熟悉Greenplum的小伙伴都知道,Greenplum是一款分布式数据库。MPP架构相较于传统的SMP架构更能快速响应分析型应用的需求。利用MPP架构的优势,Greenplum可以处理海量数据。2021数据库大咖讲坛第6期《数据库性能优化技巧与-佳实践》活动中,来自Greenplum中文社区的阿福(苑泽福)发表演讲《Greenplum数据库优化技巧与实践》。下面让我们通过本篇文章回顾一下精华内容。
本篇内容主要包括三个部分,从架构入手,延伸到Greenplum的功能特点,针对不同的功能特点提出针对性优化思路,并结合案例帮助大家快速了解Greenplum性能提升的窍门。
Greenplum架构解析
Greenplum重点功能
Greenplum优化要点
一、Greenplum架构解析
从系统架构说起
主流的系统架构主要有三类:对称多处理结构(SMP),非一致存储访问结构(NUMA)和海量并行处理架构(MPP)。其对应的特点与不足分别如下:
SMP:
较为典型的包括Oracle、MySQL等
特点:
存储,包括CPU、内存和IO都是共享的。在一台机器就能支撑起整个网站的Web时代,SMP架构是非常流行的,足以支撑前端业务。
不足:
扩展能力有限。随着业务的扩大,数据量的增长,在业务场景上就有了很大的限制。
NUMA
特点:
拥有多个CPU模块,每个模块由多个CPU组成,有独立的本地内存;节点之间通过互联模块进行连接和信息交互,较好解决SMP系统的扩展问题。
不足:
互联模块访问效率和本地内存访问不在一个效率层级,系统性能无法随着CPU数线性增加。
MPP
这个是我们今天要讲解的重点,也是Greenplum的架构。
特点:
