上一篇文章《阿里腾讯华为都在追捧的新一代大数据引擎Flink到底有多牛?》中我对新一代大数据处理引擎Flink做了简单的介绍,包括:批量计算与流式计算的区别、流式计算引擎的重要性,以及Flink相比其他流式计算引擎的优势。因为Flink性能,解决了之前流式计算引擎的痛点,非常适合电商促销、风险控制、异常检测、金融交易等领域,阿里、腾讯、华为、美团、滴滴等大公司为了保证业务的实时性,正在积极将Flink部署在生产环境。Flink是当前大数据界冉冉升起的新星。比起Hadoop和Spark,精通Flink技术的人才相对较少,因此,掌握Flink技术对于转行或跳槽的朋友来说显得越发重要。
本文将带着大家从零开始,在个人电脑上编写并运行个Flink程序,在本地构建Flink集群。下一篇文章我将分享一些Flink的基础概念,欢迎大家持续关注我的公众号:ai-xingqiu。
准备工作
项目开始之前,你需要准备:
- JDK 1.8+
- Maven
- Intellij Idea
Flink可以运行在Linux、macOS和Windows上,需要Java 1.8和Maven基础环境。关于Java的安装这里不再赘述,网络上有很多针对不同操作系统的安装配置指南,注意要配置Java的环境变量。Maven是一个项目管理工具,可以对Java或Scala项目进行构建及依赖管理,是进行大数据开发必备的工具。Intellij Idea是一个非常强大的编辑器和开发工具,内置了Maven等一系列小功能,是大数据开发必不可少的利器。Intellij Idea本来是一个商业软件,它提供了社区免费版本,免费版本已经基本能满足绝大多数的开发需求。
熟悉Scala的朋友也可以直接使用Scala。Scala是Spark大数据处理引擎推荐的编程语言,在很多公司,要同时进行Spark和Flink开发。Flink虽然主要基于Java,但这几年对Scala的支持越来越好,其提供的API也与Spark极其相似,开发人员如果使用Scala,几乎可以无缝从Spark和Flink之间转换。
本文将主要介绍Scala版的程序,也会给出Java版程序。
对于想学习大数据的朋友,非常有必要掌握好Java和Scala语言、Maven、Intellij Idea这些基础工具。
Java 环境配置:https://www.runoob.com/java/java-environment-setup.html
Maven 教程:https://www.runoob.com/maven/maven-setup.html
Intellij Idea:https://www.jetbrains.com/idea/
创建Maven项目
熟悉Maven命令行的朋友可以直接使用下面的命令创建一个项目,再使用Intellij Idea打开该项目:
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-scala \
-DarchetypeVersion=1.8.1 \
-DgroupId=com.myflink \
-DartifactId=flink-study-scala \
-Dversion=.1 \
-Dpackage=quickstart \
-DinteractiveMode=falsearchetype是Maven提供的一种项目模板,是别人提前准备好了项目的结构框架,程序员只需要下载下来,在这个框架或模板下丰富完善自己项目所涉及的代码逻辑。流行项目一般都准备好了archetype,如Spring、Hadoop等。
不熟悉Maven的朋友可以先使用Intellij Idea内置的Maven工具,熟悉Maven的朋友可直接跳过下面这部分。
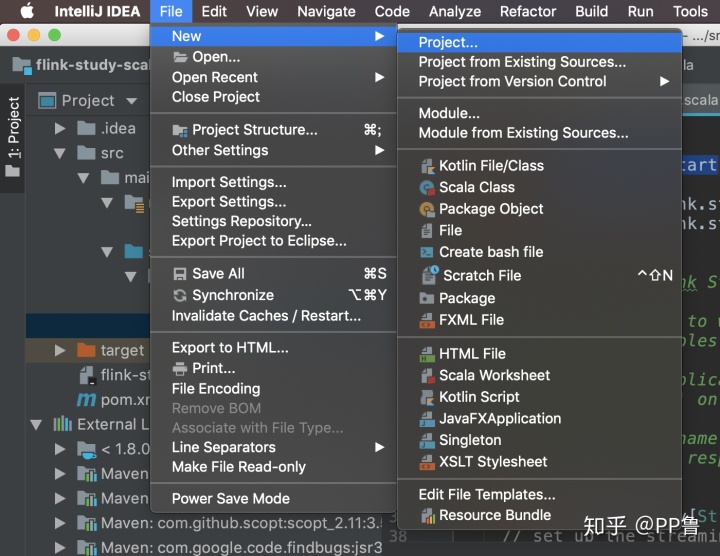
在Intellij里"File -> New -> Project..."
