原文 | Nikola M. Zivkovic
翻译 | 郑子铭
在之前的几篇文章中,我们探索了一些基本的机器学习算法。到目前为止,我们介绍了一些简单的回归算法,分类 算法。我们使用 ML.NET 实现和应用这些算法。到目前为止,我们探索了使用监督学习的算法。这意味着我们始终拥有用于训练机器学习模型的输入和预期输出数据。在这种类型的学习中,训练集包含输入和期望的输出。通过这种方式,算法可以检查其计算出的输出是否与所需输出相同,并据此采取适当的措施。
本文涵盖的主题是:
- 聚类直觉
- 数据集和先决条件
- K-均值聚类
- 其他类型的聚类
- 使用 ML.NET 实现
- 肘法
1.聚类直觉
然而,在现实生活中,我们往往并没有同时拥有输入数据和输出数据,而只有输入数据。这意味着算法本身需要计算输入样本之间的联系。为此,我们使用无监督学习。在无监督学习中,训练集只包含输入。就像我们用无监督学习解决监督学习的回归和分类问题一样,我们解决聚类问题。该技术试图识别相似的输入并将它们归类,即。它聚集数据。一般来说,目标是检测隐藏的模式在数据中,并将它们分组到集群中。这意味着具有某些共享属性的样本将归为一组——集群。
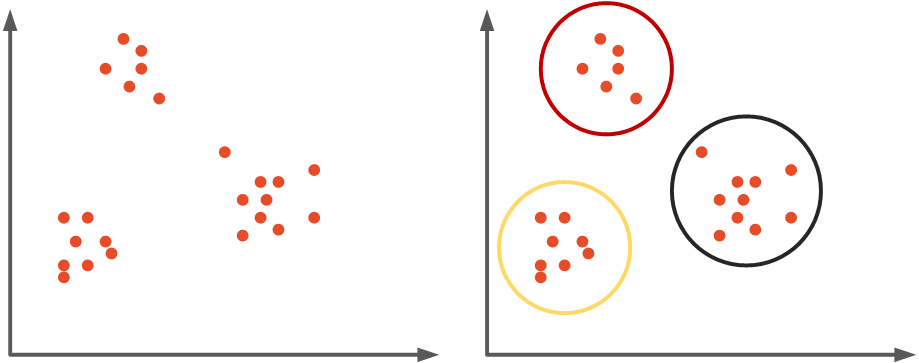
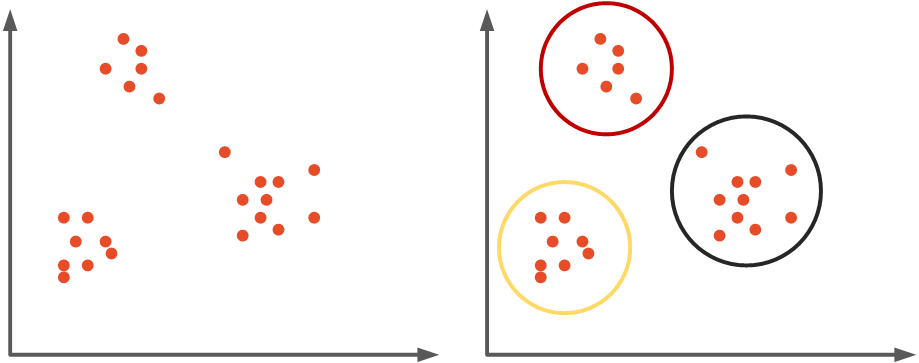
聚类算法有很多种,在本文中我们重点介绍 K-Means聚类,因为该算法在 ML.NET 中受支持。然而,我们将探索一些其他类型的聚类,如 凝聚聚类和DBSCAN,但重点仍然是 K-Means。
2. 数据集和先决条件
我们在本文中使用的数据来自PalmerPenguins数据集。该数据集近作为的鸢尾花数据集的替代品被引入。它是由 Kristen Gorman 博士和南极洲 LTER 帕尔默站创建的。您可以在此处或通过 Kaggle 获取此数据集。该数据集本质上由两个数据集组成,每个数据集包含 344 只企鹅的数据。就像在 Iris 数据集中一样,有 3 种不同种类的企鹅来自帕默群岛的 3 个岛屿。此外,这些数据集包含每个物种的culmen维度。culmen 是鸟嘴的上脊。在简化的企鹅数据中,culmen length 和 depth 被重命名为变量culmen_length_mm和culmen_depth_mm.