MPP是采用SMP组成的多个服务器,多个服务器共同完成任务。在硬件使用上可以发挥SMP架构的优势,多节点并行处理时,内存、CPU、网络、IO、磁盘均不共享,即Share-Nothing架构,每个节点只访问本地内存和存储,节点信息交互和节点本身是并行处理的。所有数据节点角色一样,可以提升并行计算能力。
不足:
MPP架构也存在一些不足,如果多台服务器在进行并行处理时,如果有一台服务器出现部分性能下降,会影响到整个MPP集群的性能,即木桶的短板效应。MPP架构集群规模不能过大,不能像Hadoop那样,几千个集群同时运行某个查询逻辑。此外,并发度不能过高。MPP架构正常情况下都是进行两阶段事务提交的,需要有一个事务汇总和底层事务查询的过程,如果并发过高,资源损耗会过大,会影响到整体系统的响应。
不同的系统架构有其擅长的应用场景,很难说某个架构更好,在其擅长的应用场景下,都可以发挥其优势。
Greenplum的MPP实现——架构优雅
在介绍完这三类主流系统架构,我们来看看Greenplum是怎么做的。Greenplum的MPP实现非常简洁优雅。
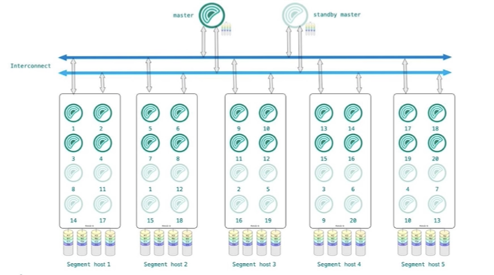
图中的架构可以被拆解为三部分来看,部分是上面的Master节点,第二部分是中间的高速交互网络,第三部分是下面的Segment 节点,是存储生产数据的地方,会利用多个不同的机器,将数据均匀分布在上面。例如图中使用了5台机器,数据会被均匀分布在这5台机器上,充分利用MPP架构的优势,5台机器同时运算,从而提高查询效率。
一切皆并行
Greenplum对标准SQL的支持非常完善。一个SQL执行后,经过Master节点会进行执行计划的拆分,下发到下面的n个节点中,并行处理。再到Master节点进行汇总。
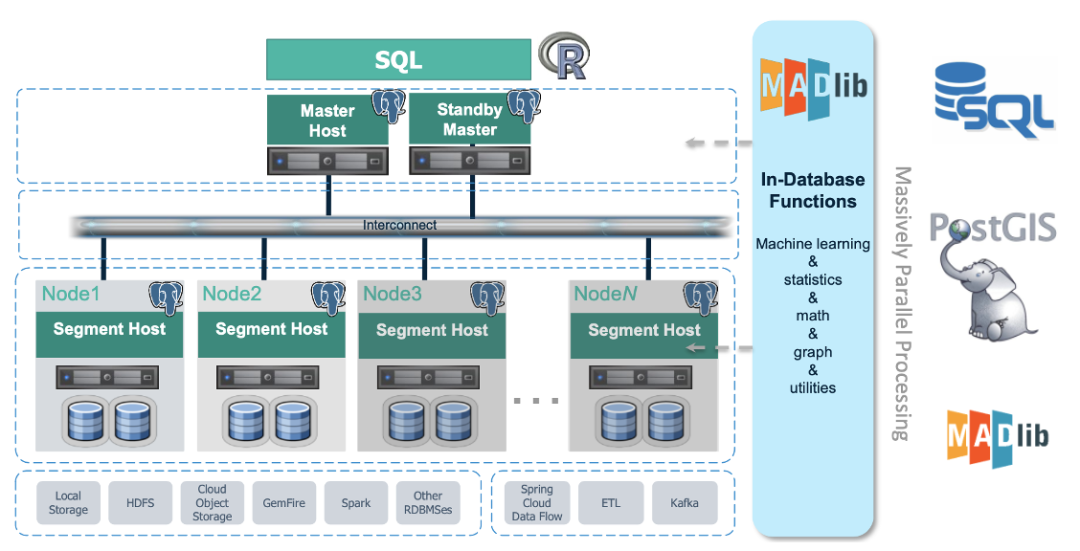
