前言
VictoriaMetrics 是一个支持水平扩展的时序数据库,可以作为 Prometheus的远端存储,并且实现了 PromSQL,可以直接通过 VictoriaMetrics 查询时序数据,避开 Prometheus 查询时的单点瓶颈。
部署Victoria Metrics 集群
VictoriaMetrics 集群版本的架构如下: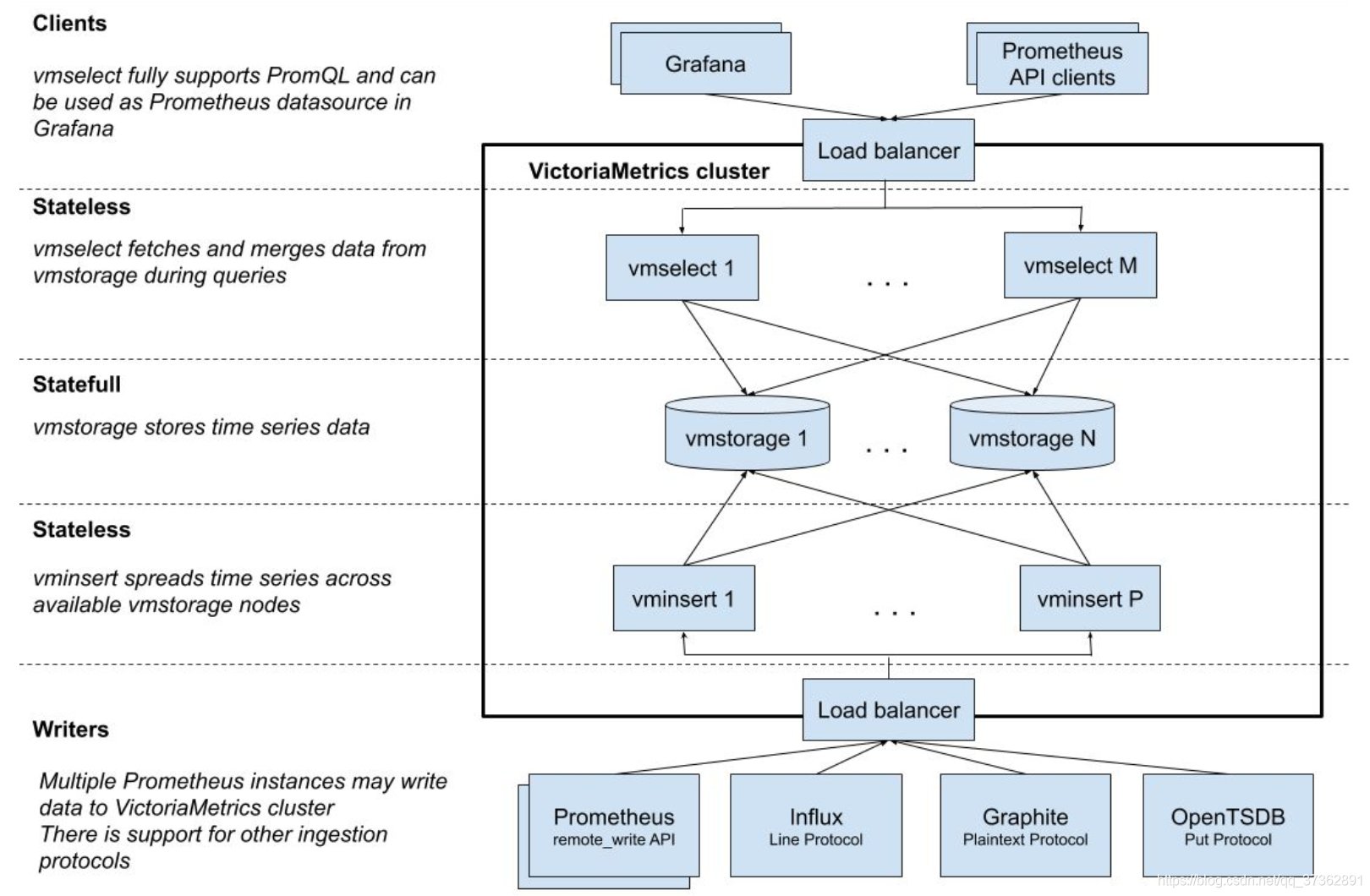
vminsert 和 vmselect 是无状态的写入、查询节点,vmstorage 是有状态的存储节点。数据平均分配到 vmstorage 节点,每个 vmstorage 分担一部分数据,没有冗余,如果 vmstorage 节点丢失,那么数据对应丢失。
三个组件的镜像:
victoriametrics/vminsert:v1.34.0-cluster
victoriametrics/vmselect:v1.34.0-cluster
victoriametrics/vmstorage:v1.34.0-cluster
vmstorage:
image: victoriametrics/vmstorage:v1.34.0-cluster
privileged: true
volumes:
- ./data/victoria:/data
command:
- "-storageDataPath=/data"
- "-retentionPeriod=1"
ports:
- "8482:8482"
- "8400:8400"
- "8401:8401"