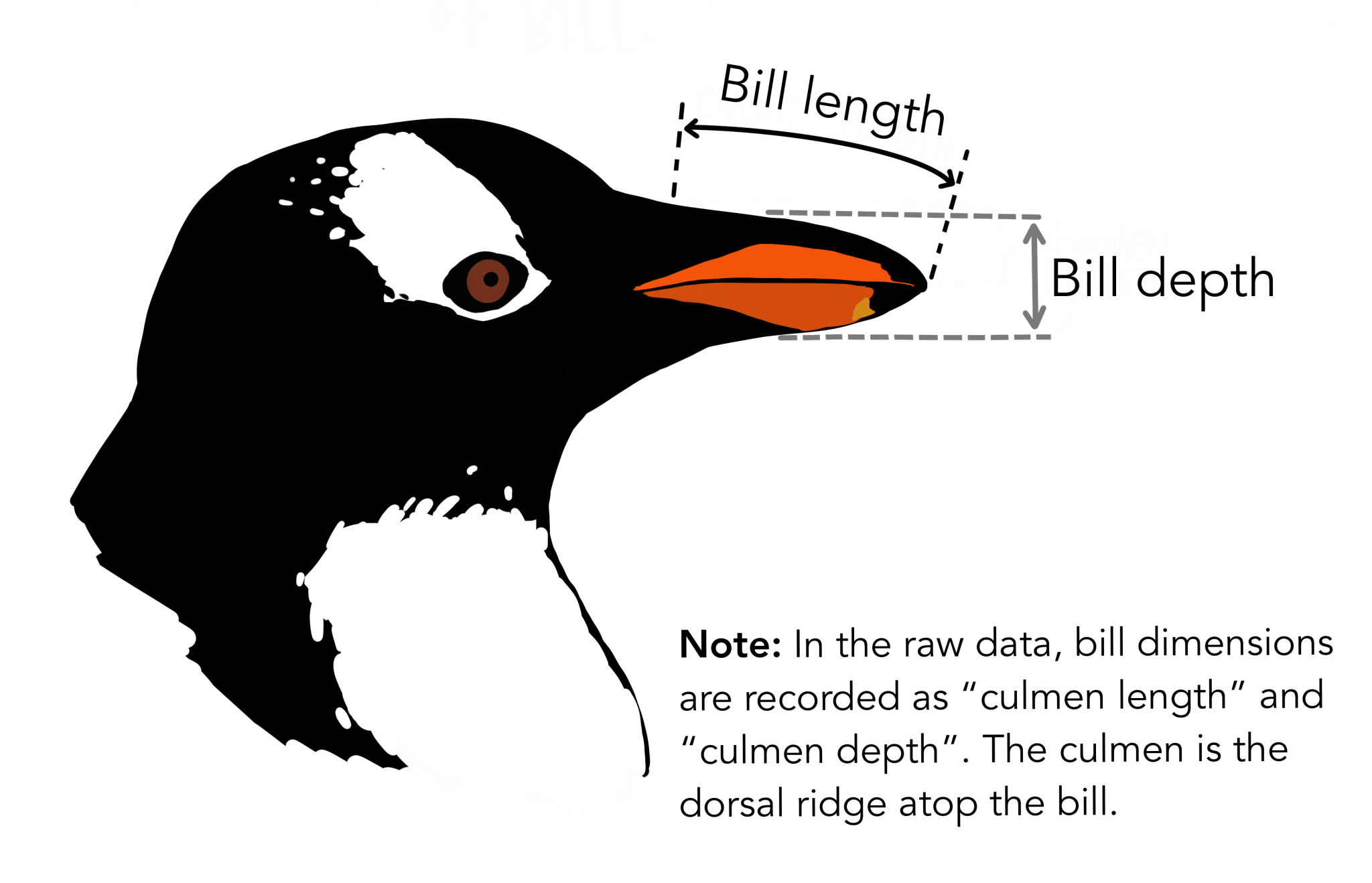
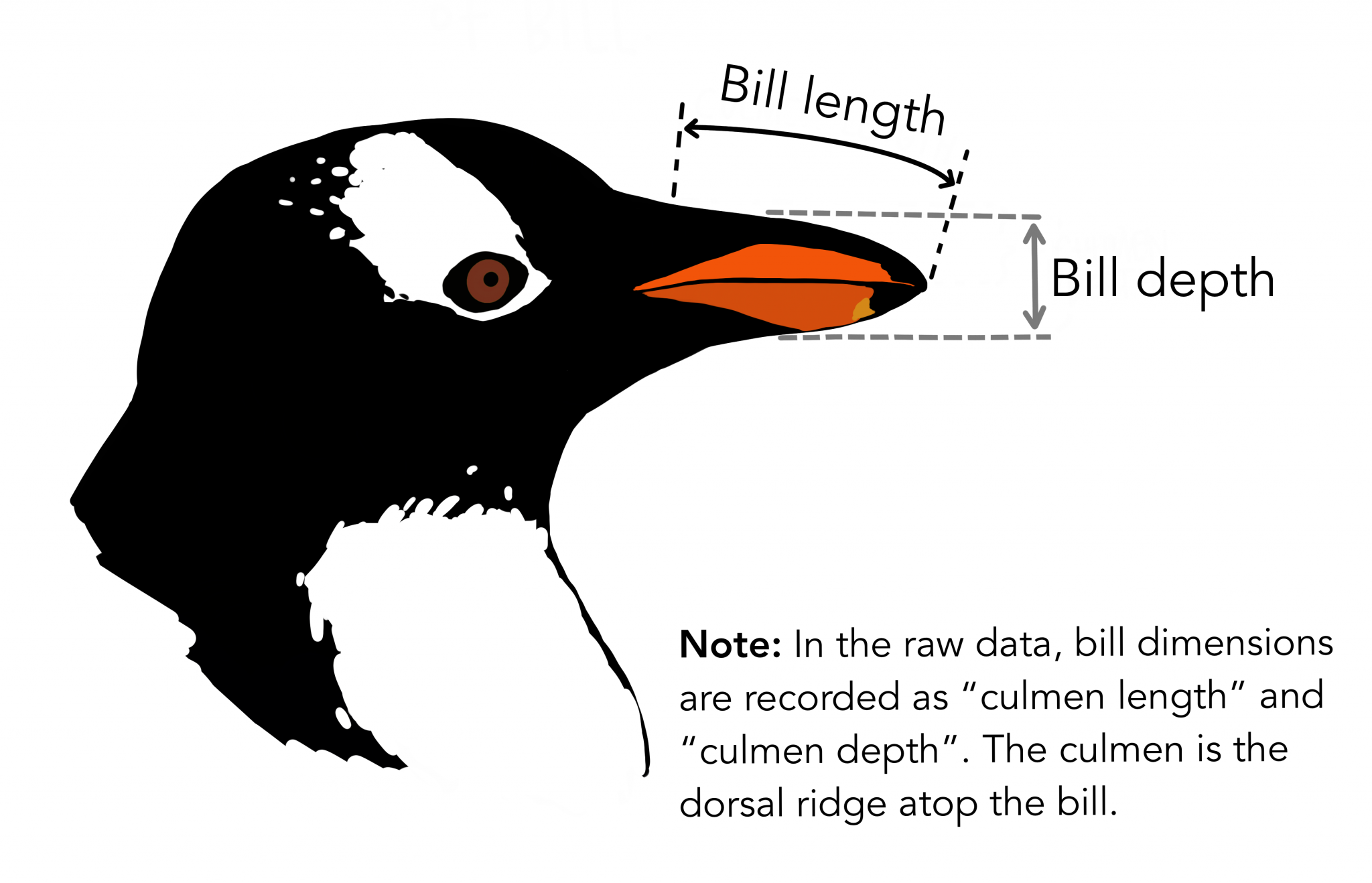
数据本身并不太复杂。本质上,它只是表格数据:


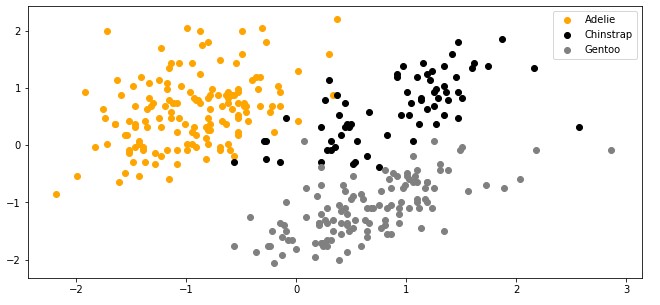
请注意,在本教程中,我们忽略了 物种特征。这是因为我们执行无监督学习,即。我们不需要样本的预期输出值。我们希望我们的算法能够自己解决这个问题。这是我们绘制数据时数据的样子:

这里提供的实现是用C#完成的,我们使用新的 .NET 5。所以请确保你已经安装了这个 SDK。如果您使用的是Visual Studio,则它随版本 16.8.3 一起提供。另外,请确保您已安装以下软件包:
Install-Package Microsoft.ML
您可以使用 Visual Studio 的 Manage NuGetPackage 选项做类似的事情:
如果您需要了解使用 ML.NET 进行机器学习的基础知识,请查看这篇文章。
3. K-均值聚类
K-Means是流行的聚类算法之一。当您开始试验未标记的数据时,它是一个。正如算法名称所示,该算法将n 个数据点分组为K个簇。该算法可以分为几个阶段:
- 在阶段,我们需要设置超参数 k。这表示K-Means 聚类完成后将创建的聚类或组的数量。
- 在特征空间中选取K 个随机向量。这些向量称为质心。这些向量在训练过程中会发生变化,目标是将它们放入每个集群的“中心”。
- 从每个输入样本x到每个质心c 的距离是使用某种度量来计算的,例如欧氏距离。近的质心被分配给数据集中的每个样本。基本上,我们在这个阶段创建集群。
- 对于每个簇,使用分配给它的样本计算平均特征向量。该值被视为集群的新质心。
- 重复步骤 2-4 进行固定次数的迭代或直到质心不改变,以先到者为准。
从数学上讲,每个样本x都根据以下条件分配到一个集群:


其中c ᵢ 是簇i的质心,D是使用以下公式计算的欧氏距离:
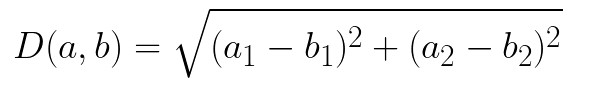

为了从聚类点组中找到新的质心,我们使用公式:
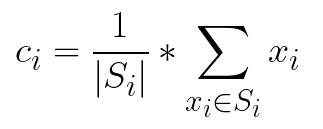
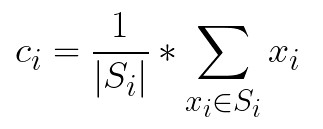
正如我们已经提到的超参数k,即。集群的数量,必须手动调整。这很烦人。在本教程的后面,我们将考虑一种选择正确数量的聚类的技术。但是,让我们探索 ML.NET 尚不支持的一些其他类型的集群。
4. 其他类型的聚类
4.1 凝聚聚类
