kafka的基础架构
Apache Kafka是一个开放源代码的分布式事件流平台,成千上万的公司使用它来实现高性能数据管道,流分析,数据集成和关键任务应用程序
kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于日志分析,大数据实时处理领域
| kafka基础架构概述
有关kakfa相关的术语如下所示:
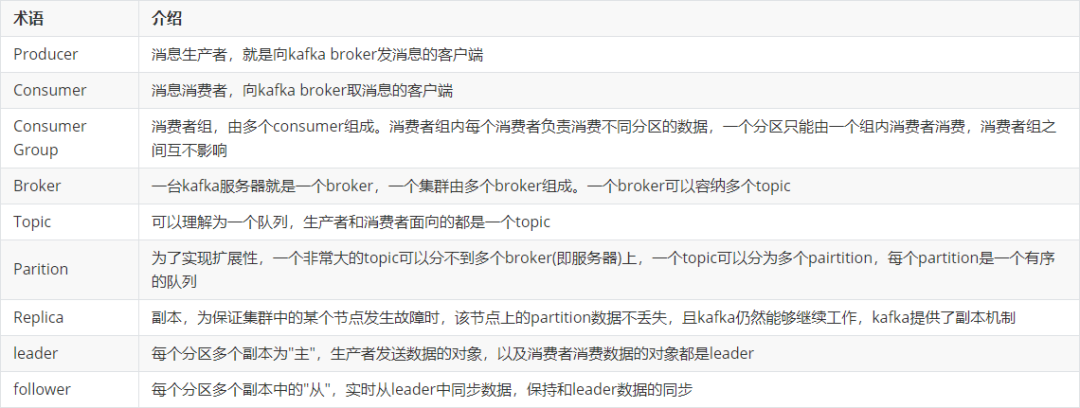
kafka的架构图如下所示:
kafka高效读写数据的底层原理
| 顺序写磁盘
kafka的producer生产数据,将数据顺序写入磁盘,从而优化的磁盘的写入效率
官方有数据表明,同样的写能到600M/s,而随机写只有100K/s。这与磁盘的机械结构有关,顺序写之所以快,是因为节省去了大量磁头寻址时间
| 零拷贝技术
如下图所示,DMA的英文拼写是"Direct Memory Access",汉语的意思就是直接内存访问,是一种不经过CPU而直接从内存存取数据的数据交换模式
温馨提示:
JDK NIO零拷贝实现分为两种方案,即mmap和sendFile
1>.mmap比较适合小文件读写,对文件大小有限制,一般在1.5GB~2.0GB之间;
2>.sendFile比较适合大文件传输,可以利用DMA方式,减少CPU拷贝;
下图中的万兆网卡我指的是服务器的硬件网卡,但也有人喜欢使用专业术语Network Interface Controller(简称"NIC")来进行说明

| 异步刷盘
kafka并不会将数据直接写入到磁盘,而是写入OS的cache,而后由OS实现数据的写入
这样做的好处就是减少kafka源代码更多关于兼容各种厂商类型的磁盘驱动,而是交给更擅长和硬件打交道的操作系统来完成和磁盘的交互
不得不说异步刷盘的确提高了效率,但也意味着带来了数据丢失的风险,假设数据已经写入到OS的cache page,但数据并未落盘之前服务器断电,很可能会导致数据的丢失
| 分布式集群
我们知道topic可以被划分多个partition,而partition可以分布在kafka集群的各个broker实例上
分布式充分利用了各个broker节点的性能,包括但不限于CPU,内存,磁盘,网卡等
kafka事务
| kafka事务概述
kafka从0.11版本开始引入了事务支持
事务可以保证kafka在Exactly Once语义的基础上,生产和消费可以跨分区的会话,要么全部成功,要么全部失败
| producer事务
为了实现跨分区跨会话的事务,需要引入一个全局的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID
为了管理Transaction,Kafka引入了新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态
Transaction Coordinator还负责所有写入kafka的内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以的得到恢复,从而继续进行
| Consumer事务
上述事务机制主要从Producer方面考虑,对于Consumer而言,事务的保证就会相对较弱,尤其是无法保证Commit的信息被消费
这是由于Consumer可以通过offset访问任意信息,而且不同的Segment File生命周期不同,同一事物的消费可能会出现重启后被删除的情况
部署单机版的kafka环境
| 下载Kafka软件并解压到指定目录
wget https://archive.apache.org/dist/kafka/3.1.1/kafka_2.12-3.1.1.tgz
tar xf kafka_2.12-3.1.1.tgz -C /oldboyedu/softwares/

| 创建符号连接并配置环境变量
ln -sv /oldboyedu/softwares/kafka_2.12-3.1.1 kafka
# 配置环境变量
cat >/etc/profile.d/kafka.sh<<EOF
#!/bin/bash
KAFKA_HOME="/oldboyedu/softwares/kafka"
PATH=\$PATH:\$KAFKA_HOME/bin
EOF
# 变量生效
source /etc/profile.d/kafka.sh

| kafka的配置文件简介
查看kafka的配置文件目录
ls -l /oldboyedu/softwares/kafka/config/


查看broker默认的配置文件
# egrep -v "^#|^$" /oldboyedu/softwares/kafka/config/server.properties
broker.id=0
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0

核心基础配置如下:
broker.id
log.dirs
zookeeper.connect

| 修改kafka101实例的配置文件
# grep ^[a-Z] /oldboyedu/softwares/kafka/config/server.properties
broker.id=101
...
log.dirs=/oldboyedu/data/kafka
...
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181
...