vmselect:
image: victoriametrics/vmselect:v1.34.0-cluster
command:
- "-selectNode=vmselect:8481"
- "-storageNode=vmstorage:8401"
ports:
- 8481:8481/tcp
vminsert:
image: victoriametrics/vminsert:v1.34.0-cluster
command:
- "-storageNode=vmstorage:8400"
ports:
- "8480:8480"分别访问下面三个地址,查看组件的状态数据:
insert: http://127.0.0.1:8480/metrics、
select: http://127.0.0.1:8481/metrics、
storage:http://127.0.0.1:8482/metrics、配置Prometheus
cd /usr/local/src/config/
vim prometheus.yml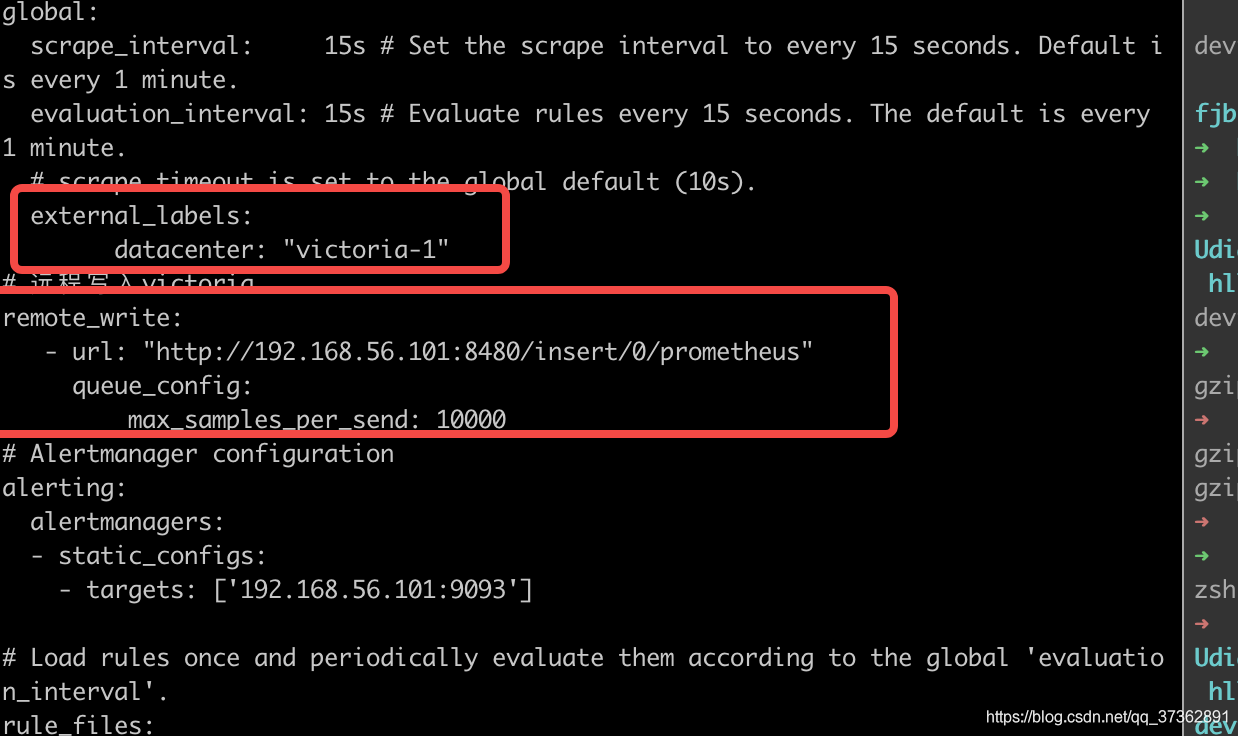
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://10.30.54.80:8888/alertMessage/receive'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
[root@localhost config]# ls