正如我们所看到的,使用K-Means的大挑战之一是我们需要事先确定 集群的数量。另一个挑战是K-Means试图使集群大小相同。这些挑战可以通过其他算法解决,例如Hierarchical Clustering。通常,每种层次聚类方法都首先将所有样本放入单独的单样本簇中。然后基于一些相似性度量,将样本或簇合并在一起,直到所有样本都被放入一个簇中。这意味着我们正在构建层次结构集群,因此得名。在本文中,我们探讨了凝聚聚类,它是一种特定类型的层次聚类。它用于合并集群的度量是距离,即。它根据质心之间的距离合并近的一对集群,并重复此步骤,直到只剩下一个集群。为此,使用了邻近矩阵。该矩阵存储每个点之间的距离。
让我们把它分成几个步骤:
- 每个点都存储在自己的集群中
- 计算邻近度矩阵
- 检测并合并近的点。它们是簇,计算质心。
- 使用创建的集群的质心更新邻近矩阵。
- 重复步骤 3 和 4,直到创建一个集群。
这时你可能会问自己,这对我们决定集群的数量有什么帮助?为此,我们利用了一个很棒的概念——树状图。这是一个树状图,记录了训练过程中发生的所有合并。因此,每次我们合并两个点或聚类时,都会将其存储在树状图中。这是一个例子:
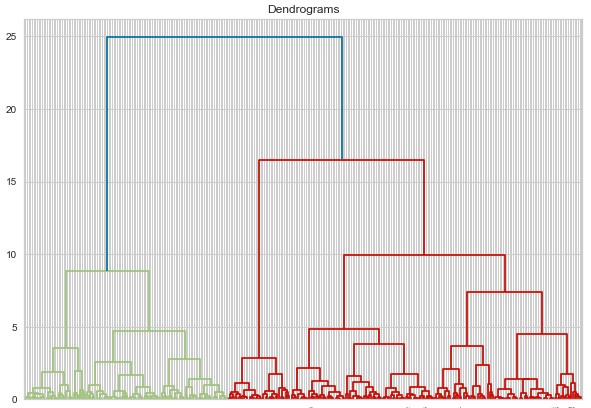
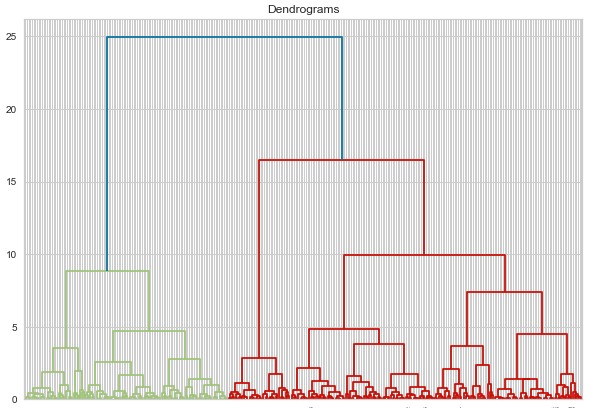
我们在看什么?那么,在 x 轴上我们有数据集中的所有点,而在 y 轴上我们有这些点之间的距离。每次合并点或集群时,都用水平线表示。垂直线表示合并点/簇之间的距离。树状图中较长的垂直线表示簇之间的距离较大。在下一步中,我们需要设置一个阈值距离并在此图像中绘制一条水平线。通常,我们尝试以切割高垂直线的方式设置阈值。在我们的示例中,我们将其设置为 15。这是如何完成的:
4.2 数据库扫描
与基于质心的算法K-Means和Hierarchical Clustering不同,DBSCAN 是一种基于密度的算法。实际上,这意味着您无需确定需要多少个集群。我们在Hierarchical clustering中看到了这一点,但DBSCAN将其提升到了另一个层次。我们没有定义超参数k ,而是为距离ε 和每个簇的样本数 – n定义了两个超参数。让我们把它分成几步,它会更清楚:
- 首先,我们将随机样本x分配给个集群。
- 我们计算有多少样本与样本x的距离小于或等于ε。如果此类样本的数量大于或等于n,我们将它们添加到集群中。
- 我们观察集群的每个新成员并为他们执行步骤 2,即。我们计算样本ε 区域内的样本数量,如果该数量大于n,我们将它们添加到集群中。我们递归地重复这个过程,直到没有更多的样本可以放入其中。
