TimescaleDB介绍
TimescaleDB官方网站:https://www.timescale.com/TimescaleDB官方文档:https://docs.timescale.com/latest/introduction易于使用:
1.PostgreSQL支持所有SQL的完整SQL接口(包括二级索引,基于非时间的聚合,子查询,JOIN,窗口函数)。2.连接到任何使用PostgreSQL的客户端或工具,无需更改。3.面向时间的特性、API函数和优化。4.对数据保留策略的强大支持。
可扩展:
1.透明的时间/空间分区,可用于扩展(单节点)和扩展(即将推出)。2.高数据写速率(包括批量提交、内存索引、事务支持、数据回填支持)3.在单个节点上设置大小合适的块(二维数据分区),以确保即使在大数据量的情况下也能快速摄取数据。4.跨块和服务器的并行操作。
什么是时间序列数据?
我们一直在讨论的“时间序列数据”是什么,它与其他数据有何不同? 许多应用程序或数据库实际上采取了一种过于狭隘的观点,并将时间序列数据等同于某种特定形式的服务器指标:
Name: CPUTags: Host=MyServer, Region=WestData:2017-01-01 01:02:00 702017-01-01 01:03:00 712017-01-01 01:04:00 722017-01-01 01:05:01 68
但事实上,在许多监控应用程序中,不同的指标常常被收集在一起(例如,CPU、内存、网络统计数据、电池寿命)。因此,将每个度量单独考虑并不总是有意义的。考虑这个替代的“更广泛的”数据模型,它维护同时收集的度量之间的相关性。
Metrics: CPU, free_mem, net_rssi, batteryTags: Host=MyServer, Region=WestData:2017-01-01 01:02:00 70 500 -40 802017-01-01 01:03:00 71 400 -42 802017-01-01 01:04:00 72 367 -41 802017-01-01 01:05:01 68 750 -54 79
这类数据属于一个范围更广的类别,无论是传感器的温度读数、股票价格、机器状态,甚至是应用程序的登录次数。 时间序列数据是表示系统、过程或行为随时间如何变化的数据。
时间序列数据的特征
如果你仔细观察它是如何产生和摄入的,有一些重要的特征是像TimescaleDB这样的时间序列数据库通常利用的:
•以时间为中心:任何数据记录都有一个时间戳•只追加数据:存储TimescaleDB的数据几乎完成是只追加数据•近的:新数据通常是关于近的时间间隔,我们很少更新或补全关于旧时间间隔的丢失数据。
数据的频率或规律性就不那么重要了;它可以每毫秒或每小时收集一次。它也可以定期或不定期地收集(例如,当某个事件发生时,而不是在预先定义的时间)。但是数据库不是早就有时间字段了吗?与其他数据(如标准关系“业务”数据)相比,时间序列数据(以及支持它们的数据库)之间的一个关键区别是,对数据的更改是插入,而不是覆盖。
数据模型
TimescaleDB作为一个支持完整SQL的关系数据库,TimescaleDB支持可以针对不同用例进行优化的灵活数据模型。这使得TimescaleDB与大多数其他时间序列数据库有所不同,后者通常使用“窄表”模型。具体来说,TimescaleDB可以同时支持宽表和窄表模型。在这里,我们以物联网(IoT)为例,讨论这两个模型的不同性能权衡和含义。想象一下,由1000个物联网设备组成的分布式团队,旨在以不同的时间间隔收集环境数据。这些数据包括:
•标识符 Identifiers: device_id/设备ID, timestamp/时间戳•元数据 Metadata: location_id/位置ID, dev_type/开发类型, firmware_version/固件版本, customer_id/客户ID•设备参数 Device metrics: cpu_1m_avg/1分钟CPU平均值, free_mem/空闲内存, used_mem/已用内存, net_rssi, net_loss/网络寿命, battery/电池•传感器指标 Sensor metrics: temperature/温度, humidity/湿度, pressure/压力, CO, NO2, PM10
例如,您输入的数据可能如下所示:
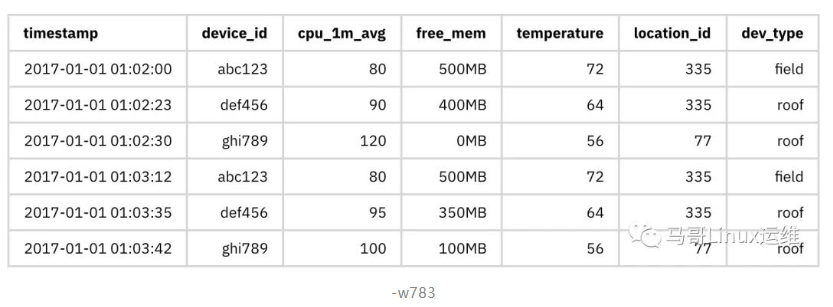
现在,让我们看看建模这些数据的各种方法
Narrow-table模型(狭窄模型)
大多数时间序列数据库将以下列方式表示这些数据: 将每个指标表示为一个单独的实体(例如,将cpu_1m_avg和free_mem表示为两个不同的东西) 存储该度量的“时间”、“值”对序列 将元数据值表示为与度量/标记集组合相关联的“标记集” 在这个模型中,每个度量/标记集组合被认为是包含时间/值对序列的单个“时间序列”。
使用上面的示例,这种方法将产生9个不同的“时间序列”,每个“时间序列”由一组惟一的标记定义。
1. {name: cpu_1m_avg, device_id: abc123, location_id: 335, dev_type: field}2. {name: cpu_1m_avg, device_id: def456, location_id: 335, dev_type: roof}3. {name: cpu_1m_avg, device_id: ghi789, location_id: 77, dev_type: roof}4. {name: free_mem, device_id: abc123, location_id: 335, dev_type: field}5. {name: free_mem, device_id: def456, location_id: 335, dev_type: roof}6. {name: free_mem, device_id: ghi789, location_id: 77, dev_type: roof}7. {name: temperature, device_id: abc123, location_id: 335, dev_type: field}8. {name: temperature, device_id: def456, location_id: 335, dev_type: roof}9. {name: temperature, device_id: ghi789, location_id: 77, dev_type: roof}
这样的时间序列的数量与每个标记的基数的叉乘成比例。即(#names) × (#device ids) × (#location ids) × (device *).随着基数的增加,一些时间序列数据库会遇到困难,终限制了可以存储在单个数据库中的设备类型和设备的数量。
TimescaleDB支持窄模型,并且不像其他时间序列数据库那样受到基数限制。如果您独立地收集每个度量,那么窄模型是有意义的。它允许您在添加新标记的同时添加新的指标,而不需要进行正式的模式更改。