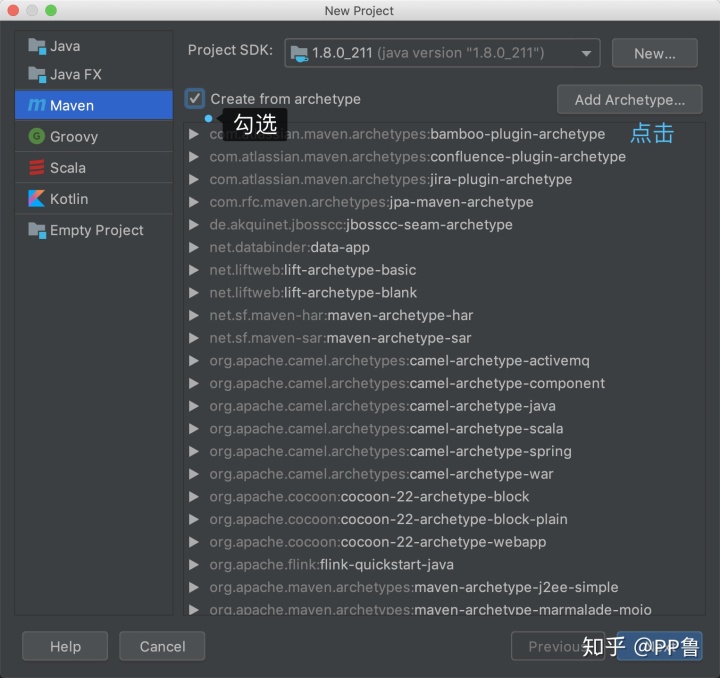
选择左侧的"Maven",并勾选“Create from archetype”,并点击右侧“Add Archetype”。
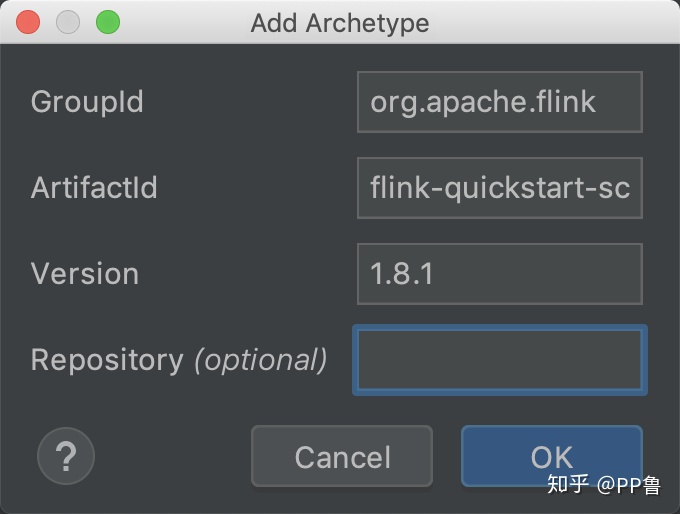
在弹出的对话框中填写archetype信息。其中GroupId为org.apache.flink,ArtifactId为flink-quickstart-scala,Version为1.8.1,然后点击"OK"。这一步主要是告诉Maven去网络的资源库中下载哪个版本的模板。"GroupId + ArtifactId + Version"可以表示一个发布出来的Java程序包。
配置好后,进入点击"Next"进入下一步。
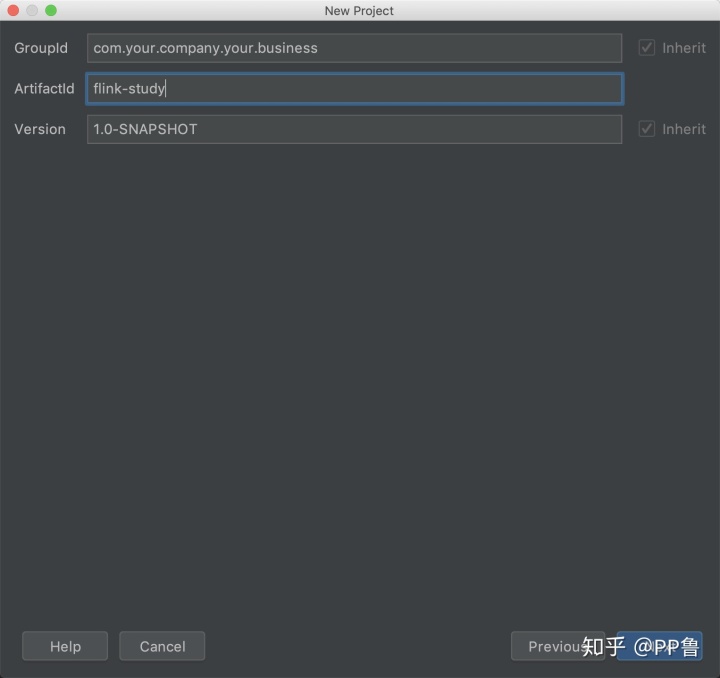
这一步是建立你自己的工程,GroupId是你的公司部门名称(可以随意填写),ArtifactId是你这个程序发布时的Jar包名,Version是你的程序的版本。这些配置主要是区别不同公司所发布的不同包,这与Maven和版本控制相关,Maven的教程中都会介绍这些概念,这里也不赘述。
接下来可以继续"Next",注意后一步选择你的项目所在的磁盘位置,点击确定,一个Flink模板程序就下载好了。
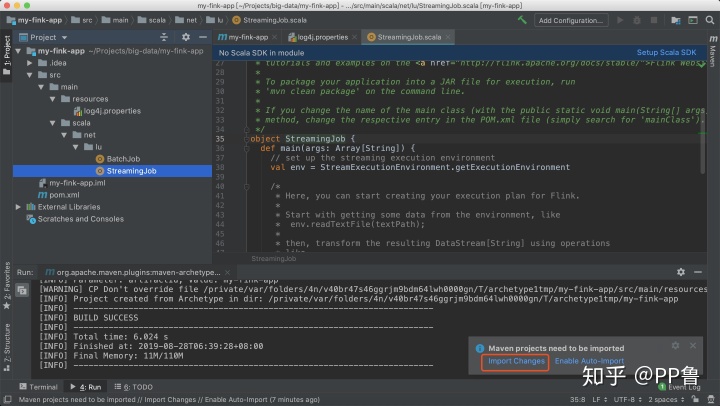
项目结构如上图所示。左侧的导航栏是项目结构,其中src/main/scala文件夹已经准备好了两个样例程序。我们可以在StreamingJob这个文件上继续修改,也可以重新创建一个新文件。注意要点击右下角的"Import Changes",让Maven导入所依赖的包。
次使用Scala的朋友可能还需配置Scala SDK,可根据Intellij Idea的提示配置,不用自己再另行下载安装。
编写 Flink 程序
我们在StreamingJob这个文件基础上,继续丰富这份代码,编写个流式WordCount程序。
首先要设置Flink的执行环境,这里类似Spark的SparkContext:
// 创建 Flink 执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment然后读取本地端口为9000的socket数据源,将数据源命名为textStream:
// 接收socket的输入流
// 使用本地9000端口,如端口被占用可换一个端口
val textStream = env.socketTextStream("localhost", 9000, '\n')使用Flink算子处理这个数据流:
// 使用Flink算子对输入流的文本进行操作
// 按空格切词、计数、分区、设置时间窗口、聚合
val windowWordCount = textStream
.flatMap(line => line.split("\\s"))
.map(word => (word, 1))
.keyBy()
.timeWindow(Time.seconds(5))
.sum(1)这里使用的是Flink提供的DataStream级别的API,主要包括转换、分组、窗口和聚合等算子。算子(Operator)是对数据进行的某种操作。熟悉Spark的朋友可以看出,Flink算子与Spark算子极其相似,无需太多学习成本。
假设输入数据是一行英文语句,flatMap将这行语句按空格切词,map将每个单词计数1次,这两个操作与Spark的算子基本一致。keyBy对数据流进行分区,将数据按照某个key分到不同的partition上,这里使用(word, count)中的个元素word作为key进行分区。timeWindow创建一个时间窗口,sum是求和操作。在这个例子中,每5秒对数据流进行一次求和。
后将数据流打印,并开始执行:
// 单线程打印结果
windowWordCount.print().setParallelism(1)
env.execute("Socket Window WordCount")env.execute 是启动Flink作业所必需的,只有在execute()被调用时,之前调用的各个算子才会在提交到集群上或本地计算机上执行。
完整代码如下:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object StreamingJob {
def main(args: Array[String]) {
// 创建 Flink 执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 接收socket的输入流
// 使用本地9000端口,如端口被占用可换一个端口
val textStream = env.socketTextStream("localhost", 9000, '\n')
// 使用Flink算子对输入流的文本进行操作
// 按空格切词、计数、分组、设置时间窗口、聚合
val windowWordCount = textStream
.flatMap(line => line.split("\\s"))
.map(word => (word, 1))
.keyBy()