- 从 1 到 3 的步骤用于新的随机非聚类样本。
- 像这样重复该过程,直到所有样本都被聚类或标记为异常值。
这种方法的主要优点是集群具有不同的随机形状。基于质心的算法总是创建具有超球体形状的簇。这就是DBSCAN对某些数据特别有用的原因。当然,主要问题是为ε 和n选择佳值。此问题已通过称为HDBSCAN的该算法的变体进行了优化,即。高性能 DBSCAN。该算法消除了ε 超参数的使用,但是,该算法超出了本教程的范围。
5. 使用 ML.NET 实现
正如我们提到的,ML.NET 仅支持 K-Means 聚类。但是,我们将以一种我们期望 Microsoft 的人员提供其他类型的集群的方式来制作我们的解决方案。这就是为什么我们的解决方案可能看起来设计过度,但是,由于未来的灵活性,我们已经这样做了。
5.1 高层架构
在深入研究ML.NET实现之前,让我们考虑一下该实现的体系结构。通常,我们希望构建一个可以使用ML.NET将来可能包含的新聚类算法轻松扩展的解决方案。考虑到这一点,我们创建解决方案的文件夹结构,如下所示:
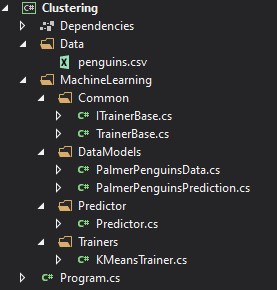

Data文件夹包含带有输入数据的 .csv,MachineLearning文件夹包含我们的算法工作所需的一切。架构概述可以这样表示:
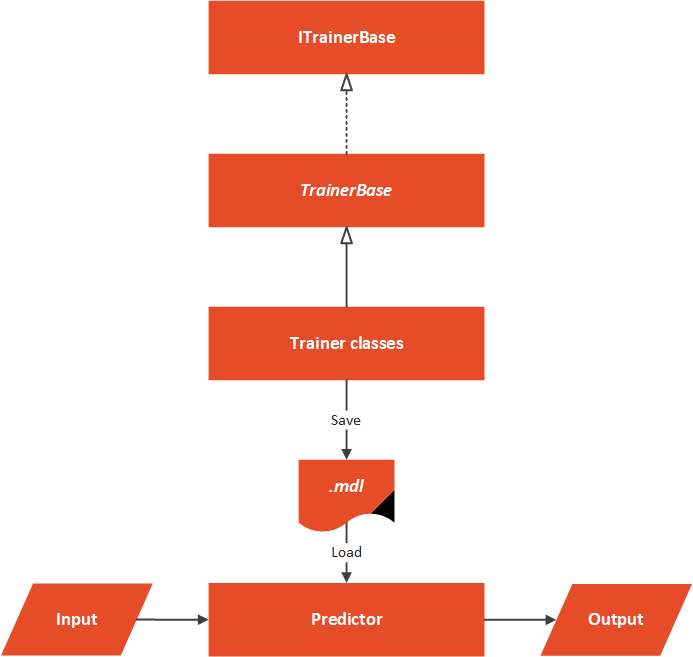

在这个解决方案的核心,我们有一个抽象的TrainerBase 类。此类位于Common文件夹中,其主要目标是标准化整个过程的完成方式。在这个类中,我们 处理数据并执行 特征工程。该类还负责 训练 机器学习算法。实现此抽象类的类位于Trainers文件夹中。在这种特殊情况下,我们只有一个类这样做。这里我们使用ML.NET K-Means 算法。曾经的微软 添加新算法,我们可以用新类扩展这个文件夹。这些类定义了应该使用哪种算法。在这种特殊情况下,我们只有一个Predictor位于Predictor文件夹中。
5.2 数据模型
为了从数据集中加载数据并将其与ML.NET 算法一起使用,我们需要实现将要对该数据建模的类。在数据文件夹中可以找到两个文件:PalmerPenguinData和PricePalmerPenguinPredictions。PalmerPenguinData类对输入数据建模,如下所示:
using Microsoft.ML.Data;
namespace Clustering.MachineLearning.DataModels
{
/// <summary>
/// Models Palmer Penguins Binary Data.
