1 前言
2 什么是体系化建模
3 为什么要进行体系化建模
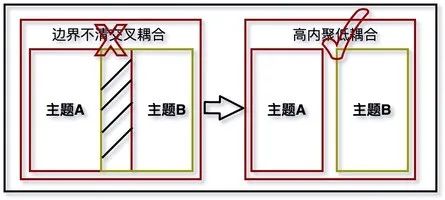
3.1 体系化建模可以对数据架构进行实质有效的管理,从源头消除“烟囱式”开发
3.2 体系化建模沉淀的规范元数据,可以有效消除业务在检索和理解数据时的困扰
4 如何进行体系化建模
4.1 高层模型设计
4.2 详细模型设计
4.3 上线前卡点
5 总结
1 前言
2 什么是体系化建模
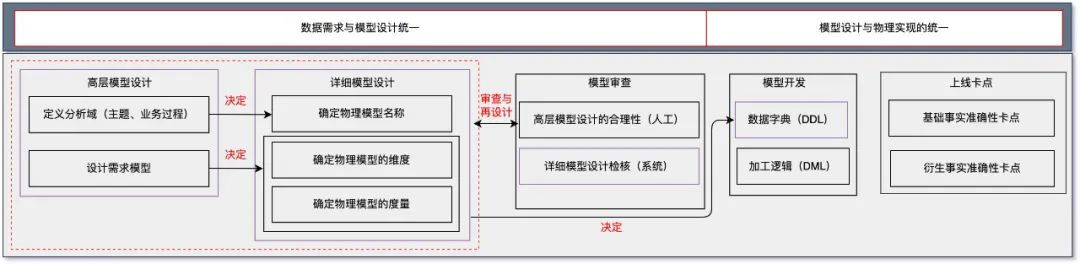 图1 体系化建模概述
图1 体系化建模概述
3 为什么要进行体系化建模
3.1 体系化建模可以对数据架构进行实质有效的管理,从源头消除“烟囱式”开发
