阿里近几年公开的推荐领域算法可真不少,既有传统领域的探索如MLR算法,还有深度学习领域的探索如entire -space multi-task model,Deep Interest Network等,同时跟清华大学合作展开了强化学习领域的探索,提出了MARDPG算法。从本篇开始,我们就一起来探秘这些算法。这里,我们只是大体了解一下每一个算法的思路,对于数学部分的介绍,我们不会过多的涉及。
1、算法介绍
现阶段各CTR预估算法的不足
我们这里的现阶段,不是指的今时今日,而是阿里刚刚公开此算法的时间,大概就是去年的三四月份吧。
业界常用的CTR预估算法的不足如下表所示:

那么挑战来了,如何设计算法从大规模数据中挖掘出具有推广性的非线性模式?
MLR算法
2011-2012年期间,阿里妈妈专家盖坤创新性地提出了MLR(mixed logistic regression)算法,引领了广告领域CTR预估算法的全新升级。MLR算法创新地提出并实现了直接在原始空间学习特征之间的非线性关系,基于数据自动发掘可推广的模式,相比于人工来说效率和精度均有了大幅提升。
MLR可以看做是对LR的一个自然推广,它采用分而治之的思路,用分片线性的模式来拟合高维空间的非线性分类面,其形式化表达如下:

其中u是聚类参数,决定了空间的划分,w是分类参数,决定空间内的预测。这里面超参数分片数m可以较好地平衡模型的拟合与推广能力。当m=1时MLR就退化为普通的LR,m越大模型的拟合能力越强,但是模型参数规模随m线性增长,相应所需的训练样本也随之增长。因此实际应用中m需要根据实际情况进行选择。例如,在阿里的场景中,m一般选择为12。下图中MLR模型用4个分片可以完美地拟合出数据中的菱形分类面。

在实际中,MLR算法常用的形式如下,使用softmax作为分片函数:
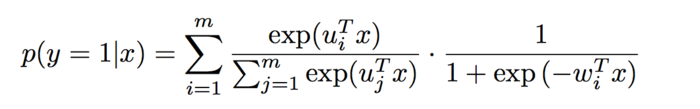
在这种情况下,MLR模型可以看作是一个FOE model:

关于损失函数的设计,阿里采用了 neg-likelihood loss function以及L1,L2正则,形式如下:
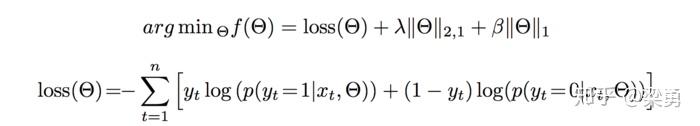
由于加入了正则项,MLR算法变的不再是平滑的凸函数,梯度下降法不再适用,因此模型参数的更新使用LBFGS和OWLQN的结合,具体的优化细节大家可以参考论文(https://arxiv.org/pdf/1704.05194.pdf).
MLR算法适合于工业级的大规模稀疏数据场景问题,如广告CTR预估。背后的优势体现在两个方面:
端到端的非线性学习:从模型端自动挖掘数据中蕴藏的非线性模式,省去了大量的人工特征设计,这 使得MLR算法可以端到端地完成训练,在不同场景中的迁移和应用非常轻松。
稀疏性:MLR在建模时引入了L1和L2,1范数正则,可以使得终训练出来的模型具有较高的稀疏度, 模型的学习和在线预测性能更好。当然,这也对算法的优化求解带来了巨大的挑战。
2、算法简单实现
我们这里只是简单实现一个tensorflow版本的MLR模型,通过代码来了解一下模型的思想。
代码的github地址为:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-MLR-Demo
所使用的数据下载地址为:http://archive.ics.uci.edu/ml/datasets/Adult,该数据是一个二分类的数据,所预测的任务是判断一个人是否能够一年挣到50K的钱,数据介绍如下:

数据处理
数据中存在连续特征和离散特征,所以我们先要对数据进行一个简单的处理,处理包括将离散特征转换为one-hot以及对连续特征进行标准化。有一个需要注意的地方,训练集和测试集中离散特征出现的个数可能不一样,因此需要先将数据合并,然后转换成one-hot,后再分开,代码如下。
import pandas as pd
from sklearn.preprocessing import StandardScaler
def get_data():
train_data = pd.read_table("data/adult.data.txt",header=None,delimiter=',')
test_data = pd.read_table("data/adult.test.txt",header=None,delimiter=',')
all_columns = ['age','workclass','fnlwgt','education','education-num',
'marital-status','occupation','relationship','race','sex',
'capital-gain','capital-loss','hours-per-week','native-country','label','type']
continus_columns = ['age','fnlwgt','education-num','capital-gain','capital-loss','hours-per-week']
dummy_columns = ['workclass','education','marital-status','occupation','relationship','race','sex','native-country']
train_data['type'] = 1
test_data['type'] = 2
all_data = pd.concat([train_data,test_data],axis=0)
all_data.columns = all_columns
all_data = pd.get_dummies(all_data,columns=dummy_columns)
test_data = all_data[all_data['type']==2].drop(['type'],axis=1)
train_data = all_data[all_data['type']==1].drop(['type'],axis=1)
train_data['label'] = train_data['label'].map(lambda x: 1 if x.strip() == '>50K' else 0)
test_data['label'] = test_data['label'].map(lambda x: 1 if x.strip() == '>50K.' else 0)
for col in continus_columns:
ss = StandardScaler()
train_data[col] = ss.fit_transform(train_data[[col]])
test_data[col] = ss.transform(test_data[[col]])
train_y = train_data['label']
train_x = train_data.drop(['label'],axis=1)
test_y = test_data['label']
test_x = test_data.drop(['label'],axis=1)
return train_x,train_y,test_x,test_y
数据处理完后,特征的维度是108维。
MLR的实现
MLR的实现需要两组参数,分别是聚类参数和分类参数:
u = tf.Variable(tf.random_normal([108,m],0.0,0.5),name='u')
w = tf.Variable(tf.random_normal([108,m],0.0,0.5),name='w')
随后,我们要计算我们的预估值:
U = tf.matmul(x,u)
p1 = tf.nn.softmax(U)
W = tf.matmul(x,w)
p2 = tf.nn.sigmoid(W)
pred = tf.reduce_sum(tf.multiply(p1,p2),1)
损失函数我们刚才介绍过了,在tensorflow中,我们选择FtrlOptimizer作为优化器,可以给我们的损失函数加上正则项:
cost1=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=pred, labels=y))
cost=tf.add_n([cost1])
train_op = tf.train.FtrlOptimizer(learning_rate).minimize(cost)
随后,我们就可以进行试验了。
实验结果
本文对比了在当前给出的数据集下,m=5,10,15,25 以及lr算法的效果,结果如下:
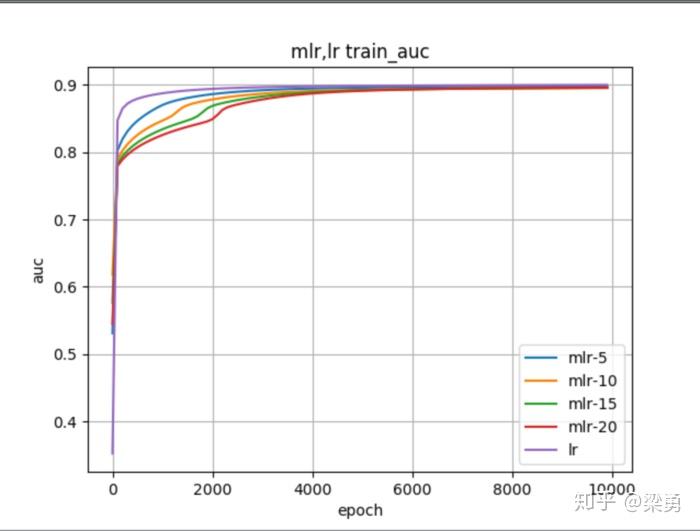
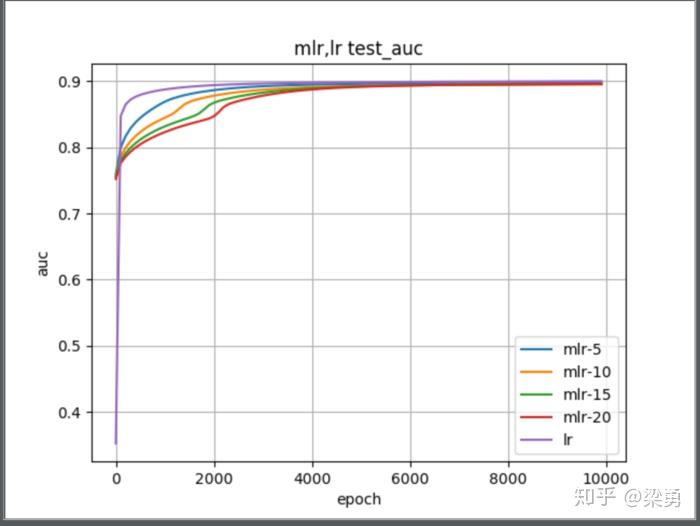
可以看到,lr的效果是好的,随着m的增加,模型的效果越来越差。当然,这并不能说明mlr效果不如lr好,只是我们的数据实在是太少了,哈哈。
