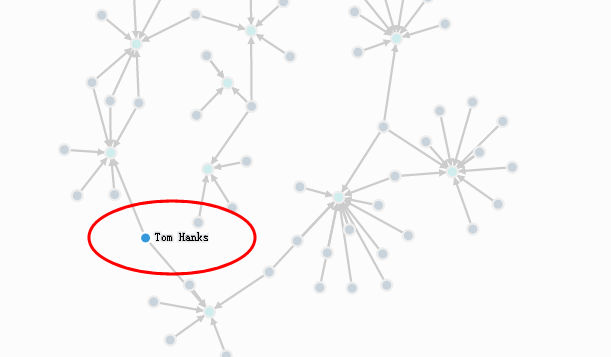
三 查找操作
1过滤 name = "Tom Hanks"的人
MATCH (n:Person)
WHERE n.name = "Tom Hanks"
RETURN n;
另一种写法:
MATCH (n:Person {name:"Tom Hanks"})
RETURN n;
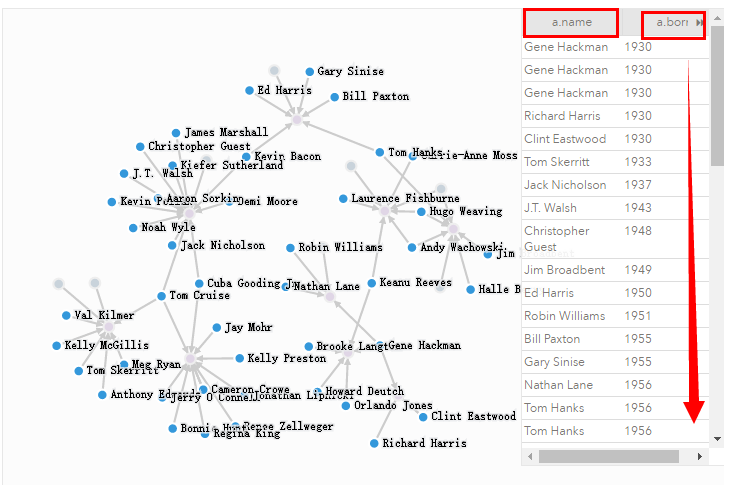
2 排序Order, 限制Limit and 跳跃Skip
根据演员的出生日期排序输出:
MATCH (a:Person)-[:ACTED_IN]->()
RETURN a.name, a.born
ORDER BY a.born
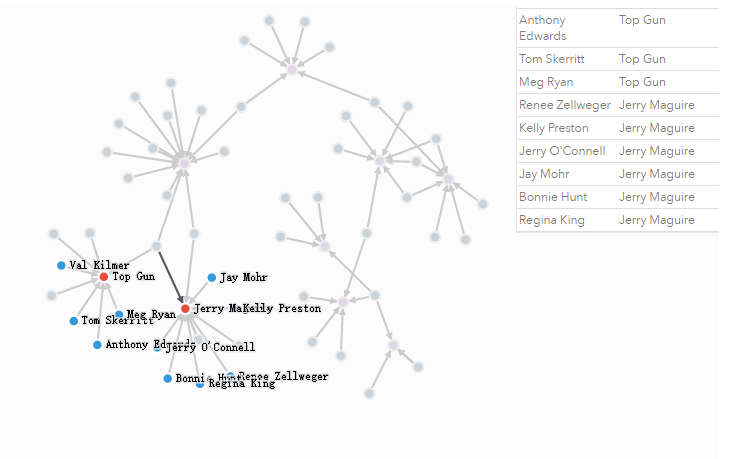
利用limit和skip分页,下面显示第二页的语句:
MATCH (a)-[:ACTED_IN]->(m)
RETURN a.name, m.title
SKIP 10
LIMIT 10;
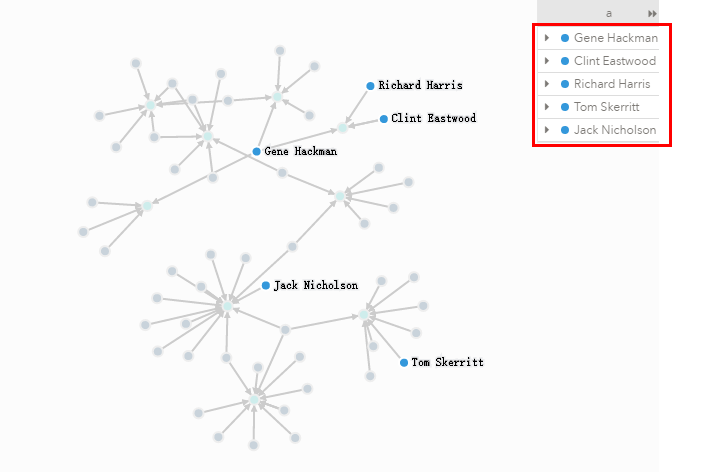
3distinct关键字使用
查询所有电影的参演演员中年龄高的五个人:
MATCH (a)-[:ACTED_IN]->()
RETURN DISTINCT a
ORDER BY a.born
LIMIT 5
说了这么多,下面两个问题大家能写出对应的CQL吗:
( 1 )查询演员 Tom Hanks 出演的所有电影,并且电影的出版在2000以后?
