
随着基于WebRTC技术的Web应用快速成长,记录web在线教育、视频会议等场景的互动内容并对其准确还原越来越成为一项迫切需求。在主流浏览器中,通常基础设施部分已实现了页面渲染结果的采集及编码。开发者可以利用浏览器提供的API对页面内容进行录制。但受限于Web标准以及浏览器厂商在专利授权方面的问题,使用Web API实现页面录制在易用性和可用性上均较难令人满意。针对上述问题,声网Agora Web 引擎架构师高纯在 RTE 2020 实时互联网大会上就Web引擎渲染采集原理进行了分享,并就基于Web引擎的服务端录制技术进行探讨。

大家好,我这次技术分享的主题是Web互动场景还原—基于Web引擎技术的Web内容录制。
我叫高纯,是来自声网的Web引擎架构师,接下来我将会为大家介绍以下的内容:包括应用背景、浏览器内容采集、服务端Web录制引擎,服务端Web录制引擎性能优化,后会进行一个总结。
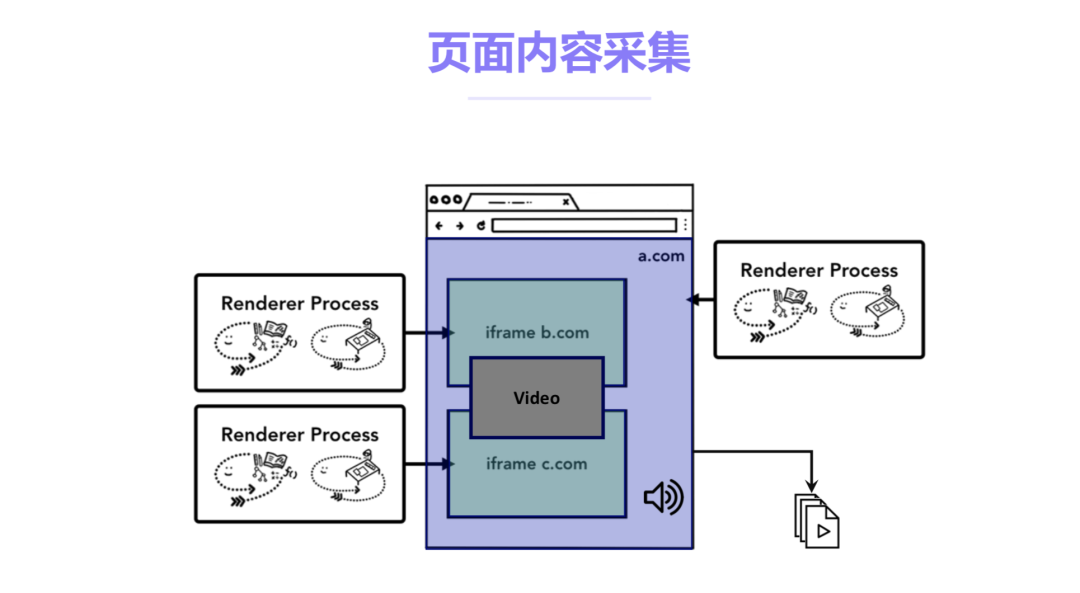


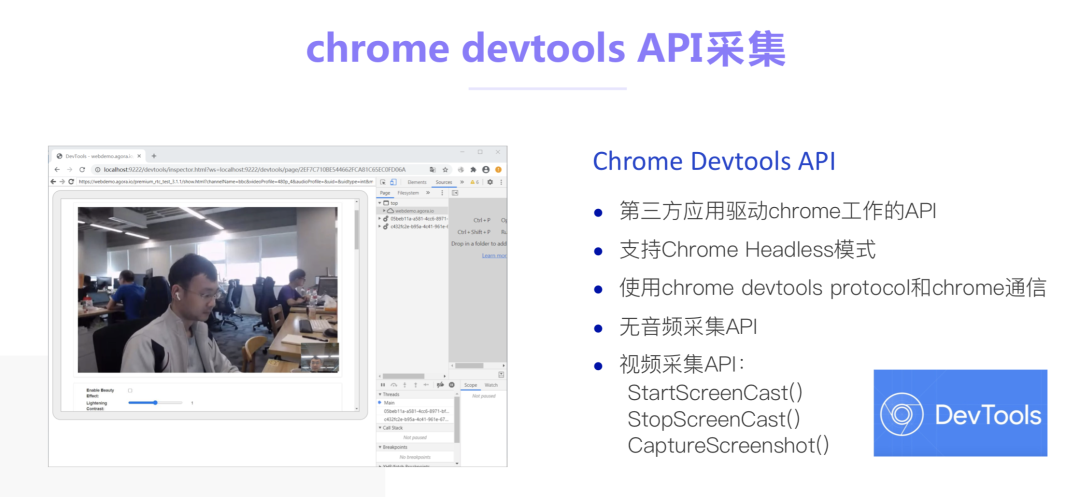
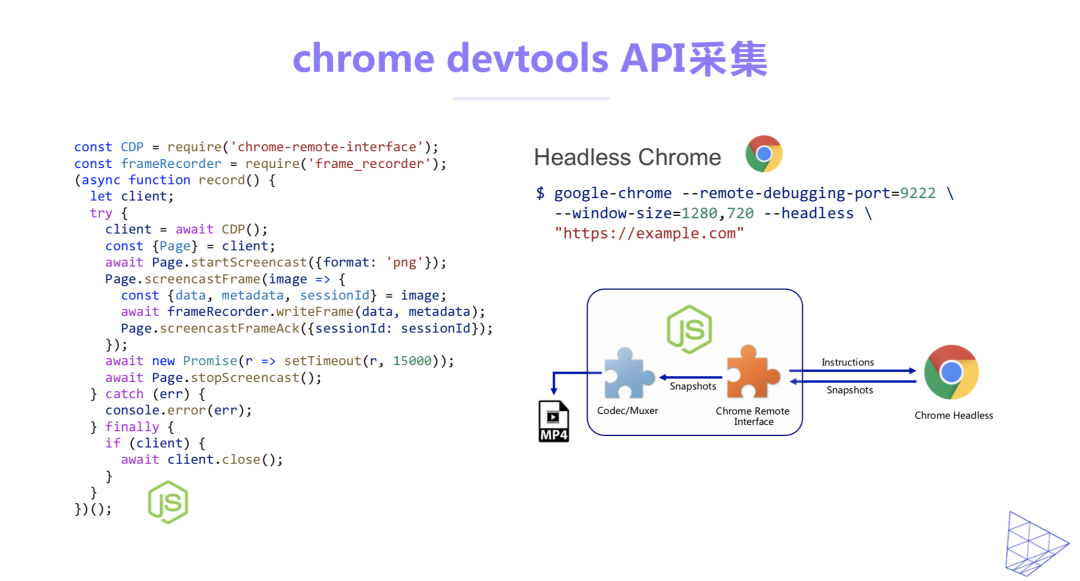
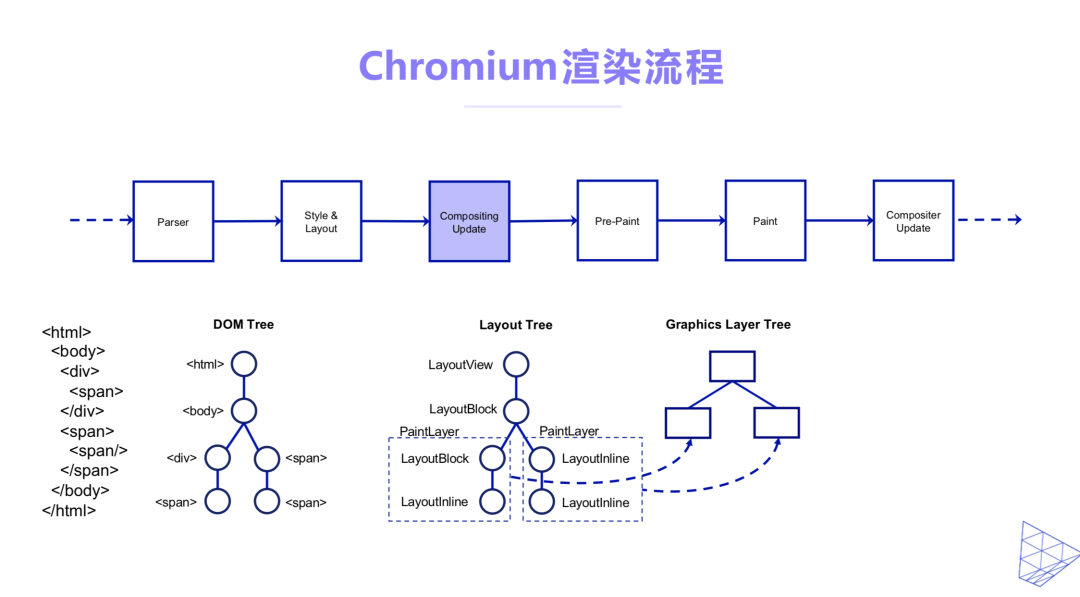
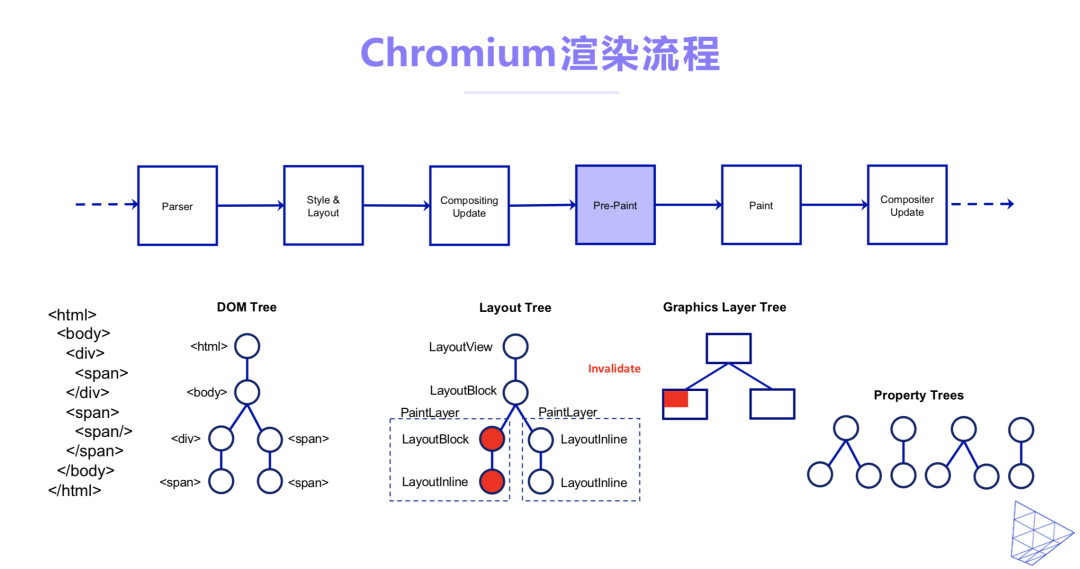