3.2 体系化建模沉淀的规范元数据,可以有效消除业务在检索和理解数据时的困扰
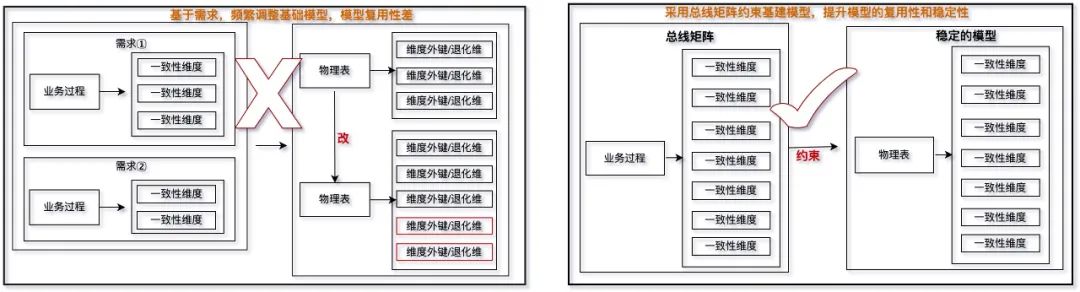
4 如何进行体系化建模
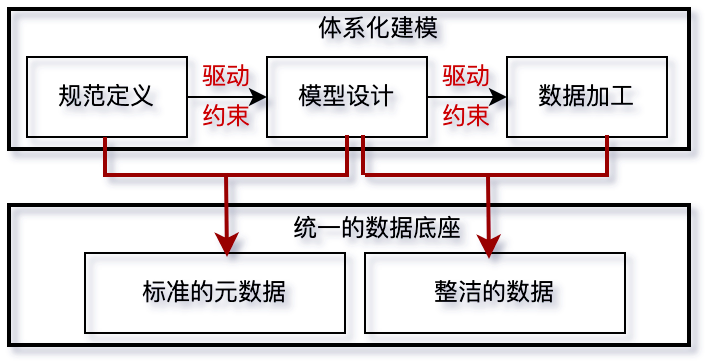
图2 体系化建模思路
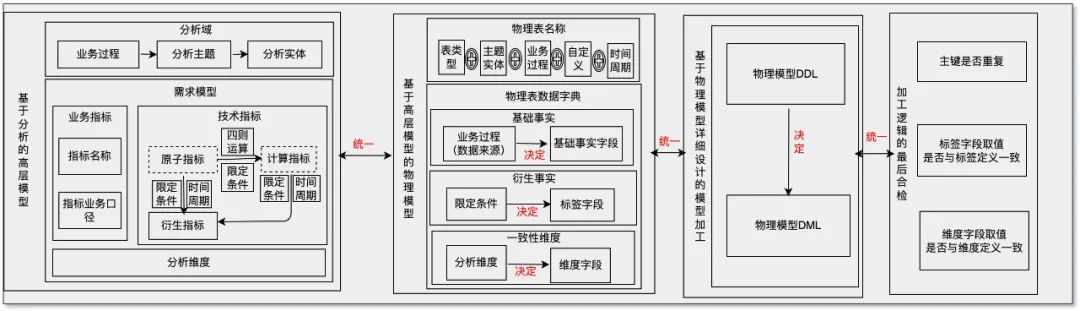
4.1 高层模型设计
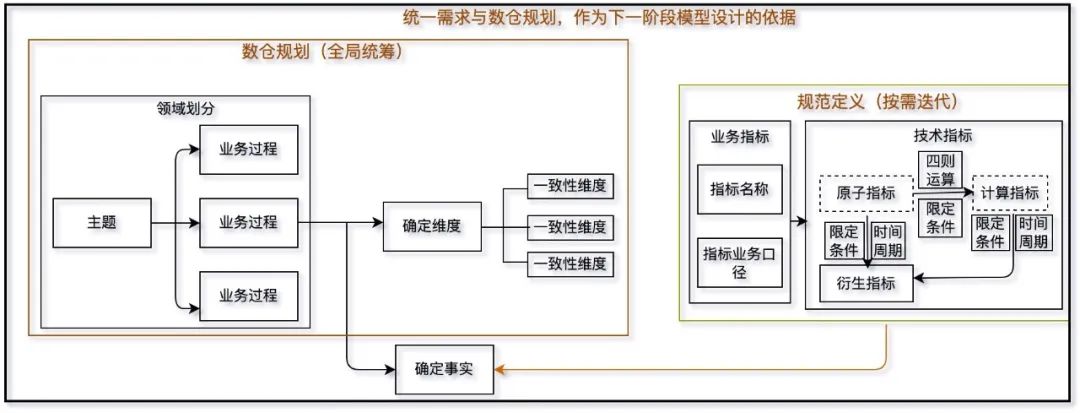
原子指标:指在某一业务过程下不可再拆分的指标,具有明确业务含义的名词。在物理实现上,它是特定业务过程下业务实体字段加特定聚合算子的组合。 计算指标:由原子指标与限定条件组合并经过加减乘除四则运算得到的指标。