温馨提示:
只需修改上述3个参数即可
| 修改broker的堆内存大小
# grep KAFKA_HEAP_OPTS /oldboyedu/softwares/kafka/bin/kafka-server-start.sh
...
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
# export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export KAFKA_HEAP_OPTS="-Xmx256M -Xms256M"
...

| 启动kafka集群
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
ss -ntl | grep 9092


| 查看zookeeper中有关kafka的信息
使用 zkWeb 服务通过web页面查看zookeeper,并添加zookeeper服务器配置
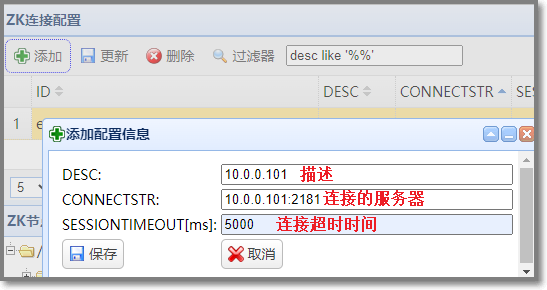
查看当前zookeeper服务器中的kafka节点

部署集群版的kafka
| 将kafka部署在其他服务器上
# 发送kafka到其它服务器上
scp -rp /oldboyedu/softwares/kafka root@10.0.0.102:/oldboyedu/softwares/
scp -rp /oldboyedu/softwares/kafka root@10.0.0.103:/oldboyedu/softwares/
# 发送kafka环境变量文件到其它服务器上
scp -rp /etc/profile.d/kafka.sh root@10.0.0.102:/etc/profile.d/kafka.sh
scp -rp /etc/profile.d/kafka.sh root@10.0.0.103:/etc/profile.d/kafka.sh

| 修改相应节点的配置文件
在102节点上
# grep ^broker /oldboyedu/softwares/kafka/config/server.properties
broker.id=102
在103节点上
# grep ^broker /oldboyedu/softwares/kafka/config/server.properties
broker.id=103

| 编写kafka集群管理脚本
# 安装ansible
yum -y install ansible
# 配置ansible
cat >/etc/ansible/hosts<<EOF
[kafka]
10.0.0.101
10.0.0.102
10.0.0.103
EOF
# 编写启动脚本
cat >/oldboyedu/softwares/kafka/bin/manager-kafka.sh<<EOF
#!/bin/bash
#判断用户是否传参
if [ \$# -ne 1 ];then
echo "参数,用法为: \$0 {start|stop}"
exit
fi
#获取用户输入的命令
cmd=\$1
for (( i=101 ; i<=103 ; i++ )) ; do
tput setaf 2
echo "****** zk\${i}.oldboyedu.com ---> [`basename \$0`: \$cmd ] ******"
tput setaf 9
case \$cmd in
start)
ssh zk\${i}.oldboyedu.com "source /etc/profile.d/kafka.sh; kafka-server-start.sh -daemon /oldboyedu/softwares/kafka/config/server.properties"
echo zk\${i}.oldboyedu.com "服务已启动"
;;
stop)
ssh zk\${i}.oldboyedu.com "source /etc/profile.d/kafka.sh; kafka-server-stop.sh"
echo zk\${i}.oldboyedu.com "服务已停止"
;;
status)
ansible kafka -m shell -a 'jps'
exit
;;
*)
echo "参数,用法为: $0 {start|stop|status}"
exit
;;
esac
done
EOF
# 为脚本添加执行权限
chmod +x /oldboyedu/softwares/kafka/bin/manager-kafka.sh

| 启动kafka集群
# 使用kafka启动脚本来启动kafka集群
manager-kafka.sh status
manager-kafka.sh start
manager-kafka.sh status


