Mysql 日志是什么?
所谓日志,就是一种将行为动作记录到一个地方,这个地方可以是文件,文本等可存储的载体。
Mysql日志就是记录整个mysql从启动,运行,到结束的整个生命周期下的行为。
日志类型
MySQL 中有七种日志文件,分别是:
二进制日志(binlog) 重做日志(redo log) 回滚日志(undo log) 错误日志(errorlog) 慢查询日志(slow query log) 一般查询日志(general log) 中继日志(relay log)
日志作用
二进制日志(binlog)
binlog 主要有以下作用:
复制:MySQL 主从复制在 Master 端开启 binlog,Master 把它的二进制日志传递给 slaves 并回放来达到 master-slave 数据一致的目的
数据恢复:通过 mysqlbinlog 工具恢复数据(4 款 MySQL Binlog 日志处理工具对比)
几个知识点:
binlog 不会记录不修改数据的语句,比如Select或者Show
binlog 会重写日志中的密码,保证不以纯文本的形式出现MySQL 8 之后的版本可以选择对 binlog 进行加密
具体的写入时间:在事务提交的时候,数据库会把 binlog cache 写入 binlog 文件中,但并没有执行fsync()操作,即只将文件内容写入到 OS 缓存中。随后根据配置判断是否执行 fsync。
删除时间:保持时间由参数expire_logs_days配置,也就是说对于非活动的日志文件,在生成时间超过expire_logs_days配置的天数之后,会被自动删除。
binlog日志格式
binlog 日志有三种格式,分别为 STATMENT 、 ROW 和 MIXED。对于生产环境中怎么选择binlog日志格式可以看看这篇文章:。
在 MySQL 5.7.7 之前,默认的格式是 STATEMENT, MySQL 5.7.7 之后,默认值是 ROW。日志格式通过 binlog-format 指定。
STATMENT:基于SQL 语句的复制( statement-based replication, SBR ),每一条会修改数据的sql语句会记录到binlog 中 。
优点:不需要记录每一行的变化,减少了 binlog 日志量,节约了 IO , 从而提高了性能; 缺点:主从复制时,存在部分函数(如 sleep)及存储过程在 slave 上会出现与 master 结果不一致的情况。
ROW:基于行的复制(row-based replication, RBR ),不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了 。
优点:因此不会发生某些特定情况下的存储过程、函数或者触发器的调用触发无法被正确复制的问题。 缺点:会产生大量的日志,尤其是 alter table的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中,实际等于重建了表。
MIXED:基于STATMENT 和 ROW 两种模式的混合复制(mixed-based replication, MBR ),一般的复制使用STATEMENT 模式保存 binlog ,对于 STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog。
主从复制
复制是 MySQL 重要的功能之一,MySQL 集群的高可用、负载均衡和读写分离都是基于复制来实现。复制步骤如下:
Master 将数据改变记录到二进制日志(binary log)中。 Slave 上面的 IO 进程连接上 Master,并请求从指定日志文件的指定位置(或者从开始的日志)之后的日志内容。 Master 接收到来自 Slave 的 IO 进程的请求后,负责复制的 IO 进程会根据请求信息读取日志指定位置之后的日志信息,返回给 Slave 的 IO 进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到 Master 端的 binlog 文件的名称以及 binlog 的位置。 Slave 的 IO 进程接收到信息后,将接收到的日志内容依次添加到 Slave 端的 relaylog 文件的末端,并将读取到的 Master 端的 binlog 的文件名和位置记录到 masterinfo 文件中,以便在下一次读取的时候能够清楚的告诉 Master 从某个 binlog 的哪个位置开始往后的日志内容。 Slave 的 SQL 进程检测到 relaylog 中新增加了内容后,会马上解析 relaylog 的内容成为在 Master 端真实执行时候的那些可执行的内容,并在自身执行。
#查看MySQL的二进制日志是否开启
show variables like ‘%log_bin%’;
 打开文件my.ini,在该文件的
打开文件my.ini,在该文件的 [mysqld] 语句下,添加以下log-bin = mysql-bin。 重启mysql服务,开启二进制日志。
重启mysql服务,开启二进制日志。
Binary Log 操作测试
#插入数据
insert into test values(21,21);
#删除数据
```sql
delete from test where id =10

#查看binlog日志事件
show binlog events in 'mysql-bin.000001';
 查看具体详细信息,可到mysql安装目录下使用
查看具体详细信息,可到mysql安装目录下使用
mysqlbinlog -vv Data/mysql-bin.000001 --start-position=219
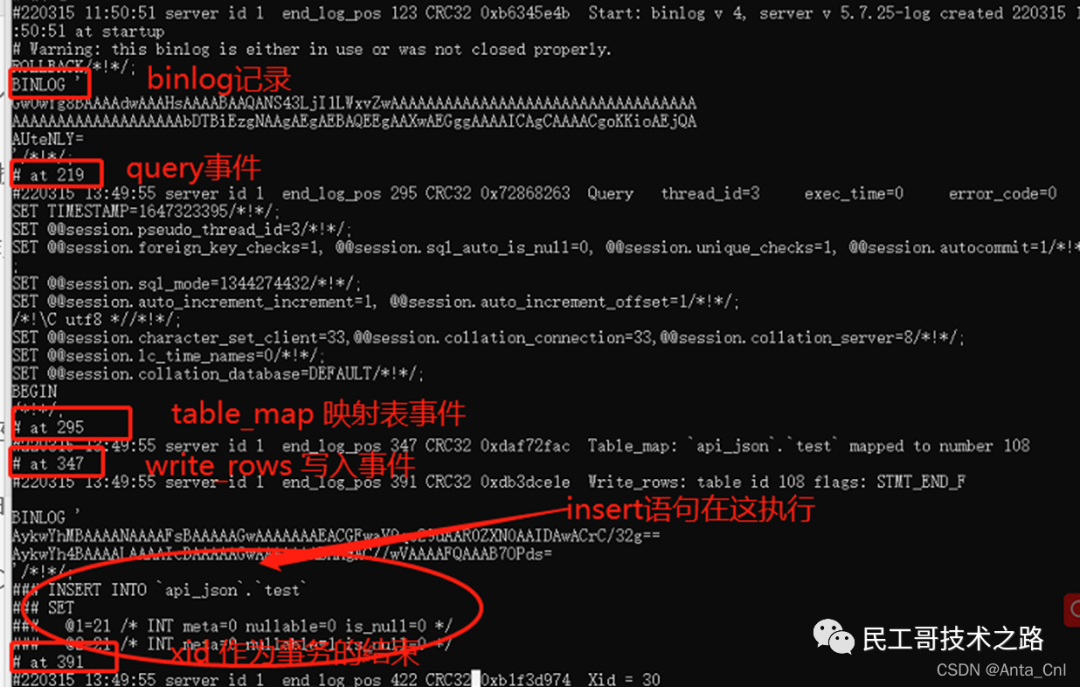
解释一下这几个事件类型:
Format_desc :
#它是binlog文件中的个事件,而且,该事件只会在binlog中出现一次,常指定了MySQL Server的版本,binlog的版本,该binlog文件的创建时间。
Previous_gtids :
#记录该binlog文件之前执行过的所有事务对应的GTID集合,在系统启动时,mysql读取该事件的内容来进行相应的初始化工作。
Gtid :
#全局事务ID 是一个对于已提交事务的全局的编号,随着事务记录到binlog中,用来标识事务,每一个事务都会有一个,GTID 实际上是由 server_uuid + transaction_id 组成。
server_uuid:
#一个mysql实例的标识,每一台mysql实例的server_uuid都是不同的。在mysql次启动时,会自动生成并持久化到auto.cnf文件(存放在mysql的数据目录下)。
transaction_id:
#该实例上已经提交的事务数量,transaction_id是一个从1开始的自增计数,表示在这台mysql实例上执行的第n个事务,随着事务的增加,此id依次递增。

Query:
- 事务开始时,在binlog中记录一个类型为query_event的begin事件。
- statement格式binlog中,具体执行的SQL语句保留在query_event事件中。
- row格式binlog,所有DDL操作以文本的格式记录在query_event事件中。
Xid :
#statement和row格式的binlog,都会添加一个XID_EVENT事件作为事物的结束。该事件记录了该事务的id,崩溃恢复时,根据事务在binlog中的提交情况决定是否提交存储引擎中prepared的事务,一个事务产生的所有event会被GTID_LOG_EVENT和XID_EVENT包住。
Table_map:负责映射需要的表。
Write_rows:负责写入数据。
Delete_rows:负责删除数据。
重做日志(redo log)
为什么需要redo log
我们都知道,事务的四大特性里面有一个是 持久性 ,具体来说就是只要事务提交成功,那么对数据库做的修改就被保存下来了,不可能因为任何原因再回到原来的状态 。
那么 mysql是如何保证持久性的呢?
