翻译自:
Oracle High Availability - ASM, Clusterware, Cold Failover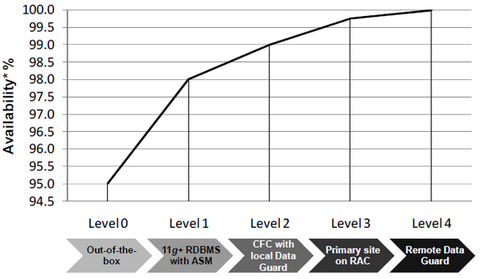
在我上一篇文章中对Oracle数据库的高可用性和SLA要求中,我们讨论了成功的高可用性(HA)首先是对业务所需的服务级别协议(SLA)以及所有这些方面的理解。这将指导有关IT技术的重要决策,并确定对HA架构的适当投资水平。从头开始为数据库系统设计选择正确的技术解决方案很困难。您可以遵循一些佳实践,以基于可用性级别构建高可用性Oracle数据库系统符合数据库行业标准。在本文中,我将分享一些佳实践以及我在为个2.5可用性级别设计数据库系统时的经验,这些知识描述了一些基于SAN,集群,集群件,Oracle ASM,冷故障转移集群(CFC)的技术解决方案。
我将从下面的图形开始,该图形说明了可用性连续体,并描述了随着可用性水平之间的进展而可获得的可用性增加。它不是基于经验数据,并且所使用的百分比值仅用于说明目的,但是(根据我的经验)接近于Oracle数据库环境的通用IT基础架构中的实际数字。
解释y轴刻度的另一种方法是衡量可接受的停机时间-轴的下端代表可以容忍的合理停机时间,而轴的上端代表即使停机时间小的停机时间,难以忍受。

可用性连续性– Oracle数据库高可用性级别
考虑上述“ 可用性连续体”图的y轴的另一种方法是在成本方面。如果所需的可用性较高,并且停机时间相应地变得不太可接受,则达到所需的可用性水平将需要较高的成本。
对于图片上的每个可用性级别(有时称为Tiers),我将代表用于构建Oracle数据库环境的具体技术示例和IT解决方案。可用性级别相互依赖,从而扩展了上一级别的冗余和恢复选项。
可用性级别0:开箱即用
级别0可用性是Oracle单个数据库实例的现成配置,没有特定的高可用性(HA)元素。意味着,您需要一台服务器,并使用普通文件系统在其中安装Oracle单个数据库实例,而无需镜像磁盘。即使不采取任何其他措施(除了安装产品),可用性也被认为是95%左右。当然,不同的单个服务器可以具有不同的可用性规范。例如,在运行Linux OS的单个HP ProLiant服务器上,使用此配置可以实现95%的可用性。即使在Oracle单个数据库实例中,您也可以使用下面列出的有限列表中的许多Oracle High Availability(HA)功能和工具:
– SPFILE
–复用生产重做日志和控制文件
–启用ARCHIVELOG模式并使用闪回恢复区
–将检查点记录到警报日志
–启用块检查
–自动撤消管理
–本地管理的表空间
–自动段空间管理
–可恢复空间分配
–数据库资源管理器
–带有临时文件的临时表空间
– Oracle重新启动
–包括闪回数据库的闪回技术
–恢复管理器(RMAN)
–快速启动故障恢复
–数据恢复顾问
–在线重组和重新定义
–在线补丁
–动态数据库重新配置
–自动诊断存储库(ADR)
–硬– Oracle硬件辅助的弹性数据
– ..
在此配置以及数据库内置功能的帮助下,使用Oracle GRID基础架构附带的Oracle Restart功能非常有效。Oracle重新启动仅针对单个非集群实例环境实施高可用性(HA)解决方案。它监视运行状况并自动重新启动以下组件:数据库实例,Oracle Net侦听器,数据库服务,ASM实例,ASM磁盘组。
可用性级别1:存储级保护– SAN / LVM / ASM
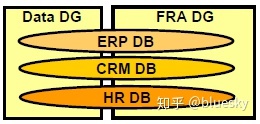
Oracle ASM – 2个磁盘组用于多个数据库
级别1的可用性涉及将11.1.0.7或更高版本的数据库实例与受保护的存储(SAN,LVM或/和Oracle ASM)一起使用。这提供了针对存储级故障的保护元素,但是服务器组件没有冗余。在这里,您应该考虑不同的存储级保护选项。存储级保护主题并不像乍看起来那样简单。在开始构建数据库系统之前,您必须考虑很多事情并回答某些问题。我在下面提到其中一些。
多少文件系统,磁盘组,磁盘足够?