| 使用zkWeb工具查看kafka在zookeeper存储的数据信息
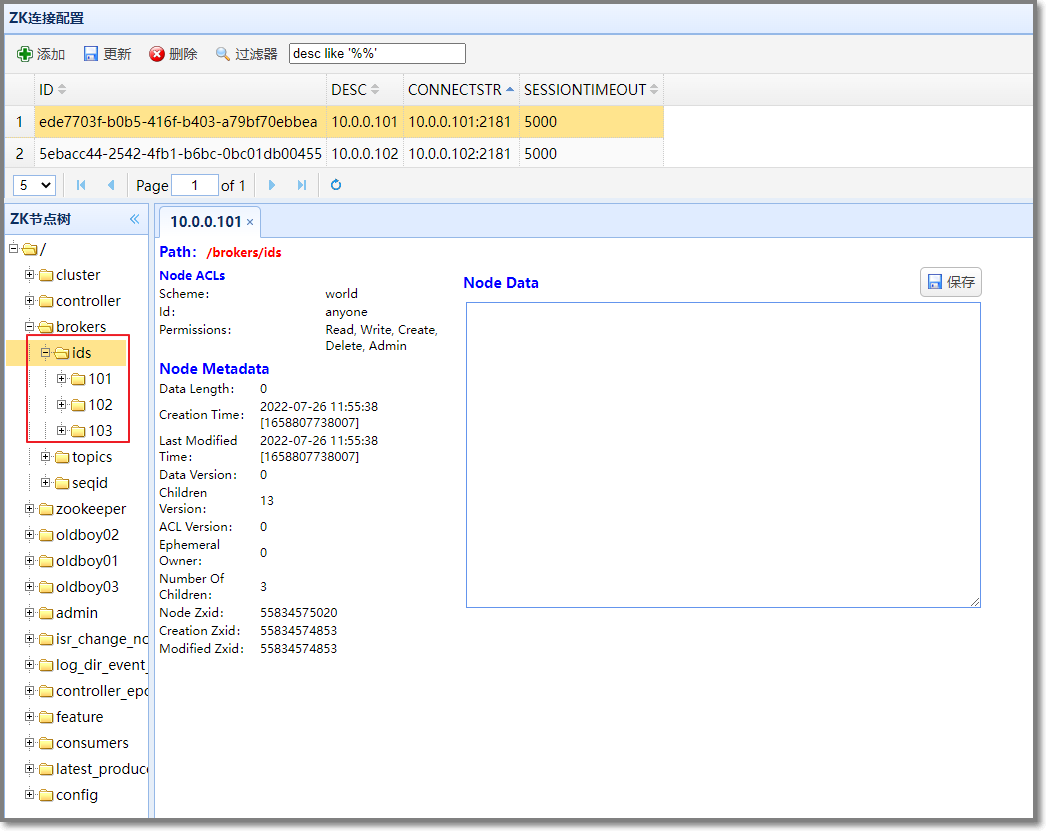
相关znode功能说明如下:

kafka集群topic管理
| 查看现有的topic名称
kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --list

温馨提示:
-
我们可以基于"--zookeeper"指令去zookeeper查询现有的topic信息;
我们也可以基于"--bootstrap-server"指令去kafka broker查询现有的topic信息,官方推荐使用"--bootstrap-server"的方式去管理topic
| 创建topic
# 创建topic
# 注意,创建的副本数必须小于等于集群的数量!
kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --create --topic demo2022 --partitions 2 --replication-factor 3
# 查看创建结果
kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --list

温馨提示:


| 查看某个topic的详细信息
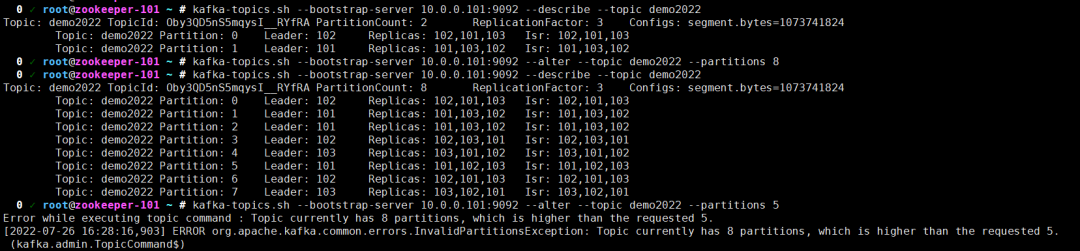
kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --describe --topic demo2022

温馨提示:
如果不使用"--topic"指定topic的名称,则默认查看所有的topic信息哟

| 修改topic的信息
# 修改topic的信息
kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --alter --topic demo2022 --partitions 8
# 查看topic的详细信息
kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --describe --topic demo2022
# 将分区数设置为5会失败,因为分区数只能扩容,无法缩容!
kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --alter --topic demo2022 --partitions 5

| 删除topic
kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --delete --topic demo2022
kafka-topics.sh --bootstrap-server 10.0.0.101:9092 --list


kafka集群生产者管理
| 创建一个生产者往topic写入数据
kafka-console-producer.sh --topic myNginx --broker-list 10.0.0.101:9092


温馨提示:
生产者创建成功后,我们可以就手动自定义写入测试数据,而后开启一个消费者进行数据消费,如果能正常获取数据,则说明集群启动是正常运行的
kafka集群消费者管理
| 从头开始消费数据
kafka-console-consumer.sh --topic myNginx --bootstrap-server 10.0.0.101:9092 --from-beginning

我们可以不使用"--from-beginning"参数,则有可能生产者要比消费者先启动一段时间,而且也将数据写入到kafka集群中了,但如果我们不想要在消费者启动时之前的数据可以不加该参数,如果使用该参数则表示从头进行消费
kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --list


总结
在本教程中,我们通过一些示例学习了如何去部署kafka集群和对kafka的基础使用
感谢您的阅读,由于文档整理较费时费力,难免会有疏漏和不妥当地方,敬请谅解
原文链接:https://mp.weixin.qq.com/s/ds6CVT6b208py0TEDYhinA
