
谈起消息队列,内心还是会有些波澜。
消息队列,缓存,分库分表是高并发解决方案三剑客,而消息队列是我喜欢,也是思考多的技术。
我想按照下面的四个阶段分享我与消息队列的故事,同时也是对我技术成长经历的回顾。
初识:ActiveMQ 进阶:Redis&RabbitMQ 升华:MetaQ 钟情:RocketMQ
1 初识ActiveMQ
1.1 异步&解耦
2011年初,我在一家互联网彩票公司做研发。
我负责的是用户中心系统,提供用户注册,查询,修改等基础功能。用户注册成功之后,需要给用户发送短信。
因为原来都是面向过程编程,我就把新增用户模块和发送短信模块都揉在一起了。
起初都还好,但问题慢慢的显现出来。
短信渠道不够稳定,发送短信会达到5秒左右,这样用户注册接口耗时很大,影响前端用户体验; 短信渠道接口发生变化,用户中心代码就必须修改了。但用户中心是核心系统。每次上线都必要谨小慎微。这种感觉很别扭,非核心功能影响到核心系统了。
个问题,我可以采取线程池的方法来做,主要是异步化。但第二个问题却让我束手无措。
于是我向技术经理请教,他告诉我引入消息队列去解决这个问题。
将发送短信功能单独拆成独立的Job服务; 用户中心用户注册成功后,发送一条消息到消息队列,Job服务收到消息调用短信服务发送短信即可。

这时,我才明白: 消息队列核心的功能就是异步和解耦。
1.2 调度中心
彩票系统的业务是比较复杂的。在彩票订单的生命周期里,经过创建,拆分子订单,出票,算奖等诸多环节。每一个环节都需要不同的服务处理,每个系统都有自己独立的表,业务功能也相对独立。假如每个应用都去修改订单主表的信息,那就会相当混乱了。
公司的架构师设计了调度中心的服务,调度中心的职责是维护订单核心状态机,订单返奖流程,彩票核心数据生成。
调度中心通过消息队列和出票网关,算奖服务等系统传递和交换信息。
这种设计在那个时候青涩的我的眼里,简直就是水滴vs人类舰队,降维打击。
随着我对业务理解的不断深入,我隐约觉得:“好的架构是简洁的,也是应该易于维护的”。
当彩票业务日均千万交易额的时候,调度中心的研发维护人员也只有两个人。调度中心的源码里业务逻辑,日志,代码规范都是极好的。
在我日后的程序人生里,我也会下意识模仿调度中心的编码方式,“不玩奇技淫巧,代码是给人阅读的”。
1.3 重启大法
随着彩票业务的爆炸增长,每天的消息量从30万激增到150~200万左右,一切看起来似乎很平稳。
某一天双色球投注截止,调度中心无法从消息队列中消费数据。消息总线处于只能发,不能收的状态下。整个技术团队都处于极度的焦虑状态,“要是出不了票,那可是几百万的损失呀,要是用户中了两个双色球?那可是千万呀”。大家急得像热锅上的蚂蚁。
这也是整个技术团队次遇到消费堆积的情况,大家都没有经验。
首先想到的是多部署几台调度中心服务,部署完成之后,调度中心消费了几千条消息后还是Hang住了。这时,架构师只能采用重启的策略。你没有看错,就是重启大法。说起来真的很惭愧,但当时真的只能采用这种方式。
