ProxySQL 能为数据库的高可用和拓展提供以下两点服务:
故障转移。当主节点发生故障时,MGR 通过选举提升另一节点为主节点。亟需前端代理为客户端提供统一的入口,避免连接失败。
读写分离。将读写请求分流至不同的数据库后端,灵活应对各种读写场景。
本文实验采用 ProxySQL+MySQL+MGR 的架构。包括两台 ProxySQL 服务及三台 MySQL 服务
操作系统:Debian GNU/Linux 10 (buster)
Proxysql 版本:2.1.1
MySQL 版本:5.7.29
层是 runtime,即运行时配置,用户无法直接操作更改,必须从 memory 中加载。
第二层是 memory,用户通过此界面查看 / 编辑 ProxySQL 配置表。
第三层是 disk/config,用于持久化 memory 中的配置。
-
用户表 mysql_users
注:用户表并不实现 host/ip 限制,在规则表中实现

2. 群组表 mysql_group_replication_hostgroups

3.服务表mysql_server
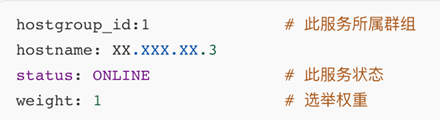
在编辑配置表后,LOAD XXX TO RUNTIME 来加载到运行时,SAVE XXX TO DISK 来持久化到磁盘
注:Mysql 的组复制搭建及配置此处不再赘述,可参照 https://dev.mysql.com/doc/refman/5.7/en/group-replication.html
规则表 mysql_query_rules:

命中规则状态查看表

下面讨论几种转发方式(以下 query 都为自动提交,不显式开启事务):
2.3.1 根据用户转发
当不配置任何规则时,根据用户表的 default_hostgroup,default_schema 配置转发至对应组和数据库
2.3.2 根据访问 ip 转发
根据访问 ip 转发,可实现 ip 白名单限制
设置一条白名单(注意 rule_id 小,并且 apply 设置为 0)
insert into mysql_query_rules (rule_id,active,client_addr,match_digest,flagOUT,apply)values(1,1,'XX.XXX.XX.3','.',10,0);-
设置其他转发规则,且 flagIN 承接白名单的 flagOUT
insert into mysql_query_rules(rule_id,active,username,match_digest,destination_hostgroup,flagIN,apply) values(100,1,'test','^select',1,10,1); -
插入一条禁止其他所有 ip 访问的黑名单 (rule_id 设置为 max(rule_id),并且 apply=1)
insert into mysql_query_rules (rule_id,active,match_digest,error_msg,apply)values(100000,1,'.','Access banned, maybe your IP is not allowed to do this',1);查询效果
1、命中白名单

2.命中黑名单
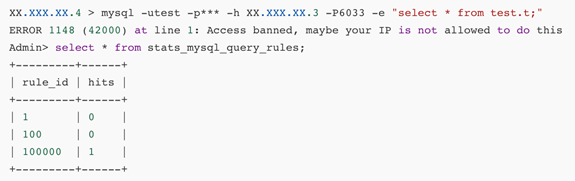
缺陷:只支持 ip,不支持域名
2.3.3 根据数据库转发
插入两条规则 (mysql_user 中只设置 default_hostgroup,不设置 default_schema)
insert into mysql_query_rules(rule_id,active,username,schemaname,match_digest,destination_hostgroup,flagIN,apply) values(100,1,'test','A',^select',1,10,1);insert into mysql_query_rules(rule_id,active,username,schemaname,match_digest,destination_hostgroup,flagIN,apply) values(100,1,'test','B','^select',3,10,1);
分别测试了 SQL
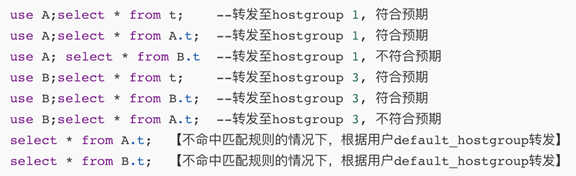
总结:不符合预期
不利用 use databases 并且不命中其他规则,默认转发到用户 default_hostgroup
Use database,不论后面跟什么,都以规则中设置的 destination_hostgroup 为准
2.3.4 根据规则转发
有效的规则设置可以帮助实现读写分离

说明:在 mysql_query_rules 中的 match_digest/match_pattern 字段设置正则匹配规则,优先匹配 match_pattern
插入两条匹配规则:
insert into mysql_query_rules(rule_id,active,username,match_pattern,destination_hostgroup,flagIN,apply) values(100,1,'test','^insert',1,10,1);insert into mysql_query_rules(rule_id,active,username,match_pattern,destination_hostgroup,flagIN,apply) values(200,1,'test','^select',3,10,1);
sql 执行效果