/// </summary>
public class PalmerPenguinsData
{
[LoadColumn(1)]
public string Island { get; set; }
[LoadColumn(2)]
public float CulmenLength { get; set; }
[LoadColumn(3)]
public float CulmenDepth { get; set; }
[LoadColumn(4)]
public float FliperLength { get; set; }
[LoadColumn(5)]
public float BodyMass { get; set; }
[LoadColumn(6)]
public string Sex { get; set; }
}
}
请注意,我们跳过了代表企鹅类的个类的加载。我们这样做是因为我们想进行无监督学习。意思是,我们在训练过程中不使用 物种列。
PricePalmerPenguinPredictions类模拟 输出数据:
using Microsoft.ML.Data;
namespace Clustering.MachineLearning.DataModels
{
/// <summary>
/// Models Palmer Penguins Binary Prediction.
/// </summary>
public class PalmerPenguinsPrediction
{
[ColumnName("PredictedLabel")]
public uint PredictedClusterId;
[ColumnName("Score")]
public float[] Distances;
}
}
5.3 TrainerBase 和 ITrainerBase
正如我们提到的,这个类是这个实现的核心。本质上,它有两个部分。个是描述这个类的接口,另一个是需要用具体实现覆盖的抽象类,但是它实现了接口方法。这是ITrainerBase接口:
using Microsoft.ML.Data;
namespace Clustering.MachineLearning.Common
{
public interface ITrainerBase
{
string Name { get; }
void Fit(string trainingFileName);
ClusteringMetrics Evaluate();
void Save();
}
}
TrainerBase类 实现了这个接口。然而,它是抽象的,因为我们想要注入特定的算法:
using Clustering.MachineLearning.DataModels;
using Microsoft.ML;
using Microsoft.ML.Calibrators;
using Microsoft.ML.Data;
using Microsoft.ML.Trainers;
using Microsoft.ML.Transforms;
using System;
using System.IO;
namespace Clustering.MachineLearning.Common
{
/// <summary>
/// Base class for Trainers.
/// This class exposes methods for training, evaluating and saving ML Models.
/// Classes that inherit this class need to assing concrete model and name.
/// </summary>
public abstract class TrainerBase<TParameters> : ITrainerBase
where TParameters : class
{
public string Name { get; protected set; }
protected static string ModelPath => Path.Combine(AppContext.BaseDirectory, "cluster.mdl");
protected readonly MLContext MlContext;
protected DataOperationsCatalog.TrainTestData _dataSplit;
protected ITrainerEstimator<ClusteringPredictionTransformer<TParameters>, TParameters>
_model;
protected ITransformer _trainedModel;
protected TrainerBase()
{
MlContext = new MLContext(111);
}
/// <summary>
/// Train model on defined data.
/// </summary>
/// <param name="trainingFileName"></param>
public void Fit(string trainingFileName)
{
if (!File.Exists(trainingFileName))
{
throw new FileNotFoundException($"File {trainingFileName} doesn't exist.");
}
_dataSplit = LoadAndPrepareData(trainingFileName);
var dataProcessPipeline = BuildDataProcessingPipeline();
var trainingPipeline = dataProcessPipeline
.Append(_model);
_trainedModel = trainingPipeline.Fit(_dataSplit.TrainSet);
}
/// <summary>
/// Evaluate trained model.
/// </summary>
/// <returns>Metrics object which contain information about model performance.</returns>
public ClusteringMetrics Evaluate()
{
var testSetTransform = _trainedModel.Transform(_dataSplit.TestSet);
return MlContext.Clustering.Evaluate(
data: testSetTransform,
labelColumnName: "PredictedLabel",
scoreColumnName: "Score",
featureColumnName: "Features");
}
/// <summary>
/// Save Model in the file.
/// </summary>
public void Save()
{
MlContext.Model.Save(_trainedModel, _dataSplit.TrainSet.Schema, ModelPath);
}
/// <summary>
/// Feature engeneering and data pre-processing.