但是,如果您正在收集许多具有相同时间戳的度量,那么窄模型的性能就不高,因为它需要为每个度量编写一个时间戳。这终导致更高的存储和摄入要求。此外,关联不同度量的查询也更复杂,因为您希望关联的每个额外度量都需要另一个连接。如果您通常同时查询多个指标,那么以宽表格式存储它们会更快更容易,我们将在下一节介绍这种格式。
Wide-table模型(宽度模型)
TimescaleDB很容易支持宽表模型。在这个模型中,跨多个指标的查询更容易,因为它们不需要连接。而且,ingest更快,因为只为多个指标编写一个时间戳。一个典型的宽表模型将匹配一个典型的数据流,在这个数据流中,在给定的时间戳中收集多个指标:
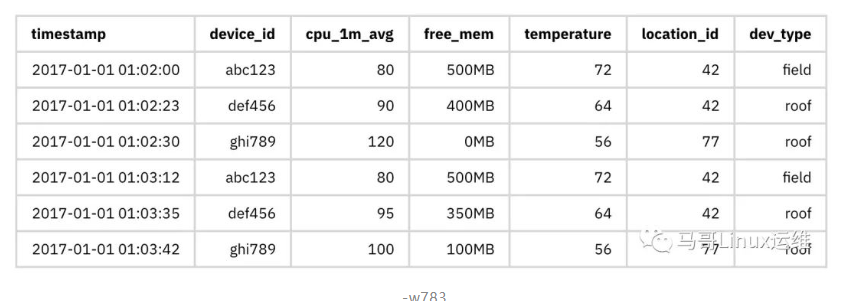
在这里,每一行是一个新的读数,在给定的时间有一组测量值和元数据。这使我们能够保留数据中的关系,并提出比以前更有趣或更具探索性的问题。当然,这不是一种新格式:它是关系数据库中常见的格式。
架构与概念
描述
TimescaleDB是作为PostgreSQL上的扩展实现的,这意味着它在整个PostgreSQL实例中运行。扩展模型允许数据库利用PostgreSQL的许多属性,如可靠性、安全性和与各种第三方工具的连接性。与此同时,TimescaleDB通过在PostgreSQL的查询规划器、数据模型和执行引擎中深入添加挂钩,利用了对扩展的高度定制。从用户的角度来看,TimescaleDB公开了看起来像单个表(hypertables称为超表)的内容,hypertables超表实际上是许多单独表(chunks称为数据块)的抽象或虚拟视图。
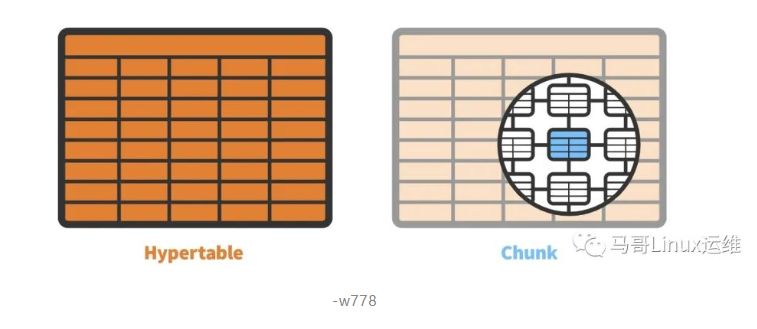
Chunk是通过将Hypertable的数据划分为一个或多个维度来创建的:所有Hypertable都按时间间隔进行分区,还可以通过设备ID、位置、用户ID等键进行分区。我们有时称之为跨越“时间和空间”的划分。
术语
Hypertables 与数据交互的主要点是hypertable,它是跨越所有空间和时间间隔的单个连续表的抽象,因此可以通过标准SQL查询它。几乎所有与TimescaleDB的用户交互都是与hypertable进行的。创建表和索引、修改表、插入数据、选择数据等等都可以(也应该)在hypertable上执行。hypertable是由具有列名称和类型的标准模式定义的,至少有一列指定时间值,一列(可选)指定附加的分区键。单个TimescaleDB部署可以存储多个Hypertables,每个Hypertables具有不同的模式。在TimescaleDB中创建Hypertables需要两个简单的SQL命令:CREATE TABLE (使用标准SQL语法),然后选择create_hypertable()
Chunks 在内部,TimescaleDB自动将每个hypertable分割为chunk,每个chunk对应于特定的时间间隔和分区键空间的一个区域(使用散列)。这些分区是不相交的(不重叠的),这有助于查询计划器小化它在解析查询时必须接触的块集。每个chunk都是使用一个标准数据库表实现的,(在PostgreSQL内部,chunk实际上是“父”hypertable的“子表”。) chunk的大小是正确的,确保在插入期间表的索引的所有 B-树 都可以驻留在内存中。当修改这些树中的任意位置时,这避免了抖动。此外,通过避免过大的chunk,我们可以在根据自动保留策略删除数据时避免高代价的“清理”操作。运行时可以通过简单地删除chunk(内部表)而不是删除单独的行来执行这些操作。