此外Greenplum具有对GIS数据的支持,可以实现对地理信息数据的处理。MADlib是Greenplum与UC Berkeley大学合作的一个开源机器学习库。Greenplum通过集成MADlib算法库,实现“in-database”数据分析和挖掘计算,数据无需搬到库外就可以进行快捷的挖掘分析,还可以利用MPP并行计算能力大幅提高数据分析数据挖掘的性能。
Greenplum在于外部系统对接时,例如Kafka、Spark等,数据的流入和流出均是并行的,会大大提高数据的入库和出库的效率。
使用Greenplum,您能获得什么?
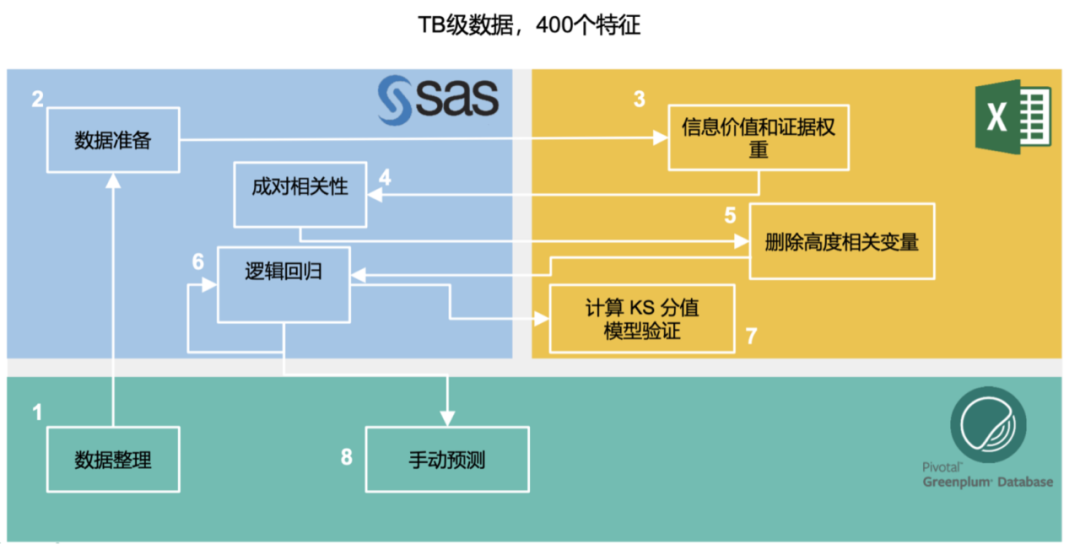
大家在做数据库选型时,通常会基于两个维度:功能和性能。这里给大家展现的是一个媒体数据分析的例子。在完全迁移到Greenplum之前,用户使用的是SAS和Excel来处理数据分析的工作,用Greenplum来进行数据整理和手动预测的工作。
但在这个过程中,处理性能遇到了瓶颈。于是,该用户便采用了我们提供的功能和计算模型来进行了一系列优化,去掉了SAS和Excel,把包括数据整理,特征生成,模型预测等功能全放进了一个库里。
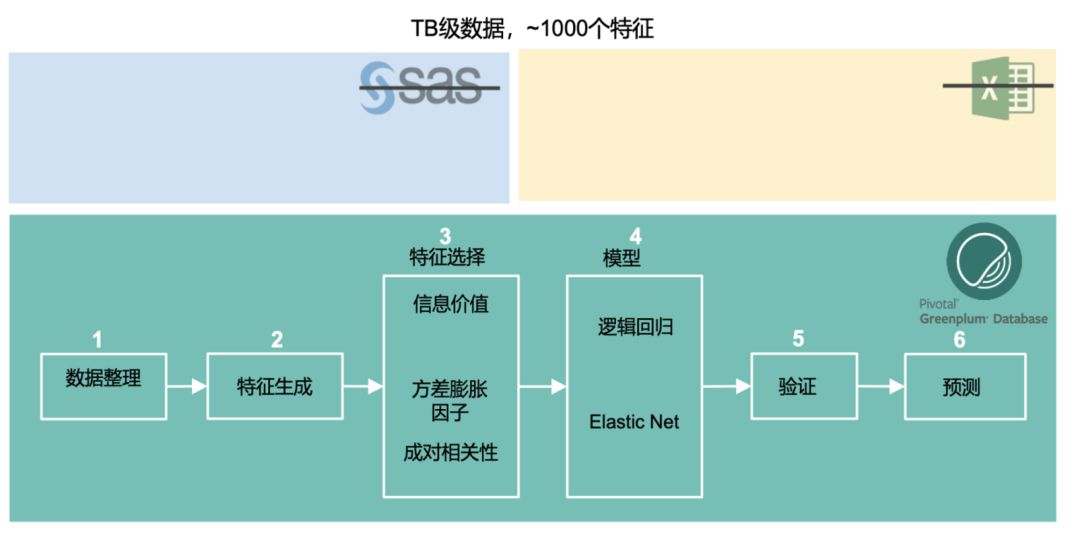
终达到了下图中的性能指标。每个阶段的性能指标均有了数量级的提高。

二、Greenplum重点功能
接下来,根据前面提到的架构信息,我们来介绍Greenplum的几个重点功能,与后面提到的调优信息也有很大的关系。
数据分布:每个节点1/n数据
