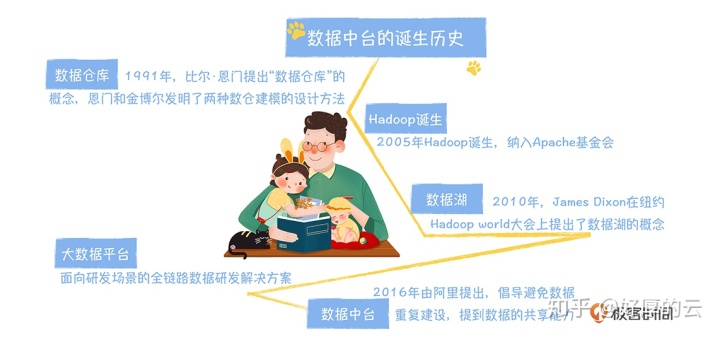
启蒙时代:数据仓库的出现
商业智能(Business Intelligence)诞生在上个世纪 90 年代,它是将企业已有的数据转化为知识,帮助企业做出经营分析决策。比如在零售行业的门店管理中,如何使得单个门店的利润大化,我们就需要分析每个商品的销售数据和库存信息,为每个商品制定合理的销售采购计划,有的商品存在滞销,应该降价促销,有的商品比较畅销,需要根据对未来销售数据的预测,进行提前采购,这些都离不开大量的数据分析。
而数据分析需要聚合多个业务系统的数据,比如需要集成交易系统的数据,需要集成仓储系统的数据等等,同时需要保存历史数据,进行大数据量的范围查询。传统数据库面向单一业务系统,主要实现的是面向事务的增删改查,已经不能满足数据分析的场景,这促使数据仓库概念的出现。
数据仓库是在企业管理和决策中面向主题的、集成的、与时间相关的,不可修改的数据集合。
为了帮你理解数据仓库的四要素,我举个电商的例子。
在电商场景中,有一个数据库专门存放订单的数据,另外一个数据库存放会员相关的数据。构建数据仓库,首先要把不同业务系统的数据同步到一个统一的数据仓库中,然后按照主题域方式组织数据。
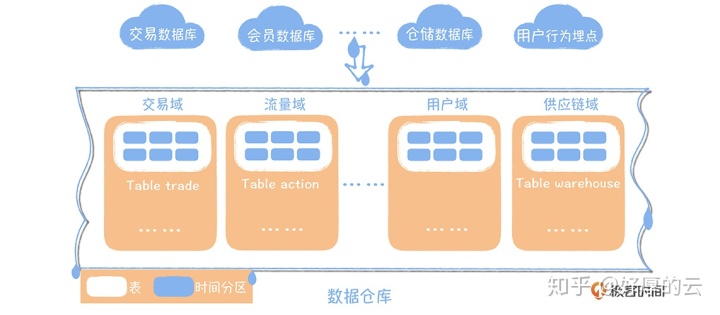
主题域是业务过程的一个高层次的抽象,像商品、交易、用户、流量都能作为一个主题域,你可以把它理解为数据仓库的一个目录。数据仓库中的数据一般是按照时间进行分区存放,一般会保留 5 年以上,每个时间分区内的数据都是追加写的方式,对于某条记录是不可更新的。
恩门提出的建模方法自顶向下(这里的顶是指数据的来源,在传统数据仓库中,就是各个业务数据库),基于业务中各个实体以及实体之间的关系,构建数据仓库。
比如,在一个简单的买家购买商品的场景中,按照恩门建模的思维模式,首先你要理清这个业务过程中涉及哪些实体。买家、商品是一个实体,买家购买商品是一个关系。所以,模型设计应该有买家表,商品表,和买家商品交易表三个模型。
金博尔建模与恩门正好相反,是一种自底向上的模型设计方法,从数据分析的需求出发,拆分维度和事实。那么用户、商品就是维度,库存、用户账户余额是事实。
这两种方法各有优劣,恩门建模因为是从数据源开始构建,构建成本比较高,适用于应用场景比较固定的业务,比如金融领域,冗余数据少是它的优势。金博尔建模由于是从分析场景出发,适用于变化速度比较快的业务,比如互联网业务。由于现在的业务变化都比较快,所以我更推荐金博尔的建模设计方法。
统数据仓库,次明确了数据分析的应用场景应该用单独的解决方案去实现,不再依赖于业务的数据库。在模型设计上,提出了数据仓库模型设计的方法论,为后来数据分析的大规模应用奠定了基础。但是进入互联网时代后,传统数据仓库逐渐没落,一场由互联网巨头发起的技术革命催生了大数据时代的到来。
技术革命:从 Hadoop 到数据湖
进入互联网时代,有两个重要的变化。
- 一个是数据规模前所未有,一个成功的互联网产品日活可以过亿,就像你熟知的头条、抖音、快手、网易云音乐,每天产生几千亿的用户行为。传统数据仓库难于扩展,根本无法承载如此规模的海量数据。