调度中心重启后,消费了一两万后又Hang住了。只能又重启一次。来来回回持续20多次,像挤牙膏一样。而且随着出票截止时间的临近,这种思想上的紧张和恐惧感更加强烈。终于,通过1小时的手工不断重启,消息终于消费完了。
我当时正好在读毕玄老师的《分布式java应用基础与实践》,猜想是不是线程阻塞了,于是我用Jstack命令查看堆栈情况。果然不出所料,线程都阻塞在提交数据的方法上。

我们马上和DBA沟通,发现oracle数据库执行了非常多的大事务,每次大的事务执行都需要30分钟以上,导致调度中心的调度出票线程阻塞了。
技术部后来采取了如下的方案规避堆积问题:
生产者发送消息的时候,将超大的消息拆分成多批次的消息,减少调度中心执行大事务的几率; 数据源配置参数,假如事务执行超过一定时长,自动抛异常,回滚。
1.4 复盘
Spring封装的ActiveMQ的API非常简洁易用,使用过程中真的非常舒服。
受限于当时彩票技术团队的技术水平和视野,我们在使用ActiveMQ中遇到了一些问题。
高吞吐下,堆积到一定消息量易Hang住;
技术团队发现在吞吐量特别高的场景下,假如消息堆积越大,ActiveMQ有较小几率会Hang住的。
出票网关的消息量特别大,有的消息并不需要马上消费,但是为了规避消息队列Hang住的问题,出票网关消费数据的时候,先将消息先持久化到本地磁盘,生成本地XML文件,然后异步定时执行消息。通过这种方式,我们大幅度提升了出票网关的消费速度,基本杜绝了出票网关队列的堆积。
但这种方式感觉也挺怪的,消费消息的时候,还要本地再存储一份数据,消息存储在本地,假如磁盘坏了,也有丢消息的风险。
高可用机制待完善
我们采用的master/slave部署模式,一主一从,服务器配置是4核8G 。
这种部署方式可以同时运行两个ActiveMQ, 只允许一个slave连接到Master上面,也就是说只能有2台MQ做集群,这两个服务之间有一个数据备份通道,利用这个通道Master向Slave单向地数据备份。这个方案在实际生产线上不方便, 因为当Master挂了之后, Slave并不能自动地接收Client发来的请来,需要手动干预,且要停止Slave再重启Master才能恢复负载集群。
还有一些很诡异丢消息的事件,生产者发送消息成功,但master控制台查询不到,但slave控制台竟然能查询到该消息。
但消费者没有办法消费slave上的消息,还得通过人工介入的方式去处理。
2 进阶Redis&RabbitMQ
2014年,我在艺龙网从事红包系统和优惠券系统优化相关工作。
2.1 Redis可以做消息队列吗
酒店优惠券计算服务使用的是初代流式计算框架Storm。Storm这里就不详细介绍,可以参看下面的逻辑图: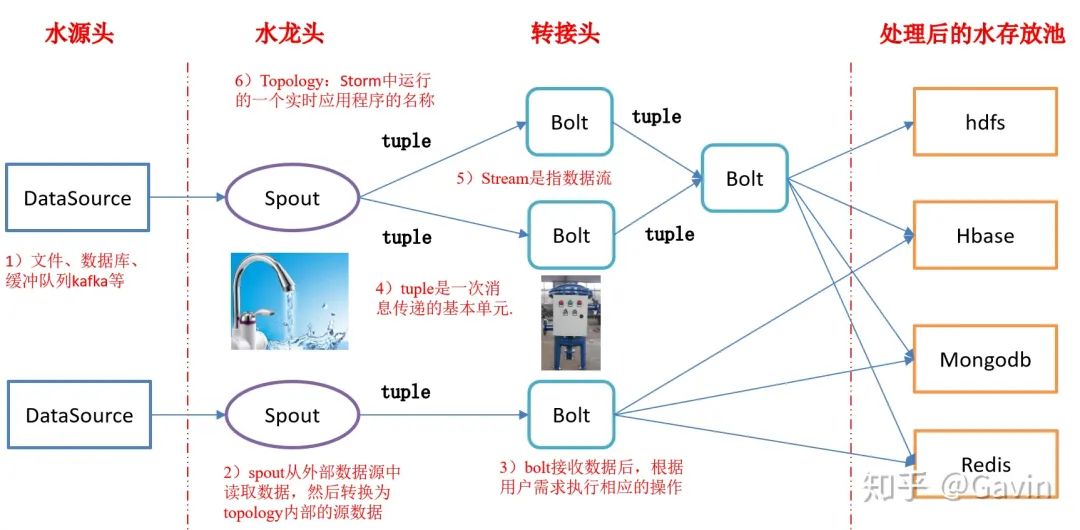