计算指标有明确的计算公式作为计算指标的定义,可以与多个限定条件进行组合。对于计算指标的归属,我们遵循2个原则①由于原子指标都能归属到相应的业务过程,业务过程一般来说都有时间前后顺序,将计算指标归属到顺序靠后的业务过程中;②如果涉及到多个业务过程,同时这些业务过程没有时间的先后顺序,这种情况下需要判断指标描述内容与主题业务过程的相关性,然后再归属到对应的业务过程。在物理实现上,计算指标可以由其定义的计算公式直接自动的生成其实现逻辑。 衍生指标:由 “时间周期+多个限定条件+原子指标/计算指标” 组成的指标。由于衍生指标是由原子指标/计算指标衍生出来的,所以衍生指标需要归属到原子指标/计算指标所属的业务过程。 限定条件:限定条件是指标业务口径的一个逻辑封装,时间周期也可以算作一类特殊的限定条件,是衍生指标必须包含的。在物理实现上我们将其加工成衍生事实的一个逻辑标签。
4.2 详细模型设计
4.2.1 数仓分层简介
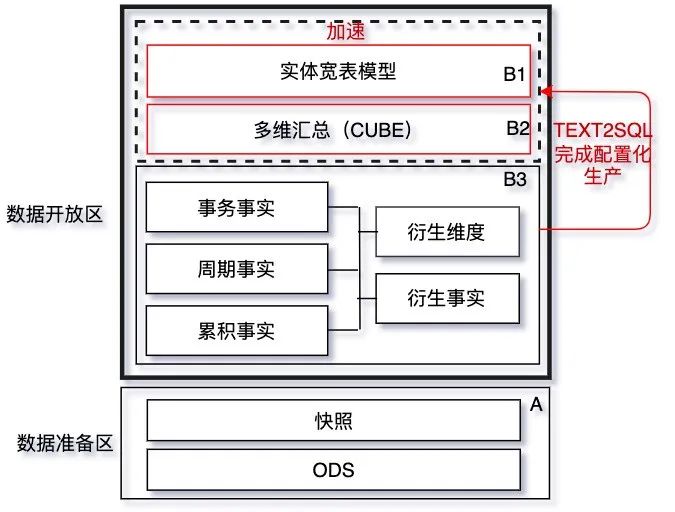
4.2.2 元数据驱动的详细模型设计
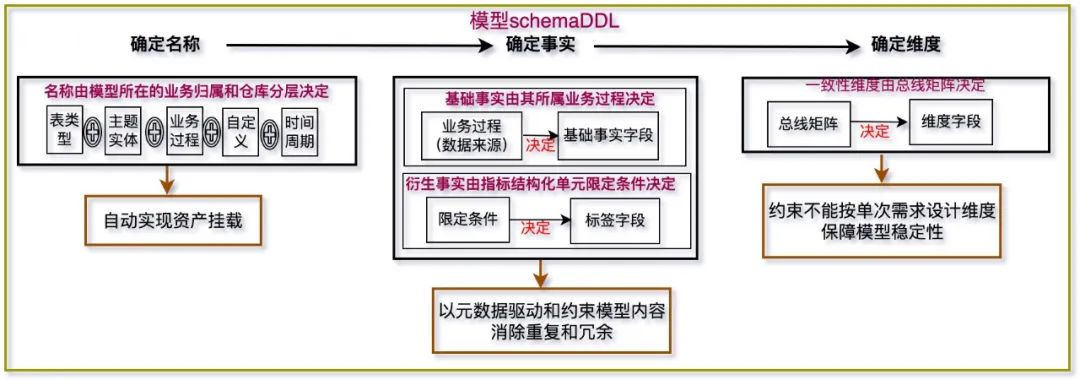
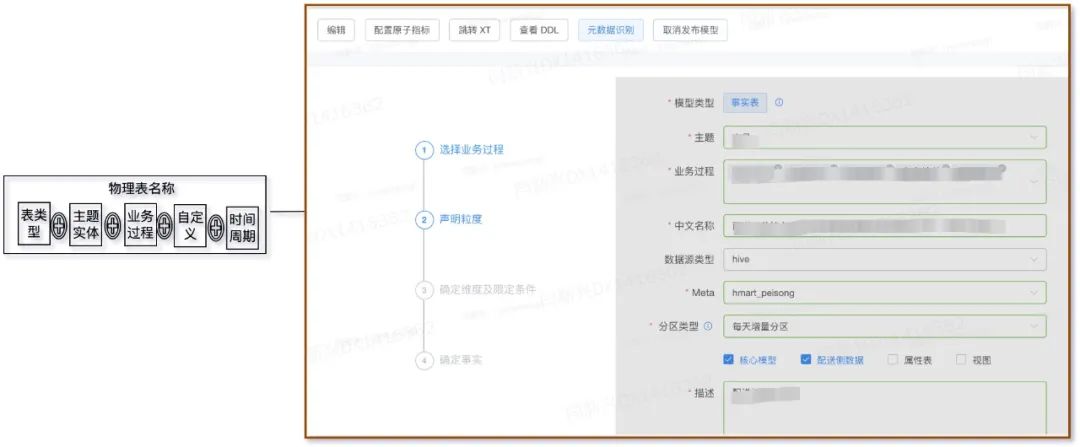
通过确定所建物理模型对应的数仓层级、主题域和业务过程,自动生成该物理表的名称。
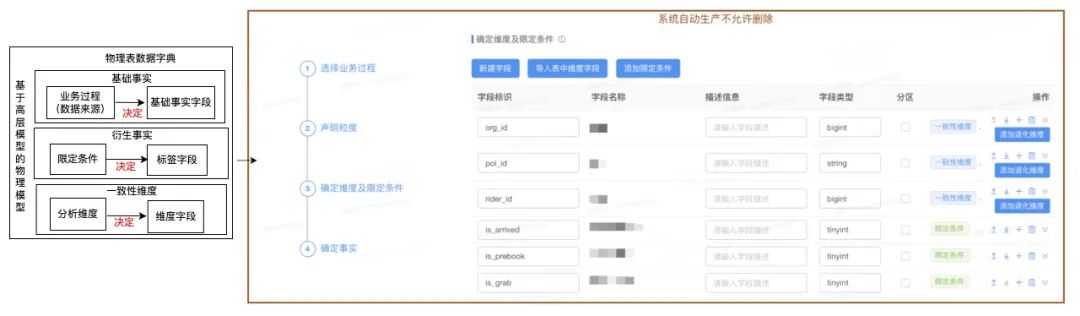
基于高层模型设计环节确定的分析度量和维度,自动生成物理表对应的数据字典,确保模型设计与终物理落地的一致性,从源头杜绝不规范的开发。