MATCH (tom:Person)-[:ACTED_IN]->(movie)
WHERE tom.name="Tom Hanks"
AND movie.released > 2000
RETURN movie.title;
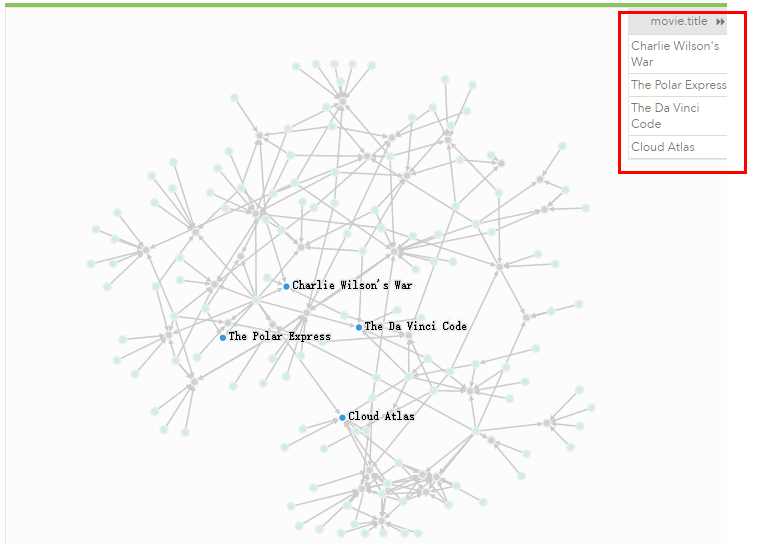
( 2 )查询Keanu Reeves 出演的所有电影,并且他的角色是Neo?
MATCH (keanu:Person)-[r:ACTED_IN]->(movie)
WHERE keanu.name="Keanu Reeves"
AND "Neo" IN r.roles
RETURN movie.title;

3 使用比较筛选查询结果
<的使用:
MATCH (tom:Person)-[:ACTED_IN]->()<-[:ACTED_IN]-(a:Person)
WHERE tom.name="Tom Hanks"
AND a.born < tom.born
RETURN a.name;
更复杂一点的语句:
MATCH (tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(movie),
(movie)<-[:ACTED_IN]-(a:Person)
WHERE a.born < tom.born
RETURN DISTINCT a.name, (tom.born - a.born) AS diff;
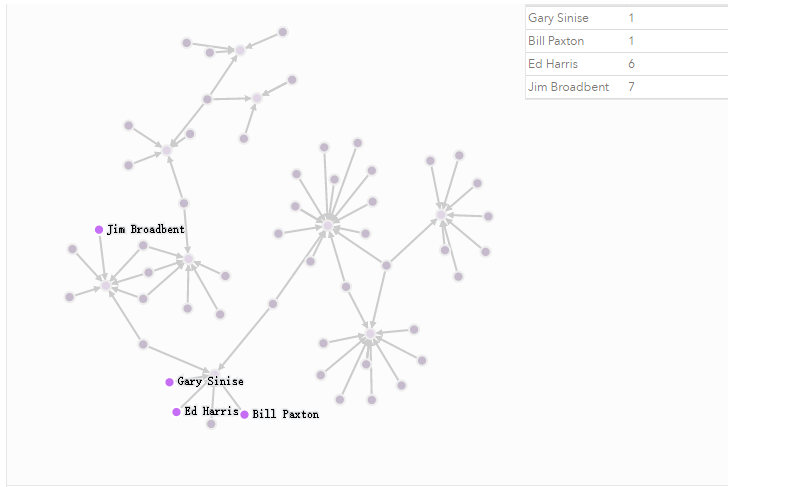
4使用模式查询
MATCH (gene:Person)
WHERE gene.name="Gene Hackman"
RETURN gene;
复杂一点的:找到所有和Gene一起工作的演员?
MATCH (gene:Person)-[:ACTED_IN]->()<-[:ACTED_IN]-(other)
WHERE gene.name="Gene Hackman"
RETURN DISTINCT other;
再复杂一点:找到与Gene一起工作并且导演过自己电影的伙伴?
