写入数据的入口函数是:DBImpl::WriteImpl
WriteImpl
rocksdb将每个将要写入的WriteBatch对象封装为一个Writer对象,其中记录了:
- 本次write的wal配置,比如是否要做sync,要写入的wal日志编号等等
- 本次要write的数据,即WriteBatch对象
- 本次write所属的write group
- 本次write的个数据对象的SN(Sequence Number)
- 前置writer
- 后置writer
因为数据库系统随时都会有接连不断的写请求涌入,为了处理并发,rocksdb将多个writer对象用链表串起来,组成一个WriteGroup, 一个WriterGroup会选出一个leader来管理当前group的写过程。而任意时刻只会有一个WriteGroup被写入。
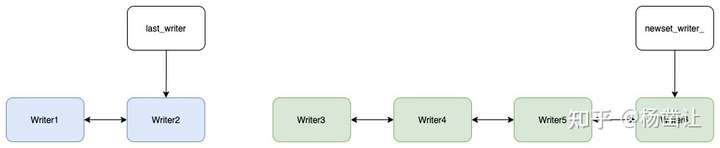
每个writer写入前要先加入一个WriteGroup。加入的过程其实将writer对象加入到writer链表尾端。每个DB对象都对应一个这样的writer链表,writer链表的尾端由newest_writer_记录。即:
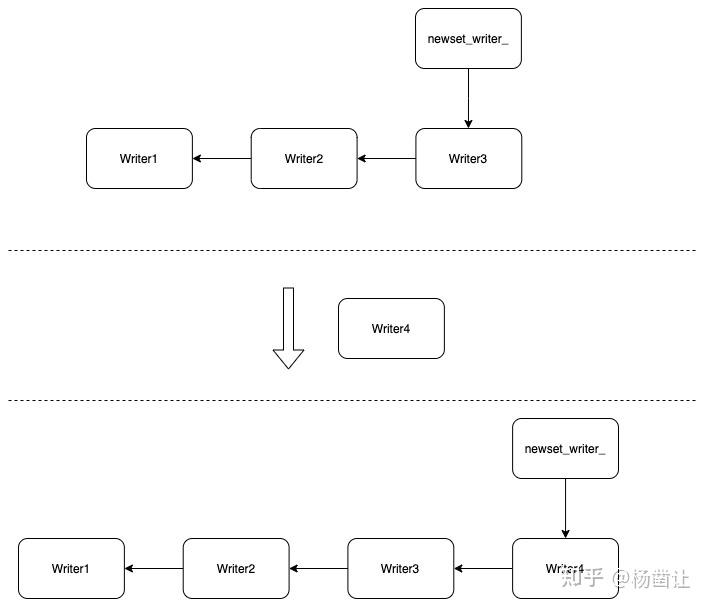
当writer被加入链表以后:
- 如果加入的链表为空,则将当前新加入的writer作为本组的leader
- 如果链表不为空,则阻塞等待当前writer的状态被设置
leader写流程
对于作为leader的writer来说,具体的步骤如下:
- 写入数据之前预处理, 下文叙述。
- 构建write group,构建write group的过程又分为两步:
步构建双向链表。上文提到过每个writer写入前要将自己加入writer链表的尾端。这一步从链表的尾端开始往前遍历,设置双向链表,注意数据库系统是不会停滞的,在构建双向链表的过程中,此时可能会有新的writer插入链表尾。即:
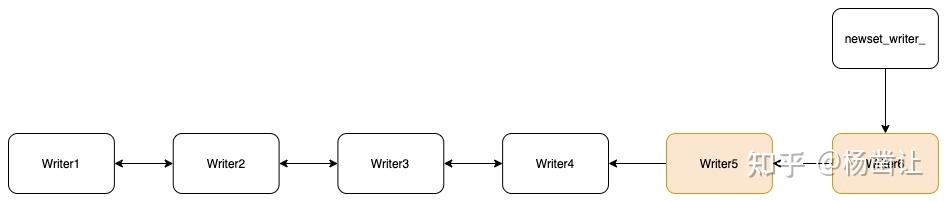
对于一个write group来说,处于链表头的writer会作为本组的writer。第二步从leader开始向后遍历writer链表,在向后遍历的过程中,任何一个writer的wal配置与leader的wal配置不同,则停止构建write group。例如,假设writer3的配置与leader不一致,则构建的write group的元素为writer1和writer2,writer group会有一个last_writer指针指向本write group中的后一个writer。
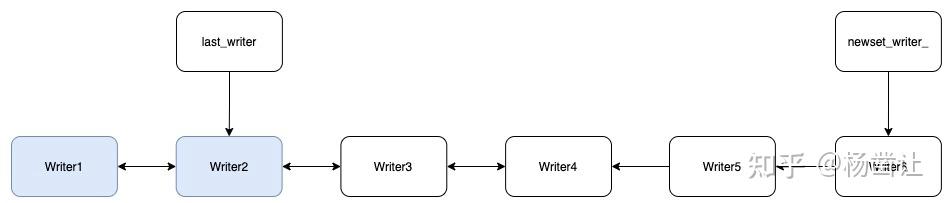
- 遍历上一步构建的write group,计算一些信息:
- total_count, 该write group共要写入多少个kv对
- total_byte_size, 该write group要写入的数据大小
- parallel, 是否允许该write group中的writer并行写memtable。只要用户指定的配置的参数允许并且write group的writer格式大于1,并且没有merge操作那么就允许并行写write group。
- 写WAL日志。
1). 将当前write group所有的writer数据做append,合并成一个merged writer。接下来会将merged writer的数据写入wal日志文件。这里做合并的原因是rocksdb认为多次小IO的性能不如一次大IO好。
2). 设置当前write group要写入的wal日志文件的编号。这个日志编号由一个全局变量logfile_number_记录。
3). 将当前整个数据库系统的下一个LSN,设置为merged writer的LSN, 该LSN作为这批次数据的LSN写入WAL文件。数据库系统的下一个LSN由全局对象VersionSet的last_sequence_记录。
4). 以merged batch为载体,将wal日志写入日志文件
5). 如果当前wal日志写完以后需要做sync,则需要将当前write group写入的log文件以及之前的所有log文件做sync。这一步的目的是为了数据的可靠性。如果当前的wal日志文件做了sync,那么可以保证系统crash后,该wal日志文件的数据依然存在,这时如果不将之前的wal日志文件文件也做sync,那么之前的wal日志文件中的数据可能会丢失,这样会导致rocksdb在恢复时失去数据的一致性。 - 写memtable。
1). 根据之前的判断,如果不能并发写memtable,则由当前线程(leader)将所有的数据写入memtable
2). 如果可以并发写, 计算并设置当前write group的所有writer的sequence。计算的过程如下图所示,如果当前的sequence=k,那么本组个writer的sequence=k,第二个writer的sequence为k加上一个writer数据对的个数,以后以此类推。
