在Raft协议中,每个节点都维护了一个状态机,该状态机有三种状态,分别是Leader状态、Follower状态和Candidate状态,在任意时刻,集群中的任意一个节点都处于这三个状态之一。在多数情况下,集群中有一个Leader节点,其他节点都处于Follower状态。
所有节点遵从一条准则:当某个节点所接收到的消息中,消息所携带的任期号大于当前节点本身记录的任期号,那么该节点会更新自身记录的任期号,同时会切换为Follower并重置选举计时器。
节点状态
1.Leader节点
(1).负责处理所有客户端的请求
接收客户端的写入请求,Leader节点会在本地追加一条相应的日志,然后将其封装成消息发送到集群中其他的Follower节点。当Follower节点收到该消息时会对其进行响应。如果集群中多数(超过半数)节点都已收到该请求对应的日志记录时,则Leader节点认为该条日志记录已提交
committed
,可以向客户端返回响应。接收客户端的只读请求。
(2).定期向集群中的Follower节点发送心跳消息,目的是为了防止集群中其他Follower节点的选举计时器超时,从而触发新一轮的选举。
2.Follower节点
响应来自Leader或者Candidate的请求:Follower节点也不处理Client的请求,而是将请求重定向给集群的Leader节点,由Leader节点进行请求处理。
3.Candidate节点
由Follower节点转换而来的,当Follower节点长时间没有收到Leader节点发送的心跳消息时,该节点的选举计时器就会过期,然后将自身状态转换成Candidate,并发起选举。
选举
1.两个控制Leader选举的时间
(1).选举超时时间
当每个Follower节点接收不到Leader节点的心跳消息时,Follower节点并不会立即发起新一轮选举,而是需要等待一段时间之后才切换成Candidate状态发起新一轮选举。这段等待时长就是election timeout,这样设计的原因是:Leader节点发送的心跳消息,可能因为瞬间的网络延迟或程序瞬间的卡顿而迟到(或是丢失),该情况下触发新一轮选举是没有必要的。
(2).心跳超时时间
Leader节点向集群中其他Follower节点发送心跳消息的时间间隔。Follower节点收到心跳信息时,会重置选举定时器防止发起新一轮的选举。
2.选举流程
(1).集群初始化,所有节点都是Follower,没有Leader。
(2).Follower收不到Leader心跳信息,导致选举计时器超时,Follower转为Candidate并发起选举。
(3).Candidate获取超过半数以上的选票,则成为该任期的Leader,直到该任期结束。
在实际选举操作中,会遇到一些特殊情况,比如选举过程中某节点收到前任Leader的心跳信息。当出现这种情况时,该节点会利用心跳信息中携带的任期值进行比较操作,假如心跳信息中的任期值小于该节点的任期值,则忽略该心跳信息。如果该Leader节点发现周边节点的任期值大于自身的任期值,那么会主动降级为Follower节点,同步新Leader节点的相关信息。
3.投票流程
(1).发起选举的节点先给自己投票。
(2).向集群中其他节点发送选举请求(Request Vote),目的是获取其他节点的选票。
(3).集群中其他节点收到Request Vote后,重置选举定时器(防止切换为Candidate,当同时出现多个Candidate时,会导致选举失败而重新进行选举)。
(4).发起选举的节点收到超半数的选票后,切换为Leader,其余节点切换为Follower。
注:集群中节点会记录当前任期号、投票结果。
4.多个Candidate情况
(1).当有两个或两个以上节点选举计时器同时过期时,就会造成这些节点同时由Follower转成Candidate,每个Candidate获取的选票不过半,就会导致选举失败。
(2).防止该情况下选举失败处理方法:在此情形下选举失败后,选举超时时间会从设定时间区间内选取一个随机数,当节点设定的时间随机数很小时,该节点会很快出现选举计时器超时,继而发起新一轮的选举。
5.Leader lease机制
Leader lease机制指的是,如果节点收到Leader发来的消息,那么就不会给其他节点投票。如下图,有s1、s2、s3三个节点,s1为Leader,s2、s3为Follower。在发生网络分区后,s1和s3可以互通,s2和s3可以互通,s1和s2无法互通。s2在选举计时器超时时间内没有收到Leader发来的心跳消息,那么s2在选举计时器超时后发起选举。s2收到s3的投票后成为新的Leader。但是s1作为Leader仍在正常工作,集群也处于正常工作状态,s2不应该发起选举。利用Leader lease机制,可以阻止s3向s2发送选票响应消息,可以有效防止这种现象的发生。

6.Check Quorum机制
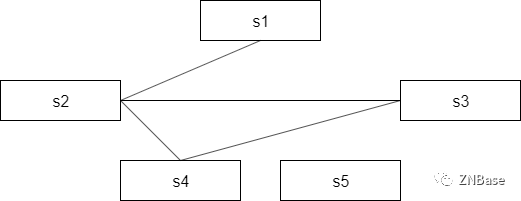
Check Quorum机制指的是,检测当前Leader是否可以与集群中超过半数的节点连通,如果不能连通,那么该节点切换成Follower。通常情况下,Check Quorum机制与Leader lease机制配合使用。如下图,有s1、s2、s3、s4、s5五个节点,s1为Leader,s2、s3、s4、s5为Follower。在发生网络分区后,s1、s2互通,s2、s3、s4互通,s5不通。在没有开启Leader lease机制的情况下,s2、s3、s4会选举出新的Leader。但开启了Leader lease机制,s2会忽略其他节点的投票消息,此时不会选举出新的Leader。为防止这种无法选出Leader的情况出现,开启Check Quorum机制可以解决这个问题,即s1由于无法与超半数节点连通而切换为Follower,s2可以响应投票消息。总的来说,Check Quorum机制是从Leader角度判断自己是否合法,Leader lease机制是从Follower角度判断Leader是否合法。