和 CPU、内存一样,磁盘和文件系统的管理,也是操作系统核心的功能。
磁盘为系统提供了基本的持久化存储。 文件系统则在磁盘的基础上,提供了一个用来管理文件的树状结构。
那么,磁盘和文件系统是怎么工作的呢?又有哪些指标可以衡量它们的性能呢?
索引节点和目录项
文件系统,本身是对存储设备上的文件,进行组织管理的机制。组织方式不同,就会形成不同的文件系统。
我们要记住重要的一点,在 Linux 中一切皆文件。不仅普通的文件和目录,就连块设备、 套接字、管道等,也都要通过统一的文件系统来管理。
为了方便管理,Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。
索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问 权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会 被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。 目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联 关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
换句话说,索引节点是每个文件的标志,而目录项维护的正是文件系统的树状结构。目录项和索引节点的关系是多对一,你可以简单理解为,一个文件可以有多个别名。
举个例子,通过硬链接为文件创建的别名,就会对应不同的目录项,不过这些目录项本质上还是链接同一个文件,所以,它们的索引节点相同。
索引节点和目录项纪录了文件的元数据,以及文件间的目录关系,那么具体来说,文件数据到底是怎么存储的呢?是不是直接写到磁盘中就好了呢?
实际上,磁盘读写的小单位是扇区,然而扇区只有 512B 大小,如果每次都读写这么小的单位,效率一定很低。所以,文件系统又把连续的扇区组成了逻辑块,然后每次都以逻 辑块为小单元,来管理数据。常见的逻辑块大小为 4KB,也就是由连续的 8 个扇区组成。
为了帮助我们理解目录项、索引节点以及文件数据的关系,画了一张示意图。我们可以对照着这张图,来回忆刚刚讲过的内容,把知识和细节串联起来。

不过,这里有两点需要我们注意:
,目录项本身就是一个内存缓存,而索引节点则是存储在磁盘中的数据。在前面的 Buffer 和 Cache 原理中,我曾经提到过,为了协调慢速磁盘与快速 CPU 的性能差异,文 件内容会缓存到页缓存 Cache 中。那么,我们也应该想到,这些索引节点自然也会缓存到内存中,加速文件的访问。
第二,磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数
据块区。其中,
超级块,存储整个文件系统的状态。
索引节点区,用来存储索引节点。
数据块区,则用来存储文件数据。
虚拟文件系统
目录项、索引节点、逻辑块以及超级块,构成了 Linux 文件系统的四大基本要素。不过, 为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
这里,下图是 Linux 文件系统的架构图,帮我们更好地理解系统调用、VFS、缓存、文 件系统以及块存储之间的关系。
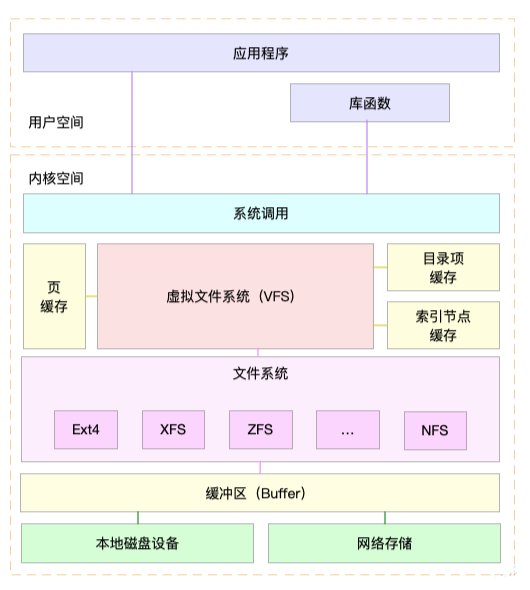
通过这张图,可以看到,在 VFS 的下方,Linux 支持各种各样的文件系统,如 Ext4、 XFS、NFS 等等。按照存储位置的不同,这些文件系统可以分为三类。
类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是 一种常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、 SMB、iSCSI 等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根 目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。
文件系统 I/O
把文件系统挂载到挂载点后,你就能通过挂载点,再去访问它管理的文件了。VFS 提供了一组标准的文件访问接口。这些接口以系统调用的方式,提供给应用程序使用。
就拿 cat 命令来说,它首先调用 open() ,打开一个文件;然后调用 read() ,读取文件的内容;后再调用 write() ,把文件内容输出到控制台的标准输出中:
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
文件读写方式的各种差异,导致 I/O 的分类多种多样。常见的有,缓冲与非缓冲 I/O、 直接与非直接 I/O、阻塞与非阻塞 I/O、同步与异步 I/O 等。接下来,我们就详细看这四种分类。
种,根据是否利用标准库缓存,可以把文件 I/O 分为缓冲 I/O 与非缓冲 I/O。
缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。
非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。
注意,这里所说的“缓冲”,是指标准库内部实现的缓存。比方说,你可能见到过,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来。
无论缓冲 I/O 还是非缓冲 I/O,它们终还是要经过系统调用来访问文件。我们知道,系统调用后,还会通过页缓存,来减少磁盘的 I/O 操作。
第二,根据是否利用操作系统的页缓存,可以把文件 I/O 分为直接 I/O 与非直接 I/O。
直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。
想要实现直接 I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认 的是非直接 I/O。
不过要注意,直接 I/O、非直接 I/O,本质上还是和文件系统交互。如果是在数据库等场景中,还会看到,跳过文件系统读写磁盘的情况,也就是我们通常所说的裸 I/O。
第三,根据应用程序是否阻塞自身运行,可以把文件 I/O 分为阻塞 I/O 和非阻塞 I/O
所谓阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
所谓非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。
比方说,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问;而如果不做任何设置,默认的就是阻塞访问。
第四,根据是否等待响应结果,可以把文件 I/O 分为同步和异步 I/O
所谓同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
所谓异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
例如,在操作文件时,如果设置了 O_SYNC 或者 O_DSYNC 标志,就代表同步 I/O。如果设置了 O_DSYNC,就要等文件数据写入磁盘后,才能返回;而 O_SYNC,则是在 O_DSYNC 基础上,要求文件元数据也要写入磁盘后,才能返回。
再比如,在访问管道或者网络套接字时,设置了 O_ASYNC 选项后,相应的 I/O 就是异步I/O。这样,内核会再通过 SIGIO 或者 SIGPOLL,来通知进程文件是否可读写。
我们可能发现了,这里的好多概念也经常出现在网络编程中。比如非阻塞 I/O,通常会跟 select/poll 配合,用在网络套接字的 I/O 中。
这下我们也应该可以理解,“Linux 一切皆文件”的深刻含义。无论是普通文件和块设备、还是网络套接字和管道等,它们都通过统一的 VFS 接口来访问。
性能观测
接下来,打开一个终端,SSH 登录到服务器上,我们一起来探索,如何观测文件系统的性能。
容量
对文件系统来说,常见的一个问题就是空间不足。当然,你可能本身就知道,用 df 命 令,就能查看文件系统的磁盘空间使用情况。比如:
df /dev/vda1
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/vda1 104846316 28228044 76618272 27% /
可以看到,我的根文件系统只使用了 27% 的空间。这里还要注意,总空间用 1K- 快 的数量来表示,你可以给 df 加上 -h 选项,以获得更好的可读性:
df -h /dev/vda1
文件系统 容量 已用 可用 已用% 挂载点
/dev/vda1 100G 27G 74G 27% /
不过有时候,明明碰到了空间不足的问题,可是用 df 查看磁盘空间后,却发现剩余空间还有很多。这是怎么回事呢?
