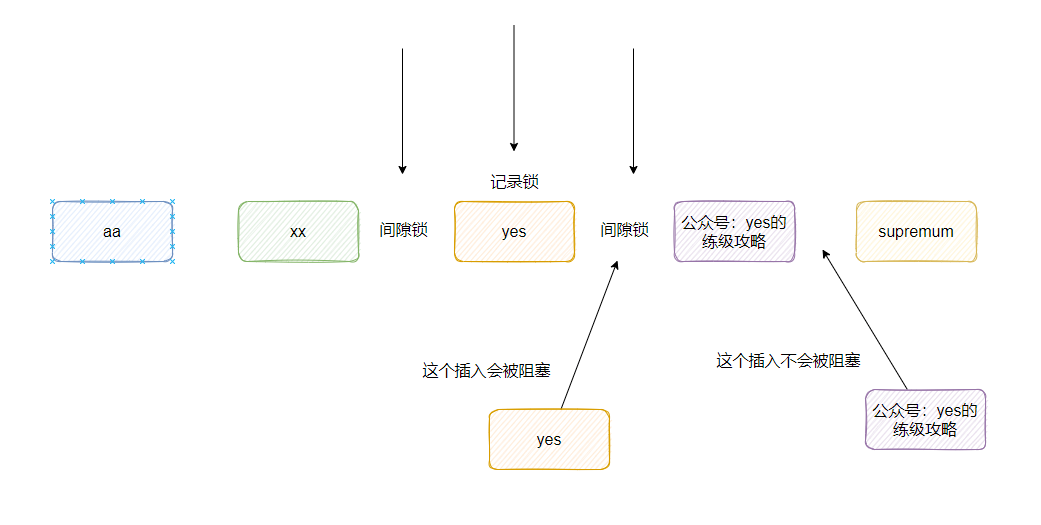
如果此时事务 C 接着再执行:

则会被阻塞,我们看下锁的信息:

可以看到,此时被阻塞的锁是记录锁+间隙锁(next-key lock),这符合我们的认知和上面的图,因为要插入的数据在 yes 和公众号:yes的练级攻略之间。
update我就不实验了,不是全表扫描,只会根据索引加锁扫描到的记录。
小结
在命中索引列的前提下,只会在索引列上加锁。
如果此时在读已提交级别下:
select..for update和update的所查找的记录本身会被加上记录锁,因此这个位置的插入会被阻塞,其他位置的插入则没有影响。
如果此时在可重复读级别下:
select..for update和update的所查找的记录在索引位置前后会被加间隙锁,记录本身加记录锁,因此这些位置的插入会被阻塞,其他位置的插入则没有影响。
后
分了四个实验大类,一个做了十三个实验。
还是挺有收获的,惊喜就是发现了细节盲区,之后研究一下再出一篇文章。
从实验来看,这里再做个概念性的总结:
锁是作用在索引上的,因此如果能命中二级索引就在二级索引上加锁,不然就得被迫在聚簇索引上加锁。
被迫在聚簇索引上加锁,会导致全表扫描式的加锁。
在可重复读下,不论命中哪个索引,不论是select..for update还是update,只要被扫描到的记录,都会被加锁,不论是否符合条件,在事务提交之后才会释放。
在读提交下,select..for update表现出来的结果是扫描到的记录先加锁,再判断条件,不符合就立马释放,不需要等到事务提交,而 update 的扫描是先判断是否符合条件,符合了才上锁。
声明:以上实验是基于 MySQL 5.7.26 版本,存储引擎为 InnoDB 。
这些实验我之前花了三个工作日晚上做的,由于时间是零散的,导致中间实验出错,期间设置事务隔离级别语句有问题,导致我在错误的前提下做实验,实验结果不断地冲击我的认知,我整个人都快搞崩溃了....
然后周六花了一天的时间重新理了一下,实验图很多,可能看了后面就忘了前面,建议结合着结论来回看,这样对结论会有更深刻的认识,但是有些实验结论我是根据实验现象来推断的,我没有去找相关的官网说明,如有错误,恳请指正,如有疑惑还请自行实验,可以在评论区交流一番。