简单的做法是在每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。但是这么做会有严重的性能问题。主要体现在两个方面:
1.因为 Innodb 是以 页 为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!并且如果每一次提交事务,就把数据从内存写到磁盘的话,这样频繁IO会导致性能很低。
2.一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入性能太差!
因此 mysql 设计了 redo log , 具体来说就是只记录事务对数据页做了哪些修改,这样就能完美地解决性能问题了(相对而言文件更小并且是顺序IO)。
总而言之就是有两个优势:
1.事务提交后不需要每一次都把数据写入磁盘中,先写到redo log日志中,然后写入磁盘。
2.redo log 和写表的区别就在于随机写和顺序写。MySQL 的表数据是随机存储在磁盘中的,而 redo log 是一块固定大小的连续空间。而磁盘顺序写入要比随机写入快几个数量级。
redo log基本概念
redo log 包括两部分:一个是内存中的日志缓冲( redo log buffer ),另一个是磁盘上的日志文件( redo logfile)。
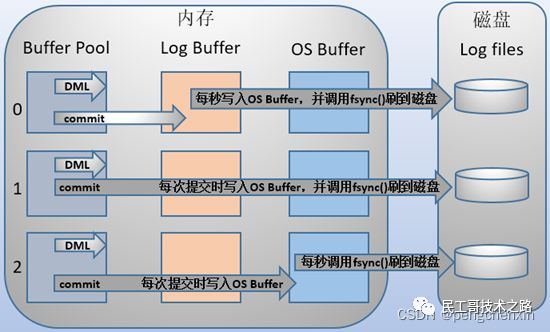
mysql 每执行一条 DML 语句,先将记录写入 redo log buffer,后续某个时间点再一次性将多个操作记录写到 redo log file。这种 先写日志,再写磁盘 的技术就是 MySQL里经常说到的 WAL(Write-Ahead Logging) 技术。
在计算机操作系统中,用户空间( user space )下的缓冲区数据一般情况下是无法直接写入磁盘的,中间必须经过操作系统内核空间( kernel space )缓冲区( OS Buffer )。因此, redo log buffer 写入 redo logfile 实际上是先写入 OS Buffer ,然后再通过系统调用 fsync() 将其刷到 redo log file中,过程如下: mysql 支持三种将 redo log buffer 写入 redo log file 的时机,可以通过
mysql 支持三种将 redo log buffer 写入 redo log file 的时机,可以通过 innodb_flush_log_at_trx_commit 参数配置,各参数值含义如下:
redo log记录形式
前面说过, redo log 实际上记录数据页的变更,而这种变更记录是没必要全部保存,因此 redo log实现上采用了大小固定,循环写入的方式,当写到结尾时,会回到开头循环写日志。如下图: 同时我们很容易得知, 在innodb中,既有redo log 需要刷盘,还有 数据页 也需要刷盘, redo log存在的意义主要就是降低对 数据页 刷盘的要求 ** 。在上图中, write pos 表示 redo log 当前记录的 LSN (逻辑序列号)位置, check point 表示 数据页更改记录 刷盘后对应 redo log 所处的 LSN(逻辑序列号)位置。write pos 到 check point 之间的部分是 redo log 空着的部分,用于记录新的记录;check point 到 write pos 之间是 redo log 待落盘的数据页更改记录。当 write pos追上check point 时,会先推动 check point 向前移动,空出位置再记录新的日志。启动 innodb 的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。因为 redo log记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如 binlog )要快很多。重启innodb 时,首先会检查磁盘中数据页的 LSN ,如果数据页的LSN 小于日志中的 LSN ,则会从 checkpoint 开始恢复。还有一种情况,在宕机前正处于checkpoint 的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的 LSN 大于日志中的 LSN,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