Native Compression
压缩由TimescaleDB的内置作业调度器框架提供支持。我们利用它跨超表异步地将单个chunk从未压缩的基于行的表单转换为压缩的柱状表单:当chunk足够大时,将以事务方式将其从行转换为柱状表单。使用本机压缩,即使TimescaleDB中的单个hypertable将以行和列的形式存储数据,用户也不需要为此担心:在查询数据时,他们将继续看到基于行的标准模式。这类似于在已解压缩的柱状数据上构建视图。TimescaleDB启用了这一功能,方法是(1)使用从柱状格式解压的数据透明地附加存储在标准行格式中的数据,以及(2)在查询时透明地解压从选定行的单个列。在查询期间,未压缩的块将被正常处理,而来自压缩块的数据将在查询时首先被解压缩并转换为标准行格式,然后再附加或合并为其他数据。这种方法与TimescaleDB所期望的一切兼容,例如关系JOIN和分析查询,以及积极的约束排除以避免处理块。
开始使用TimescaleDB
TimescaleDB在许多方面的行为与标准PostgreSQL数据库类似:
•在PostgreSQL服务器上与其他时间表和PostgreSQL数据库共存。•使用SQL作为其接口语言。•包含标准数据库对象,如表、索引和触发器。•使用常见的PostgreSQL连接器到第三方工具。
数据库实现这种同步的方式是将其打包为PostgreSQL扩展,从而将标准的PostgreSQL数据库转换为一个计时器
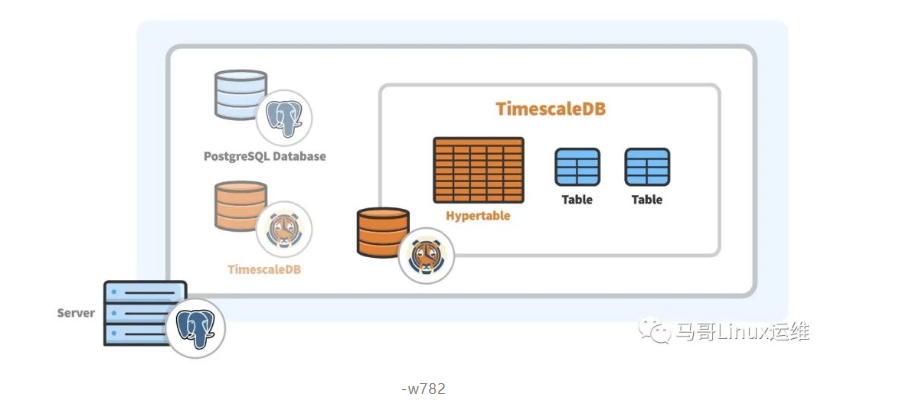
除了PostgreSQL的优势外,TimescaleDB提供的优势主要与处理时间序列数据有关。这些优点在与Hypertable交互时容易看到,Hypertable的行为与普通表类似,但即使在将存储扩展到通常无法承受的数据量时仍能保持高性能。Hypertable可以进行正常的表操作,包括与标准表的连接。
开始安装TimescaleDB
因为TimescaleDB是以插件的形式基于PostgreSQL之上,所以要先部署PostgreSQL后再进行部署TimescaleDB
本地环境基于:CentOS Linux release 7.6.1810 (Core) 1)下载PostgreSQL yum源
sudo yum install -y https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm2)安装PostgreSQL
sudo yum install -y postgresql11-server postgresql11 postgresql-devel3) 初始化PostgreSQL数据库并设置为开机自动启动
sudo /usr/pgsql-11/bin/postgresql-11-setup initdbInitializing database ... OKsudo systemctl enable postgresql-11 && sudo systemctl start postgresql-11
PostgreSQL默认监听5432端口 PostgreSQL默认数据存储路径/var/lib/pgsql/11/data/
4) 添加timescaledb的yum源*
