将表中已有的字段中的数据汇聚到一个新的字段中进行存储的机制,用以解决数据搜索过程中不知道位置的问题的方法叫做汇聚存储。
汇聚存储可以解决搜索的内容不知道在表的哪个字段中,可以做到全表匹配。再结合分词数据类型即可做到全文检索的特性。
用户可以自己定义任意的字段存储到不同的或者相同的目标字段中。支持指定字段前缀、字段下标、全字匹配的逻辑汇聚;汇聚后的字段可以存储原始的字段名称。
映射表汇聚
映射表更详细的用法参考《LSQL特性 | 映射表》该文。
1. 创建带有汇聚功能的映射表
汇聚例子如下:
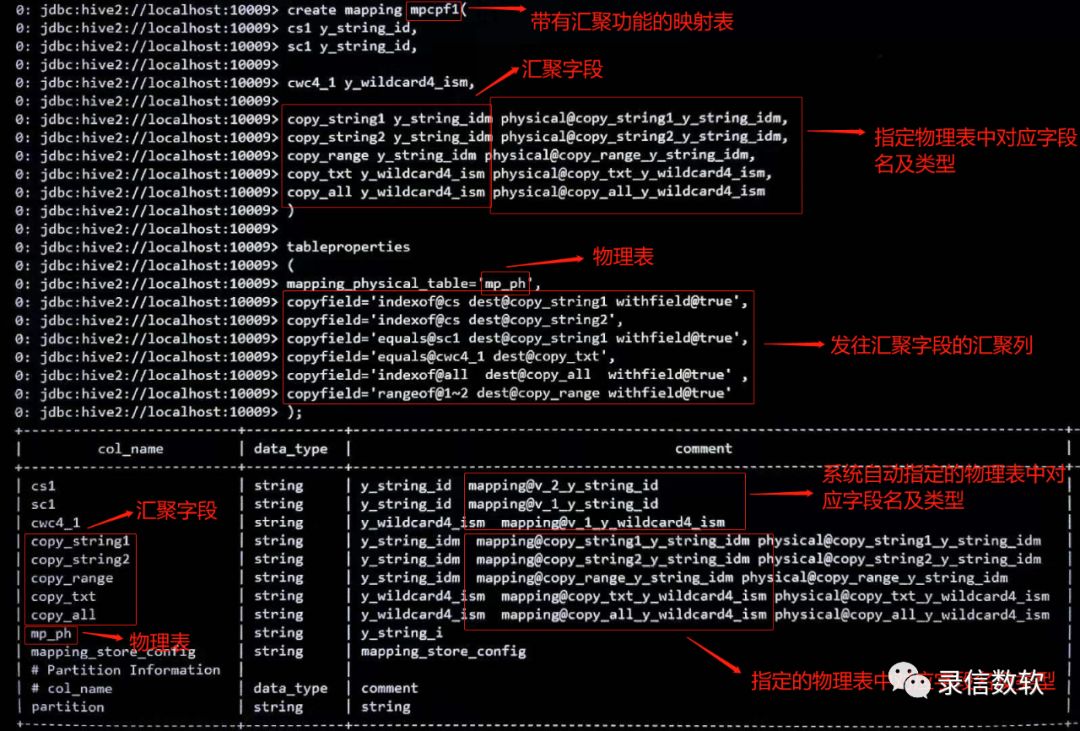
create mapping macpf1(cs1 y_string_id,sc1 y_string_id,
cwc4_1 y_wildcard4_ism,
copy_string1 y_string_idm physical@copy_string1_y_string_idm,copy_string2 y_string_idm physical@copy_string2_y_string_idm,copy_range y_string_idm physical@copy_range_y_string_idm,copy_txt y_wildcard4_ism physical@copy_txt_y_wildcard4_ism,copy_all y_wildcard4_ism physical@copy_all_y_wildcard4_ism)tableproperties (mapping_physical_table=’mp_ph’,/*映射到哪张表里去*//*汇聚1:汇聚字段名称以cs开头的数据(cs1),withfield@true表示含有原始字段的名称*/copyfield='indexof@cs dest@copy_string1 withfield@true',/*汇聚2:汇聚字段名称以cs开头的字段的数据(cs1),不含原始字段的名称*/copyfield='indexof@cs dest@copy_string2',/*汇聚3:汇聚字段’sc1’中的数据(copy_string1在汇聚1中已做汇聚,可以继续对其添加汇聚数据,不会对之前的内容造成覆盖),withfield@true表示含有原始字段的名称*/copyfield='equals@sc1 dest@copy_string1 withfield@true',/*汇聚4:汇聚’cwc4_1’中的数据,不含原始字段的名称*/copyfield='equals@cwc4_1 dest@copy_txt',/*汇聚5:汇聚所有字段中的数据,withfield@true表示含有原始字段的名称*/copyfield='indexof@all dest@copy_all withfield@true',/*汇聚6:汇聚第1~2个字段中的数据(cs1、sc1),withfield@true表示含有原始字段的名称*/copyfield='rangeof@1~2 dest@copy_range withfield@true');注:
cs*、sc*、cwc4*:代表原始字段。
copy_*:代表要发往目标汇聚字段。
copyfield:代表字段数据汇聚关键字。
withfield@:true代表汇聚字段含有原始的字段名称,该关键字不声明则代表汇聚字段不含原始字段名称。
indexof@:可以使用all关键字匹配所有字段,也可以用字段的前缀,比如:cs,匹配含有cs前缀字符的字段。
dest@:代表汇聚的数据发往哪个目标字段中的关键字。
equals@:代表需要进行汇聚的明确的字段名称的关键字。
2. 导入数据
(1) 原始数据(路径:/wyh/mpcpf.log):