使用一款MPP数据库,重要的策略和目标就是将数据均匀分布。MPP数据库会将数据进行分片,从而在并行处理的过程中,更快的得到结果。下图中有十二条二手游戏买号数据,十二条数据每条数据均会被放到不同的segment实例上。从而每个机器分到了2条数据。查询时,每个机器可能仅需要2个节点运行,便可以得到查询结果。相较于SMP架构中,在一台机器上用一个实例查询,性能的提升是不言而喻的。数据均匀分布后,我们在Master节点下发执行计划,来做二次查询时,多台机器是并行执行的,从而能够发挥所有服务器的能力,从而避免资源的浪费。
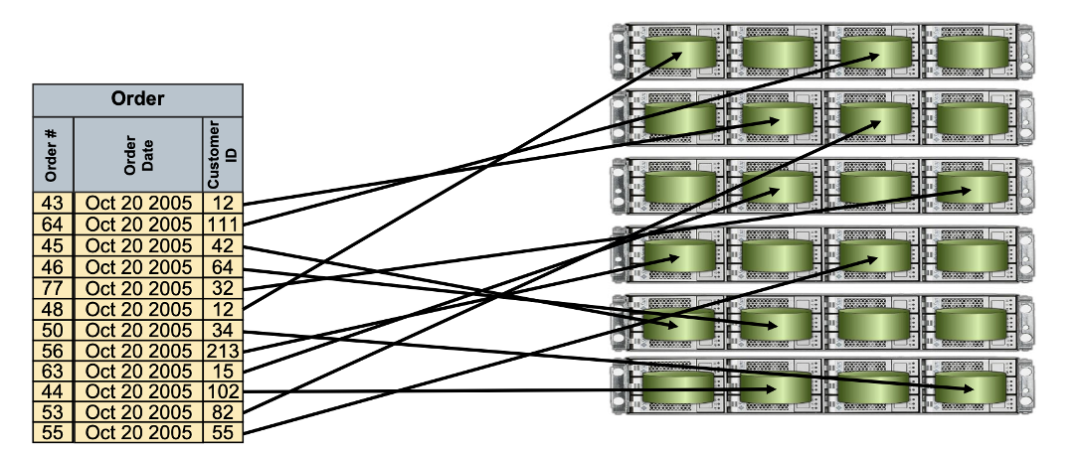
因此,在做表结构设计,或数据入库设计时,需要考虑如何把数据更均匀的分布在每一个节点上。在使用过程中,可以通过一些视图来看数据入库过程中有无数据倾斜或者计算瓶颈。具体内容可以参考官方手册相关部分。
多级分区
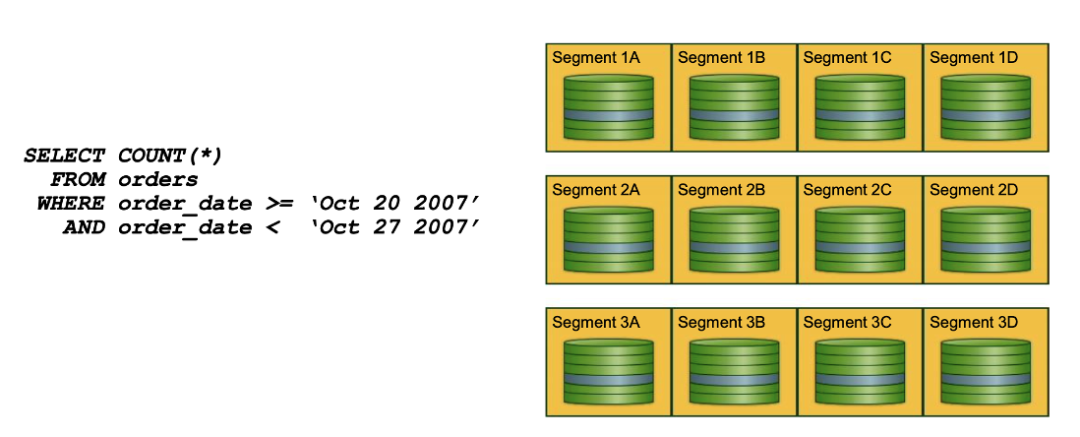
Greenplum的分区设计与Oracle较类似。与数据分布不同的是,分区是一个逻辑的概念,而数据分布是物理的概念。在创建分区表时,在每个segment都会创建同一套完整的,包括所有表结构的分区表。在每个segment查询时,会将无用的分区裁剪,将无用的数据进行过滤,从而提升查询效率。图中可以看到,每个segment上,只有蓝色的部分参与了查询。
多模存储/多态存储
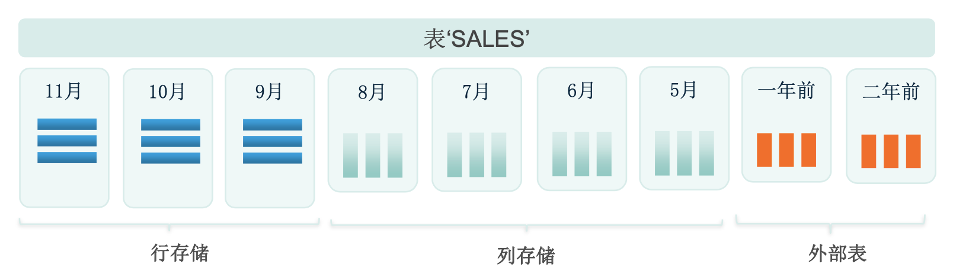
多模存储/多态存储在很多数据库都会有所涉及,这里,我们为大家总结了三个不同的特征:
行存储
行存储比较适合OLTP业务,适合频繁的更新或访问大部分字段的场景。Greenplum作为一款HTAP数据库,做了很多对OLTP场景的优化,在这种场景下,可以选用行存储。
列存储
列存储更适合压缩,查询列子集时速度快,适用于分析型场景。不同列可以使用不同压缩方式:gzip(1-9),quicktz,delta,RLE,zstd。
