前言
凌晨,钉钉上收到ScyllaDB down的报警,等一下又恢复,如此反复,对数据的读写造成了一定的影响,于是进行对Scylla的错误排查,终查到异常重启的原因,在这里给大家分享一下如何进行排错的。
排查思路
1、查看服务器资源
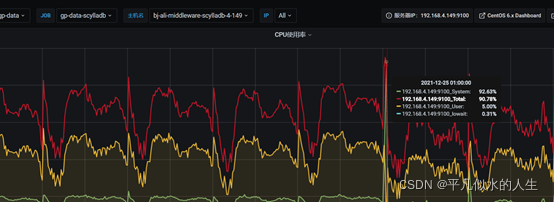
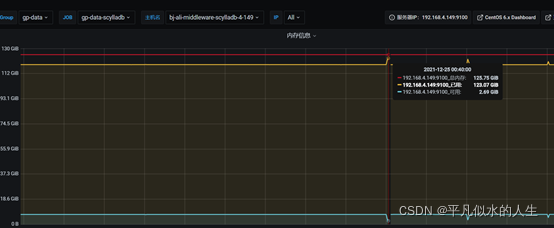
从上图中可以看出,这个时间段CPU和内存相对较高,我们再看看Scylla的错误日志,进一步分析异常重启的原因
2、查看ScyllaDB程序日志

上图中可以看到是客户端连接异常,没有其他有价值的日志信息,一般来讲,程序日志中看不出来具体错误,有可能是和系统有关。
3、查看系统日志messages

在系统日志里发现以上红框标记的错误信息,网上查找资料,分析原因
问题原因
默认情况下, Linux会多使用40%的可用内存作为文件系统缓存。当超过这个阈值后,文件系统会把将缓存中的内存全部写入磁盘, 导致后续的IO请求都是同步的。
将缓存写入磁盘时,有一个默认120秒的超时时间。 出现上面的问题的原因是IO子系统的处理速度不够快,不能在120秒将缓存中的数据全部写入磁盘。
IO系统响应缓慢,导致越来越多的请求堆积,终系统内存全部被占用,导致系统失去响应。
解决办法
1、升级服务器配置,简单的办法,不过成本比较大
1
2、针对上面的问题原因分析,缓存写入磁盘时间默认120秒,我们可以调整缓存写入磁盘的频率,避免因为请求堆积而导致系统异常。
vim /etc/sysctl.conf
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
vm.dirty_background_ratio: 是内存可以填充脏数据的百分比。这些脏数据稍后会写入磁盘,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。比如,我有32G内存,那么有3.2G的脏数据可以待着内存里,超过3.2G的话就会有后台进程来清理。
vm.dirty_ratio: 是可以用脏数据填充的大系统内存量,当系统到达此点时,必须将所有脏数据
————————————————
版权声明:本文为CSDN博主「平凡似水的人生」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_37837432/article/details/122182132