2.3.5 根据耗时语句重写规则
proxysql 的语句重写是规则转发的一重要特性。proxysql 对 query 进行指纹化处理后,统计查询耗时。
用户通过统计信息可以重新分配查询路由或者重写 query
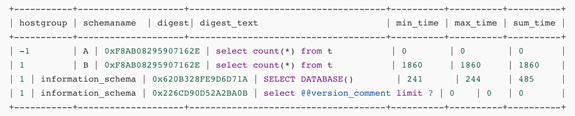
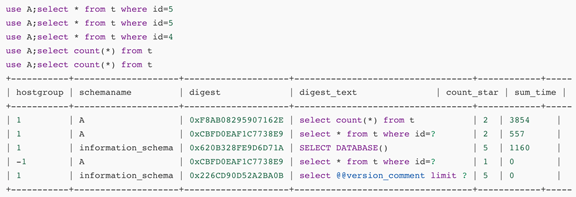
查看统计信息

可以看到第二条查询语句耗时较长,将其特殊转发至其他组
insert into mysql_query_rules (rule_id,active,username,flagIN,digest,destination_hostgroup,apply) values (100,1,'test',0,'0x681748B5ABB3CFCA',3,1);
-
再次观察,此 query 被转发至群组 3

2.3.6 查询缓存
说明:每个查询缓存记录的 key 是根据 username + schemaname +SQL 做 hash 运算出来的
这里的 SQL 是完整的 包含参数SQL 语句,而 非参数化后的语句,如果 SQL 语句进行了重写,则使用重写后的完整的 SQL 语句参与 hash 运算,即相同 digest 的语句只要参数不相同,会分别缓存
根据查询用户全部进行缓存
INSERT INTO mysql_query_rules (active,username,cache_ttl) VALUES (1,"test",120000);
只要是 test 用户的查询语句都会进入缓存,hostgroup 值为 -1

根据数据库进行缓存
只对 A 数据库的查询进行缓存
根据查询规则进行缓存
update mysql_query_rules set match_pattern='^select \* from';
前后对比
select count(*) 始终不缓存
select * from t where id=?根据 id 的值不同,次不缓存,第二次缓存
proxysql 的另一个重要功能,即在发生故障转移时,为客户端提供同一的入口。本节讨论 mysql 服务节点异常和网络异常情况下,proxysql 对于读写流量的处理结果。
本实验的 MGR 结构为单主模式,一台写组 + 两台读组

写服务 down
1))停掉 XX.XXX.XX.3 上的 mysql 进程

MGR 自动推举出新的 primary server,并将此服务的 read_only 变量设置为 NO,ProxySQL 通过监控自动监测并更新服务信息
2)把挂掉的机器拉起来,开启组复制,它作为读节点重新加入

读写请求都正常转发至写组
-
一读一写服务 down
剩下的一个读节点提升为写节点,同样写读请求可以正常转发。
Proxysql 参数说明:
监视 mysql 后端状况
mysql-monitor_connect_interval: 代理的 Monitor 模块尝试连接到所有 MySQL 服务器以检查它们是否可用的时间间隔。默认 600ms.
mysql-monitor_connect_timeout: 连接超时时间,默认 2000ms,
Proxysql 监视组复制参数:
mysql-monitor_groupreplication_healthcheck_timeout:监控组复制成员是否健康的阈值时间, 默认 800ms
mysql-monitor_groupreplication_healthcheck_interval: 监视组复制状态的心跳间隔,如果成员状态不可得,则被暂时置为 shunned(由 mysql_galera_hostgroups.max_transactions_behind 列控制),默认 1000ms
mysql-monitor_groupreplication_healthcheck_max_timeout_count: 设置 ProxySQL 在脱机之前在组复制节点上进行超时检查的大次数。默认 3 次
Mysql 参数说明
group_replication_unreachable_majority_timeout:
注意:mysql5.7 默认成员被驱逐的时间限制是 5s
Mysql8.0 可以设置 group_replication_member_expel_timeout=N,说明在 5s 没有响应之后,再等待 Ns 后驱逐
模拟网络延迟方法
注意不要超过 10s,否则 ssh 也连不上了
sudo tc qdisc add dev eth0 root netem delay 10s
恢复
sudo tc qdisc del dev eth0 root
2.4.1 读组延迟
-
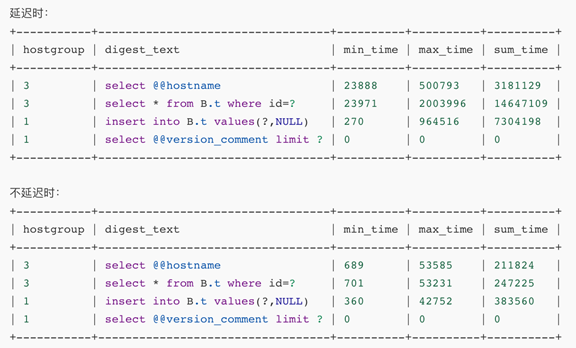
参数 1: 网络延迟 0.5s,但是还没达到被 shunned(ProxySQL) 的时限 (1s)