这里我们的Storm集群的水源头(数据源)是redis集群,使用list数据结构实现了消息队列的push/pop功能。
流式计算的整体流程:
酒店信息服务发送酒店信息到Redis集群A/B; Storm的spout组件从Redis集群A/B获取数据, 获取成功后,发送tuple消息给Bolt组件; Bolt组件收到消息后,通过运营配置的规则对数据进行清洗; 后Storm把处理好的数据发送到Redis集群C; 入库服务从Redis集群C获取数据,存储数据到数据库; 搜索团队扫描数据库表,生成索引。

这套流式计算服务每天处理千万条数据,处理得还算顺利。但方案在团队内部还是有不同声音:
storm的拓扑升级时候,或者优惠券服务重启的时候,偶尔出现丢消息的情况。但消息的丢失,对业务来讲没有那么敏感,而且我们也提供了手工刷新的功能,也在业务的容忍范围内; 团队需要经常关注Redis的缓存使用量,担心Redis队列堆积, 导致out of memory; 架构师认为搜索团队直接扫描数据库不够解耦,建议将Redis集群C替换成Kafka,搜索团队从kafka直接消费消息,生成索引;
我认为使用Redis做消息队列应该满足如下条件:
容忍小概率消息丢失,通过定时任务/手工触发达到终一致的业务场景; 消息堆积概率低,有相关的报警监控; 消费者的消费模型要足够简单。
2.2 RabbitMQ是管子不是池子
RabbitMQ是用erlang语言编写的。RabbitMQ满足了我的两点需求:
高可用机制。艺龙内部是使用的镜像高可用模式,而且这种模式在艺龙已经使用了较长时间了,稳定性也得到了一定的验证。 我负责的红包系统里,RabbitMQ每天的吞吐也在百万条消息左右,消息的发送和消费都还挺完美。
优惠券服务原使用SqlServer,由于数据量太大,技术团队决定使用分库分表的策略,使用公司自主研发的分布式数据库DDA。
因为是次使用分布式数据库,为了测试DDA的稳定性,我们模拟发送1000万条消息到RabbitMQ,然后优惠券重构服务消费消息后,按照用户编号hash到不同的mysql库。
RabbitMQ集群模式是镜像高可用,3台服务器,每台配置是4核8G 。
我们以每小时300万条消息的速度发送消息,开始1个小时生产者和消费者表现都很好,但由于消费者的速度跟不上生产者的速度,导致消息队列有积压情况产生。第三个小时,消息队列已堆积了500多万条消息了, 生产者发送消息的速度由开始的2毫秒激增到500毫秒左右。RabbitMQ的控制台已血溅当场,标红报警。
这是一次无意中的测试,从测试的情况来看,RabbitMQ很,但RabbitMQ对消息堆积的支持并不好,当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降。
有的朋友对我讲:“RabbitMQ明明是管子,你非得把他当池子?”