.timeWindow(Time.seconds(5))
.sum(1)
// 单线程打印结果
windowWordCount.print().setParallelism(1)
env.execute("Socket Window WordCount")
}
}Java版本的程序:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class StreamingWordCount {
public static void main(String[] args) throws Exception {
// 创建 Flink 执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 接收socket的输入流
// 使用本地9000端口,如端口被占用可换一个端口
DataStream<String> text = env.socketTextStream("localhost", 9000, "\n");
// 使用Flink算子对输入流的文本进行操作
// 按空格切词、计数、分组、设置时间窗口、聚合
DataStream<Tuple2<String, Integer>> windowCounts = text
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
for (String word : value.split("\\s")) {
out.collect(Tuple2.of(word, 1));
}
}
})
.keyBy()
.timeWindow(Time.seconds(5))
.sum(1);
// 单线程打印结果
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
}比较两份代码,可见Scala程序比Java程序精简得多。
执行程序
在macOS或Linux终端中启动netcat制造一个socket输入流:
$ nc -l 9000如果是 Windows 平台,可以在 https://eternallybored.org/misc/netcat/ 下载,在Windows命令行运行:
$ nc -l 9000然后点击绿色按钮,执行这个程序。这两步的顺序不要颠倒,否则Flink程序会发现没有对应的数据流而无法启动。

在刚才启动的nc中输入英文字符串,Flink程序会对这些字符串做词频统计。
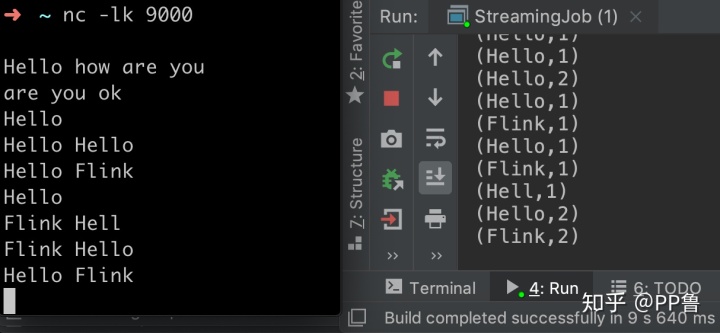
恭喜你,你的个Flink程序运行成功!