同时我们很容易得知, 在innodb中,既有redo log 需要刷盘,还有 数据页 也需要刷盘, redo log存在的意义主要就是降低对 数据页 刷盘的要求 ** 。在上图中, write pos 表示 redo log 当前记录的 LSN (逻辑序列号)位置, check point 表示 数据页更改记录 刷盘后对应 redo log 所处的 LSN(逻辑序列号)位置。write pos 到 check point 之间的部分是 redo log 空着的部分,用于记录新的记录;check point 到 write pos 之间是 redo log 待落盘的数据页更改记录。当 write pos追上check point 时,会先推动 check point 向前移动,空出位置再记录新的日志。启动 innodb 的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。因为 redo log记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如 binlog )要快很多。重启innodb 时,首先会检查磁盘中数据页的 LSN ,如果数据页的LSN 小于日志中的 LSN ,则会从 checkpoint 开始恢复。还有一种情况,在宕机前正处于checkpoint 的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的 LSN 大于日志中的 LSN,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
中继日志
中继日志用于主从复制架构中的从服务器上,从服务器的 slave 进程从主服务器处获取二进制日志的内容并写入中继日志,然后由 IO 进程读取并执行中继日志中的语句。
#查看中继日志
show variables like '%relay%';
 相关参数解释如下:
相关参数解释如下:
max_relay_log_size
#relay log 允许的大值,如果该值为,则默认值为 max_binlog_size (1G);如果不为,则 max_relay_log_size 则为大的relay_log文件大小。
relay_log
#relay_log 的位置和名称,如果值为空,则默认位置在数据文件的目录。
relay_log_index
#relay_log 索引的位置和名称,记录有几个 relay_log 文件,默认为2个。
relay_log_info_file
#relay-log.info 的位置和名称,relay-log.info 记录 master 主库的 binary_log 的恢复位置和 从库 relay_log 的位置。
relay_log_purge
#是否自动清空中继日志,默认值为1(启用);
relay_log_recovery
#当slave从库宕机后,假如relay-log损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的relay-log,并且重新从master上获取日志,这样就保证了relay-log的完整性。默认情况下该功能是关闭的,将relay_log_recovery的值设置为 1时,可在slave从库上开启该功能,建议开启;
sync_relay_log
#设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay log中继日志里,这样是安全的,因为在崩溃的时候,你多会丢失一个事务,但会造成磁盘的大量I/O;
#设置为时,并不是马上就刷入中继日志里,而是由操作系统决定何时来写入,虽然安全性降低了,但减少了大量的磁盘I/O操作。这个值默认是,可动态修改;
sync_relay_log_info
#这个参数和 sync_relay_log 参数一样。
回滚日志(undo log)
undo log是mysql中比较重要的事务日志之一,顾名思义,undo log是一种用于撤销回退的日志,在事务没提交之前,MySQL会先记录更新前的数据到 undo log日志文件里面,当事务回滚时或者数据库崩溃时,可以利用 undo log来进行回退。
基本概念
undo log有两个作用:提供回滚和多个行版本控制(MVCC)。
在数据修改的时候,不仅记录了redo,还记录了相对应的undo,如果因为某些原因导致事务失败或回滚了,可以借助该undo进行回滚。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。
当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。有时候应用到行版本控制的时候,也是通过undo log来实现的:当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据是什么,从而提供该行版本信息,让用户实现非锁定一致性读取。
undo log是采用段(segment)的方式来记录的,每个undo操作在记录的时候占用一个undo log segment。
另外,undo log也会产生redo log,因为undo log也要实现持久性保护。
undo log 的存储方式
下面以一张图来说明undo log日志里面到底存了哪些信息? innodb存储引擎对undo的管理采用段的方式。
innodb存储引擎对undo的管理采用段的方式。rollback segment称为回滚段,每个回滚段中有 1024 个undo log segment。
在以前老版本,只支持1个rollback segment,这样就只能记录1024个undo log segment。后来MySQL5.5可以支持128个rollback segment,即支持128*1024个undo操作,还可以通过变量 innodb_undo_logs (5.6版本以前该变量是 innodb_rollback_segments )自定义多少个rollback segment,默认值为128。
