准备工作:下载示例数据,提取码:tkqn 数据例子

经过了数据读取、数据预览,接下来是要开始清洗数据了。今天涉及的清洗步骤有:格式修改、去除空格、替换、分列、合并。
- 字符串格式→日期格式

数据的Time列看似日期格式,但实际上是字符串格式。

#导入库
import datetime
import pandas as pd
#读取数据
amazon_data = pd.read_excel(r'D:\data\python\amazon-fine-foods\amazon_data.xlsx',sheetname='data')
price = pd.read_excel(r'D:\data\python\amazon-fine-foods\amazon_data.xlsx',sheetname='price')
#数据清洗
#字符串转日期
amazon_data.loc[:,'日期date'] = amazon_data['Time'].apply(lambda x: datetime.datetime.strptime(x,'%Y/%m/%d %H:%M')) 转换出来的格式为日期格式了。
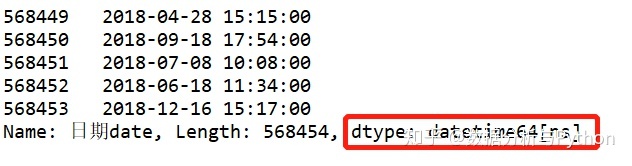
- 去除空格
实际应用中,可能会碰到某些列有空格的情况,比如“电脑”、“电 脑”。虽然字面意思是一样,在统计的时候,Python会把它们当做两个不同的东西。所以在清洗的时候,要把“电 脑”的空格去掉。
本数据例子中,暂且以【ProfileName】列为示范,去除空格。

#去除空格
amazon_data.loc[:,'ProfileName无空格'] = amazon_data['ProfileName'].str.replace(' ','')
对比一下,amazon_data['ProfileName无空格']的已经把空格都去掉了
- 分列
比如有这么一个数据:‘四川省 成都市’,在统计中只需要‘四川省’,在Excel中是根据空格进行分列,然后取省份那列。Python也是同样的操作。本示例还是用【ProfileName】列为示范。
#数据分列
amazon_data.loc[:,'ProfileName分列'] = amazon_data['ProfileName'].str.split(' ').str[0]
如果需要第2个即“成都市”,就 .str[1]。如果是 ‘四川省:成都市’,那么可以写 amazon_data['ProfileName'].str.split(':').str[0]
- 合并
本例子中,data表的productid对应 price中的productid,现在需要把data中的产品价格加进来。用到merge方法。
#合并
amazon_data = pd.merge(left=amazon_data,right=price,on='ProductId')pd.merge(left=df1, right=df2, left_on=’key1’, right_on=’key2’, how=’left’)
left左表,right右表,left_on左表的连接键,right_on右表连接键,how是连接方式:左连left,右连right,外连outer,内连inner(默认)。
语法讲解及延伸
- datetime
这是个很常用的日期格式处理库,示例当中的:
amazon_data['Time'].apply(lambda x: datetime.datetime.strptime(x,'%Y/%m/%d %H:%M')) strptime()括号内的东西一定要注意,'%Y/%m/%d %H:%M'格式与amazon_data['Time']格式要一致。
比如:
‘2018/12/16 15:17’对应 '%Y/%m/%d %H:%M'
‘2018-12-16 15:17:18’对应 '%Y-%m-%d %H:%M:%S'
如果写错了,就会出现错误,说你的样式比匹配。

- 去除空格
去除空格还有个方法是
amazon_data['ProfileName'].str.strip(' ')但这个只能去除字符串前后两端的空格,无法去除中间的空格。如果要去除所有空格,就需要用replace替换。
- replace替换
多个替换如何做?比如把 '我我我你你你' 替换成 '你你你我我我':

连续使用replace,是从前往后替换的。学过C的应该知道如何交换两个变量的值吧?
- 合并
合并表格,除了用merge,还有个方法是concat。concat可以纵向合并,也可以横向合并。
pd.concat([df1, df2] ) 纵向合并,即把df2的数据接到df1后面。
pd.concat([df1, df2], axis=1, join='inner') 横向合并,按索引取交集。