外部表
外部表是PostgreSQL的优势之一,Greenplum也继承了这一优势。历史数据和不常访问的数据存储在HDFS或者其他外部系统中。可以无缝查询所有数据。支持Text,CSV,Binary,Avro,Parquet,ORC格式。
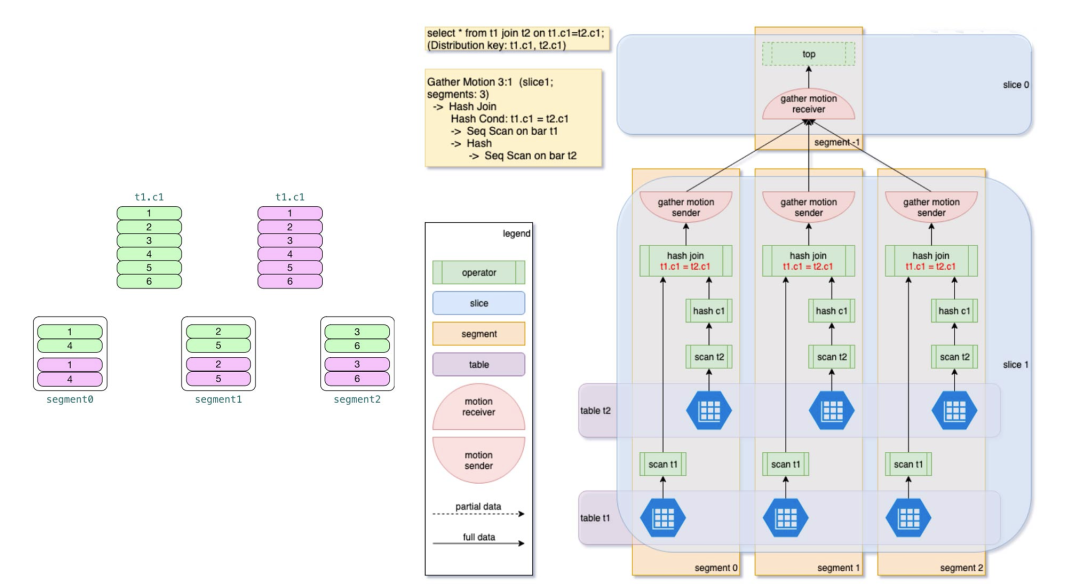
N个节点并行执行
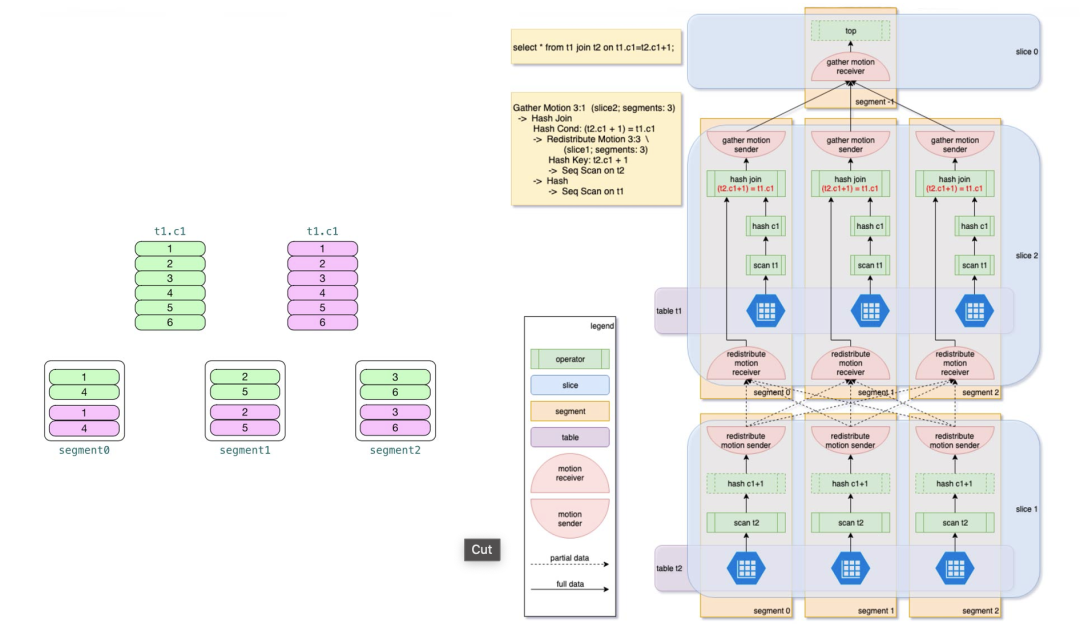
这一特点主要从查询计划来展开为大家进行介绍。下面的图中,将左侧的一个SELECT查询,分解成了不同的动作。在Segment 0,1,2三个机器上做并行的查询。在Greenplum中,为了提高-大的并行度,会将计算原子都提升到并行计算中。为了提高性能,我们需要不断优化执行计划,从而在在计算的过程中避免产生没有必要的代价。
数据Shuffle
对Hadoop比较了解的小伙伴应该会知道,在Map和Reduce之间会有一个shuffle的操作,起到一个桥梁的作用。在Greenplum中,会涉及到数据的重分布和广播。简单来说,例如对两个表做Join操作时,在并行处理的过程中,需要同一个实例对两个表中相关数据进行相关的处理。如果数据不在此节点中,需要从别的节点取数据,这个取过来的方式就是Shuffle。
下面的图中有个代价计算模型,是在执行计划时会做评估,如果数据量大,可能会产生数据的广播。广播的代价比较大,需要想所有节点发布同一份数据。因此我们在做数据表的设计时,应该尽量避免两个特别大的表做关联。一般在设计模型时,一般都会采用星形模型或者雪花型模型,在计算的过程中会把一些小表进行数据的重分布,从而减少代价。
