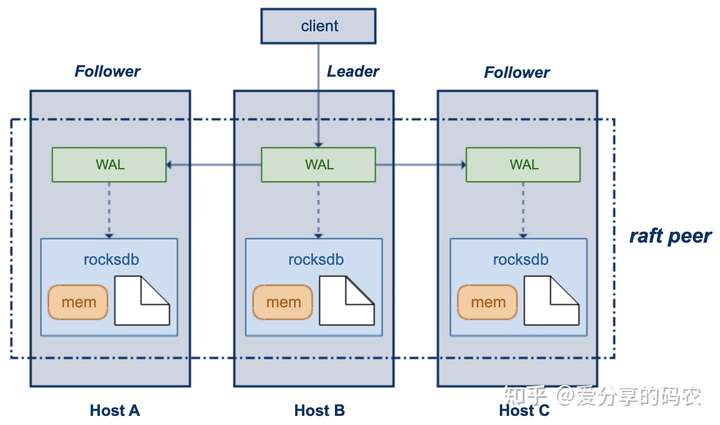
然而该部署方式其实也还存在着一些相应的短板,比如RAFT这种Y型写入方式是没有办法规避Leader慢节点问题的,单个rocksdb实例的数据规模庞大了以后,节点的故障迁移也会变的比较麻烦。
恰好近有在阅读Amazon Aurora提供的论文,于是设想rocksdb是否也可以参照Aurora来做类似的功能改善,初步设想的工作逻辑如图所示:
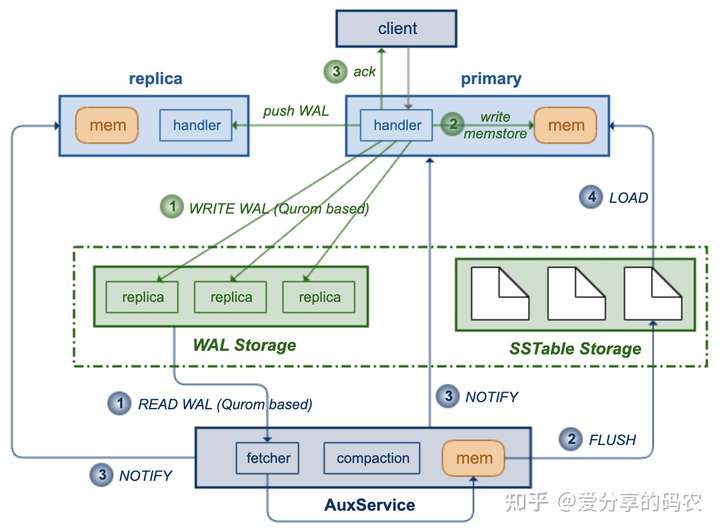
主要基于share disk方式来对rocksdb的存储和计算资源进行分开管理。上层的计算实例保留了memstore的写入功能,但是WAL的写入不在记录到本地,而是基于Qurom机制保存到中间存储。同时在底层提供了AuxService服务,其会不断的对WAL数据进行拉取(同样基于Qurom机制),然后将日志数据转储成sstable,并保存到中间的共享存储层。
WAL转储过程与客户端的写操作是异步进行的,但是不用担心primary的访问会出现数据不一致,因为新写入的数据已经记录到了memstore。然而memstore不能无限增长,何时对其进行清理呢?主要由AuxService服务来负责对其进行通知,每有FLUSH完成之后,AuxService都会将持久化了的logId通知到计算层,以便其通过logId来决定可以对哪些memstore数据做drop清理,并将新生成的sstable使用句柄载入内存。
该处理方式主要可以带来以下好处:
(1) WAL写入基于Qurom机制进行,可以有效的规避掉慢节点。
(2) 针对LSM树的整理操作,可以缩减出两份读IO资源。
基于share nothing方式部署,每个rocksdb实例都需要对待整理的源数据做一次读取,而基于share storage方式仅需要由AuxService统一读取一次。
(3) 故障容错恢复能力得到提升
share nothing方式,单服务实例的替换是比较麻烦的,membership change需要做点对点的数据迁移,还需要在peer之间做信息同步。
而share disk方式在这方面则表现的更加灵活,底层的存储集群已经具备了单节点的故障容错能力,存储资源的弹性扩缩容也都变的比较容易。
当然基于share disk方式部署之后,数据的访问效率可能不如本地磁盘那样高效,不过随着RDMA,DPDK等网络技术的成熟,走网络与走PCIe的差距正在缩小。
针对该方案的一些问题点做了简单梳理。
(1) 是否有必要针对primary提供热切功能
个人觉得可以不提供,从整个处理链路来看,primary的重新启动、AuxService感知primary失联、以及AuxService转储日志是一个相对并行的处理过程,因此服务的MTTR时间可通过以下公式来描述。
服务的MTTR时间 = max (primary重新启动的时间,AuxService感知primary失联 + 冲刷memstore数据的时间)
计算存储分离之后,rocksdb计算层服务会变的比较轻量,启动过程不在需要执行logReplay相关的逻辑,因此重启过程会变的比较迅速(借助容器快速拉起),相比之下,服务恢复时间主要耗费在感知primary失联这一块,因此只需要等待primary重新启动,然后向其通知新生成的sstable即可,而在收到AuxService的通知之前primary需要暂停读服务(考虑数据读取强一致性前提下),写操作则不受影响。
(2) AuxService执行flush不及时,会导致rocksdb的memstore使用飙升
需要针对memstore的使用引入stall机制
(3) 引入replica服务的目的
针对强一致性要求不高的业务,可以访问replica来做数据读取,或者将primary与replica之间的数据同步做成强一致,这样访问任何一个节点都能满足读写一致性要求。
(4) compaction如何处理
交由AuxService异步进行,整理过程中可以对整个集群的IO资源进行利用,配合存储资源弹性扩所容的能力,提升整理效率变的更加容易。整理成功后需要将sstable的变动情况通知到计算层实例。
来源 https://zhuanlan.zhihu.com/p/478705155