搭建本地Flink集群
通常情况下,我们把自己写的代码编译成Jar包,并将这个Jar包以作业的方式提交到这个本地集群上。下面将在本地搭建一个Flink集群。
从官网下载编译好的Flink程序,把下载的tgz压缩包放在你想放置的目录:https://flink.apache.org/downloads.html
macOS和Linux
解压、进入解压缩目录,启动Flink集群:
$ tar zxvf flink-1.9.0-bin-scala_2.11.tgz # 解压缩
$ cd flink-1.9.0 # 进入解压缩目录
$ ./bin/start-cluster.sh # 启动 Flink 集群Windows
Windows可以使用7-zip或WinRAR软件解压,使用Windows自带的命令行工具进入该目录。记得一定要提前配好Java环境变量。
$ cd flink-1.9.0
$ cd bin
$ start-cluster.bat成功启动后,打开浏览器,输入:http://localhost:8081/#/overview,可以进入到Flink集群的仪表盘,这里可以对Flink的作业做一些管理和监控。
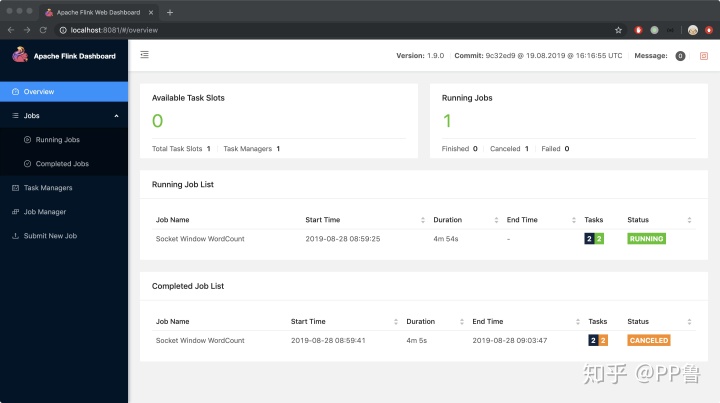
现在,你就已经拥有了一个Flink集群,虽然它只有一台机器。一般公司有自建的Flink集群,或使用Yarn、Kubernetes管理的集群,并将作业提交到这个集群上。
在集群上提交作业
接下来就可以向这个集群提交作业了,仍然以刚才的WordCount为例,使用netcat制造一个数据流:
$ nc -l 9000提交一个打包好的Jar包到集群上:
$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000这时,刚才的仪表盘上就多了一个Flink程序。
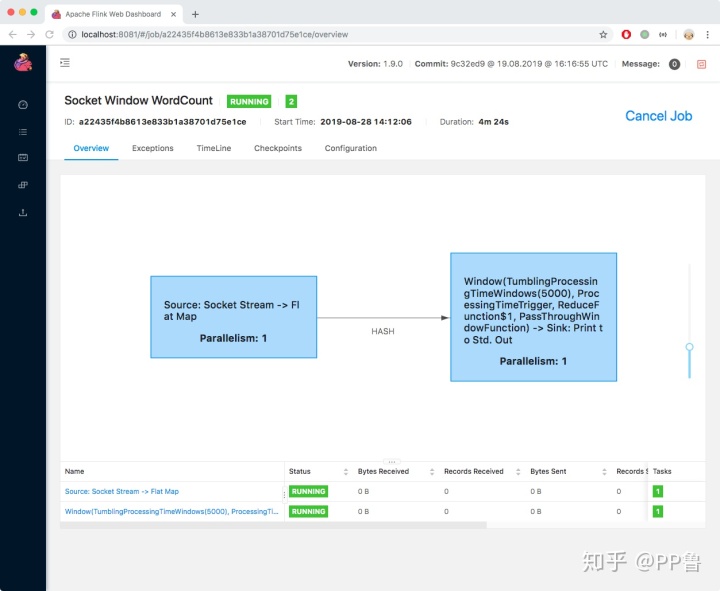
程序的输出会打到Flink主目录下面的log目录下的.out文件中,使用下面的命令查看结果:
$ tail -f log/flink-*-taskexecutor-*.out停止本地集群:
$ ./bin/stop-cluster.sh至此,你已经搭建好了一个Flink集群,接下来你可以在集群上做你想做的各种尝试了!
