先来看段代码:

这段代码非常简单,就是先用mmap的方式,为该进程分配10GiB的虚拟内存,然后再用page写的方式,让操作系统为这10GiB虚拟内存,分配对应的物理内存,后sleep,等待我们测试。
运行下:

没啥问题,和我们预期的一样,正常执行。
打开另一个终端,执行以下命令,看下它的内存占用:

上图中的VSZ指的是虚拟内存,RSS指的是物理内存,单位都是KiB,所以该进程虚拟内存和物理内存的使用,都约等于10GiB,没问题。
我们再开个终端,再执行下这个程序:

第二次执行这个程序也没问题,但奇怪的是,此时次执行的那个程序却被kill掉了:

这是为什么呢?
上面我们说到,该程序的逻辑是分配10GiB的物理内存,所以运行两次,也就是要分配20GiB的物理内存。
但在我们的测试机器上,物理内存一共才16GiB,所以,运行两个这样的进程肯定是不行的。
在第二次执行该程序,且向操作系统申请物理内存时,操作系统会发现,物理内存已经没有了。
此时,为了防止整个系统crash掉,linux内核会触发 OOM/Out of Memory killing 机制,即按照一定的规则选择一个进程,将其kill掉,以便回收物理内存,以此来保证机器整体的稳定运行。
同时,该kill事件,也会被记录到内核日志中,且可通过dmesg命令等方式查看。
比如上面个进程被kill掉的事件记录如下:

看上面红色字体行,该行是说,进程14134因为out of memory被linux内核kill掉了,该进程正是上面我们次执行的那个程序。
linux内核的oom killing机制,其实是一种弃车保帅的做法,因为如果我们不kill掉某进程,来释放物理内存的话,那很有可能会导致后续系统级别的crash,两害相权取其轻,操作系统只能这样处理,归根结底,是我们对进程使用物理内存的规划不足,才导致了这种情况。
那为什么不在第二次执行该程序时,在调用mmap分配虚拟内存时就直接报错,返回无法分配内存呢?
这是因为,经过多年观察,linux内核的开发人员发现,绝大部分程序在分配了很大的虚拟内存之后,在大部分时间里,并不会一直使用这么多的物理内存。
所以,为了更合理更高效的利用物理内存资源,linux内核允许虚拟内存的overcommit,即,例如在上面执行mmap分配虚拟内存时,linux内核并不会严格检查,所有运行中的进程分配的虚拟内存加起来,是否超过了整个物理内存大小。
这也就解释了为什么上面第二次运行该程序时,mmap是没有报错的。
但是,虽然mmap的虚拟内存分配成功了,但当真正使用该内存时,比如上面的写内存,此时要分配物理内存,则是有可能失败的,因为虚拟内存的overcommit,很可能导致后续的物理内存不足。
如果真的发生了这种情况,就会触发linux内核的oom killing机制,即linux内核中的oom killer会按一定的规则,选一个进程,将其kill掉,这个上面我们已经演示过了。
那为什么不kill掉第二个进程,而是kill掉个呢?
这个和linux内核中oom killer的选择策略有关,我们直接看源码:
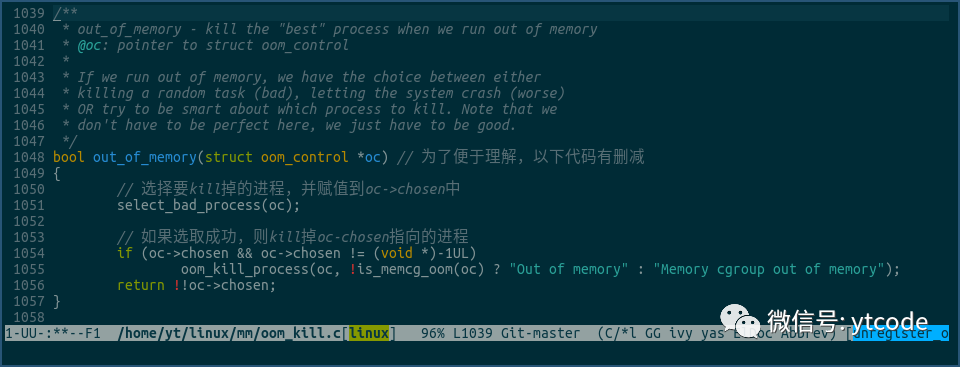
当进程请求操作系统为其分配物理内存时,如果此时物理内存已经没有了,则会触发上图中的out_of_memory函数。
该函数中,会使用select_bad_process选择要被kill掉的进程,然后使用oom_kill_process将其kill掉,来释放物理内存。
在看select_bad_process之前,我们先看下oom_kill_process:

该函数调用了__oom_kill_process:
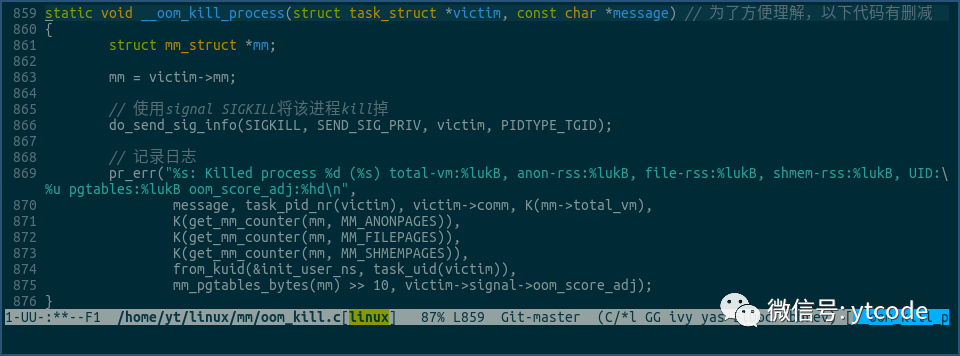
在上面的函数中,通过向victim进程发送SIGKILL这个signal(我们平时使用的kill -9命令,就是用的这个signal),将其kill掉,然后该kill事件,会被记录到内核日志中。
注意,这里记录的日志格式,正好和我们上面用dmesg输出的,14134进程被kill掉事件日志格式完全一样。
kill掉进程的过程就是这样,我们再来看下select_bad_process函数是如何选择要被kill掉进程的:

在该函数中,会遍历系统中的所有进程,然后使用oom_evaluate_task这个函数,对各个进程进行评估:
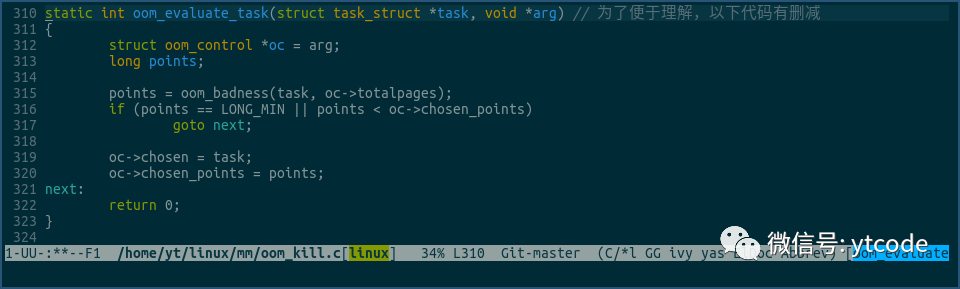
oom_evaluate_task函数中,会使用oom_badness,计算某进程badness的点数,点数越高,越容易被kill掉。
如果badness的点数是LONG_MIN这个特殊值,则直接跳过该进程,即该进程不会成为被kill掉的对象,如果badness点数小于之前选择进程的badness点数,同样也跳过该进程,即被kill掉的进程badness点数要是大的。
遍历中选择的进程,及其badness的点数,会被赋值到oc->chosen和oc->chosen_points里,oc->chosen终指向的进程,就是上面oom_kill_process里kill掉的进程。
我们再来看下badness点数是如何计算的:
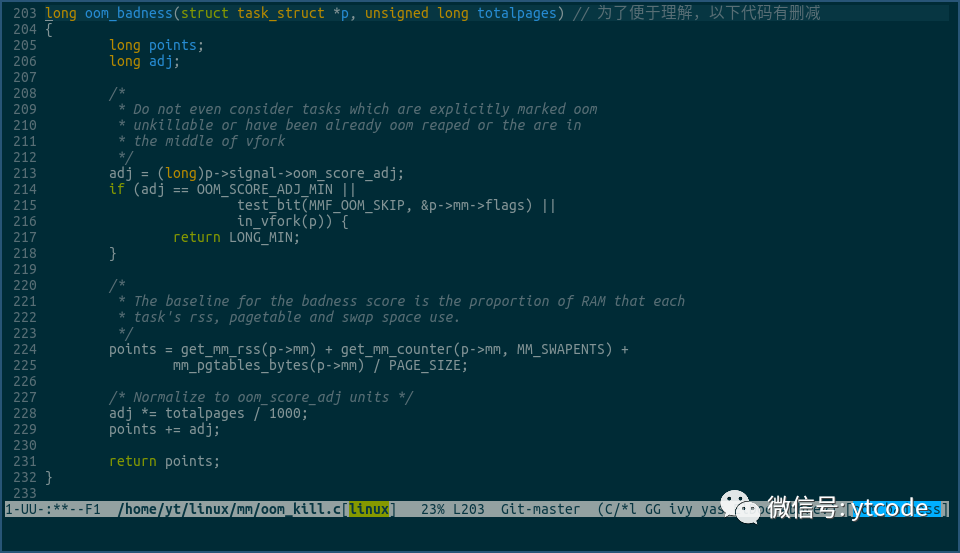
该函数主体逻辑分成两部分,一部分是,在某些情况下,该进程的badness点数直接返回LONG_MIN,即不会被kill掉。
这些情况包括,oom_score_adj的值为OOM_SCORE_ADJ_MIN,即-1000,或者该进程已经在被kill的过程中了,或者该进程在vfork过程中。
该函数逻辑的另外一部分就是计算进程的badness点数,其大致计算规则为:
points = 该进程占用的物理内存总数 + 总物理内存 * oom_score_adj值的千分比。
oom_score_adj的值,是进程独有的,是可以通过写 /proc/[pid]/oom_score_adj 的方式调整的,取值范围为 -1000 到 1000。
该值越大,进程总的badness点数就会越大,进程也就越容易被kill掉。
该值越小,进程总的badness点数就会越小,该进程也就越不容易被kill掉。
上面我们还提到oom_score_adj有一个特殊值为OOM_SCORE_ADJ_MIN,即-1000,表示该进程不能被kill掉。
各进程的oom_score_adj的值默认为0。
综上可知,linux内核中oom killer选择被kill进程的方式,就是看各进程badness点数的大小。
默认情况下,因为各进程的oom_score_adj的值都为0,所以进程占用的物理内存越大,其badness点数也就越大,其也就越容易被kill掉。
这也就解释了,为什么上面在第二次执行那个程序时,被kill掉的是次执行的那个进程,而不是第二次执行的进程,因为次执行的那个进程,占用的物理内存更大。
其实,调整linux内核中oom killer行为的方式有很多,不止修改oom_score_adj值这一种方法。
比如,通过修改 /proc/sys/vm/panic_on_oom 的值,可以让整个系统在物理内存不够时,直接panic,而不是选择性的kill掉某个进程。
比如,通过修改 /proc/sys/vm/overcommit_memory 的值,可以使上面第二次执行的测试程序,在使用mmap分配虚拟内存时,就直接报错,说内存不够。
比如,通过修改 /proc/[pid]/oom_adj 值的方式,同样可以达到修改 /proc/[pid]/oom_score_adj 的目的,不过这个在内核2.6.36版本之后已经不推荐使用。
oom killer行为调整的相关参数,其具体详解可以看proc的man文档:
https://man.archlinux.org/man/proc.5
聊了这么多,那理解linux内核的oom killer机制,对于我们实际应用有哪些帮助呢?
我们假设以下场景:
假如,我们有一台机器,上面跑着一个非常重要的服务,比如数据库,或者某个应用进程等。
它非常耗内存,但是正常情况下,它使用的物理内存肯定不会高于实际总物理内存大小。
有一天我们需要在这台机器上执行一项任务,如果这个任务也比较耗内存,那很可能在执行这项任务时,整台机器的物理内存就完全不够用了,此时,就会触发linux内核的oom killing机制。
又因为在不调整oom_score_adj值的情况下,linux内核中的oom killer默认kill掉的,就是占用物理内存多的那个进程,一般来说,就是我们数据库进程,或其他应用进程,假设这个进程又是线上的一个重要服务,那它被kill掉了,你想一下这会是多么严重的一个事故。
那怎么避免呢?
此时,我们就可以使用上面提到的,用于调整进程badness点数的,oom_score_adj 这个参数。
比如,我们可以通过 echo -1000 > /proc/[pid]/oom_score_adj 命令,将oom_score_adj的值设置为-1000,即该进程不能被kill掉。
又比如,还是通过上面的echo命令,将oom_score_adj的值修改为一个较小的值,来降低它被kill掉的概率。
但是,这些方法其实都不是完美的解决方式。
虽然该机器上的这个重要服务不被kill掉了,但操作系统为了保证整个系统不crash,还是会kill掉其他各种进程。
如果那些进程不重要还好,万一重要的话,还是会相当严重的。
甚至,如果操作系统找不到可以kill掉的进程,那整个系统就会crash,这个就更严重了。
所以,好的方式,还是人为去避免物理内存不足的情况,在机器上跑各种程序时,要提前对整个物理内存的使用,有个规划和预判,好是能预留出一些内存,以防各种误操作。
好了,该篇文章就讲这些内容,如果以后你发现你的进程,莫名奇妙就没有了,可以通过dmesg等方式看下内核日志,确定下你的进程是否被oom kill掉了。
希望本文对你有所帮助,可以的话也帮忙点个赞 。
。
原文链接:https://mp.weixin.qq.com/s/oNgvmytO3zkddiWZjxKsgg