随着整个互联网数据量的激增, 很多业务场景下是允许适当堆积的,只要保证消费者可以平稳消费,整个业务没有大的波动即可。
我心里面越来越相信:消息队列既可以做管子,也可以当做池子。

3 升华MetaQ
Metamorphosis的起源是我从对linkedin的开源MQ–现在转移到apache的kafka的学习开始的,这是一个设计很独特的MQ系统,它采用pull机制,而 不是一般MQ的push模型,它大量利用了zookeeper做服务发现和offset存储,它的设计理念我非常欣赏并赞同,强烈建议你阅读一下它的设计文档,总体上说metamorphosis的设计跟它是完全一致的。--- MetaQ的作者庄晓丹
3.1 惊艳消费者模型
2015年,我主要从事神州专车订单研发工作。
MetaQ满足了我对于消息队列的幻想:“分布式,高吞吐,高堆积”。
MetaQ支持两种消费模型:集群消费和广播消费 ,因为以前使用过的消费者模型都是用队列模型,当我次接触到这种发布订阅模型的时候还是被惊艳到了。
▍ 集群消费
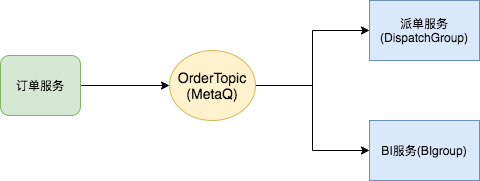
订单创建成功后,发送一条消息给MetaQ。这条消息可以被派单服务消费,也可以被BI服务消费。
▍ 广播消费
派单服务在讲订单指派给司机的时候,会给司机发送一个推送消息。推送就是用广播消费的模式实现的。
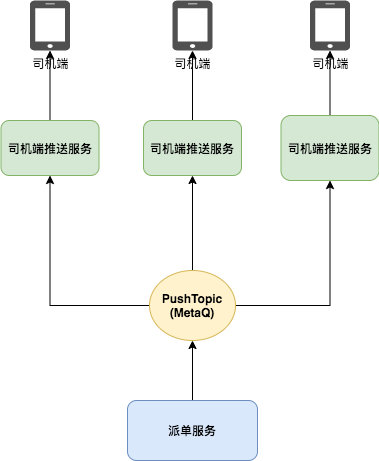
大体流程是:
司机端推送服务是一个TCP服务,启动后,采用的是广播模式消费MetaQ的PushTopic; 司机端会定时发送TCP请求到推送服务,鉴权成功后,推送服务会保存司机编号和channel的引用; 派单服务发送推送消息到MetaQ; 推送服务的每一台机器都会收到该消息,然后判断内存中是否存在该司机的channel引用,若存在,则推送消息。
这是非常经典的广播消费的案例。我曾经研读京麦TCP网关的设计,它的推送也是采用类似的方式。
3.2 激进的消峰
2015年是打车大战硝烟弥漫的一年。
对神州专车来讲,随着订单量的不断增长,欣喜的同时,性能的压力与日俱增。早晚高峰期,用户打车的时候,经常点击下单经常无响应。在系统层面来看,专车api网关发现大规模超时,订单服务的性能急剧下降。数据库层面压力更大,高峰期一条记录插入竟然需要8秒的时间。
整个技术团队需要尽快提升专车系统的性能,此前已经按照模块领域做了数据库的拆分。但系统的瓶颈依然很明显。
我们设计了现在看来有点激进的方案:
设计订单缓存。缓存方案大家要有兴趣,我们可以以后再聊,里面有很多可以详聊的点; 在订单的载客生命周期里,订单的修改操作先修改缓存,然后发送消息到MetaQ,订单落盘服务消费消息,并判断订单信息是否正常(比如有无乱序),若订单数据无误,则存储到数据库中。

这里有两个细节:
消费者消费的时候需要顺序消费,实现的方式是按照订单号路由到不同的partition,同一个订单号的消息,每次都发到同一个partition;

一个守护任务,定时轮询当前正在进行的订单,当缓存与数据不一致时候,修复数据,并发送报警。
这次优化大大提升订单服务的整体性能,也为后来订单服务库分库分表以及异构打下了坚实的基础,根据我们的统计数据,基本没有发生过缓存和数据库后不一致的场景。但这种方案对缓存高可用有较高的要求,还是有点小激进吧。
3.3 消息SDK封装
做过基础架构的同学可能都有经验:“三方组件会封装一层”,神州架构团队也是将metaq-client封装了一层。
在我的思维里面,封装一层可以减少研发人员使用第三方组件的心智投入,统一技术栈,也就如此了。
直到发生一次意外,我的思维升级了。那是一天下午,整个专车服务崩溃较长时间。技术团队发现:"专车使用zookeeper做服务发现。zk集群的leader机器挂掉了,一直在选主。"