undo log的工作原理
在更新数据之前,MySQL会提前生成undo log日志,当事务提交的时候,并不会立即删除undo log,因为后面可能需要进行回滚操作,要执行回滚(rollback)操作时,从缓存中读取数据。undo log日志的删除是通过通过后台purge线程进行回收处理的。
同样,通过一张图来理解undo log的工作原理。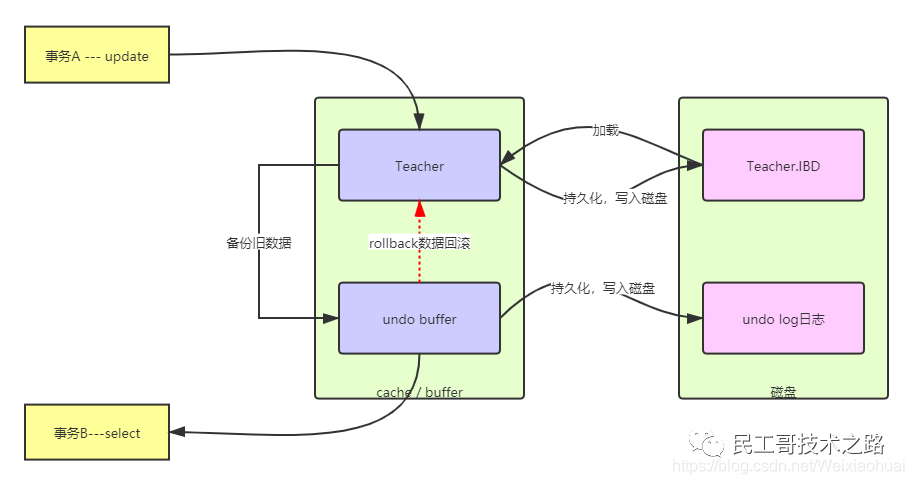 如上图:
如上图:
1、事务A执行update操作,此时事务还没提交,会将数据进行备份到对应的undo buffer,然后由undo buffer持久化到磁盘中的undo log文件中,此时undo log保存了未提交之前的操作日志,接着将操作的数据,也就是Teacher表的数据持久保存到InnoDB的数据文件IBD。 2、此时事务B进行查询操作,直接从undo buffer缓存中进行读取,这时事务A还没提交事务,如果要回滚(rollback)事务,是不读磁盘的,先直接从undo buffer缓存读取。
undo log默认存放在共享表空间中。
[root@xuexi data]# ll /mydata/data/ib*
-rw-rw---- 1 mysql mysql 79691776 Mar 31 01:42 /mydata/data/ibdata1
-rw-rw---- 1 mysql mysql 50331648 Mar 31 01:42 /mydata/data/ib_logfile0
-rw-rw---- 1 mysql mysql 50331648 Mar 31 01:42 /mydata/data/ib_logfile1
如果开启了 innodb_file_per_table ,将放在每个表的.ibd文件中。
在MySQL5.6中,undo的存放位置还可以通过变量 innodb_undo_directory 来自定义存放目录,默认值为"."表示datadir。
默认rollback segment全部写在一个文件中,但可以通过设置变量 innodb_undo_tablespaces 平均分配到多少个文件中。该变量默认值为0,即全部写入一个表空间文件。该变量为静态变量,只能在数据库示例停止状态下修改,如写入配置文件或启动时带上对应参数。但是innodb存储引擎在启动过程中提示,不建议修改为非0的值,如下:
2017-03-31 13:16:00 7f665bfab720 InnoDB: Expected to open 3 undo tablespaces but was able 2017-03-31 13:16:00 7f665bfab720 InnoDB: to find only undo tablespaces. 2017-03-31 13:16:00 7f665bfab720 InnoDB: Set the innodb_undo_tablespaces parameter to the 2017-03-31 13:16:00 7f665bfab720 InnoDB: correct value and retry. _Suggested value is _
和undo log相关的变量
undo相关的变量在MySQL5.6中已经变得很少。如下:它们的意义在上文中已经解释了。
mysql> show variables like "%undo%";
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| innodb_undo_directory | . |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 0 |
+-------------------------+-------+
delete/update操作的内部机制
当事务提交的时候,innodb不会立即删除undo log,因为后续还可能会用到undo log,如隔离级别为repeatable read时,事务读取的都是开启事务时的新提交行版本,只要该事务不结束,该行版本就不能删除,即undo log不能删除。
但是在事务提交的时候,会将该事务对应的undo log放入到删除列表中,未来通过purge来删除。并且提交事务时,还会判断undo log分配的页是否可以重用,如果可以重用,则会分配给后面来的事务,避免为每个独立的事务分配独立的undo log页而浪费存储空间和性能。
通过undo log记录delete和update操作的结果发现:(insert操作无需分析,就是插入行而已)
delete操作实际上不会直接删除,而是将delete对象打上delete flag,标记为删除,终的删除操作是purge线程完成的。 update分为两种情况:update的列是否是主键列。 如果不是主键列,在undo log中直接反向记录是如何update的。即update是直接进行的。 如果是主键列,update分两部执行:先删除该行,再插入一行目标行。
错误日志
用来记录 MySQL 服务器运行过程中的错误信息,默认开启无法关闭。复制环境下,从服务器进程的信息也会被记录进错误日志。