表现: 可以正常读写,但是出现了读写都出现了延迟,观察 max_time(1 秒 =1000 毫秒 =1000000 微秒,输出结果为微秒)
原因:此时 mgr 和 proxysql 都认为机器状况正常,所以正常地分别转发到两个读组。
-
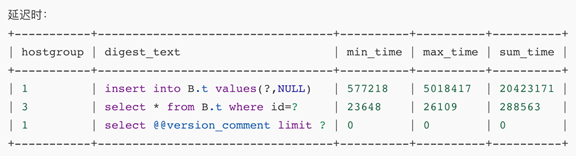
参数 2: 网络延迟 1s,达到被 shunned 的时限 (800ms)
查看延迟情况: 可以正常读写,但是 insert 语句耗费时间比较长,select 语句时间正常。
原因:因为 mgr 并没有断掉,所有 mgr 机制要求全部的成员都插入了数据,才能够返回。而 select 语句全部被转发到不延迟的读组。
-
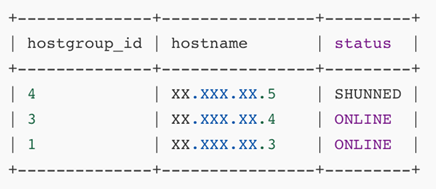
参数 3:网络延迟 6s,节点被驱逐出 mgr
观察proxysql日志:
MySQL_Monitor.cpp:1543:monitor_group_replication_thread(): [WARNING]XX.XXX.XX.5:3306 : group replication health check timeout count 3. Maxthreshold 3.
MySQL_Monitor.cpp:1561:monitor_group_replication_thread(): [ERROR] ServerXX.XXX.XX.5:3306 missed 3 group replication checks. Number retries 3, Assumingoffline
观察mysql日志:
2021-05-18T10:55:59.505363+08:00 0 [ERROR] Plugin group_replication reported:'Member was expelled from the group due to network failures, changing memberstatus to ERROR.'

表现:读写仍比不延迟时快了一点,因为只剩一个读组。
2.4.2 读组全部延迟
延迟 0.5s 与上一组实验类似,读写延迟
延迟 6s 可以预测只剩下一台读组,请求都转发至此
-
两台读组都延迟 1s

这时,读请求被卡死。写请求正常
mysql-utest -ptest -h XX.XXX.XX.3 -P6033 -e"select * from B.t where id=1"
ERROR 9001 (HY000) at line 1: Max connect timeout reached while reachinghostgroup 3 after 10000ms
恢复网络后,读请求正常转发
2.4.3 写组延迟
延迟 0.5s 与上一组实验类似,读写延迟
-
写组延迟 1s

表现:写请求无法写入,读请求正常

写组延迟 6s

XX.XXX.XX.5被提升为写组,读写请求正常转发

表现:读写请求正常转发,其中一台读组提升为写组
总结
网络延迟 800ms 以内,会造成读写请求延迟,但是功能正常
网络延迟 800ms~5s 内,可能造成读写失败。是 proxysql 和 mgr 判断 mysql 服务不正常的时长差异造成。
网络延迟 5s 以上,proxysql 和 mgr 均判定为不正常状态。读写正常。
方法:可通过 proxysql 参数mysql-monitor_groupreplication_healthcheck_timeout来调整状态健康监测时长,而 mgr 目前没有调整为 5s 内的办法。
本文通过对 proxysql+mgr 架构的测试,得出能够基本满足故障转移和读写分离需求的结论。
规则功能方面:
数据库转发功能无法支持 database.table 形式 sql。
规则配置时,需正确理解 digest, match_digest, match_pattern 的含义,推荐首先使用 match_pattern。
异常情况方面:
mysql 服务节点宕机,proxysql 和 mgr 能够实现正常的故障转移恢复
针对网络延迟严重情况,可能出现无法读或写情况。
作者简介:
林雅婷,网易游戏技术部数据库系统工程师。平时热衷研究关于MySQL的高可用架构、备份恢复、SQL调优等技术。