临时解决后,我们发现MetaQ和服务发现都使用同一套zk集群,而且consumer的offset提交,以及负载均衡都会对zk集群进行大量的写操作。
为了减少MetaQ对zk集群的影响,我们的目标是:“MetaQ使用独立的zk集群”。
需要部署新的zk集群; MetaQ的zk数据需要同步到新的集群; 保证切换到新的集群,应用服务基本无感知。
我很好奇向架构部同学请教,他说新的集群已经部署好了,但需要同步zk数据到新的集群。他在客户端里添加了双写的操作。也就是说:我们除了会写原有的zk集群一份数据,同时也会在新的zk集群写一份。过了几周后,MetaQ使用独立的zk集群这个任务已经完成了。

这一次的经历带给我很大的感慨:“还可以这么玩?” ,也让我思考着:三方组件封装没有想像中那么简单。
我们可以看下快手消息的SDK封装策略:
对外只提供基本的 API,所有访问必须经过SDK提供的接口。简洁的 API 就像冰山的一个角,除了对外的简单接口,下面所有的东西都可以升级更换,而不会破坏兼容性 ; 业务开发起来也很简单,只要需要提供 Topic(全局)和 Group 就可以生产和消费,不用提供环境、NameServer 地址等。SDK 内部会根据 Topic 解析出集群 NameServer 的地址,然后连接相应的集群。生产环境和测试环境环境会解析出不同的地址,从而实现了隔离; 上图分为 3 层,第二层是通用的,第三层才对应具体的 MQ 实现,因此,理论上可以更换为其它消息中间件,而客户端程序不需要修改; SDK 内部集成了热变更机制,可以在不重启 Client 的情况下做动态配置,比如下发路由策略(更换集群 NameServer 的地址,或者连接到别的集群去),Client 的线程数、超时时间等。通过 Maven 强制更新机制,可以保证业务使用的 SDK 基本上是新的。

3.4 重构MetaQ , 自成体系
我有一个习惯 : "经常找运维,DBA,架构师了解当前系统是否有什么问题,以及他们解决问题的思路。这样,我就有另外一个视角来审视公司的系统运行情况"。
MetaQ也有他的缺点。
MetaQ的基层通讯框架是gecko,MetaQ偶尔会出现rpc无响应,应用假死的情况,不太好定位问题; MetaQ的运维能力薄弱,只有简单的Dashboard界面,无法实现自动化主题申请,消息追踪等功能。
有一天,我发现测试环境的一台消费者服务器启动后,不断报链接异常的问题,而且cpu占用很高。我用netstat命令马上查一下,发现已经创建了几百个链接。出于好奇心,我打开了源码,发现网络通讯框架gecko已经被替换成了netty。我们马上和架构部的同学联系。
我这才明白:他们已经开始重构MetaQ了。我从来没有想过重构一个开源软件,因为距离我太远了。或者那个时候,我觉得自己的能力还达不到。
后来,神州自研的消息队列自成体系了,已经在生产环境运行的挺好。
时至今天,我还是很欣赏神州架构团队。他们自研了消息队列,DataLink(数据异构中间件),分库分表中间件等。他们愿意去创新,有勇气去做一个更好的技术产品。
我从他们身上学到很多。
也许在看到他们重构MetaQ的那一刻,我的心里埋下了种子。
4 钟情RocketMQ
4.1 开源的盛宴
2014年,我搜罗了很多的淘宝的消息队列的资料,我知道MetaQ的版本已经升级MetaQ 3.0,只是开源版本还没有放出来。
大约秋天的样子,我加入了RocketMQ技术群。誓嘉(RocketMQ创始人)在群里说:“近要开源了,放出来后,大家赶紧fork呀”。他的这句话发在群里之后,群里都炸开了锅。我更是欢喜雀跃,期待着能早日见到阿里自己内部的消息中间件。
终于,RocketMQ终于开源了。我迫不及待想一窥他的风采。