alertmanager.yml defaults.ini node_down.yml prometheus.yml test.tmpl
[root@localhost config]# cat prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
external_labels:
datacenter: "victoria-1"
# 远程写入victoria
remote_write:
- url: "http://192.168.56.101:8480/insert/0/prometheus"
queue_config:
max_samples_per_send: 10000
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.56.101:9093']
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "node_down.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 用于配置victoria
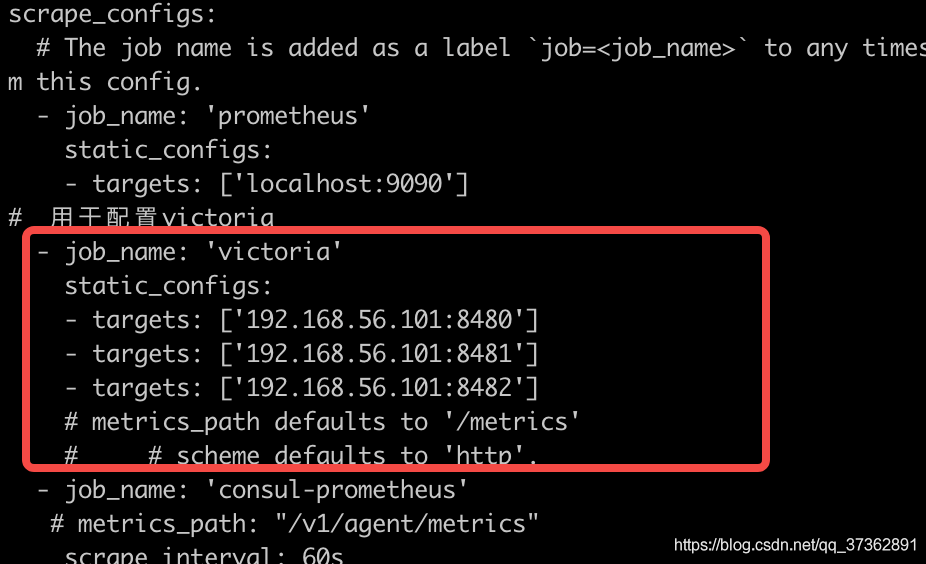
- job_name: 'victoria'
static_configs:
- targets: ['192.168.56.101:8480']
- targets: ['192.168.56.101:8481']
- targets: ['192.168.56.101:8482']