MATCH (gene:Person)-[:ACTED_IN]->(m),
(other)-[:ACTED_IN]->(m)
WHERE gene.name="Gene Hackman"
AND (other)-[:DIRECTED]->()
RETURN DISTINCT other;
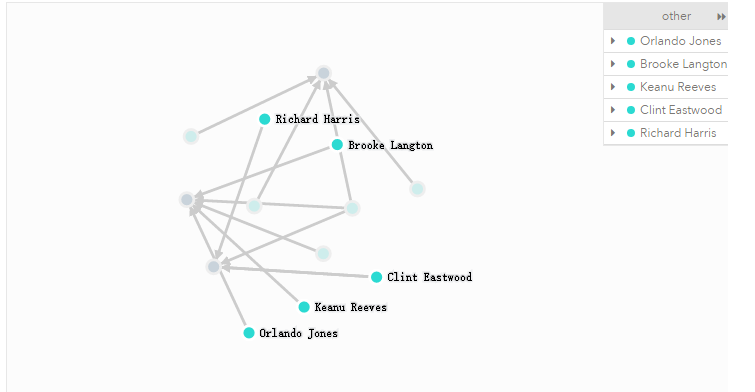
更复杂的了:找到与Gene一起工作过,但没有同时和"Robin Williams"合作的演员?
MATCH (gene:Person {name:"Gene Hackman"})-[:ACTED_IN]->(movie),
(other)-[:ACTED_IN]->(movie),
(robin:Person {name:"Robin Williams"})
WHERE NOT (robin)-[:ACTED_IN]->(movie)
RETURN DISTINCT other;
5 索引 index
创建索引:INDEX
CREATE INDEX ON :Movie(title);
CREATE INDEX ON :Person(name);
这样的话,查询中有根据name或title的语句就会很快了。(索引的目的就是为了加速查询的)
比如下面的这条语句速度就会提高:
MATCH (gene:Person)-[:ACTED_IN]->(m),
(other)-[:ACTED_IN]->(m)
WHERE gene.name="Gene Hackman"
RETURN DISTINCT other;
创建标签索引:
CREATE INDEX ON :Person(name);
CREATE INDEX ON :Movie(title);
标签的检索速度就可以提升了,比如下面这句:
MATCH (tom:Person)-[:ACTED_IN]->(movie),
(kevin:Person)-[:ACTED_IN]->(movie)
WHERE tom.name="Tom Hanks" AND
kevin.name="Kevin Bacon"
RETURN DISTINCT movie;
6聚类操作
复制代码
count(x) //Count the number of occurrences
min(x) //Get the lowest value
max(x) //Get the highest value
avg(x) //Get the average of a numeric value
sum(x) //Sum up values
collect(x) //Collect all the values into an collection
复制代码
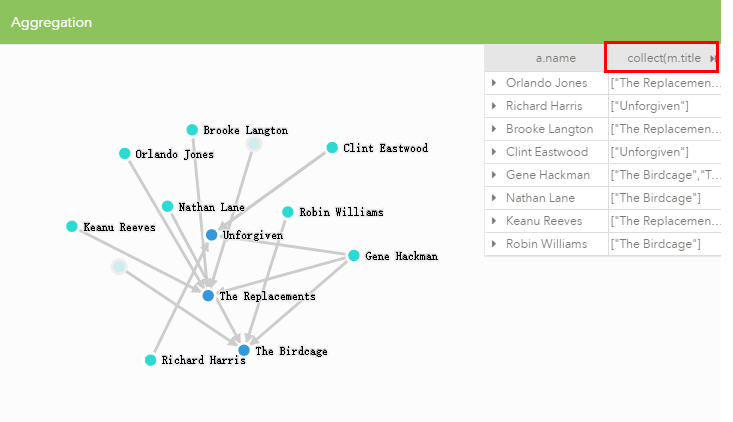
eq
MATCH (a:Person)-[:ACTED_IN]->(m)
RETURN a.name, collect(m.title);
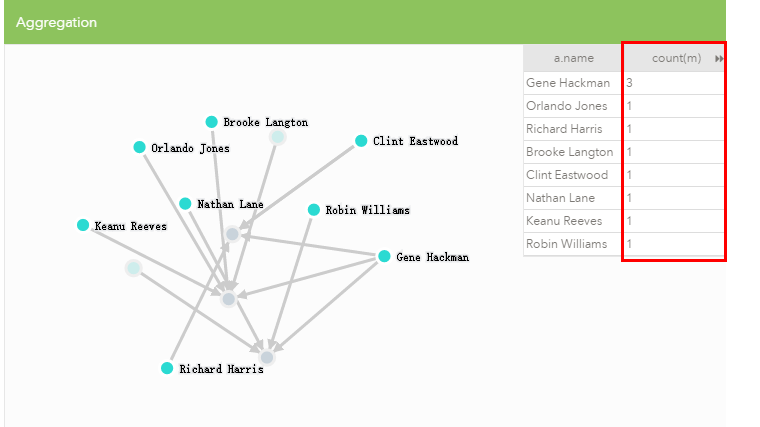
eq2
MATCH (a:Person)-[:ACTED_IN]->(m)
RETURN a.name, count(m)
ORDER BY count(m) DESC
LIMIT 10;
查询我们已经了解了不少,下一篇我继续介绍怎么创建图数据库,希望继续关注。