因为我想学网络编程,而RocketMQ的通讯模块remoting底层也是Netty写的。所以,RocketMQ的通讯层是我学习切入的点。
我模仿RocketMQ的remoting写了一个玩具的rpc,这更大大提高我的自信心。正好,艺龙举办技术创新活动。我想想,要不尝试一下用Netty改写下Cobar的通讯模块。于是参考Cobar的源码花了两周写了个netty版的proxy,其实非常粗糙,很多功能不完善。后来,这次活动颁给我一个鼓励奖,现在想想都很好玩。
因为在神州优车使用MetaQ的关系,我学习RocketMQ也比较得心应手。为了真正去理解源码,我时常会参考RocketMQ的源码,写一些轮子来验证我的学习效果。
虽然自己做了一些练习,但一直没有在业务环境使用过。2018年是我真正使用RocketMQ的一年,也是有所得的一年。
▍ 短信服务
短信服务应用很广泛,比如用户注册登录验证码,营销短信,下单成功短信通知等等。开始设计短信服务的时候,我想学习业界是怎么做的。于是把目标锁定在腾讯云的短信服务上。腾讯云的短信服务有如下特点:
统一的SDK,后端入口是http/https服务 , 分配appId/appSecret鉴权; 简洁的API设计:单发,群发,营销单发,营销群发,模板单发,模板群发。
于是,我参考了这种设计思路。
模仿腾讯云的SDK设计,提供简单易用的短信接口; 设计短信服务API端,接收发短信请求,发送短信信息到消息队列; worker服务消费消息,按照负载均衡的算法,调用不同渠道商的短信接口; Dashboard可以查看短信发送记录,配置渠道商信息。 
短信服务是我真正意义次生产环境使用RocketMQ,当短信一条条发出来的时候,还是蛮有成就感的。
▍ MQ控制台

使用过RocketMQ的朋友,肯定对上图的控制台很熟悉。当时团队有多个RocketMQ集群,每组集群都需要单独部署一套控制台。于是我想着:能不能稍微把控制台改造一番,能满足支持多组集群。
于是,撸起袖子干了起来。大概花了20天的时间,我们基于开源的版本改造了能支持多组集群的版本。做完之后,虽然能满足我初的想法,但是做的很粗糙。而且搜狐开源了他们自己的MQCloud ,我看了他们的设计之后, 觉得离一个消息治理平台还很远。
后来我读了《网易云音乐的消息队列改造之路》,《今日头条在消息服务平台和容灾体系建设方面的实践与思考》这两篇文章,越是心痒难耐,蛮想去做的是一个真正意义上的消息治理平台。一直没有什么场景和机会,还是有点可惜。
近看了哈罗单车架构专家梁勇的一篇文章《哈啰在分布式消息治理和微服务治理中的实践》,推荐大家一读。
https://mp.weixin.qq.com/s/N-vd6he4nsZp-G3Plc4m6A
▍ 一扇窗子,开始自研组件
后来,我尝试进一步深入使用RocketMQ。
仿ONS风格封装消息SDK; 运维侧平滑扩容消息队列; 生产环境DefaultMQPullConsumer消费模式尝试
这些做完之后,我们又自研了注册中心、配置中心,任务调度系统。设计这些系统的时候,从RocketMQ源码里汲取了很多的营养,虽然现在看来有很多设计不完善的地方,代码质量也有待提高,但做完这些系统后,还是大大提升我的自信心。
RocketMQ给我打开了一扇窗子,让我能看到更广阔的Java世界。对我而言,这就是开源的盛宴。
4.2 Kafka: 大数据生态的不可或缺的部分
Kafka是一个拥有高吞吐、可持久化、可水平扩展,支持流式数据处理等多种特性的分布式消息流处理中间件,采用分布式消息发布与订阅机制,在日志收集、流式数据传输、在线/离线系统分析、实时监控等领域有广泛的应用。
▍ 日志同步
在大型业务系统设计中,为了快速定位问题,全链路追踪日志,以及故障及时预警监控,通常需要将各系统应用的日志集中分析处理。
Kafka设计初衷就是为了应对大量日志传输场景,应用通过可靠异步方式将日志消息同步到消息服务,再通过其他组件对日志做实时或离线分析,也可用于关键日志信息收集进行应用监控。