其实除了文件数据,索引节点也占用磁盘空间。可以给 df 命令加上 -i 参数,查看索引节点的使用情况,如下所示:
df -h -i /dev/vda1
文件系统 Inode 已用(I) 可用(I) 已用(I)% 挂载点
/dev/vda1 50M 162K 50M 1% /
索引节点的容量,(也就是 Inode 个数)是在格式化磁盘时设定好的,一般由格式化工具自动生成。当发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。
所以,一般来说,删除这些小文件,或者把它们移动到索引节点充足的其他磁盘中,就可以解决这个问题。
缓存
可以用 free 或 vmstat,来观察页缓存的大小。free 输出的 Cache,是页缓存和可回收 Slab 缓存的和,你可以从 /proc/meminfo ,直接得到它们的大小:
cat /proc/meminfo | grep -E "SReclaimable|Cached"
Cached: 2014100 kB
SwapCached: 5316 kB
SReclaimable: 216128 kB
话说回来,文件系统中的目录项和索引节点缓存,又该如何观察呢?
实际上,内核使用 Slab 机制,管理目录项和索引节点的缓存。/proc/meminfo 只给出了 Slab 的整体大小,具体到每一种 Slab 缓存,还要查看 /proc/slabinfo 这个文件。
比如,运行下面的命令,你就可以得到,所有目录项和各种文件系统索引节点的缓存情况:
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunab
cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
ovl_inode 66 66 736 22 4 : tunables : slabdata 3 3
fuse_inode 832 19 4 : tunables : slabdata
xfs_inode 100470 110736 1024 16 4 : tunables : slabdata 6921 6921
mqueue_inode_cache 64 64 1024 16 4 : tunables : slabdata 4 4
hugetlbfs_inode_cache 48 48 680 24 4 : tunables : slabdata 2 2
sock_inode_cache 4581 4807 704 23 4 : tunables : slabdata 209 209
shmem_inode_cache 1816 2541 760 21 4 : tunables : slabdata 121 121
proc_inode_cache 10210 13024 728 22 4 : tunables : slabdata 592 592
inode_cache 36498 38832 656 24 4 : tunables : slabdata 1618 1618
dentry 150086 183204 192 21 1 : tunables : slabdata 8724 8724
这个界面中,dentry 行表示目录项缓存,inode_cache 行,表示 VFS 索引节点缓存,其 余的则是各种文件系统的索引节点缓存。
/proc/slabinfo 的列比较多,具体含义可以查询 man slabinfo。在实际性能分析中,我们更常使用 slabtop ,来找到占用内存多的缓存类型。
比如,下面就是运行 slabtop 得到的结果:
# 按下 c 按照缓存大小排序,按下 a 按照活跃对象数排序
slabtop
Active / Total Objects (% used) : 991123 / 1087653 (91.1%)
Active / Total Slabs (% used) : 40627 / 40627 (100.0%)
Active / Total Caches (% used) : 103 / 138 (74.6%)
Active / Total Size (% used) : 329426.37K / 371563.66K (88.7%)
Minimum / Average / Maximum Object : .01K / .34K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
183204 150026 81% .19K 8724 21 34896K dentry
38832 36498 93% .64K 1618 24 25888K inode_cache
....
6174 6009 97% .19K 294 21 1176K cred_jar
6066 5878 96% .44K 337 18 2696K xfrm_dst_cache
5950 5950 .02K 35 170 140K avtab_node
4807 4581 95% .69K 209 23 3344K sock_inode_cache
3948 3812 96% 1.12K 141 28 4512K signal_cache
3744 3680 98% .25K 234 16 936K skbuff_head_cache
3634 3634 .09K 79 46 316K trace_event_file
从这个结果你可以看到,在我的系统中,目录项(dentry)和索引节点(inode_cache)占用了多的 Slab 缓存。不 过它们占用的内存其实并不大,加起来也只有 60MB 左右。
总结
文件系统,是对存储设备上的文件,进行组织管理的一种机制。为了支持各类不同的文件系统,Linux 在各种文件系统实现上,抽象了一层虚拟文件系统(VFS)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,就只需要跟 VFS 提供的统一接口进行交互。
为了降低慢速磁盘对性能的影响,文件系统又通过页缓存、目录项缓存以及索引节点缓存,缓和磁盘延迟对应用程序的影响。
- EOF -
来自:https://mp.weixin.qq.com/s/XWuhPJO0UCxs-hms0uEEcQ