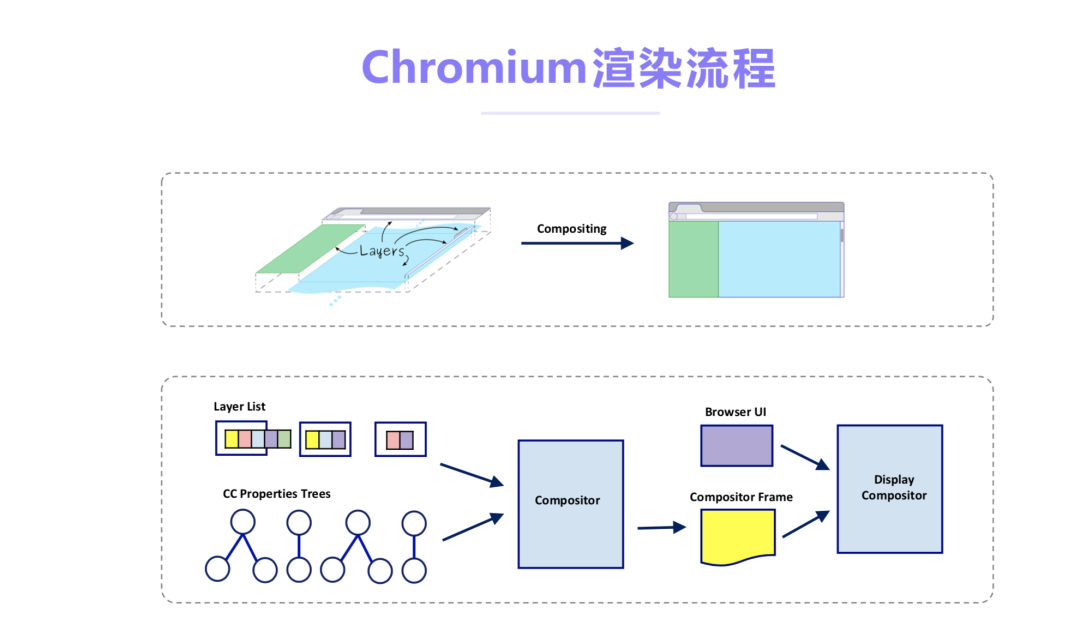


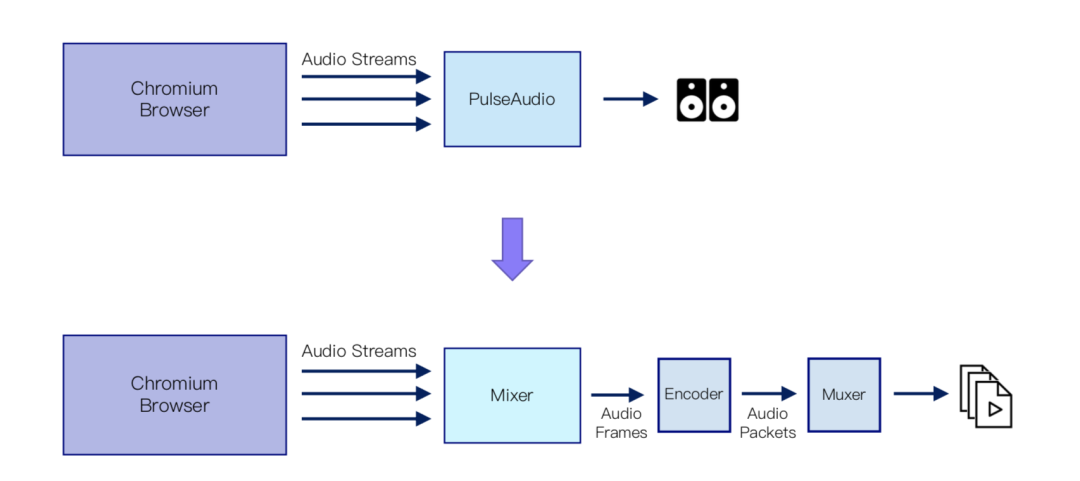







当前主流的浏览器对Web录制的支持并不能满足我们的业务需求。
我们所需要的业务能力和可用性可以通过定制chromium浏览器来实现。