日志同步主要有三个关键部分:日志采集客户端,Kafka消息队列以及后端的日志处理应用。
日志采集客户端,负责用户各类应用服务的日志数据采集,以消息方式将日志“批量”“异步”发送Kafka客户端。Kafka客户端批量提交和压缩消息,对应用服务的性能影响非常小。 Kafka将日志存储在消息文件中,提供持久化。 日志处理应用,如Logstash,订阅并消费Kafka中的日志消息,终供文件搜索服务检索日志,或者由Kafka将消息传递给Hadoop等其他大数据应用系统化存储与分析。
日志同步示意图:
▍流计算处理
在很多领域,如股市走向分析、气象数据测控、网站用户行为分析,由于数据产生快、实时性强且量大,您很难统一采集这些数据并将其入库存储后再做处理,这便导致传统的数据处理架构不能满足需求。Kafka以及Storm、Samza、Spark等流计算引擎的出现,就是为了更好地解决这类数据在处理过程中遇到的问题,流计算模型能实现在数据流动的过程中对数据进行实时地捕捉和处理,并根据业务需求进行计算分析,终把结果保存或者分发给需要的组件。
▍ 数据中转枢纽
近10多年来,诸如KV存储(HBase)、搜索(ElasticSearch)、流式处理(Storm、Spark、Samza)、时序数据库(OpenTSDB)等专用系统应运而生。这些系统是为单一的目标而产生的,因其简单性使得在商业硬件上构建分布式系统变得更加容易且性价比更高。通常,同一份数据集需要被注入到多个专用系统内。例如,当应用日志用于离线日志分析时,搜索单个日志记录同样不可或缺,而构建各自独立的工作流来采集每种类型的数据再导入到各自的专用系统显然不切实际,利用消息队列Kafka版作为数据中转枢纽,同份数据可以被导入到不同专用系统中。
下图是美团 MySQL 数据实时同步到 Hive 的架构图,也是一个非常经典的案例。

4.3 如何技术选型
2018年去哪儿QMQ开源了,2019年腾讯TubeMQ开源了,2020年Pulsar如火如荼。
消息队列的生态是如此的繁荣,那我们如何选型呢?
我想我们不必局限于消息队列,可以再扩大一下。简单谈一谈我的看法。
Databases are specializing – the “one size fits all” approach no longer applies ----- MongoDB设计哲学
点:先有场景,然后再有适配这种场景的技术。什么样的场景选择什么样的技术。
第二点:现实往往很复杂,当我们真正做技术选型,并需要落地的时候,技术储备和成本是两个我们需要重点考量的因素。
▍ 技术储备
技术团队有无使用这门技术的经验,是否踩过生产环境的坑,以及针对这些坑有没有完备的解决方案; 架构团队是否有成熟的SDK,工具链,甚至是技术产品。
▍ 成本
研发,测试,运维投入人力成本; 服务器资源成本; 招聘成本等。
后一点是人的因素,特别是管理者的因素。每一次大的技术选型考验技术管理者的视野,格局,以及管理智慧。
5 写到后
我觉得这个世界上没有什么毫无道理的横空出世,真的,如果没有大量的积累大量的思考是不会把事情做好的。。。总之,在经历了这部电影以后,我觉得我要学的太多了,这世界上有太多的能人,你以为的极限,弄不好,只是别人的起点。所以只有不停地进取,才能不丢人。那,人可以不上学,但一定要学习,真的。------ 韩寒《后会无期》演讲
我学习消息队列的过程是不断思考,不断实践的过程,虽然我以为的极限,弄不好,只是别人的起点,但至少现在,当我面对这门技术的时候,我的内心充满了好奇心,同时也是无所畏惧的。
我始终相信:每天学习一点点,比昨天进步一点点就好。
如果我的文章对你有所帮助,还请帮忙点赞、在看、转发一下,你的支持会激励我输出更高质量的文章,非常感谢!