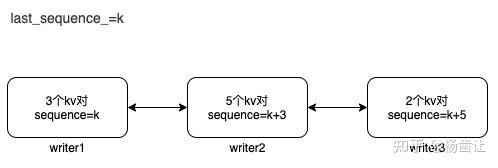
计算好每个writer的sequence后,leader将当前write group的所有writer的状态设置为STATE_PARALLEL_MEMTABLE_WRITER,并将本组的其余writer唤醒,然后将自己的数据写入memtable。
- 如果leader是本组后一个写完memtable的writer,则做一些收尾工作。如果不是,等待本组后一个完成的writer将当前leader的状态置为STATE_COMPLETED。
非leader写流程
对于作为非leader的writer来说
- 如果未指定allow_concurrent_memtable_write,则当前writer被leader唤醒后,它的数据已经由leader完成写入,该writer写流程结束,返回
- 如果指定了allow_concurrent_memtable_write,当前writer被leader唤醒,writer的数据需要由其自身写入memtable,其写入流程和leader写memtable流程一致。当当前writer写完memtable以后,rocksdb接下来会判断当前writer是否为本write group中后一个完成的writer,如果不是,等待本组后一个完成的writer将当前writer的状态置为STATE_COMPLETED,如果是,与leader一样要做一些收尾工作。
设置下一个write group
当leader或者非leader是本组中后一个完成写memtable的writer,它们都要做一些收尾工作,流程如下:
- 更新全局的sequence number
- 设置新的write group。设置新write group的过程其实是将newest_writer_之前的所有writer建立双向链表,然后设置下一个write batch group的新leader(本组后一个writer的后置writer),并将新leader的前置指针设为null。
3. 将本组所有writer的状态置为STATE_COMPLETED,表示完成,然后写流程结束。
写memtable
写memtable的入口函数为InsertInto,InsertInto会根据是由write group写入或是单个writer写入进行重载,不过基本过程一致,下面以put操作为例说明写memtable的过程:
- 创建本次写入的MemTableInserter对象。该对象持有几个重要成员:
MemTableInserter: 记录写操作起始的sequence,该sequence会随着写操作的进行自增。
ColumnFamilyMemTables: 对ColumnFamilySet的封装,可以获取每个ColumnFamily的memtable,即:ColumnFamilySet[ColumnFamily_ID].memtable()。
FlushScheduler: 一个装有元素类型为ColumnFamilyData的链表,记录了所有需要刷memtable的ColumnFamily2. 调用当前writer记录的write batch对象的Iterate函数。该函数会遍历当前write batch的所有kv数据对,然后根据操作类型(增删改)调用MemTableInserter对象封装的处理逻辑。
3. MemTableInserter对象的put接口的执行流程如下:
1). 根据column_family_id获取对应的memtable
2). 根据用户指定的配置,如果写模式不是inplace update类型,则将对应的记录加入到memtable中
3). 如果写模式是inplace update类型,则先在memtable中查找对应的key,如果找到了则更新该key对应的value,未找到则加入到memtable
4). 写完一条数据后sequence自增
5). 如果当前memtable需要flush(也就是memtable的size已经达到了配置的阈值),则将memtable对应的ColumnFamily加入FlushScheduler链表中,等待后台线程处理
注意: 如果采用原地更新的话,那么就不能支持多writer并发写了,原因是如果不是原地更新的话,那么同一个key可能会有多个版本:(keyX, sequence1, val1), (keyX, sequence2, val2), (keyX, sequence3, val3),多个writer并发插数据到跳表的时候,一定能够保证,对于相同的key,sequence越大的排在跳表的后面,这可以保证mvcc或者事务的正确性。如果是原地更新,那么同一个key在跳表中只对应一个节点,多writer并发写的时候,无法保证sequence大的writer后写入相关的节点。
来源 https://zhuanlan.zhihu.com/p/369384686