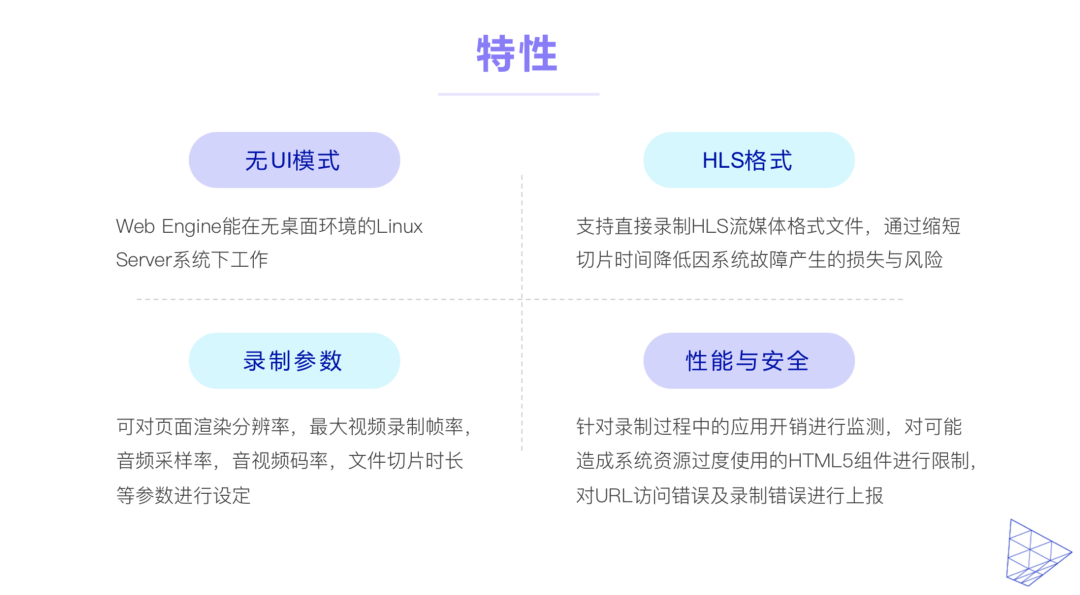
Web云录制作为一种新的技术和业务形态,它面对性能和安全性的双重挑战。
我们针对目标硬件平台来进行CPU和GPU的优化能够比较有效的缓解性能的问题。
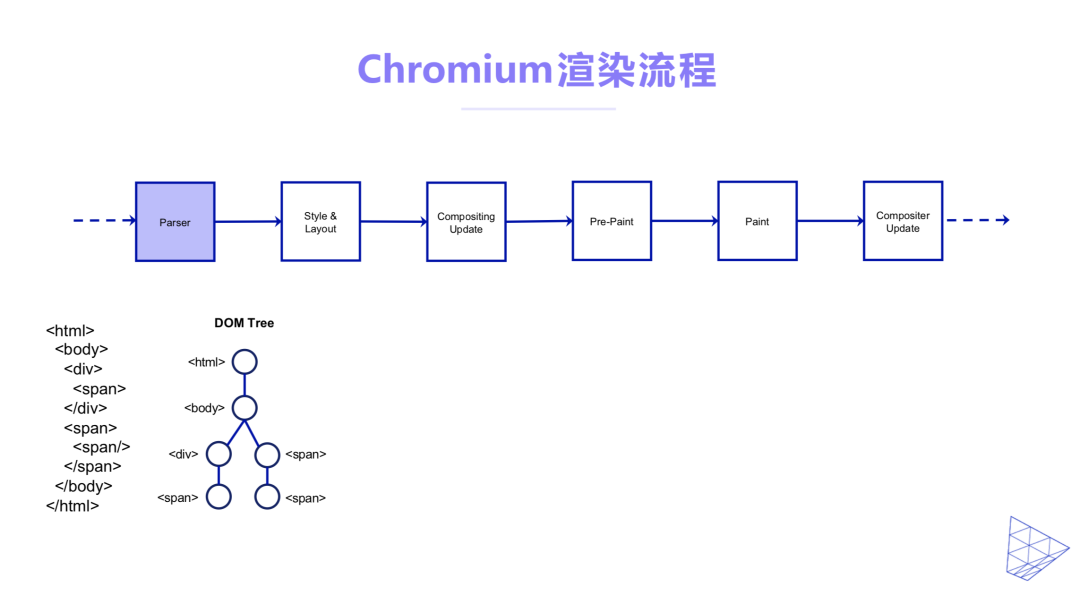
通过对Web引擎渲染流程进行特殊优化能够有效的降低我们的服务在业务高峰时的性能压力。
以上就是我的分享,非常感谢。