sudo tee /etc/yum.repos.d/timescale_timescaledb.repo <<EOL[timescale_timescaledb]name=timescale_timescaledbbaseurl=https://packagecloud.io/timescale/timescaledb/el/7/\$basearchrepo_gpgcheck=1gpgcheck=enabled=1gpgkey=https://packagecloud.io/timescale/timescaledb/gpgkeysslverify=1sslcacert=/etc/pki/tls/certs/ca-bundle.crtmetadata_expire=300EOL
5) 安装Timescaledb
sudo yum clean allsudo yum makecachesudo yum install -y timescaledb-postgresql-11
6) 配置postgresql.conf 使用postgres启动时加载timescaledb
sudo echo "shared_preload_libraries = 'timescaledb'" >> /var/lib/pgsql/11/data/postgresql.conf7)重启PostgreSQL
sudo systemctl restart postgresql-118) 修改默认用户名密码
su - postgres-bash-4.2$ psqlpostgres=# ALTER USER postgres WITH PASSWORD 'TimescaleDB@ZABBIX#2020!';ALTER ROLEpostgres=# \q-bash-4.2$ exitlogout
9) 修改postgres的监听地址,默认只能为本地连接
sudo echo "listen_addresses = '*'" >> /var/lib/pgsql/11/data/postgresql.conf10) 允许所有地址 来连接该数据库 编辑pg_hba.conf文件,然后到后,把认证模式改为如下,这个地方是个坑,务必与下方改为一致
sudo vim /var/lib/pgsql/11/data/pg_hba.conf# TYPE DATABASE USER ADDRESS METHOD# "local" is for Unix domain socket connections onlylocal all all trust# IPv4 local connections:host all all 127.0.0.1/32 md5host all all 0.0.0.0/ md5# IPv6 local connections:host all all ::1/128 trust# Allow replication connections from localhost, by a user with the# replication privilege.local replication all peerhost replication all 127.0.0.1/32 trusthost replication all ::1/128 trust
11) 重启postgresql数据库
sudo systemctl start postgresql-1112) 测试数据库远端登录
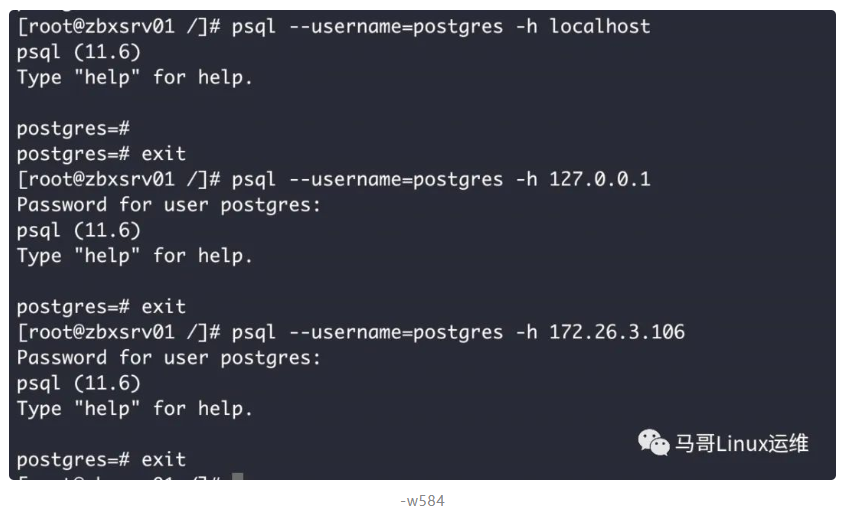 来源 https://mp.weixin.qq.com/s/rf2e202dq2aRYQjFE0JYqA
来源 https://mp.weixin.qq.com/s/rf2e202dq2aRYQjFE0JYqA