./load.sh -t mpcpf1 -tp txt -local -f /wyh/mpcpf.log -sp , -fl cs1,sc1,cwc4_1(3) 导入数据后对映射表做全表查询:

注:创建表时进行汇聚时未声明withfield@true的汇聚内容,在查询时只展示字段值,如["zs"]的形式,若声明withfield@true关键字,展示形式为原始字段名称@字段值,如["cs1@zs"]的形式。
3. 查询方法
(1) 指定字段查询:
select copy_string1,copy_string2,copy_range,copy_txt,copy_all from mpcpf1;
select * from mpcpf1;select * from mpcpf1 where copy_all = ‘早餐’;
物理表汇聚
1. 创建带有汇聚功能的物理表
汇聚例子如下:
create table ph1(cs1 y_string_id,sc1 y_string_id,
cwc4_1 y_wildcard4_ism,
copy_string1 y_string_idm ,copy_string2 y_string_idm,copy_range y_string_idm ,copy_txt y_wildcard4_ism ,copy_all y_wildcard4_ism)tableproperties (/*汇聚1:汇聚字段名称以cs开头的数据(cs1),withfield@true表示含有原始字段的名称*/copyfield='indexof@cs dest@copy_string1 withfield@true',/*汇聚2:汇聚字段名称以cs开头的字段的数据(cs1),不含原始字段的名称*/copyfield='indexof@cs dest@copy_string2',/*汇聚3:汇聚字段’sc1’中的数据(copy_string1在汇聚1中已做汇聚,可以继续对其添加汇聚数据,不会对之前的内容造成覆盖),withfield@true表示含有原始字段的名称*/copyfield='equals@sc1 dest@copy_string1 withfield@true',/*汇聚4:汇聚’cwc4_1’中的数据,不含原始字段的名称*/copyfield='equals@cwc4_1 dest@copy_txt',/*汇聚5:汇聚所有字段中的数据,withfield@true表示含有原始字段的名称*/copyfield='indexof@all dest@copy_all withfield@true',/*汇聚6:汇聚第1~2个字段中的数据(cs1、sc1),withfield@true表示含有原始字段的名称*/copyfield='rangeof@1~2 dest@copy_range withfield@true');注:
cs*、sc*、cwc4*:代表原始字段。
copy_*:代表要发往目标汇聚字段。
copyfield:代表字段数据汇聚关键字。
withfield@:true代表汇聚字段含有原始的字段名称,该关键字不声明则代表汇聚字段不含原始字段名称。
indexof@:可以使用all关键字匹配所有字段,也可以用字段的前缀,比如:cs,匹配含有cs前缀字符的字段。
dest@:代表汇聚的数据发往哪个目标字段中的关键字。
equals@:代表需要进行汇聚的明确的字段名称的关键字。

2. 导入数据
(1) 原始数据(路径:/wyh/ph.log):

(2) 导入数据脚本:
./load.sh -t ph1 -tp txt -local -f /wyh/ph.log -sp , -fl cs1,sc1,cwc4_1(3) 导入数据后对物理表做全表查询:

注:创建表时进行汇聚时未声明withfield@true的汇聚内容,在查询时只展示字段值,如["zs"]的形式,若声明withfield@true关键字,展示形式为原始字段名称@字段值,如["cs1@zs"]的形式。
3. 查询方法
(1) 模糊查询:
select copy_string1,copy_string2,copy_range,copy_txt,copy_all from ph1;select * from ph1 where copy_all = ‘早餐’;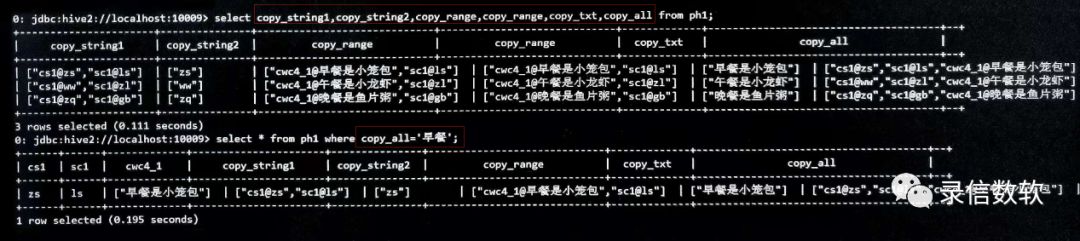
映射表&物理表对比
1. Mapping导入数据后显示效果

2. Table导入数据后显示效果

原文链接:https://mp.weixin.qq.com/s/9rIJthPB5-cTVQ1OQS7mOw