其他的一些功能包括全局死锁检测、复制表、灵活索引、资源负载管理、企业级监控等,能够很好的帮助用户的使用,这里就不再一一赘述,希望了解的小伙伴,可以前往Greenplum中文社区网站获取相关资源。
三、Greenplum优化要点
社区提供的工具及文档
首先为大家介绍的是一些优化的工具和思路。社区为大家提供了很多工具和文档来帮助大家的使用。
首先是数据库初始化使用时,需要做参数预估。大家可以参考工具:
https://greenplum.org/calc/
数据库初始化安装前,根据硬件规划情况,使用这个计算器工具粗略计算各个vmem protect值;后期在使用过程中,如果觉得不满足,可以再上下调整。

其他各个指标,例如sysctl.conf/limits.conf/statement_mem等参数的配置,请参考安装文档具体计算公式。文档里具体的位置如下:Installation Guide -> Setting the Greenplum Recommended OS Parameters
常用压测工具及目的
下面为大家介绍一些常用的压测工具,这些工具经常在Greenplum的调优,或者选型中会用到。
1、gpcheckperf - 定期对内存、网络、磁盘性能进行压测
这个工具在Greenplum4、5、6版本中均有。在Greenplum启动前,需要用此工具测试整个集群的性能,如果不满足我们的经验要求,就需要大家去调整一些硬件。建议定期执行该测试,用于掌握集群硬件环境的变化情况,及时发现存在的潜在性能影响因素,并针对性的安排硬件调整计划;
2、TPCH/TPC-DS - 选型场景下的标准测试集压测
在选型场景下,与其他数据库选用同样的分析型测试模型,更有利于选择更有的方案,并能在同一测试场景下,不断查找并学习针对性优化方法;Greenplum的TPC-DS解决方案请参考:
https://github.com/RunningJon/TPC-DS