大多数情况下,对于一个数据库,甚至两个数据库组之间的共享磁盘阵列(SAN),两个磁盘组就足够了。一个磁盘组用于Oracle数据文件(ORA_DATA)。使用第二个磁盘组可以将数据用作公用的Oracle快速恢复区(ORA_FRA),从而对数据进行备份。这样,您可以大化用作ASM磁盘的逻辑单元号(LUN)的数量,从而获得佳性能。
HA使用哪种RAID配置?
Oracle建议在使用硬件镜像技术时尽可能使用外部冗余磁盘组,以避免服务器上不必要的开销。好使用具有相同性能,特性和容量的LUN,以大程度地增加SAN和Oracle ASM磁盘组中的主轴数量(但是,这对于SAN管理员来说是很痛苦的)。同样,选择取决于您的业务需求和预算,但是我在下面列出了一些主要选择:
a)硬件RAID1(镜像;佳性能;现代SAN的佳选择)
b)RAID5(奇偶校验保护,更经济的解决方案,不适用于写密集型工作负载或重做日志)
c)Oracle ASM镜像(低成本存储的佳选择;启用扩展集群解决方案)
d)不建议同时使用Oracle ASM镜像和硬件镜像。
哪种条纹效果好?
这里的一个建议是:不要使用LVM或“无条带化”。基于Oracle的条带化条带(结合了Oracle ASM条带化和RAID条带化)也提供了良好的性能。但是,我不建议您也这样做。
可用性级别2a:冷故障转移群集模式(CFC)中的数据库

Oracle Clusterware上的冷故障转移群集模式下的Oracled数据库
级别2的可用性可能由处于相同物理位置的冷故障转移群集模式(CFC)的单个Oracle数据库实例组成,或采用Oracle Data Guard将数据库复制到故障转移硬件。故障转移到冗余系统期间会导致一些停机时间。如上所述,由于可用性级别是相互建立的,因此此配置还包括存储级别的保护。CFC和Oracle Data Guard是分开的世界,那里的配置有很多选择。从可用性级别2开始,还考虑尝试构建一个简单的数据库系统而不是设计复杂的东西的复杂性。
冷故障转移群集模式(CFC)是更复杂的主题,因为它不仅由Oracle涵盖,而且由不同的供应商提供。对于此数据库配置,您需要以下内容:
– 2个或多个节点的群集
–带有群集软件的OS
–共享存储(SAN)不是强制性的,但在Oracle ASM,OCFS2,NFS或任何经过认证的群集文件系统上更可取
–处于冷故障转移模式的单个数据库实例
我亲自进行以下配置。
带有TruVluster软件的基于OpenVMS和Tru64的冷故障转移群集
+非常稳定
+使用自己的群集文件系统
–成本高昂
–过时的解决方案
基于Linux RedHat集群件的冷故障转移集群
+便宜
+使用Linux RedHat有意义+易于
管理,但进行重大升级可能会很痛苦
–每个实例只能使用一个Oracle二进制集
–不共享存储阵列(SAN),而是将其安装到活动集群节点上
–基于主机的镜像扩展集群中的服务器需要不同的Linux LVM,且需要更多维护
基于HP和ServiceGuard软件的冷故障转移群集
+ +复杂但稳定
+在HP-UX和Linux上可用
+可能具有HP-UX LVM的基于主机的镜像
+先进的集群裂脑功能
+可能具有ASM的基于主机的镜像
–每个实例只能有一个Oracle二进制集
–存储阵列(SAN)未共享,但已安装到活动群集节点上
-相当大
基于具有故障转移脚本的Oracle Clusterware的冷故障转移群集
+如果您将Oracle许可产品(数据库)集群化,则不会单独获得许可
+在11gR2之前可与Oracle Clusterware和数据库一起使用
+集群节点之间共享存储阵列(SAN)
+可能使用ASM进行基于主机的镜像
–无法进行在线数据库重定位与RAC One Node一样
– Oracle不直接将操作脚本支持为自定义代码片段
基于Oracle Clusterware和Oracle RAC 1节点的冷故障转移群集
+ Oracle推荐的冷故障转移解决方案
+提供比其他数据库更高的数据库可用性
+可以进行在线迁移和修补
+单一供应商解决方案
+准备扩展到完整的RAC
+在群集节点之间共享存储阵列(SAN)
+可以与ASM进行基于主机的镜像
–仅可用于11gR2 +
–单独许可(高CPU许可的〜+ 25%)
总结来说,在本文中,我分享了一些佳实践和我在设计数据库系统时的经验,这些经验描述了基于单服务器,SAN,集群,集群件,Oracle ASM和冷故障转移集群(CFC)模式下的数据库的一些技术解决方案。下次,我将继续介绍Oracle Data Guard,Oracle RAC和Oracle Maximum Availability Architecture(MAA)的其他可用性级别。在DOAG成立25周年的Oracle HA演示中看到更多例子。