可以使用--log-error=[file_name]来指定mysqld记录的错误日志文件,如果没有指定file_name,则默认的错误日志文件为datadir目录下的hostname.err ,hostname表示当前的主机名。
也可以在MariaDB/MySQL配置文件中的mysqld配置部分,使用log-error指定错误日志的路径。
如果不知道错误日志的位置,可以查看变量log_error来查看。
mysql> show variables like 'log_error';
+---------------+----------------------------------------+
| Variable_name | Value |
+---------------+----------------------------------------+
| log_error | /var/lib/mysql/node1.longshuai.com.err |
+---------------+----------------------------------------+
在MySQL 5.5.7之前,刷新日志操作(如flush logs)会备份旧的错误日志(以_old结尾),并创建一个新的错误日志文件并打开,在MySQL 5.5.7之后,执行刷新日志的操作时,错误日志会关闭并重新打开,如果错误日志不存在,则会先创建。
在MariaDB/MySQL正在运行状态下删除错误日志后,不会自动创建错误日志,只有在刷新日志的时候才会创建一个新的错误日志文件。
以下是MySQL 5.6.35启动的日志信息。
2017-03-29 01:15:14 2362 [Note] Plugin 'FEDERATED' is disabled.
2017-03-29 01:15:14 2362 [Note] InnoDB: Using atomics to ref count buffer pool pages
2017-03-29 01:15:14 2362 [Note] InnoDB: The InnoDB memory heap is disabled
2017-03-29 01:15:14 2362 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2017-03-29 01:15:14 2362 [Note] InnoDB: Memory barrier is not used
2017-03-29 01:15:14 2362 [Note] InnoDB: Compressed tables use zlib 1.2.3
2017-03-29 01:15:14 2362 [Note] InnoDB: Using Linux native AIO
2017-03-29 01:15:14 2362 [Note] InnoDB: Using CPU crc32 instructions
2017-03-29 01:15:14 2362 [Note] InnoDB: Initializing buffer pool, size = 128.0M
2017-03-29 01:15:14 2362 [Note] InnoDB: Completed initialization of buffer pool
2017-03-29 01:15:14 2362 [Note] InnoDB: Highest supported file format is Barracuda.
2017-03-29 01:15:14 2362 [Note] InnoDB: 128 rollback segment(s) are active.
2017-03-29 01:15:14 2362 [Note] InnoDB: Waiting for purge to start
2017-03-29 01:15:14 2362 [Note] InnoDB: 5.6.35 started; log sequence number 3911610
2017-03-29 01:15:14 2362 [Note] Server hostname (bind-address): '*'; port: 3306
2017-03-29 01:15:14 2362 [Note] IPv6 is available.
2017-03-29 01:15:14 2362 [Note] - '::' resolves to '::';
2017-03-29 01:15:14 2362 [Note] Server socket created on IP: '::'.
2017-03-29 01:15:14 2362 [Warning] 'proxies_priv' entry '@ root@xuexi.longshuai.com' ignored in --skip-name-resolve mode.
2017-03-29 01:15:14 2362 [Note] Event Scheduler: Loaded events
2017-03-29 01:15:14 2362 [Note] /usr/local/mysql/bin/mysqld: ready for connections.
