以下文章来源于黎杜编程 ,作者黎杜
这里的主要是分享索引方面的调优,在工作中,很多同学都有建立索引的一些经验,但是是否有自己深入的思考过,怎么样建立索引才合适。
字符串怎么建立索引、怎么优化联合索引、怎么避免回表等一些问题,是否有结合自己的实际项目进行深入的思考呢?
这里,我就将自己实际中遇到的一些问题分享给大家,下面开始我们的正题,首先开始之前,先来回顾一些基础的知识。
什么是Mysql的索引,联合索引是什么?回表是什么?回表怎么解决?
Mysql索引
Mysql的索引是一种加快查询速度的数据结构,索引就好比书的目录一样能够快速的定位你要查找的位置。
Mysql的索引底层是使用B+树的数据结构进行实现,结构如下图所示:
 索引的一个数据页的大小是16kb,从磁盘加载到内存中是以数据页的大小为单位进行加载,然后供查询操作进行查询,若是查询的数据不在内存中,才会从磁盘中再次加载到内存中。
索引的一个数据页的大小是16kb,从磁盘加载到内存中是以数据页的大小为单位进行加载,然后供查询操作进行查询,若是查询的数据不在内存中,才会从磁盘中再次加载到内存中。
索引的实现有很多,比如hash。hash是以key-value的形式进行存储,适合于等值查询的场景,查询的时间复杂度为O(1),因为hash储存并不是有序的。
所以,对于范围查询就可能要遍历所有数据进行查询,而且不同值的计算还会出现hash冲突,所以hash并不适合于做Mysql的索引。
有序数组在等值查询和范围查询性能都是非常好的,那为什么又不用有序数组作为索引呢?因为对于数组而言作为索引更新的成本太高,新增数据要把后面的数据都往后移一位,所以也不采用有序数组作为索引的底层实现。
后二叉树,主要是因为二叉树只有二叉,一个节点存储的数据量非常有限,需要频繁的随机IO读写磁盘,若是数据量大的情况下二叉的树高太高,严重影响性能,所以也不采用二叉树进行实现。
而B+树是多叉树,一个数据页的大小是16kb,在1-3的树高就能存储10亿级以上的数据,也就是只要访问磁盘1-3次就足够了,并且B+树的叶子结点上一个叶子结点有指针指向下一个叶子结点,便于范围查询:

种类的索引
索引从数据结构进行划分的分为:B+树索引、hash索引、R-Tree索引、FULLTEXT索引。
索引从物理存储的角度划分为:聚族索引和非聚族索引。
从逻辑的角度分为:主键索引、普通索引、索引、联合索引以及空间索引。
什么是回表
再详细了解什么事回表之前,我们先来详细的深入了解一下什么是InnoDB的索引存储形式,InnoDB的主键索引存储形式是聚族索引,索引与数据都在一起:
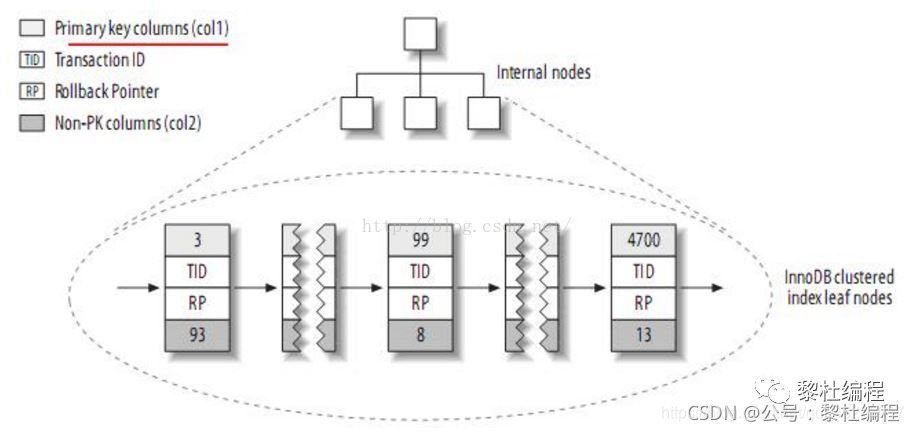 InnoDB的主键索引中叶子结点并不是存储行指针,而是存储行数据,二级索引中MyISAM也是一样的存储方式,InnoDB的二级索引的叶子结点则是存储当前索引值以及对应的主键索引值。
InnoDB的主键索引中叶子结点并不是存储行指针,而是存储行数据,二级索引中MyISAM也是一样的存储方式,InnoDB的二级索引的叶子结点则是存储当前索引值以及对应的主键索引值。
InnoDB的二级索引带来的好处就是减少了由于数据移动或者数据页分列导致行数据的地址变了而带来的维护二级索引的性能开销,因为InnoDB的二级索引不需要更新行指针:

上面说到InnoDB引擎的主键索引存储的是行数据,二级索引的叶子结点存储的是索引数据以及对应的主键,所以回表就是根据索引进行条件查询,回到主键索引树进行搜索的过程:
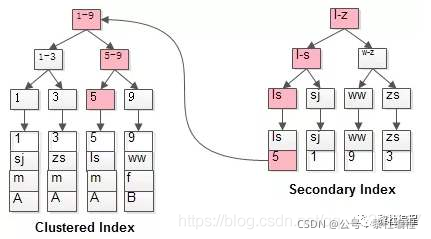
因为查询还要回表一次,再次查询主键索引树,所以实际中应该尽量避免回表的产生。
解决回表
解决回表问题可以建立联合索引进行索引覆盖,如图所示根据name字段查询用户的name和sex属性出现了回表问题:
 那么我们可以建立下面这个联合索引来解决:
那么我们可以建立下面这个联合索引来解决:
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name, sex)
) engine = innodb;
建立了如上所示的index(name,sex)联合索引,在二级索引的叶子结点的位置就会同时也出现sex字段的值,因为能够获取到要查询的所有字段,因为就不用再回表查询一次。
左前缀原则
左前缀原则可以是联合索引的的左N个字段,也可以是字符串索引的左的M个字符。举个例子,假如现在有一个表的原始数据如下所示:
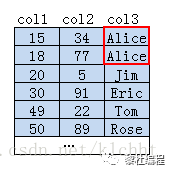
并根据col3 ,col2的顺序建立联合索引,此时联合索引树结构如图下所示:

叶子结点中首先会根据col3的字符进行排序,若是col3相等,在col3相等的值里面再对col2进行排序,假如我们要查询where col3 like 'Eri%',就可以快速的定位查询到Eric。
若是查询条件为where col3 like '%se',前面的字符不确定,表示任意字符都可以,这样就可以导致全表扫描进行字符的比较,就会使索引失效。
调优案例一
其中个案例新人写了一个这样的sql,由于业务的原因就不粘贴全部sql,其中sql的条件如下所示WHERE ( STATUS = '1' AND shop_code = 'XXX' ) GROUP BY act_id。
并且他在表中建立的这样的一个索引idx_status_shop_code,当时看到就吐血一地。
我给新人提出建议是把shop_code为''空字符串的(数据库默认值)是设为一个特殊的00000这样的类型,不要把商店的shop_code默认值设置为空字符串。
并且,索引中shop_code字段放在前面,建idx_shop_code_status_act_id索引。
因为一般状态值status只有0和1,区分度不大,而shop_code的区分度大,在执行where条件筛选的时候,区分度大的放在前面,层过滤的时候就能过滤掉大部分行数,减少扫描的行数,提高效率。
并且将act_id,和store_code也加入其中,sql中涉及分组(group by)操作,这样就能避免filesort排序,因为索引本来就是有序的:

并且从他的sql中可以看到他只要返回act_id,而实际中只用到了act_id,所以将act_id也加入索引中就可以避免回表的操作,所以再索引中后加入act_id有两大好处:避免回表以及避免filesort排序。
因为写sql的不良习惯造成回表操作,平时也没有注意建立索引的一些原则,以及理解索引的一些原理,所以新人对于一些优化的理解还有要一步一步的指导,毕竟自己也是从新人过来的。
对于索引的顺序的建立,以及出现filesort的解决方案在阿里的开发手册中也有提到:

order by和group by都可以利用索引的有序性。

说真的这本开发手册还是非常好用的,里面很多经验总结,慢慢的遇到场景就能够瞬间顿悟,毕竟是众多阿里人的开发经验的结晶。
调优案例二
第二个案例是关于字符串的,新人接到一个需求需要比较电话,但是一般电话在数据库中都会加密md5。
所以,新人为了提高查询的效率新建KEY idx_mobile_md5_type (mobile_md5,type)使用md5全字段建立索引。
我是建议他使用select count(distinct left(mobile_md5, 5))/count(*) from XXX.users查找大的区分度:

在实际中当md5值长度为5以及大于5的长度都不变了:

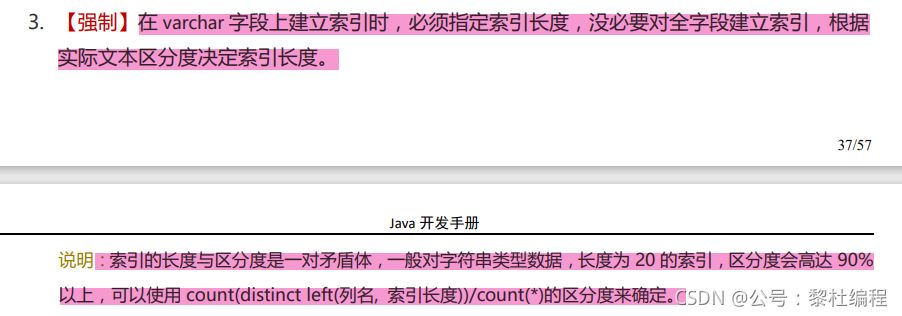
实际情况只要前五个字符就能达到80%的区分度,并且再加字段长度区分度也不变,所以个人提出只要建立前五个字符的索引即可,可以大大节约空间。
这个在阿里的开发手册也有提到,其实一般来说达到90%的区分度是比较好的,区分度越大,就类似于越趋向于索引,过滤的行数就越多:
调优案例三
后一个字符串的案例就是userId,这个userId使用有20位的长度的字符串左右,有点类似于身份证号码,大家都知道身份证号码的前多少位是基本一样的,区别大的在后面的几位(具体几位没去了解过)。
我们这边的场景也是一样,userId前10位左右基本都是一样,反而只有后面的几位区别度高达90%以上。
所以,建议新人建立userId的反转之后的前几位索引即可,区别度可以通过:select count(distinct left(REVERSE(userId), 7))/count(*) as '区分度' from XXX.users;
具体sql如下的sql:select u.city_code from XXX.city_role_user u where role_key = 'XXX' and uc_id = 'XXX' and status = 1;
这个sql有两个问题,一个是把区分度不大的role_key放在前面,因为一般角色key在PC端只有几种,区别度很小;另一个就是前面说的uc_id字符串问题。
我是建议把where条件的条件uc_id放在前面,建立索引也是如此,并且uc_id是由20位的数字组成,前面的10位左右都是一样的,只有后面的几位区分度才大。
所以个人也建议通过查询区分度,并且建立翻转字符串后的索引来达到节省空间,并且还可以提升查询效率,后就是city_code也加入索引中建立联合索引就可以避免回表操作。
所以,这就要sql优化的关键点有三个:区分度大的放在前面、字符串减少长度、避免回表。
其它的code review
通过code review新人的代码,还发现一些问题,就是不遵循接口的单一原则,比较喜欢写通用的接口,一个接口多个场景使用,通常使用select * 返回数据,对于一些where条件的查询需要大量的回表操作,但是一些接口中只需要用到其中select 回来的一个字段,所以导致慢sql,慢接口的产生。
并且,在实际的编码中主要是面向于实现,对于一些整体的模块没有把控,类似于一些可以使用到策略模式、建造者模式等设计模式的,都没有使用,代码的扩展性比较差。
还要在代码中大量的使用Java 8的stream流操作,代码的可读性差,对于stream流其实可以用来并行流处理还是挺高效的,因为stream流的底层使用到了Fork/Join。
在服务器配置允许的条件下,使用如下代码,数据量大的时候是可以有效率提升的,下面引用redspider的一个案例:
public class StreamParallelDemo {
public static void main(String[] args) {
System.out.println(String.format("本计算机的核数:%d", Runtime.getRuntime().availableProcessors()));
// 产生100w个随机数(1 ~ 100),组成列表
Random random = new Random();
List<Integer> list = new ArrayList<>(1000_0000);
for (int i = 0; i < 1000_0000; i++) {
list.add(random.nextInt(100));
}
long prevTime = getCurrentTime();
list.stream().reduce((a, b) -> a + b).ifPresent(System.out::println);
System.out.println(String.format("单线程计算耗时:%d", getCurrentTime() - prevTime));
prevTime = getCurrentTime();
list.stream().parallel().reduce((a, b) -> a + b).ifPresent(System.out::println);
System.out.println(String.format("多线程计算耗时:%d", getCurrentTime() - prevTime));
}
private static long getCurrentTime() {
return System.currentTimeMillis();
}
}
一路code review,发现还是挺多问题,也是非常基础的东西,这里就顺手做了个记录,不过也情有可原,毕竟是新人,只能慢慢的指导,一行代码一行代码的手把手教。