- 另一个是数据类型变得异构化,互联网时代的数据除了来自业务数据库的结构化数据,还有来自 App、Web 的前端埋点数据,或者业务服务器的后端埋点日志,这些数据一般都是半结构化,甚至无结构的。传统数据仓库对数据模型有严格的要求,在数据导入到数据仓库前,数据模型就必须事先定义好,数据必须按照模型设计存储。
所以,数据规模和数据类型的限制,导致传统数据仓库无法支撑互联网时代的商业智能。
而以谷歌和亚马逊为代表的互联网巨头率先开始了相关探索。从 2003 年开始,互联网巨头谷歌先后发表了 3 篇论文:《The Google File System》《MapReduce:Simplified Data Processing on Large Clusters》《Bigtable:A Distributed Storage System for Structed Data》,这三篇论文奠定了现代大数据的技术基础。它们提出了一种新的,面向数据分析的海量异构数据的统一计算、存储的方法。
但 2005 年 Hadoop 出现的时候,大数据技术才开始普及。你可以把 Hadoop 认为是前面三篇论文的一个开源实现,我认为 Hadoop 相比传统数据仓库主要有两个优势:
- 完全分布式,易于扩展,可以使用价格低廉的机器堆出一个计算、存储能力很强的集群,满足海量数据的处理要求;
- 弱化数据格式,数据被集成到 Hadoop 之后,可以不保留任何数据格式,数据模型与数据存储分离,数据在被使用的时候,可以按照不同的模型读取,满足异构数据灵活分析的需求。
数据湖(Data Lake)是一个以原始格式存储数据的存储库或系统。
数据湖拉开了 Hadoop 商用化的大幕,但是一个商用的 Hadoop 包含 20 多种计算引擎, 数据研发涉及流程非常多,技术门槛限制了 Hadoop 的商用化进程。那么如何让数据的加工像工厂一样,直接在设备流水线上完成呢?
数据工厂时代:大数据平台兴起
对于一个数据开发,在完成一项需求时,常见的一个流程是首先要把数据导入到大数据平台中,然后按照需求进行数据开发。开发完成以后要进行数据验证比对,确认是否符合预期。接下来是把数据发布上线,提交调度。后是日常的任务运维,确保任务每日能够正常产出数据。
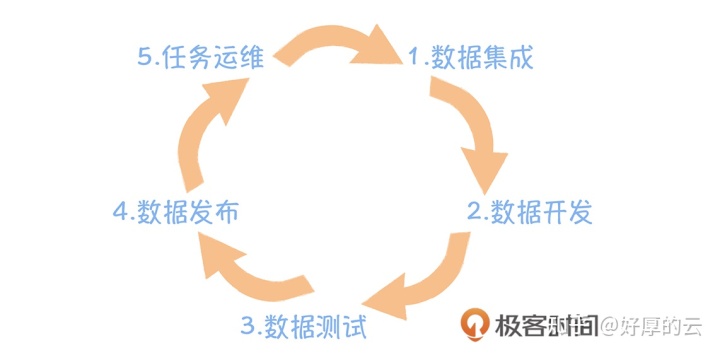
如此繁杂的一个工作流程,如果没有一个高效的平台作为支撑,就跟写代码没有一个好用的 IDE, 用文本编辑器写代码一样,别人完成十个需求,你可能连一个需求都完成不了,效率异常低下,根本无法大规模的应用。
提出大数据平台的概念,就是为了提高数据研发的效率,降低数据研发的门槛,让数据能够在一个设备流水线上快速地完成加工。
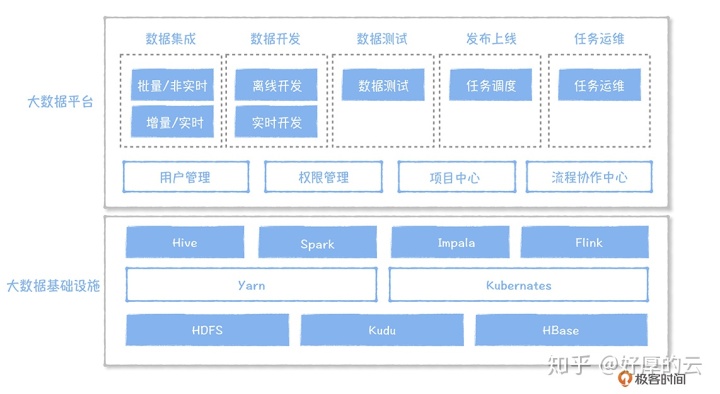
大数据平台按照使用场景,分为数据集成、数据开发、数据测试……任务运维,大数据平台的使用对象是数据开发。大数据平台的底层是以 Hadoop 为代表的基础设施,分为计算、资源调度和存储。
- Hive、Spark 主要解决离线数据清洗、加工的场景,目前,Spark 用得越来越多,性能要比 Hive 高不少;
- Flink 主要是解决实时计算的场景;
- Impala 主要是解决交互式查询的场景。