Version: '5.6.35' socket: '/mydata/data/mysql.sock' port: 3306 MySQL Community Server (GPL)
一般查询日志
一般查询日志里面记录了数据库执行的所有命令,不管语句是否正确,都会被记录,默认是关闭的(建议关闭)。
使用--general_log={0|1}来决定是否启用一般查询日志,使用--general_log_file=file_name 来指定查询日志的路径。不给定路径时默认的文件名以 hostname.log 命名。
和查询日志有关的变量有:
long_query_time = 10 # 指定慢查询超时时长,超出此时长的属于慢查询,会记录到慢查询日志中
log_output={TABLE|FILE|NONE} # 定义一般查询日志和慢查询日志的输出格式,不指定时默认为file
TABLE表示记录日志到表中,FILE表示记录日志到文件中,NONE表示不记录日志。只要这里指定为NONE,即使开启了一般查询日志和慢查询日志,也都不会有任何记录。
和一般查询日志相关的变量有:
general_log=off # 是否启用一般查询日志,为全局变量,必须在global上修改。
sql_log_off=off # 在session级别控制是否启用一般查询日志,默认为off,即启用
general_log_file=/mydata/data/hostname.log # 默认是库文件路径下主机名加上.log
在MySQL 5.6以前的版本还有一个"log"变量也是决定是否开启一般查询日志的。在5.6版本开始已经废弃了该选项。
首先开启一般查询日志
mysql> set @@global.general_log=1;
[root@xuexi data]# ll *.log
-rw-rw---- 1 mysql mysql 5423 Mar 20 16:29 mysqld.log
-rw-rw---- 1 mysql mysql 262 Mar 29 09:31 xuexi.log
执行几个语句。
mysql> select host,user from mysql.user;
mysql> show variables like "%error%";
mysql> insert into ttt values(233);
mysql> create table tt(id int);
mysql> set @a:=3;
查看一般查询日志的内容。
[root@xuexi data]# cat xuexi.log
/usr/local/mysql/bin/mysqld, Version: 5.6.35-log (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /mydata/data/mysql.sock
Time Id Command Argument
180421 20:04:41 13 Query select user,host from mysql.user
180421 20:06:06 13 Query show variables like "%error%"
180421 20:07:28 13 Query insert into ttt values(233)
180421 20:11:47 13 Query create table tt(id int)
180421 20:12:29 13 Query set @a:=3
由此可知,一般查询日志查询的不止是select语句,几乎所有的语句都会记录。
慢查询日志
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的SQL语句,具体是指运行时间超过 long_query_time 值的SQL,这样的SQL则会被记录到慢查询日志中。long_query_time 的默认值为10,意思是运行10S以上的SQL语句。
默认情况下,MySQL数据库并没有开启慢查询日志,需要我们手动来设置这个参数。当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。
#查看慢查询日志是否开启
show variables like 'slow_query%'
 慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
#默认查询超过几秒才记录(一般情况下,默认是10秒)
show variables like 'long_query_time';

#测试执行一条慢查询语句
select sleep(11);
 这里可以看出是那个sql以及查询时间。
这里可以看出是那个sql以及查询时间。
慢查询日志内容解读:
Query_time: duration
#语句执行时间,以秒为单位
Lock_time: duration
#获取锁的时间(以秒为单位)
Rows_sent: N
#发送到客户端的行数
Rows_examined:
#服务器层检查的行数(不包括存储引擎内部的任何处理)
Set timestamp:
#语句包含指示慢语句何时被记录的时间戳(在语句完成执行后发生)
#开启慢查询日志中包含慢管理语句( ALTER TABLE、 ANALYZE TABLE、 CHECK TABLE、 CREATE INDEX、 DROP INDEX、 OPTIMIZE TABLE和 REPAIR TABLE)
show VARIABLES like '%log_slow_admin_statements%'
set global log_slow_admin_statements = on
#写入慢查询日志的语句中包含不使用索引进行行查找的查询
show VARIABLES like '%log_queries_not_using_indexes%'
set global log_queries_not_using_indexes = on

#测试一下使用索引和不使用索引谁会生成慢查询日志?
select age from test; //age查询不使用索引
select id from test; //id查询使用索引

参考链接如下:cnblogs.com/f-ck-need-u/p/9010872.html blog.csdn.net/u013487071/article/details/123541679 blog.csdn.net/pengchenxin/article/details/123627046
原文链接:https://mp.weixin.qq.com/s/GWfmapsxP86osx6e2hCDhA