/// </summary>
/// <returns>Data Processing Pipeline.</returns>
private EstimatorChain<ColumnConcatenatingTransformer> BuildDataProcessingPipeline()
{
var dataProcessPipeline =
MlContext.Transforms.Text
.FeaturizeText(inputColumnName: "Sex", outputColumnName: "SexFeaturized")
.Append(MlContext.Transforms.Text
.FeaturizeText(inputColumnName: "Island", outputColumnName: "IslandFeaturized"))
.Append(MlContext.Transforms.Concatenate("Features",
"IslandFeaturized",
nameof(PalmerPenguinsData.CulmenLength),
nameof(PalmerPenguinsData.CulmenDepth),
nameof(PalmerPenguinsData.BodyMass),
nameof(PalmerPenguinsData.FliperLength),
"SexFeaturized"
))
.AppendCacheCheckpoint(MlContext);
return dataProcessPipeline;
}
private DataOperationsCatalog.TrainTestData LoadAndPrepareData(string trainingFileName)
{
var trainingDataView = MlContext.Data.LoadFromTextFile<PalmerPenguinsData>(
trainingFileName,
hasHeader: true,
separatorChar: ',');
return MlContext.Data.TrainTestSplit(trainingDataView, testFraction: 0.3);
}
}
}
那是一个大类。它控制着整个过程。让我们把它分开,看看它到底是什么。首先我们观察一下这个类的字段和属性:
public string Name { get; protected set; }
protected static string ModelPath => Path.Combine(AppContext.BaseDirectory, "cluster.mdl");
protected readonly MLContext MlContext;
protected DataOperationsCatalog.TrainTestData _dataSplit;
protected ITrainerEstimator<ClusteringPredictionTransformer<TParameters>, TParameters> _model;
protected ITransformer _trainedModel;
继承该类的类使用 Name 属性添加算法的名称。ModelPath字段用于定义训练模型后我们将存储模型的位置。请注意,文件名具有.mdl扩展名。然后我们有了MlContext,这样我们就可以使用ML.NET功能。不要忘记这个类是一个singleton,所以我们的解决方案中只有一个。_dataSplit字段包含加载的数据。在此结构中,数据被分成训练和测试数据集。
字段_model由子类使用。这些类定义了该领域使用的机器学习算法。_trainedModel字段是应评估和保存的结果模型。本质上,继承和实现这个类的工作是通过将所需算法的对象实例化为_model来定义应该使用的算法。
很酷,现在让我们探索Fit()方法:
public void Fit(string trainingFileName)
{
if (!File.Exists(trainingFileName))
{
throw new FileNotFoundException($"File {trainingFileName} doesn't exist.");
}
_dataSplit = LoadAndPrepareData(trainingFileName);
var dataProcessPipeline = BuildDataProcessingPipeline();
var trainingPipeline = dataProcessPipeline.Append(_model);
_trainedModel = trainingPipeline.Fit(_dataSplit.TrainSet);
}
该方法是算法训练的蓝图。作为输入参数,它接收.csv文件的路径。确认文件存在后,我们使用私有方法LoadAndPrepareData。此方法将数据加载到内存中并将其拆分为两个数据集,即训练数据集和测试数据集。我们将返回值存储到_dataSplit 中,因为我们需要一个用于 评估阶段的测试数据集。然后我们调用BuildDataProcessingPipeline()。
这是执行数据预处理和特征工程的方法。对于这些数据,不需要做一些繁重的工作,我们只需从文本列创建特征并进行归一化 ,因为连续数据的规模不同。这是方法:
private EstimatorChain<ColumnConcatenatingTransformer> BuildDataProcessingPipeline()
{
var dataProcessPipeline = MlContext.Transforms.Text
.FeaturizeText(inputColumnName: "Sex", outputColumnName: "SexFeaturized")
.Append(MlContext.Transforms.Text
.FeaturizeText(inputColumnName: "Island", outputColumnName: "IslandFeaturized"))
.Append(MlContext.Transforms.Concatenate("Features",
"IslandFeaturized",
nameof(PalmerPenguinsData.CulmenLength),
nameof(PalmerPenguinsData.CulmenDepth),
nameof(PalmerPenguinsData.BodyMass),
nameof(PalmerPenguinsData.FliperLength),
"SexFeaturized"
))
.AppendCacheCheckpoint(MlContext);
return dataProcessPipeline;
}
接下来是 Evaluate() 方法:
public ClusteringMetrics Evaluate()
{
var testSetTransform = _trainedModel.Transform(_dataSplit.TestSet);
return MlContext.Clustering.Evaluate(
data: testSetTransform,
labelColumnName: "PredictedLabel",
scoreColumnName: "Score",
featureColumnName: "Features");
}
这是一个非常简单的方法,它通过使用_trainedModel和测试Dataset创建一个Transformer对象。然后我们利用MlContext检索回归指标。后,让我们检查一下Save()方法:
public void Save()
{
MlContext.Model.Save(_trainedModel, _dataSplit.TrainSet.Schema, ModelPath);
}
这是另一种简单的方法,它只使用MLContext将模型保存到定义的路径中。
5.4 培训师
由于我们在TrainerBase类中完成的所有繁重工作,其他Trainer类应该很 简单,并且只专注于实例化 ML.NET 算法。在这种特殊情况下,我们只有一个类KMeansTrainer。这里是:
using Microsoft.ML;
using Microsoft.ML.Trainers;
using Clustering.MachineLearning.Common;
namespace Clustering.MachineLearning.Trainers
{
public class KMeansTrainer : TrainerBase<KMeansModelParameters>
{
public KMeansTrainer(int numberOfClusters) : base()
{
Name = $"K Means Clulstering - {numberOfClusters} Clusters";
_model = MlContext.Clustering.Trainers
.KMeans(numberOfClusters: numberOfClusters, featureColumnName: "Features");
}
}
}
请注意,该算法有一个超参数 numberOfClusters。我们使用这个数字来定义我们期望在我们的数据集中有多少集群。
5.5 预测器
Predictor类在这里加载保存的模型并运行一些预测。通常,此类不是与培训师相同的微服务的一部分。我们通常有一个执行模型训练的微服务。该模型被保存到文件中,另一个模型从中加载它并根据用户输入运行预测。这是这个类的样子:
using Microsoft.ML;
using Clustering.MachineLearning.DataModels;
using System;
using System.IO;
namespace Clustering.MachineLearning.Predictors
{
public class Predictor
{
protected static string ModelPath => Path.Combine(AppContext.BaseDirectory, "cluster.mdl");
private readonly MLContext _mlContext;
private ITransformer _model;
public Predictor()
{
_mlContext = new MLContext(111);
}
/// <summary>
/// Runs prediction on new data.
