Spark SQL也可以通过设置参数来使其符合ANSI标准(结构化查询语言(SQL)是用于访问和管理数据库的数据库管理员(DBA)的标准语言),通过设置spark.sql.ansi.enabled=’true’(默认值是false)选项来控制spark sql是否符合ANSI标准,当spark.sql.storeAssignmentPolicy(默认值为ANSI)选项为ANSI时,spark sql符合ANSI标准的存储分配原则,这两个配置选项是相互独立的。
01
基本语法


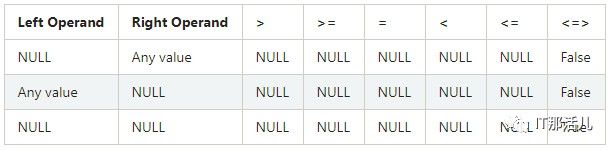

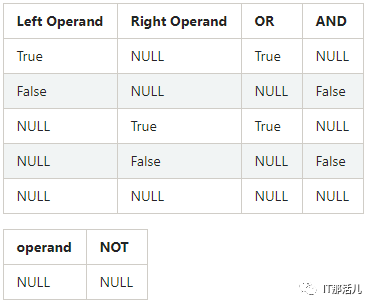
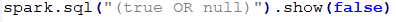


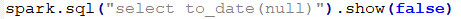

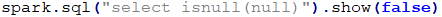

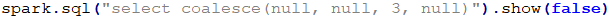



COUNT(*)返回的所有的数据个数 COUNT(NAME)返回的是NAME不为NULL的个数。 其他聚合函数都为将NULL排除再进行操作。 WHERE、HAVING、JOIN字句中NULL值得处理。 WHERE字句中将会排除过滤条件为NULL的数据。 WHERE NAME IS NULL将会返回NAME为NULL的数据。 HAVING字句将会将为NULL的数据过滤掉。 JOIN字句中将会将为NULL值得数据过滤掉,但是如果使用<=>作为关联条件时将会一块将NULL进行返回。意思就是两边关联条件如果都为NULL也是可以返回的。 GROUP BY、DISTINCT对NULL值都会进行处理,不会排除为NULL值得数据。 ORDER BY字句也会将NULL进行排序,默认情况下,NULL值得数据都会排在前面,如果想排在后可以:ORDER BY AGE NULLS LAST进行处理。 EXISTS和NOT EXISTS字句中,也不会将NULL值进行排除。
02
函 数


03
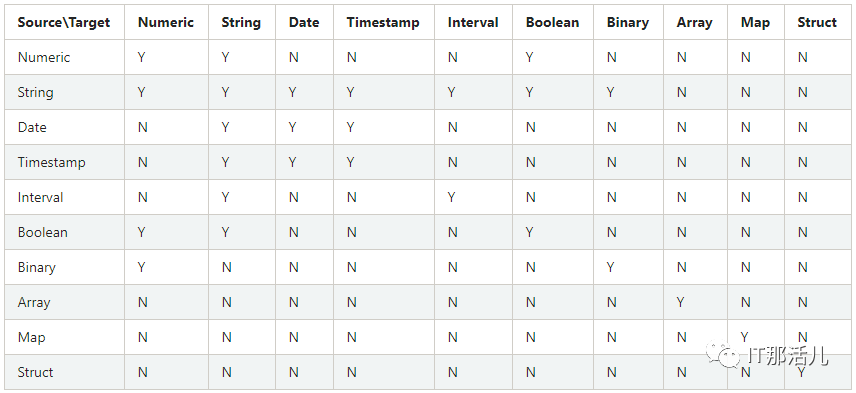
数据类型
ArrayType(elementType, containsNull):表示元素序列数据类型,containsNull用于指示是否可以包括空值。 MapType(keyType, valueType, valueContainsNull)用于表示键值对数据类型,其中key不能为空值,valueContainsNull指示值是否可以为空。 StructType(fields):一系列由StructField(name, dataType, nullable)定义的数据类型,nullable指示是否可以为空。