这些计算引擎统一运行在一个称为 Yarn 的资源调度管理框架内,由 Yarn 来分配计算资源。目前新的研究方向中也有基于 Kubernetes 实现资源调度的,例如在新的 Spark 版本(2.4.4)中,Spark 已经能够运行在 Kubernetes 管理的集群上,这样的好处是可以实现在线和离线的资源混合部署,节省机器成本。
数据存储在 HDFS、Kudu 和 HBase 系统内。HDFS 不可更新,主要存全量数据,HBase 提供了一个可更新的 KV,主要存一些维度表,Kudu 提供了实时更新的能力,一般用在实时数仓的构建场景中。
大数据平台像一条设备流水线,经过大数据平台的加工,原始数据变成了指标,出现在各个报表或者数据产品中。随着数据需求的快速增长,报表、指标、数据模型越来越多,找不到数据,数据不好用,数据需求响应速度慢等问题日益尖锐,成为阻塞数据产生价值的绊脚石。
数据价值时代:数据中台崛起
时间到了 2016 年前后,互联网高速发展,背后对数据的需求越来越多,数据的应用场景也越来越多,有大量的数据产品进入到了我们运营的日常工作,成为运营工作中不可或缺的一部分。在电商业务中,有供应链系统,供应链系统会根据各个商品的毛利、库存、销售数据以及商品的舆情,产生商品的补货决策,然后推送给采购系统。
大规模数据的应用,也逐渐暴露出现一些问题。
业务发展前期,为了快速实现业务的需求,烟囱式的开发导致企业不同业务线,甚至相同业务线的不同应用之间,数据都是割裂的。两个数据应用的相同指标,展示的结果不一致,导致运营对数据的信任度下降。如果你是运营,当你想看一下商品的销售额,发现两个报表上,都叫销售额的指标出现了两个值,你的感受如何? 你反应肯定是数据算错了,你不敢继续使用这个数据了。
数据割裂的另外一个问题,就是大量的重复计算、开发,导致的研发效率的浪费,计算、存储资源的浪费,大数据的应用成本越来越高。
- 如果你是运营,当你想要一个数据的时候,开发告诉你至少需要一周,你肯定想是不是太慢了,能不能再快一点儿?
- 如果你是数据开发,当面对大量的需求的时候,你肯定是在抱怨,需求太多,人太少,活干不完。
- 如果你是一个企业的老板,当你看到每个月的账单成指数级增长的时候,你肯定觉得这也太贵了,能不能再省一点,要不吃不消了。
这些问题的根源在于,数据无法共享。2016 年,阿里巴巴率先提出了“数据中台”的口号。数据中台的核心,是避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能数据应用。之前,数据是要啥没啥,中间数据难于共享,无法积累。现在建设数据中台之后,要啥有啥,数据应用的研发速度不再受限于数据开发的速度,一夜之间,我们就可以根据场景,孵化出很多数据应用,这些应用让数据产生价值。
论文链接:
《The Google File System》《MapReduce:Simplified Data Processing on Large Clusters》《Bigtable:A Distributed Storage System for Structed Data》原始博客:
https://time.geekbang.org/column/article/216555?gk_activity=0