4.3 上线前卡点
相同指标不同出处的数据一致性验证,将来自不同出处的相同指标上卷到相同维度,它们具有相同的数值; 业务定义与具体实现的一致性验证,此类验证主要针对码值类字段,具体数值必须与其对应的业务定义一致; 研发合规的约束类验证,例如,主键必须、全表扫描、代码流程分支覆盖(T+1重导、批量重导、全量重导); 变更时的级联影响,包括下游的生产任务影响和消费任务影响。
5 总结

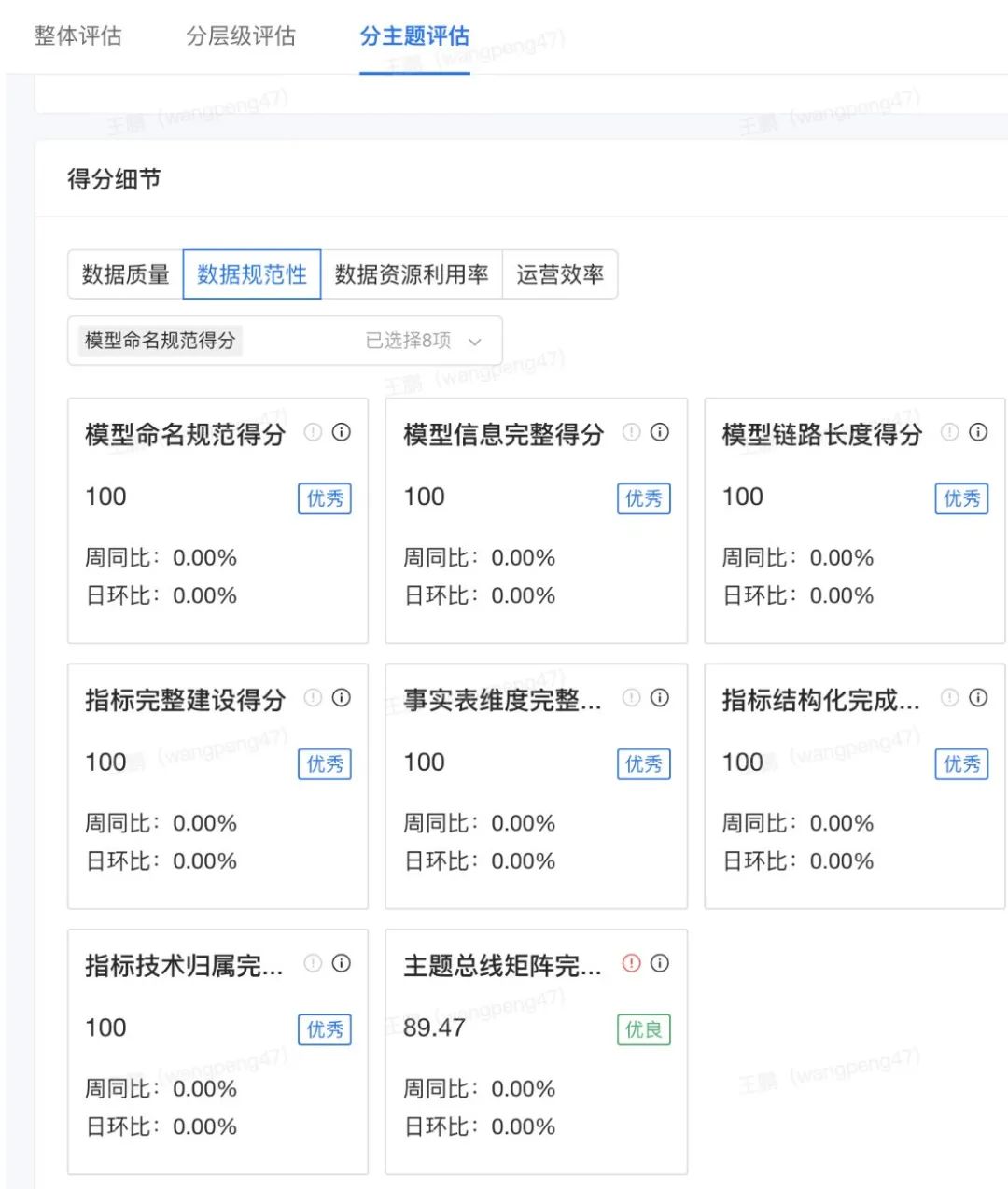
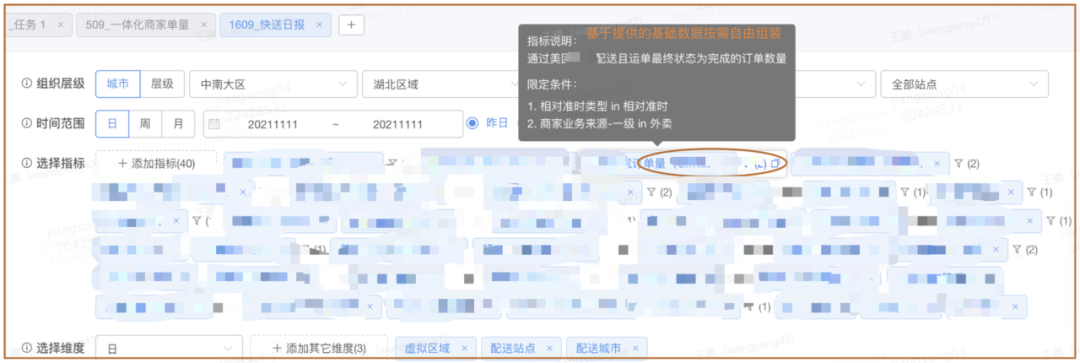
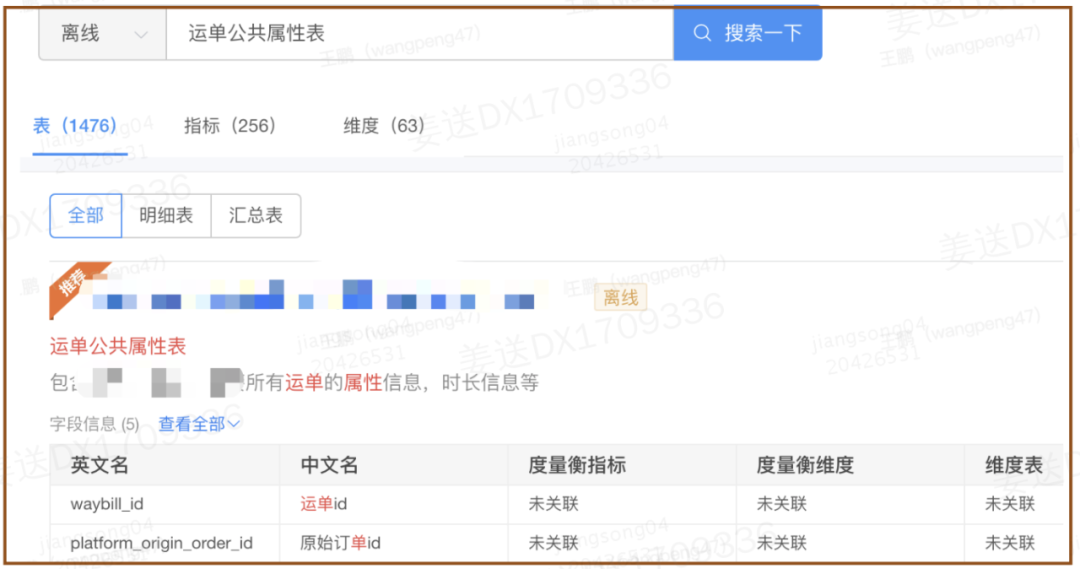 图13 数据可检索
图13 数据可检索