# metrics_path defaults to '/metrics'
# # scheme defaults to 'http'.
- job_name: 'consul-prometheus'
# metrics_path: "/v1/agent/metrics"
scrape_interval: 60s
scrape_timeout: 10s
scheme: http
params:
format: ['prometheus']
#static_configs:
# - targets:
# - 192.168.56.101:8500
consul_sd_configs:
- server: '192.168.56.101:8500'
services: []
relabel_configs:
- source_labels: [__metrics_path__]
separator: ;
regex: /metrics
target_label: __metrics_path__
replacement: /actuator/prometheus
action: replace
- source_labels: ['__meta_consul_tags']
regex: '^.*,metrics=true,.*$'
action: keep配置granfana验证
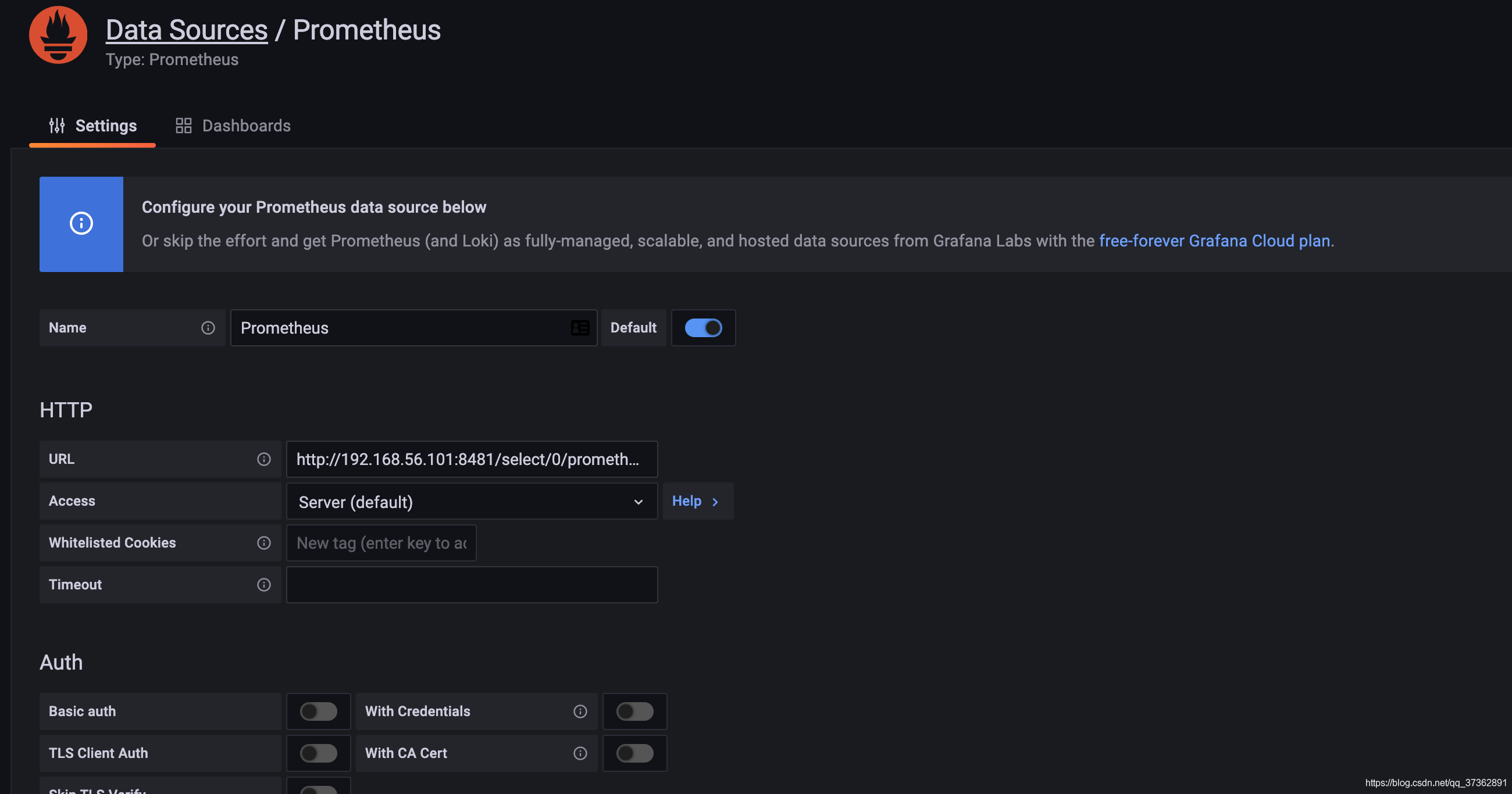