/// </summary>
/// <param name="newSample">New data sample.</param>
/// <returns>PalmerPenguinsData object, which contains predictions made by model.</returns>
public PalmerPenguinsPrediction Predict(PalmerPenguinsData newSample)
{
LoadModel();
var predictionEngine = _mlContext.Model
.CreatePredictionEngine<PalmerPenguinsData, PalmerPenguinsPrediction>(_model);
return predictionEngine.Predict(newSample);
}
private void LoadModel()
{
if (!File.Exists(ModelPath))
{
throw new FileNotFoundException($"File {ModelPath} doesn't exist.");
}
using (var stream = new FileStream(
ModelPath,
FileMode.Open,
FileAccess.Read,
FileShare.Read))
{
_model = _mlContext.Model.Load(stream, out _);
}
if (_model == null)
{
throw new Exception($"Failed to load Model");
}
}
}
}
简而言之,模型是从定义的文件中加载的,并对新样本进行预测。请注意,我们需要创建PredictionEngine 才能这样做。
5.6 用法和结果
好的,让我们把所有这些放在一起。假设我们不知道我们的数据集中有 3 个集群。这就是我们为不同数量的集群运行K-Means 的原因。
using Clustering.MachineLearning.Common;
using Clustering.MachineLearning.DataModels;
using Clustering.MachineLearning.Predictors;
using Clustering.MachineLearning.Trainers;
using System;
using System.Collections.Generic;
namespace Clustering
{
class Program
{
static void Main(string[] args)
{
var newSample = new PalmerPenguinsData
{
Island = "Torgersen",
CulmenDepth = 18.7f,
CulmenLength = 39.3f,
FliperLength = 180,
BodyMass = 3700,
Sex = "MALE"
};
var trainers = new List<ITrainerBase>
{
new KMeansTrainer(1),
new KMeansTrainer(2),
new KMeansTrainer(3),
new KMeansTrainer(4),
new KMeansTrainer(5),
};
trainers.ForEach(t => TrainEvaluatePredict(t, newSample));
}
static void TrainEvaluatePredict(ITrainerBase trainer, PalmerPenguinsData newSample)
{
Console.WriteLine("*******************************");
Console.WriteLine($"{ trainer.Name }");
Console.WriteLine("*******************************");
trainer.Fit("C:\\Users\\n.zivkovic\\source\\repos\\LogisticRegressionFromScratch\\MulticlassClassificationMLNET\\Data\\penguins.csv");
var modelMetrics = trainer.Evaluate();
Console.WriteLine($"Average Distance: {modelMetrics.AverageDistance:#.##}{Environment.NewLine}" +
$"Davies Bouldin Index: {modelMetrics.DaviesBouldinIndex:#.##}{Environment.NewLine}" +
$"Normalized Mutual Information: {modelMetrics.NormalizedMutualInformation:#.##}{Environment.NewLine}");
trainer.Save();
var predictor = new Predictor();
var prediction = predictor.Predict(newSample);
Console.WriteLine("------------------------------");
Console.WriteLine($"Prediction: {prediction.PredictedClusterId:#.##}");
Console.WriteLine($"Distances: {string.Join(" ", prediction.Distances)}");
Console.WriteLine("------------------------------");
}
}
}
注意TrainEvaluatePredict()方法。这种方法在这里完成了繁重的工作。在这个方法中,我们可以注入一个继承TrainerBase的类的实例和一个我们想要预测的新样本。然后我们调用Fit()方法来训练算法。然后我们调用Evaluate()方法并打印出指标。后,我们保存模型。完成后,我们创建Predictor的实例,使用新样本调用Predict()方法并打印出预测。在Main中,我们创建一个训练对象列表,然后我们调用对这些对象进行TrainEvaluatePredict。以下是结果:
*******************************
K Means Clulstering - 1 Clusters
*******************************
Average Distance: 680784.5
Davies Bouldin Index:
Normalized Mutual Information: NaN
------------------------------
Prediction: 1
Distances: 261472
------------------------------
*******************************
K Means Clulstering - 2 Clusters
*******************************
Average Distance: 181156.54
Davies Bouldin Index: .49
Normalized Mutual Information: 1
------------------------------
Prediction: 1
Distances: 788 1860964
------------------------------
*******************************
K Means Clulstering - 3 Clusters
*******************************
Average Distance: 101760.4
Davies Bouldin Index: .55
Normalized Mutual Information: 1
------------------------------
Prediction: 1
Distances: 31438 484714 2955820
------------------------------
*******************************
K Means Clulstering - 4 Clusters
*******************************
Average Distance: 51608.34
Davies Bouldin Index: .51
Normalized Mutual Information: 1
------------------------------
Prediction: 1
Distances: 40618 887034 3310738 139807
------------------------------
*******************************
K Means Clulstering - 5 Clusters
*******************************
Average Distance: 38005.6
Davies Bouldin Index: .58
Normalized Mutual Information: 1
------------------------------
Prediction: 1
Distances: 185 1204550 3419592 218208 241552
------------------------------
好的,我们得到了一些有趣的结果。在所有情况下,我们的解决方案都将集群 1 的值分配给新样本。这与Adelie类相对应,这很好。然而,这些数据告诉我们什么?如果你还记得的话,我们假装不知道我们的数据集中有多少个集群。那么我们如何从这些结果中得出结论呢?这里我们使用肘法。
6. 肘法
我们知道我们的数据集中有树类。但是,让我们暂时忘记所有这些,让我们为所有类别使用相同的颜色绘制数据:
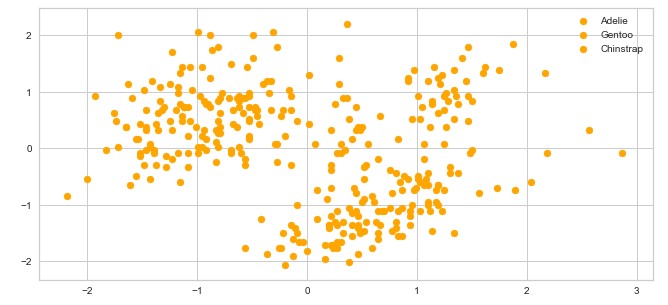
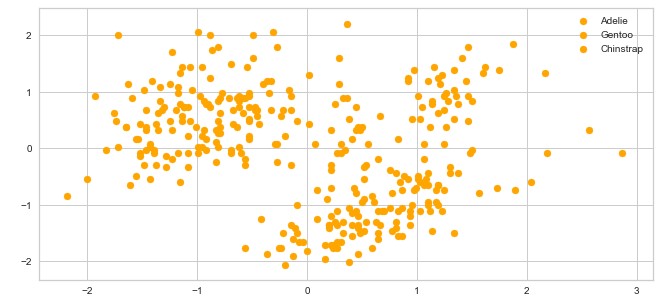
你看到多少个集群?我们可以说 3-ish,但我们不能确定。另外,中间的数据非常粗略。正如我们所说,确定数据集中聚类数量的流行方法之一称为 Elbow 方法。它可以建立在两个指标之上:失真和惯性。失真被计算为与各个集群的集群中心的平方距离(假设为欧几里德距离)的平均值。惯性表示样本到它们近的聚类中心的距离的平方和。
我们可以做的是使用 可变数量的集群运行我们的聚类算法并计算失真和惯性。然后我们可以绘制结果。在那里我们可以寻找“肘”点。这是随着集群数量的增加,失真/惯性开始以线性方式下降的点。这一点告诉我们佳簇数。
这正是我们对我们的解决方案所做的,所以当我们计算上述结果的失真和惯性并 绘制 失真值和簇数时:
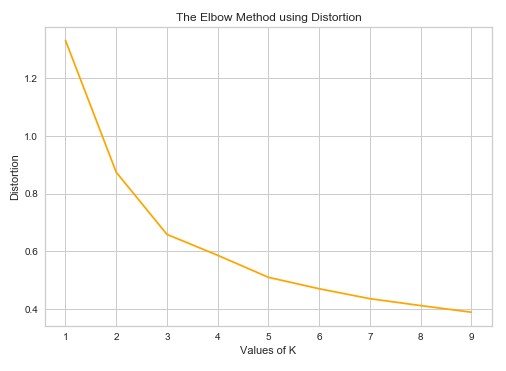

从这张图片我们可以得出结论,在 3 个集群之后,失真以线性方式减少,即。3 是佳簇数。惯性如何:
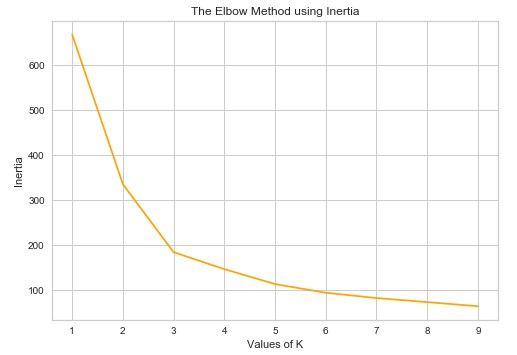
我们也可以从这张图片中得出同样的结论。
结论
在本文中,我们有机会探索如何利用无监督学习解决聚类问题。我们观察了 K-Means 聚类算法并用 ML.NET 实现了它。我们还简要探讨了层次聚类和 DBSCAN 等算法。我们将 K-Means 聚类应用于PalmerPenguins数据集,并看到了一些非常有趣的结果。此外,我们还有机会看到无监督学习的强大之处。
引用
- 使用 ML.NET 进行机器学习 - 集群完整指南 - ONEO AI - [...] by /u/RubiksCodeNMZ [链接] [...]
- Dew Drop – 2021 年 2 月 8 日(#3376) – Alvin Ashcraft 的 Morning Dew – […] 使用 ML.NET 进行机器学习 – 聚类完整指南(Nikola M. Zivkovic)[…]
- 使用 ML.NET 进行机器学习 - 集群完整指南 - AI 摘要- [...] 阅读完整文章:rubikscode.net [...]
原文链接
Machine Learning with ML.NET – Complete Guide to Clustering