3、业务场景定期压测
定期进行业务压测,方便提前察觉长期运行状态下产生的性能下降问题,并针对性的进行性能提升操作,制定日常vacuum analyze操作计划,调整数据模型。
如何进行性能瓶颈分析
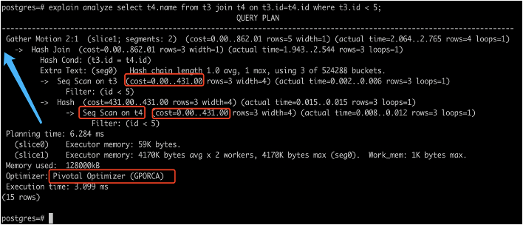
在做瓶颈分析时,每个人可能都有自己的方式,在这里,我将介绍一点自己的经验。首先,我们需要看执行计划。如果有一条查询特别慢,我们需要查看这条查询的查询计划,来寻找慢的原因。从下往上的顺序看查询计划,主要需要关注的指标如下图。分析步骤中是否有cost值过大的场景,cost值过大说明在这一阶段,浪费了大量的时间进行处理,可以看看是否能进行优化。
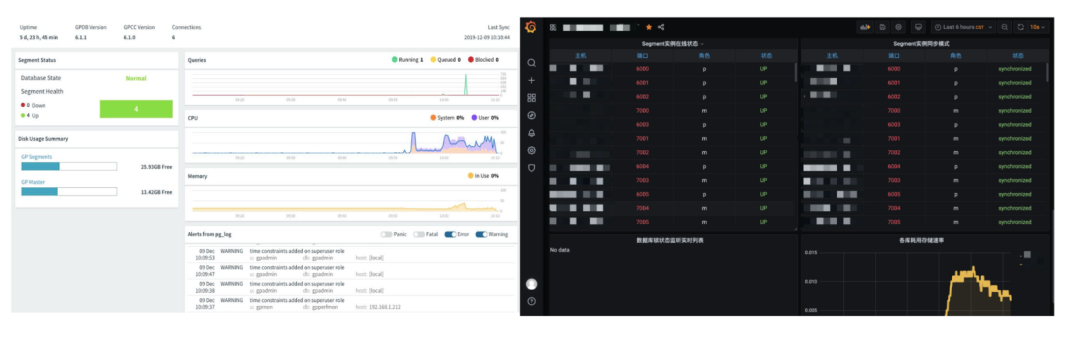
查看完查询计划后可以通过一些监控工具来辅助性能分析,例如官方监控工具GPCC、开源的Prometheus等。
问题定位的一般思路
1.遇到问题不要慌,一定是有原因的,不要急于采用kill -9、重启集群或重启机器等方法来强制处理;这种处理方法通常会导致数据库宕机时间远远大于耐心分析解决的时间;
2.首先看一下数据库是否还能继续使用,如果可以,尽快断开前端连接,避免新进入的查询对数据库造成更严重的影响;
3.然后通过观察数据库活动查询视图(pg_stat_activity)、锁视图(pg_locks)、数据库日志(gpAdminlogs/pg_log)来查找问题的蛛丝马迹,结合前面介绍的MVCC和锁原理知识,结合数据库模式设计与日常运维逻辑之间的处理关系,来终解决该问题。
本文来源:https://blog.csdn.net/ludongguoa/article/details/121168851