 3、查看面板
3、查看面板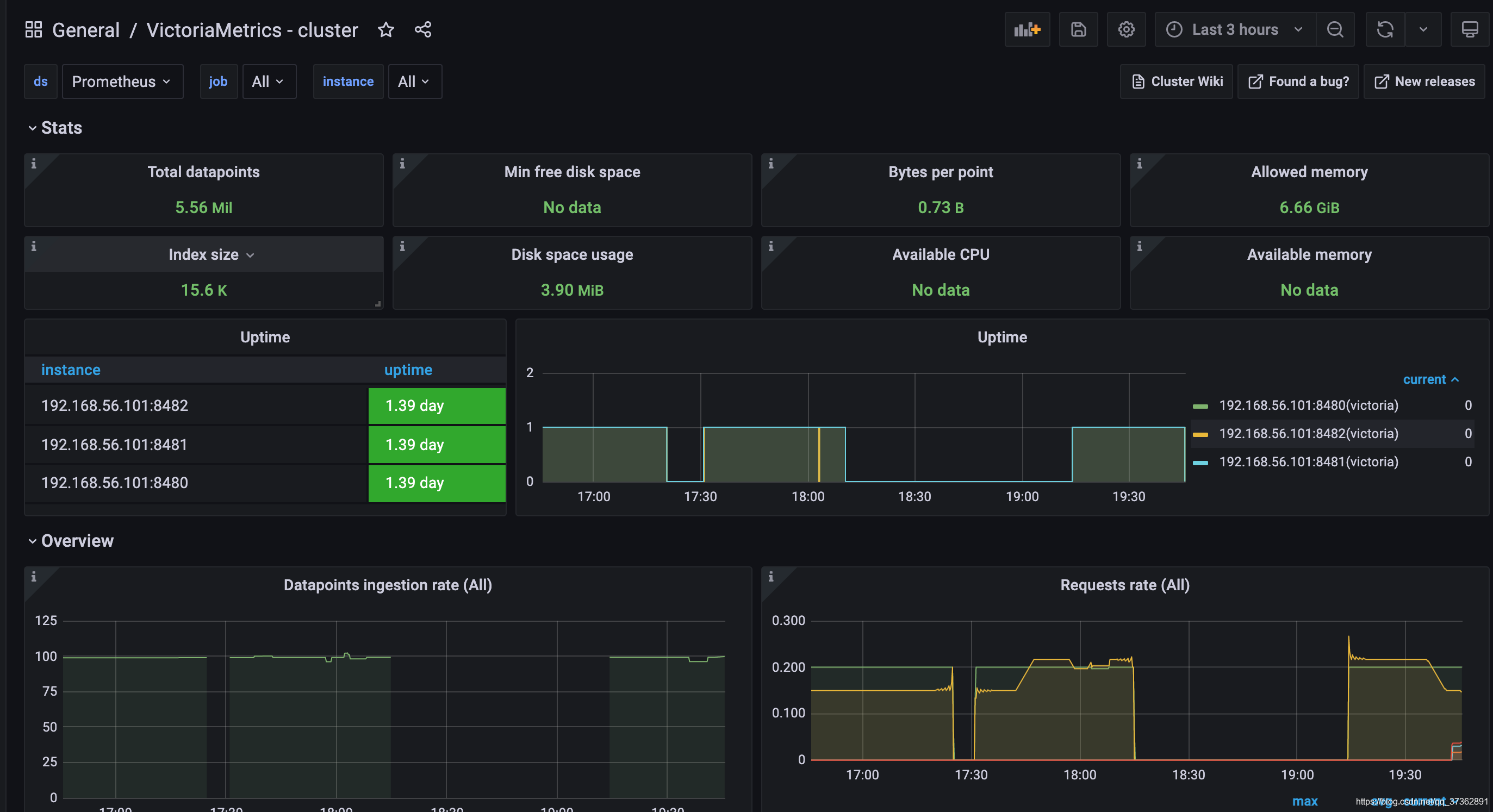
Victoria Metrics 的数据查询


通过 VictoriaMetrics 的 API 查询:
curl -g 'http://127.0.0.1:8481/select/0/prometheus/api/v1/series' --data-urlencode 'match[]=requests_total{}' |jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
10 236 100 208 100 28 17229 2319 --:--:-- --:--:-- --:--:-- 20800
{
"status": "success",
"data": [
{
"__name__": "requests_total",
"datacenter": "victoria-1",
"job": "consul-prometheus",
"instance": "10.30.54.80:8080",
"application": "fast-commmon-prometheus-example",
"status": "success"
}
]
}原文链接:https://blog.csdn.net/qq_37362891/article/details/119577204
